 電子發燒友App
電子發燒友App


首先簡單介紹一下Dremel是什么,能解決什么問題。第二部分著重講Dremel的數據模型,即數據結構。第三部分將談一下在此數據結構上設計的算法。
1?起源
Dremel的數據模型起源于分布式系統的應用環境(Protocol Buffers,一種在Google內廣泛使用,現已開源的實現)。其數據模型是基于強類型的嵌套記錄,抽象語法可以表示成下面公式:
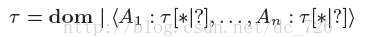
一個例子:

2?嵌套列式存儲
2.1?記錄結構的無損表示
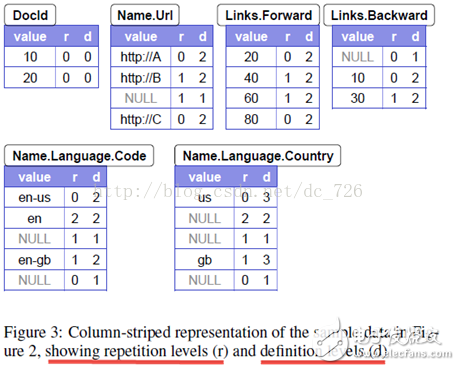
首先來看一下Dremel的數據模型是如何在列式存儲下無損的表示出記錄的結構的(lossless representation of record structure in a columnar format)。如果僅僅是數值(values)的話,數值本身無法傳遞出記錄(record)的結構信息。我們不知道兩個數值是屬于兩條不同的記錄還是在一條記錄下,同時我們也不知道一些可選的字段(field)是否顯式定義。因此,我們引入了兩個概念:Repetition Level和Definition Level。
為了說清楚Dremel模型是如何無損地表示數據的,我想到了兩種畫法。最終還是決定采用第一種畫法,類似有向圖,感覺與后面的FSM狀態機能更好的對應上。

Repetition Level
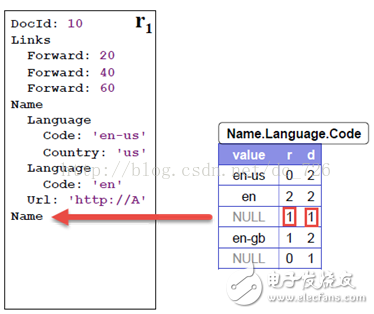
Dremel論文中對repetition level的定義聽起來比較抽象:at what repeated field in the field's path the value has repeated。意思就是在路徑上,在哪個repeated字段上重復了。還是看個例子解釋一下吧,以之前的圖例中的文檔r1中的Code字段為例。
?

上圖清晰地表示出三個Code字段與文檔中字段的對應關系。下面來看一下這三個Code的repetition level(簡寫為r) 0,2,1是如何計算出來的。下圖忽略無關的字段,將三個Code字段的完整路徑都表示出來。那么就可以簡單易懂地看出,r就是這些字段路徑上,發生重復了的字段的level。請參考下圖中的注釋就能很快理解。
?

大家可能還注意到Name.Code表中除了en-us、en和en-gb三行外,還有兩行NULL。第二個NULL是描述文檔r2的,我們就分析一下第一個NULL的含義吧。因為文檔r1的第二個Name字段下沒有Code,而為了說明en-gb是屬于第三個Name字段下的,所以在en和en-gb之間加了一行NULL,其r也等于1(Name重復)。同時,由于Code在定義中是required的字段,所以事實上這一行NULL也暗示了:在第二個Name字段下Language也是不存在的。不然Language存在而下面卻沒有Name,這是不符合文檔定義的。
以此類推,其他字段的r值都是這樣計算出來的。同時注意一點:我們只保存了有值的字段,如DocId、Name.Url、Name.Language.Code等,而像Links、Name.Language等字段是沒必要保存的。
?
Definition Level
definition level(簡寫為d)在論文中的定義還比較清楚:Each value of a field with path p ,?esp. every NULL, has a definition level specifying?how many fields in p that could be undefined?(because they are optional or repeated)?are actually present.?尤其對于NULL來說,路徑p上有多少字段可以是不存在(例如在文檔定義中是optional或repeated,而不是required),然而實際卻存在的。例如文檔r1的Links下沒有Backward字段,然而Links字段卻存在(因為Links下有Forward),所以我們在Links.Backward表中保存一條NULL,并且d=1。對于非NULL字段來說,意義不大,因為d的值對于每種字段來說都是相同的,例如Code都是2,Country都是3。
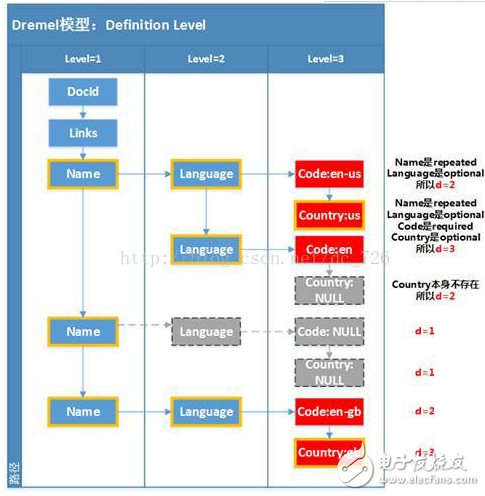
值得注意的幾點是:
???在路徑上計算多少字段本可以不存在時,包含了當前字段本身。例如計算Country:us時,Country本身也是optional,也計入總數,所以d=3。
???每種字段只計算1次。例如最下面的Country:gb,在其路徑上的3個Name都滿足條件,但只計1次,所以d=3,而不是5。(前面提過,也許是我這第一種畫法的緣故,需要這一條規則來限定)
數據壓縮
前面介紹了數據的保存方法,實際上真正保存時,數據還會被進一步壓縮。
???不顯式保存NULL,因為它可以通過d來確定:d
???總是會被定義的字段的d不會被保存。
???r也是僅在必要時才會保存。例如d=0暗示r=0,所以r可以省略不存。
???像DocId這種所有level都是0的,實際上不會保存任何level信息。
???盡可能使用位圖。例如假如d最大是3,那么我們只使用2個bit來保存。
2.2?快速編碼成列式存儲
略,詳見論文附錄部分的偽代碼。
2.3?高效地組裝記錄
高效地從列式存儲數據中組裝出記錄,對像MapReduce這種面向記錄的數據處理工具來說非常重要。我們的目標是:給定字段的子集,我們能重新構建出僅包含選中字段的原始記錄,而過濾掉其他字段。核心思想是:使用有限狀態機(finite state machine, FSM)讀取每個字段的值和level,順序地追加到輸出流中。FSM為每種字段都關聯一個field reader。狀態轉變通過repetition level來標記。一旦reader抓取到值,我們繼續看下一repetition level來決定使用哪個reader。FSM就這樣從開始狀態到結束狀態遍歷完每條記錄。
下面還是用前面的例子,通過DocId和Name.Language.Country這兩個字段的重建,來詳細解析一下FSM的工作過程。關鍵步驟用紅色加粗標記。
?
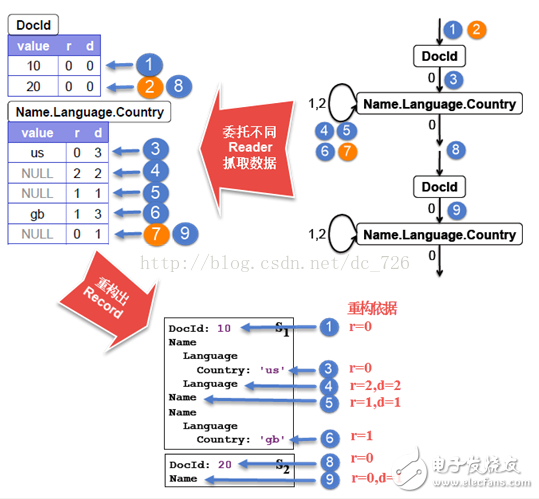
1.??????FSM委托Reader1讀取DocId第一行,通過r=0重建記錄。
2.??????檢查DocId第二行,發現r=0,則Reader1停在當前“游標”位置。FSM將狀態變化到Name.Language.Country。
3.??????FSM委托Reader2讀取Name.Language.Country第一行,通過r=0重建記錄。
4.??????FSM委托Reader2讀取Name.Language.Country第二行。通過r=2(說明Language字段重復,即Language有多個)重建記錄。
5.??????FSM委托Reader2讀取Name.Language.Country第三行。通過r=1和d=1(說明只有Name字段不是NULL)重建記錄。
6.??????略過第四行。
7.??????檢查到第五行,發現r=0,Reader2停在當前位置。FSM再次發生狀態變化,繼續重建文檔2的記錄。
8.??????FSM委托Reader1繼續讀取DocId第二行(之前Reader1就停在這里了)。
9.??????到這里應該已經很清楚了,最后過程就略說了:DocId中沒有數據了,FSM狀態變化,Reader2繼續讀取Country的最后一行數據,重建出記錄。
注:論文原圖中少了第二個Name字段,我覺得應該加上吧。在第五步被重新構建出來。為什么在原圖中沒有呢?
前面例子的完整FSM就是這樣的:
?

?“神秘”的r和d
單從數據結構來看的話,我們可以這樣解釋r和d的含義。r代表著當前字段與前一字段的關系,是在哪一層合并的,即公共的父結點在哪?舉例來說,假如我們重建到了Code='en',通過r=2可以知道是在Language那一層發生了重復。
?

為了保持原紀錄的結構,我們會保存一些NULL數據,而d就是用于重建NULL字段。通過d的值,就能知道NULL的結構。例如下圖,通過r=1知道應該合并到Name那一層。而通過d=1則知道路徑上只有一個字段,即不僅僅是Code字段不存在,Language也不存在。這樣就把NULL正確地重建出來了,那么接下來的Code='en-gb'的層級也就不會亂了。
?
然而這只是從靜態的數據結構來解釋,而r和d的深層次含義還是要看FSM是如何執行的。真正的因果關系是FSM的執行方式決定了數據結構的設計。
3?記錄查詢3.1?從FSM角度看r和d
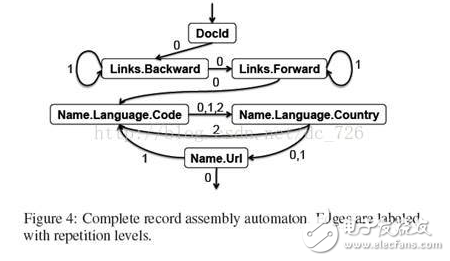
先看一下前面例子的完整FSM的樣子。如果把Protocol Buffer中對數據格式定義的schema看作是編譯原理中的語法定義的話,那么一般可以使用工具如antlr,?yacc自動生成自動機,手寫的話是相當恐怖的吧。
?
?
?
對列數據的完整遍歷就是這個樣子的:
?

在討論查詢如何執行之前,先繼續剛才未完成的題目,r和d的本質,這次通過動態的FSM的角度來分析,而不是靜態的數據結構了:
???FSM狀態機只是定義了狀態的變更,即處理流程應當如何在各個列的存儲表之間跳轉,而實際數據還是在表中保存。有點像數據庫索引,遍歷時是根據FSM進行跳轉,然后對某一列的表進行table scan。但索引是靠字段值的順序組織,因為數據庫表之間沒什么嵌套關系,而Dremel的FSM則是靠字段之間的嵌套關系來組織。
?

???狀態機中線條上的數字表示什么?回憶一下,數字表示的是:字段的數據表中當前行的下一行的r值。通過檢測下一個r值來決定跳轉。因為r=0,則說明下一行與當前行所表示的字段一定不在同一路徑,否則必然會在某一Level上有共同的字段(路徑的部分重疊)。注意這是由于Protocol Buffer的schema不是樹,沒有共同的根所導致,否則所有字段必然都會在根重復,上面對r的解釋也就沒意義了。以repeated的Forward為例,檢查到下一行r=1說明40、60都是接在20字段下面的。Code字段也是同樣道理。
?

???Name.Language.Code到Name.Language.Country之間的線上為什么是0,1,2?因為Name.Language.Code是required不是repeated,讀取后不管下一行的r值是多少都要去讀Name.Language.Country。同理Name.Language.Country也是讀完不管怎樣都跳到下一字段。
???最復雜的要屬Name.Url了,因為它是schema里定義的最后一個字段。在Name.Url這要決定到底是繼續下一文檔如r2的處理,還是跳回到本文檔的其他字段繼續處理。具體分析一下:r=0說明當前文檔中沒有Name字段了。為什么這么說?因為如果文檔后面真有Name字段,假如下面有Url,則當前表中的下一條應該是r=1;假如下面沒有Url,則當前表的下一條應該是r=0的NULL。這里NULL又發揮用處了!所以中間部分的NULL能保持結構無損,而后面部分的NULL能提示文檔是否結束。
3.2?查詢引擎
至此,我們已經徹底摸清Dremel數據模型以及FSM的基本運行方式了。現在終于可以分析Dremel是如何解析和執行類SQL查詢的了。查詢語言類似SQL,輸出也是個嵌套式的記錄,以及schema定義。

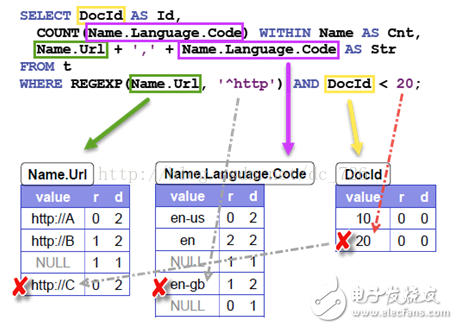
那么查詢引擎如何執行呢?首先為查詢語句中涉及到的每個字段都打開一個Reader來讀取數據,然后就是根據WHERE中的條件過濾以及根據SELECT中的條件投影并聚合了。難點在于:重建出層次關系,再進行過濾和聚合。例如,過濾掉DocId=20很容易,但其實文檔r2的所有記錄都應被過濾。因為WHERE中兩個條件是AND關系,同時DocId又是最底層的字段,所以相當于r2這一整棵樹都被裁剪掉了。Code=en-gb也是由于所在的Name字段下沒有滿足http開頭的Url字段,而被間接的過濾掉了。
聚合也是同樣道理,有了層次關系,才能正確的聚合。例如Code=en-us,en和Url=http://A是同一個Name下的,COUNT和字符串拼接時會一起處理。而Url=http://B則是另一個Name下的,要分開處理。
























 工商網監
工商網監
評論