 電子發(fā)燒友App
電子發(fā)燒友App


作者:程進(jìn)1,2,胡寒棟1,2,3,江業(yè)帆1,2,張一博1,2,3,丁季時(shí)雨1,2,3
(1.航天科工集團(tuán)智能科技研究院有限公司,北京 100144;2.航天防務(wù)智能系統(tǒng)與技術(shù)科研重點(diǎn)實(shí)驗(yàn)室,北京 100144;3.中國(guó)航天科工集團(tuán)第二研究院,北京 100854)
摘要:?隨著人工智能技術(shù)的發(fā)展,空域無(wú)人作戰(zhàn)正由“單平臺(tái)遙控”向“多平臺(tái)協(xié)同”轉(zhuǎn)變。多無(wú)人機(jī)協(xié)同作戰(zhàn)任務(wù)具有非完全信息、通信受限、高實(shí)時(shí)、強(qiáng)動(dòng)態(tài)等特點(diǎn),給協(xié)同決策生成帶來(lái)巨大挑戰(zhàn)。針對(duì)通信受限環(huán)境中的多無(wú)人機(jī)協(xié)同決策問(wèn)題,提出一種基于動(dòng)態(tài)層級(jí)網(wǎng)絡(luò)通信架構(gòu)的通信強(qiáng)化學(xué)習(xí)協(xié)同策略,該策略能夠顯著減少無(wú)人機(jī)集群間的通信次數(shù),同時(shí)準(zhǔn)確傳遞其決策需要的信息,從而得到較優(yōu)協(xié)同策略。針對(duì)多無(wú)人機(jī)協(xié)同圍捕的典型任務(wù)場(chǎng)景,基于OpenAI平臺(tái)對(duì)所提出的算法進(jìn)行了仿真驗(yàn)證。結(jié)果表明,與傳統(tǒng)強(qiáng)化學(xué)習(xí)算法相比,提出的通信強(qiáng)化學(xué)習(xí)策略可以顯著減少無(wú)人機(jī)間的通信次數(shù),同時(shí)在一定程度上避免潛在的信息欺騙問(wèn)題。完成任務(wù)需要的平均通信次數(shù)相比于傳統(tǒng)兩兩通信結(jié)構(gòu)減少約 77%,為實(shí)現(xiàn)通信受限環(huán)境中的多無(wú)人機(jī)協(xié)同任務(wù)提供技術(shù)支撐。
1 引 言
隨著人工智能技術(shù)的發(fā)展,空域無(wú)人作戰(zhàn)正由“單平臺(tái)遙控”向“多平臺(tái)協(xié)同”轉(zhuǎn)變[1]。由于單個(gè)無(wú)人機(jī)的載荷能力與探測(cè)能力有限,因而難以完成復(fù)雜的作戰(zhàn)任務(wù),無(wú)法滿足日益增長(zhǎng)的智能化作戰(zhàn)需求。多無(wú)人機(jī)集群協(xié)同能夠突破單個(gè)無(wú)人機(jī)的能力限制,通過(guò)信息共享與統(tǒng)一決策有效提升無(wú)人機(jī)的總體作戰(zhàn)能力[2],從而實(shí)現(xiàn)多無(wú)人機(jī)集群自主協(xié)同搜索、協(xié)同圍捕、協(xié)同打擊等作戰(zhàn)任務(wù)。在多無(wú)人機(jī)協(xié)同作戰(zhàn)過(guò)程中,每架無(wú)人機(jī)作為一個(gè)智能體,共同構(gòu)成多智能體系統(tǒng)。多智能體系統(tǒng)的目標(biāo)是讓若干個(gè)單智能體通過(guò)相互協(xié)作實(shí)現(xiàn)復(fù)雜智能,使得在降低系統(tǒng)建模復(fù)雜性的同時(shí),提高系統(tǒng)的魯棒性、可靠性、靈活性。
當(dāng)前,多無(wú)人機(jī)在復(fù)雜環(huán)境下的不完全信息博弈決策問(wèn)題已成為多無(wú)人機(jī)協(xié)同作戰(zhàn)場(chǎng)景下亟待解決的前沿?zé)狳c(diǎn)問(wèn)題之一[3]。多無(wú)人機(jī)協(xié)同決策具有多智能體并存、多復(fù)雜任務(wù)、對(duì)抗實(shí)時(shí)性、動(dòng)作持續(xù)性、信息不完全、搜索空間龐大等特點(diǎn)。近年來(lái),以深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)為代表的人工智能技術(shù)取得了較大的突破,多智能體協(xié)同決策問(wèn)題的解決方法逐漸從傳統(tǒng)的基于預(yù)編程規(guī)則的方法轉(zhuǎn)向以智能體自主強(qiáng)化學(xué)習(xí)為主的方法[4-5]。通過(guò)強(qiáng)化學(xué)習(xí)方法研究多無(wú)人機(jī)間的協(xié)同決策,能夠?yàn)榻鉀Q未來(lái)軍事協(xié)同對(duì)抗問(wèn)題提供新的有效途徑。
多智能體強(qiáng)化學(xué)習(xí)場(chǎng)景根據(jù)任務(wù)目標(biāo)可分為完全合作型、完全競(jìng)爭(zhēng)型、混合型[6]。其中,在完全合作型中,智能體一般無(wú)法觀測(cè)到環(huán)境中的所有狀態(tài)信息,且所有智能體需要合作實(shí)現(xiàn)共同目標(biāo);在完全競(jìng)爭(zhēng)型中,智能體一般分為兩隊(duì),且兩隊(duì)智能體具有零和獎(jiǎng)勵(lì)函數(shù),智能體一般考慮在最壞的情況下將對(duì)手盡力最小化,從而最大化自己的利益,經(jīng)典算法有Minimax-Q等[7];在混合型中,智能體擁有各自獨(dú)立的獎(jiǎng)勵(lì)函數(shù)且不受限制,常見(jiàn)方法主要有Nash Q-learning等[8]。近年來(lái),多智能體強(qiáng)化學(xué)習(xí)主要聚焦于在部分可觀環(huán)境下的完全合作型場(chǎng)景。在該設(shè)置下,多智能體強(qiáng)化學(xué)習(xí)算法的主要研究方向包括緊急行為分析[9]、值分解[10]、聯(lián)合探索[11]等。
真實(shí)作戰(zhàn)場(chǎng)景電磁環(huán)境復(fù)雜、通信容量有限,難以滿足智能體海量節(jié)點(diǎn)實(shí)時(shí)全聯(lián)通的需求。對(duì)于無(wú)人機(jī)集群而言,通信受限問(wèn)題已成為限制其協(xié)同決策發(fā)展的關(guān)鍵瓶頸之一。傳統(tǒng)強(qiáng)化學(xué)習(xí)算法無(wú)法有效處理通信受限環(huán)境中的協(xié)同決策需求。為此,一些學(xué)者提出了基于通信的多智能體強(qiáng)化學(xué)習(xí)算法。基于通信的多智能體強(qiáng)化學(xué)習(xí)算法主要解決多智能體系統(tǒng)中的部分可觀測(cè)問(wèn)題,試圖使用顯式的通信信道實(shí)現(xiàn)信息的共享。Foerster等[12]最先在深度多智能體強(qiáng)化學(xué)習(xí)中引入通信學(xué)習(xí),提出了RIAL和DIAL兩種使用深度網(wǎng)絡(luò)學(xué)習(xí)離散通信信息的方法。Sukhbaatar等[13]提出了CommNet,在智能體之間構(gòu)建了一個(gè)具備傳輸連續(xù)信息能力的通信通道,確保環(huán)境中任何一個(gè)智能體都可以實(shí)時(shí)傳遞信息。IC3NET[14]使用可學(xué)習(xí)的閥函數(shù)控制智能體是否參與本次通信,減少了智能體間不必要的通信頻率。SchedNet[15]利用智能體根據(jù)自身觀測(cè)生成的動(dòng)態(tài)重要性權(quán)重進(jìn)行排序,只選取最大的K個(gè)智能體進(jìn)行通信,利用先驗(yàn)信息減少了通信次數(shù)。TarMAC[16]利用注意力機(jī)制計(jì)算智能體對(duì)其他智能體消息的權(quán)重,以此實(shí)現(xiàn)選擇性的通信。GA-Comm使用游戲提取法,即基于軟性注意力及硬性注意力提取智能體間的關(guān)系,結(jié)合雙向LSTM網(wǎng)絡(luò)實(shí)現(xiàn)更準(zhǔn)確、高效的通信[17]。NDQ[17]通過(guò)限制信息熵、接收到的信息與動(dòng)作信息,對(duì)信息質(zhì)量進(jìn)行優(yōu)化,得到更加簡(jiǎn)短、高效的通信信息。IS[18]使用預(yù)測(cè)網(wǎng)絡(luò)估計(jì)環(huán)境轉(zhuǎn)移概率,并將智能體未來(lái)運(yùn)動(dòng)軌跡編碼至通信信息中,實(shí)現(xiàn)智能體間的意圖分享。然而,上述方法在多無(wú)人機(jī)協(xié)同決策中存在信息欺騙問(wèn)題。
鑒于此,本文針對(duì)通信受限環(huán)境中的多無(wú)人機(jī)協(xié)同決策問(wèn)題,提出了一種基于動(dòng)態(tài)層級(jí)網(wǎng)絡(luò)通信架構(gòu)的通信強(qiáng)化學(xué)習(xí)協(xié)同策略。該策略能夠顯著減少無(wú)人機(jī)集群間的通信次數(shù),同時(shí)準(zhǔn)確傳遞其決策需要的信息,在一定程度上避免信息欺騙問(wèn)題,從而得到較優(yōu)協(xié)同策略。針對(duì)多無(wú)人機(jī)協(xié)同圍捕的典型場(chǎng)景,基于 OpenAI平臺(tái)對(duì)所提出的算法進(jìn)行了仿真驗(yàn)證。
2 多無(wú)人機(jī)通信強(qiáng)化學(xué)習(xí)協(xié)同策略架構(gòu)
本文基于動(dòng)態(tài)層級(jí)網(wǎng)絡(luò)設(shè)計(jì)多無(wú)人機(jī)強(qiáng)化學(xué)習(xí)協(xié)同策略,通過(guò)將多無(wú)人機(jī)系統(tǒng)建模為層級(jí)通信網(wǎng)絡(luò),在消息中融合觀測(cè)及意圖信息,實(shí)現(xiàn)選擇性的觀測(cè)共享和單邊的意圖分享,提升無(wú)人機(jī)對(duì)全局狀態(tài)的信念并且實(shí)現(xiàn)更好的協(xié)作。在此基礎(chǔ)上,引入線性值分解網(wǎng)絡(luò),將團(tuán)隊(duì)獎(jiǎng)勵(lì)分解為條件狀態(tài)-動(dòng)作函數(shù)值,實(shí)現(xiàn)更為準(zhǔn)確的效用分配。同時(shí),結(jié)合內(nèi)在獎(jiǎng)勵(lì)的方法,設(shè)計(jì)基于策略不確定度的通信獎(jiǎng)勵(lì),實(shí)現(xiàn)對(duì)有向?qū)蛹?jí)網(wǎng)絡(luò)的訓(xùn)練。
多無(wú)人機(jī)通信強(qiáng)化學(xué)習(xí)協(xié)同策略的整體架構(gòu)如圖1所示。將多無(wú)人機(jī)系統(tǒng)建模為動(dòng)態(tài)可學(xué)習(xí)的有向?qū)蛹?jí)網(wǎng)絡(luò),該網(wǎng)絡(luò)被定義為包含了多組領(lǐng)導(dǎo)者-追隨者樹(shù)的森林。每棵樹(shù)可以表示為節(jié)點(diǎn)和有向邊的集合,其中N代表節(jié)點(diǎn)集合,E代表有向邊集合。每個(gè)節(jié)點(diǎn)代表了一個(gè)無(wú)人機(jī),有向邊則描述了無(wú)人機(jī)間的領(lǐng)導(dǎo)者-追隨者關(guān)系。通過(guò)限制意圖僅能沿著有向邊單向流動(dòng),有向?qū)蛹?jí)網(wǎng)絡(luò)保證了單邊的意圖分享,從而在一定程度上減少了信息傳遞過(guò)程中潛在的信息欺騙,并緩解了通信過(guò)程中的環(huán)境非穩(wěn)態(tài)問(wèn)題。
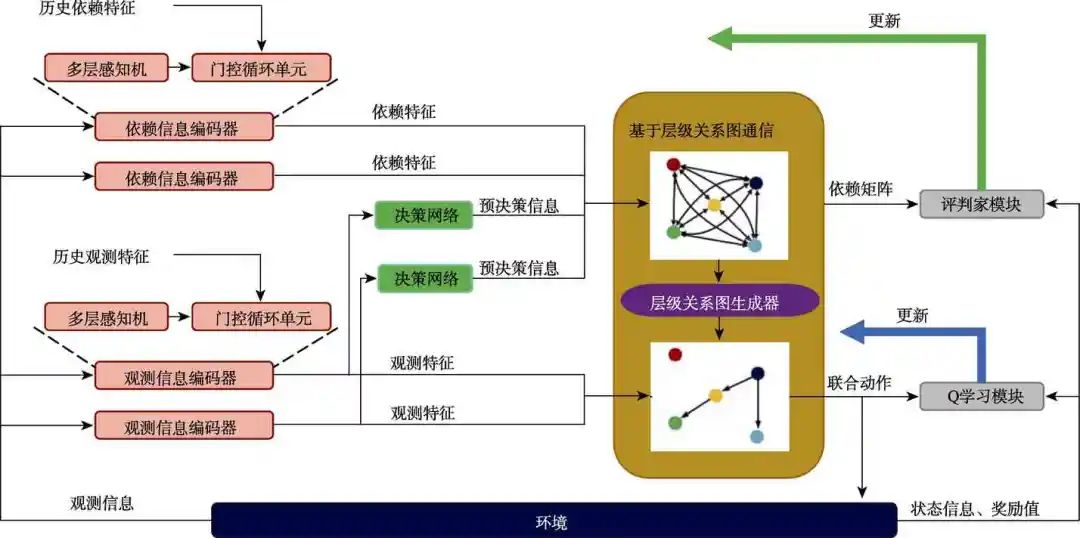
圖1 基于層級(jí)通信網(wǎng)絡(luò)的多無(wú)人機(jī)協(xié)同策略示意圖
Fig.1 Schematic diagram of multi-UAV cooperation strategy based on hierarchical communication network
在每個(gè)決策時(shí)間步,每個(gè)無(wú)人機(jī)收到各自的局部觀測(cè)信息后,經(jīng)過(guò)觀測(cè)信息編碼器和依賴信息編碼器,將其轉(zhuǎn)化為觀測(cè)特征和依賴特征。每個(gè)無(wú)人機(jī)根據(jù)其觀測(cè)特征進(jìn)行預(yù)決策,將預(yù)決策信息和依賴特征進(jìn)行融合,利用融合特征計(jì)算無(wú)人機(jī)間的相關(guān)性,獲得帶權(quán)重的全連接圖。之后,基于最小生成樹(shù)算法的層級(jí)關(guān)系圖生成器將帶權(quán)重的全連接圖轉(zhuǎn)化為能夠表示無(wú)人機(jī)間領(lǐng)導(dǎo)者-追隨者的有向?qū)蛹?jí)關(guān)系圖。根據(jù)生成的有向?qū)蛹?jí)關(guān)系圖,無(wú)人機(jī)根據(jù)其領(lǐng)導(dǎo)的決策信息依次做出決策,并將其意圖信息分享給追隨無(wú)人機(jī),直至所有的無(wú)人機(jī)均做出決策。多無(wú)人機(jī)執(zhí)行聯(lián)合動(dòng)作并與環(huán)境交互,獲得團(tuán)隊(duì)獎(jiǎng)勵(lì),并將狀態(tài)、動(dòng)作、下時(shí)刻狀態(tài)、獎(jiǎng)勵(lì)、預(yù)決策等信息存入經(jīng)驗(yàn)回放池。
訓(xùn)練時(shí),將多無(wú)人機(jī)系統(tǒng)視為一個(gè)整體,使用單無(wú)人機(jī)的訓(xùn)練方法優(yōu)化聯(lián)合動(dòng)作價(jià)值函數(shù)及層級(jí)通信網(wǎng)絡(luò)。聯(lián)合動(dòng)作價(jià)值函數(shù)是由各個(gè)無(wú)人機(jī)的觀測(cè)動(dòng)作值函數(shù)加和計(jì)算得到的,因此不僅可以適應(yīng)動(dòng)態(tài)變化的無(wú)人機(jī)數(shù)目及異構(gòu)的多智能體類型,保證算法的可擴(kuò)展性,同時(shí)由于所有無(wú)人機(jī)使用團(tuán)隊(duì)獎(jiǎng)勵(lì),可以更好地實(shí)現(xiàn)多無(wú)人機(jī)的協(xié)作任務(wù)。具體的,根據(jù)每個(gè)無(wú)人機(jī)的狀態(tài)-動(dòng)作函數(shù)值及其執(zhí)行動(dòng)作,利用線性值分解網(wǎng)絡(luò)計(jì)算團(tuán)隊(duì)狀態(tài)-動(dòng)作值,使用 Q學(xué)習(xí)模塊完成智能體策略的更新。另一方面,根據(jù)無(wú)人機(jī)策略在通信前后的不確定性變化及環(huán)境獎(jiǎng)勵(lì),設(shè)計(jì)內(nèi)在通信獎(jiǎng)勵(lì),基于深度確定性梯度下降方法,實(shí)現(xiàn)對(duì)動(dòng)態(tài)有向?qū)蛹?jí)關(guān)系圖的訓(xùn)練。算法1展示了基于層級(jí)通信網(wǎng)絡(luò)的多無(wú)人機(jī)強(qiáng)化學(xué)習(xí)算法的完整流程。該算法能夠解決由于可能的信息欺騙所導(dǎo)致的錯(cuò)誤合作,同時(shí)單邊通信在一定程度上減少了通信次數(shù),提升了基于通信的多無(wú)人機(jī)強(qiáng)化學(xué)習(xí)算法的性能。
3 基于動(dòng)態(tài)層級(jí)通信的多無(wú)人機(jī)協(xié)同策略
3.1 層級(jí)通信網(wǎng)絡(luò)與單邊意圖分享
根據(jù)無(wú)人機(jī)智能體間的相互依賴關(guān)系,可以使用基于最小生成樹(shù)的有向圖生成算法,實(shí)現(xiàn)全連接圖向?qū)蛹?jí)通信網(wǎng)絡(luò)的轉(zhuǎn)變。首先,基于依賴矩陣 d
w計(jì)算每個(gè)節(jié)點(diǎn)的流入流出值,即無(wú)人機(jī)的相對(duì)依賴程度

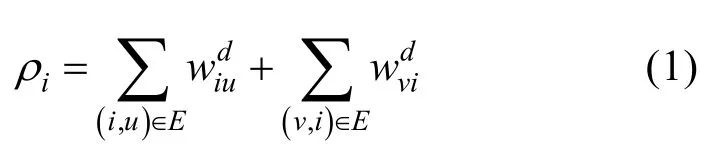
式中,u,v是除去 i以外的其他節(jié)點(diǎn)。由于我們采用了軟性注意力機(jī)制計(jì)算依賴矩陣,因此實(shí)際上
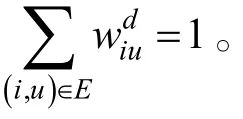
根據(jù)無(wú)人機(jī)相對(duì)依賴程度,我們可以選出更適合作為領(lǐng)導(dǎo)者的無(wú)人機(jī):相對(duì)依賴程度越大,其越能影響其他無(wú)人機(jī)的決策,而越不受到其他無(wú)人機(jī)的影響。
基于最小生成樹(shù)算法,本文提出了層級(jí)通信網(wǎng)絡(luò)生成算法。首先,根據(jù)無(wú)人機(jī)的相對(duì)依賴程度ρi選出最大值對(duì)應(yīng)的無(wú)人機(jī)作為根節(jié)點(diǎn),將其建立在有向圖中。之后,找到在 w d中擁有最大的邊權(quán)重wij的無(wú)人機(jī)i,其中 i ∈ N r = ( N /Nnew),j∈N n ew。判斷wij是否為從無(wú)人機(jī)i流出的最大邊。如果是,則將其建立在有向圖中,作為無(wú)人機(jī) j的子節(jié)點(diǎn);如果不是,則拒絕該節(jié)點(diǎn)的加入,再?gòu)奈词褂玫臒o(wú)人機(jī)集合Nr中,根據(jù)無(wú)人機(jī)的相對(duì)依賴程度ρi選出最大的值對(duì)應(yīng)的無(wú)人機(jī)作為根節(jié)點(diǎn)。重復(fù)上述操作,直至所有的無(wú)人機(jī)均被建立在有向圖中,并生成最終的層級(jí)通信網(wǎng)絡(luò)。同時(shí),如果無(wú)人機(jī)的組數(shù),即層級(jí)有向圖的樹(shù)木棵樹(shù)是給定的,我們可以使用Top(k)方法直接選取n個(gè)根節(jié)點(diǎn),且不使用拒絕機(jī)制,從而簡(jiǎn)化樹(shù)的建立過(guò)程。級(jí)通信網(wǎng)絡(luò)生成具體步驟如算法 2所示。在實(shí)際執(zhí)行過(guò)程中,我們可以根據(jù)實(shí)際通信所需時(shí)間計(jì)算出層級(jí)網(wǎng)絡(luò)中樹(shù)的最大深度d,將超過(guò)此深度的節(jié)點(diǎn)進(jìn)行剪枝,將其掛在前d層的父節(jié)點(diǎn)上,以此實(shí)現(xiàn)帶有深度約束的層級(jí)通信網(wǎng)絡(luò),滿足通信時(shí)間需求。

在通信過(guò)程中,無(wú)人機(jī)收到由其他無(wú)人機(jī)的觀測(cè)信息h-i和意圖信息u-i組成的通信信息mi。之后,無(wú)人機(jī)通過(guò)一個(gè)自注意力模型,將來(lái)自其他無(wú)人機(jī)的觀測(cè)信息進(jìn)行選擇性接收,獲得融合觀測(cè)信息

式中, w isj表示自注意力模型中無(wú)人機(jī)i對(duì)無(wú)人機(jī)j發(fā)送的信息占融合觀測(cè)信息的權(quán)重。同時(shí),無(wú)人機(jī)根據(jù)其在層級(jí)關(guān)系圖中的層數(shù),獲取其領(lǐng)導(dǎo)者的決策信息
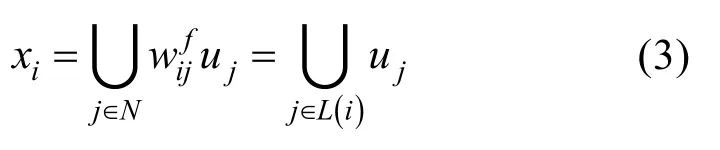
式中,L(i)表示無(wú)人機(jī)i的領(lǐng)導(dǎo)人,即其在層級(jí)通信網(wǎng)絡(luò)中的所有祖先節(jié)點(diǎn)。最終,無(wú)人機(jī)根據(jù)自身觀測(cè)信息及聚合信息 a ggri =[c i , xi ]做出最終決策
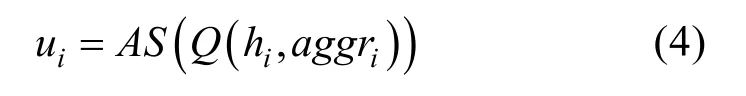
最終,無(wú)人機(jī)i將其意圖信息發(fā)送給其追隨者,并在當(dāng)前決策步中保持不變。循環(huán)此過(guò)程,直至所有的無(wú)人機(jī)都完成了通信任務(wù)。
3.2 條件狀態(tài)-行為值分解及策略網(wǎng)絡(luò)訓(xùn)練
在線性值分解網(wǎng)絡(luò) VDN和單調(diào)值分解網(wǎng)絡(luò)QMIX等SOTA效用分配算法中,由于相對(duì)過(guò)度泛化問(wèn)題,其在部分任務(wù)的性能極差。在博弈論中,相對(duì)過(guò)度泛化問(wèn)題是指當(dāng)聯(lián)合行動(dòng)空間中的次優(yōu)納什均衡優(yōu)于最優(yōu)納什均衡。在該狀態(tài)下,次優(yōu)均衡中每個(gè)智能體的行動(dòng)與合作智能體的任意行動(dòng)組成的聯(lián)合動(dòng)作均為最優(yōu)動(dòng)作,從而導(dǎo)致無(wú)人機(jī)學(xué)習(xí)及協(xié)作的失敗。
解決該問(wèn)題的一個(gè)思路是引入無(wú)人機(jī)的策略信息,即使用無(wú)人機(jī)的動(dòng)作信息減少環(huán)境的非穩(wěn)態(tài)性,利用一種集中式的訓(xùn)練方式來(lái)尋找正確的全局最優(yōu)點(diǎn)。在我們的方法中,由于使用了層級(jí)有向的意圖分享,追隨者能夠獲得其領(lǐng)導(dǎo)者的策略信息,進(jìn)而生成條件狀態(tài)-行為函數(shù)值。于是,基于條件狀態(tài)-行為函數(shù)值的線性分解網(wǎng)絡(luò)
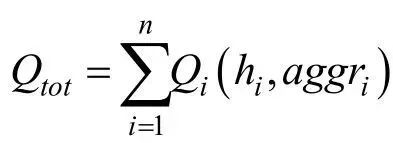
可以減少由于其他無(wú)人機(jī)變化策略帶來(lái)的環(huán)境非穩(wěn)態(tài)問(wèn)題。
層級(jí)通信網(wǎng)絡(luò)的結(jié)構(gòu)在策略生成過(guò)程中也起到了至關(guān)重要的作用。層級(jí)通信網(wǎng)絡(luò)控制了無(wú)人機(jī)的領(lǐng)導(dǎo)者,即影響了其接收到的其他無(wú)人機(jī)策略信息。同時(shí),層級(jí)通信網(wǎng)絡(luò)的生成過(guò)程中失去了訓(xùn)練所需要的梯度,但具有梯度的輸入依賴矩陣 w d 和層級(jí)通信網(wǎng)絡(luò) w f之間是多對(duì)一的關(guān)系。因此,我們將層級(jí)通信網(wǎng)絡(luò) w f視為一個(gè)偏置項(xiàng),同時(shí)利用集中式訓(xùn)練的優(yōu)勢(shì),結(jié)合環(huán)境的真實(shí)狀態(tài)信息,以此提高訓(xùn)練的穩(wěn)定性。于是,策略的更新式可以寫(xiě)作
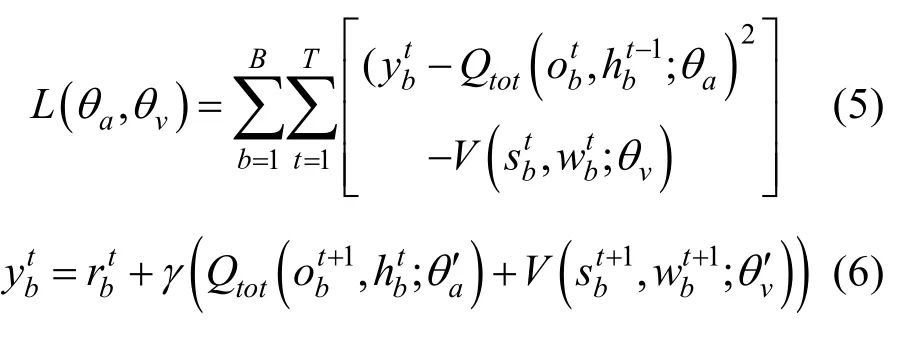
式中,?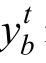 表示聯(lián)合狀態(tài)-動(dòng)作目標(biāo)值,V表示層級(jí)關(guān)系網(wǎng)絡(luò)的值函數(shù),B表示批采樣得到的軌跡總數(shù),b表示批采樣中的軌跡標(biāo)識(shí),T表示當(dāng)前軌跡的時(shí)間步總數(shù),t表示強(qiáng)化學(xué)習(xí)時(shí)間步,γ表示獎(jiǎng)勵(lì)折扣因子,
表示聯(lián)合狀態(tài)-動(dòng)作目標(biāo)值,V表示層級(jí)關(guān)系網(wǎng)絡(luò)的值函數(shù),B表示批采樣得到的軌跡總數(shù),b表示批采樣中的軌跡標(biāo)識(shí),T表示當(dāng)前軌跡的時(shí)間步總數(shù),t表示強(qiáng)化學(xué)習(xí)時(shí)間步,γ表示獎(jiǎng)勵(lì)折扣因子,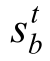 表示t時(shí)刻環(huán)境狀態(tài), w bt表示智能體間的有向圖關(guān)系,θa表示智能體網(wǎng)絡(luò)參數(shù),θv表示層級(jí)關(guān)系網(wǎng)絡(luò)的值函數(shù)網(wǎng)絡(luò)參數(shù),θa′表示智能體網(wǎng)絡(luò)目標(biāo)參數(shù),θv′表示層級(jí)關(guān)系網(wǎng)絡(luò)的值函數(shù)目標(biāo)網(wǎng)絡(luò)參數(shù)。
表示t時(shí)刻環(huán)境狀態(tài), w bt表示智能體間的有向圖關(guān)系,θa表示智能體網(wǎng)絡(luò)參數(shù),θv表示層級(jí)關(guān)系網(wǎng)絡(luò)的值函數(shù)網(wǎng)絡(luò)參數(shù),θa′表示智能體網(wǎng)絡(luò)目標(biāo)參數(shù),θv′表示層級(jí)關(guān)系網(wǎng)絡(luò)的值函數(shù)目標(biāo)網(wǎng)絡(luò)參數(shù)。
3.3 內(nèi)在獎(jiǎng)勵(lì)及層級(jí)通信網(wǎng)絡(luò)訓(xùn)練
為生成動(dòng)態(tài)變化的層級(jí)通信有向圖,我們需要使得其成為可訓(xùn)練的網(wǎng)絡(luò)。然而,在層級(jí)通信網(wǎng)絡(luò)的生成過(guò)程中,我們使用的最小生成樹(shù)方法無(wú)法實(shí)現(xiàn)梯度反傳。但是,如果給定了一個(gè)依賴矩陣 w d ,層級(jí)通信網(wǎng)絡(luò) w f是確定的。因此,我們可以將 w f視為經(jīng)過(guò)了動(dòng)作選擇器的動(dòng)作信號(hào),而其對(duì)應(yīng)的策略網(wǎng)絡(luò)輸出為 w d = a =φ(o)。該策略網(wǎng)絡(luò)將無(wú)人機(jī)觀測(cè)信息映射到依賴特征上。于是,層級(jí)通信網(wǎng)絡(luò)被建模為了一個(gè)強(qiáng)化學(xué)習(xí)過(guò)程,可以通過(guò)深度確定性梯度下降的方式進(jìn)行更新。
在學(xué)習(xí)過(guò)程中,我們需要獲得能夠指導(dǎo)更新大小和幅度的獎(jiǎng)勵(lì)信號(hào)。基于內(nèi)在獎(jiǎng)勵(lì)方法,我們?yōu)閷蛹?jí)通信網(wǎng)絡(luò)的訓(xùn)練設(shè)計(jì)了通信獎(jiǎng)勵(lì)。一方面,無(wú)人機(jī)在接收到其他無(wú)人機(jī)的意圖信息后,其策略的不確定性應(yīng)當(dāng)減小。我們使用無(wú)人機(jī)狀態(tài)-行為函數(shù)值最大的前兩項(xiàng)的方差作為無(wú)人機(jī)對(duì)自身決策信心的評(píng)價(jià)標(biāo)準(zhǔn)。因此,內(nèi)在獎(jiǎng)勵(lì)可以表示為通信前后所有無(wú)人機(jī)決策信心的變化
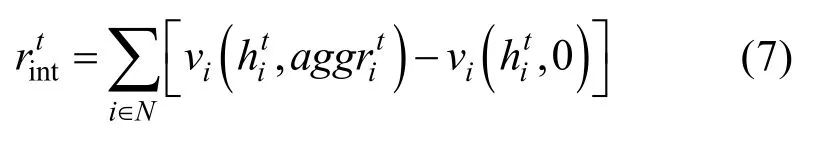
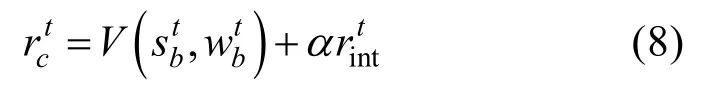
式中,α為調(diào)節(jié)內(nèi)在獎(jiǎng)勵(lì)和外在建立的權(quán)重因子。依賴矩陣的更新式為
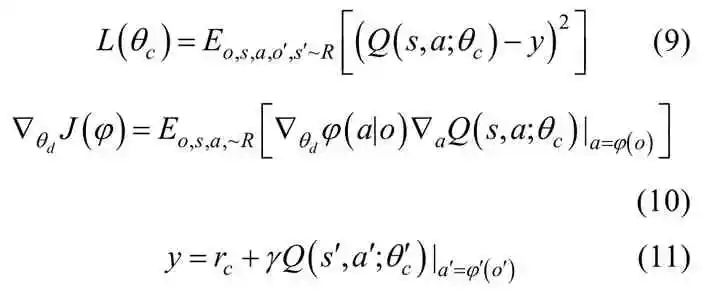
另一方面,層級(jí)通信網(wǎng)絡(luò)的最終目標(biāo)仍然是最大化無(wú)人機(jī)決策的累計(jì)回報(bào)。于是,我們可以最終獲得通信獎(jiǎng)勵(lì)
式中,Q表示層級(jí)關(guān)系網(wǎng)絡(luò)的狀態(tài)-動(dòng)作值,y表示層級(jí)關(guān)系網(wǎng)絡(luò)的狀態(tài)-動(dòng)作目標(biāo)值,cθ表示Critic網(wǎng)絡(luò)的參數(shù),cθ′表示Critic目標(biāo)網(wǎng)絡(luò)的參數(shù),dθ表示Actor網(wǎng)絡(luò)的參數(shù)。
4 多無(wú)人機(jī)協(xié)同場(chǎng)景設(shè)計(jì)及仿真驗(yàn)證
4.1 多無(wú)人機(jī)協(xié)同任務(wù)場(chǎng)景設(shè)計(jì)
本文針對(duì)多無(wú)人機(jī)協(xié)同圍捕場(chǎng)景,采用捕食者-被捕食者強(qiáng)化學(xué)習(xí)訓(xùn)練平臺(tái)對(duì)本文算法進(jìn)行仿真驗(yàn)證。捕食者-被捕食者仿真環(huán)境為一個(gè)部分可觀測(cè)多智能體協(xié)作任務(wù)環(huán)境,環(huán)境共初始化 8個(gè)捕食者(智能體)和8個(gè)被捕食者(獵物),分別模擬我方和敵方的無(wú)人機(jī)群。在該場(chǎng)景中,每個(gè)智能體的動(dòng)作空間中有“上移”“下移”“左移”“右移”“靜止”和“打擊”6個(gè)動(dòng)作,當(dāng)選擇移動(dòng)的目標(biāo)位置被其他智能體或獵物占領(lǐng)時(shí)所選的動(dòng)作會(huì)被判定為無(wú)效動(dòng)作,當(dāng)相鄰網(wǎng)格中沒(méi)有獵物時(shí)不可以選擇“打擊”動(dòng)作。環(huán)境中獵物隨機(jī)選取一個(gè)方向移動(dòng),當(dāng)4個(gè)相鄰網(wǎng)格都被其他智能體占領(lǐng)時(shí)保持靜止。每個(gè)智能體的觀測(cè)信息為以其所在位置為中心的5×5網(wǎng)格。兩個(gè)相鄰的智能體同時(shí)進(jìn)行“打擊”動(dòng)作,視為打擊成功,并獲得獎(jiǎng)勵(lì)值10,一個(gè)智能體單獨(dú)執(zhí)行“打擊”動(dòng)作則會(huì)受到懲罰p(p≤0)。實(shí)驗(yàn)?zāi)繕?biāo)為:通過(guò)8個(gè)捕食者無(wú)人機(jī)協(xié)同決策,完成對(duì)8個(gè)被捕食者無(wú)人機(jī)的全部打擊。當(dāng)所有被捕食者無(wú)人機(jī)都被成功“打擊”或達(dá)到200個(gè)時(shí)間步,則判定任務(wù)結(jié)束。基于上述場(chǎng)景,分別對(duì)本文算法和當(dāng)前主流通信強(qiáng)化學(xué)習(xí)算法進(jìn)行仿真驗(yàn)證,對(duì)比不同算法間的決策效果以及完成任務(wù)所需要的平均通信次數(shù)。
4.2 仿真結(jié)果
圖2給出了本文算法與基于通信的SOTA多無(wú)人機(jī)強(qiáng)化學(xué)習(xí)算法在捕食者-被捕食者平臺(tái)上的性能對(duì)比結(jié)果。在仿真測(cè)試中,分別取懲罰值p= -1、-1.25、-1.5和-2。可以看到,CommNet、TarMAC和GA-Comm隨著懲罰值p的減小而逐漸變得不穩(wěn)定,甚至在p= -2時(shí)完全無(wú)法完成任務(wù)。CommNet在 p≤-1.25后就開(kāi)始無(wú)法完成任務(wù),說(shuō)明冗余的通信信息可能會(huì)損害多智能體協(xié)作的性能。由于 NDQ使用互信息減小了環(huán)境的非穩(wěn)態(tài)問(wèn)題,因此具有學(xué)習(xí)到正確策略的潛力。雖然IS也進(jìn)行了意圖共享,但是其中的軟性注意力機(jī)制并無(wú)法讓其獲得準(zhǔn)確的智能體間關(guān)系,從而間接證明了任務(wù)中可能存在信息欺騙,且該問(wèn)題會(huì)導(dǎo)致算法的失效。作為對(duì)比,我們提出的算法在不同的環(huán)境設(shè)置下均能很快學(xué)習(xí)到正確的策略并保持穩(wěn)定,證明了基于層級(jí)通信的網(wǎng)絡(luò)結(jié)構(gòu)的有效性。
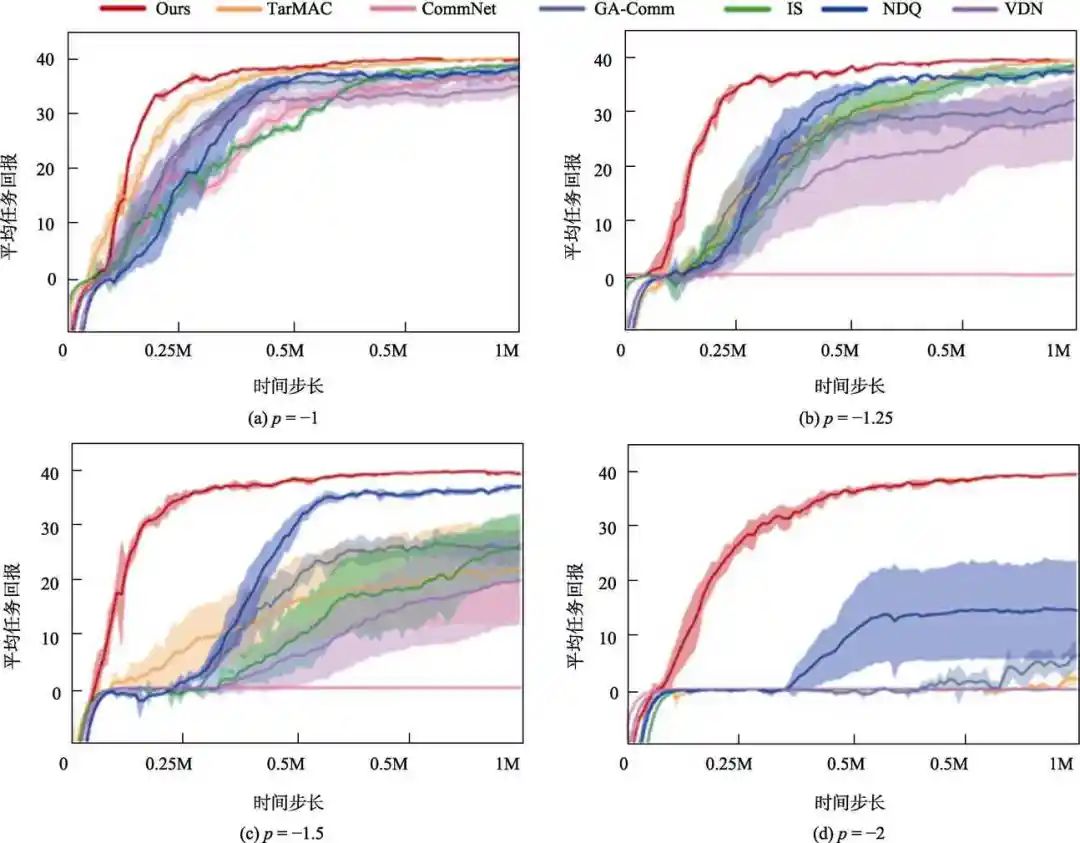
圖2 不同基于通信的多智能體強(qiáng)化學(xué)習(xí)算法的性能對(duì)比
Fig.2 Performance comparison of different communication based multi-agent reinforcement learning algorithms
進(jìn)一步地,將本文提出的算法與其他預(yù)先設(shè)定好的通信拓?fù)浣Y(jié)構(gòu)或關(guān)系生成算法進(jìn)行對(duì)比。設(shè)置任務(wù)場(chǎng)景的懲罰值p= -2.25,結(jié)果如圖3所示。可以看到,現(xiàn)有的關(guān)系生成算法均不能快速地學(xué)會(huì)最優(yōu)策略,而預(yù)設(shè)的拓?fù)浣Y(jié)構(gòu)Line則能夠快速地學(xué)習(xí)到正確的策略。與之相比,本文算法在算法前期上升較慢,這是由于算法需要學(xué)習(xí)合適的層級(jí)通信網(wǎng)絡(luò),這一過(guò)程較為復(fù)雜和耗時(shí)。但是,在算法后期的收斂狀態(tài),能夠看到本文學(xué)習(xí)算法性能優(yōu)于預(yù)設(shè)拓?fù)浣Y(jié)構(gòu)。同時(shí),本文算法可以實(shí)現(xiàn)稀疏通信,比預(yù)設(shè)的Line型拓?fù)浣Y(jié)構(gòu)運(yùn)行效率更高,能夠高效、準(zhǔn)確地完成任務(wù)。
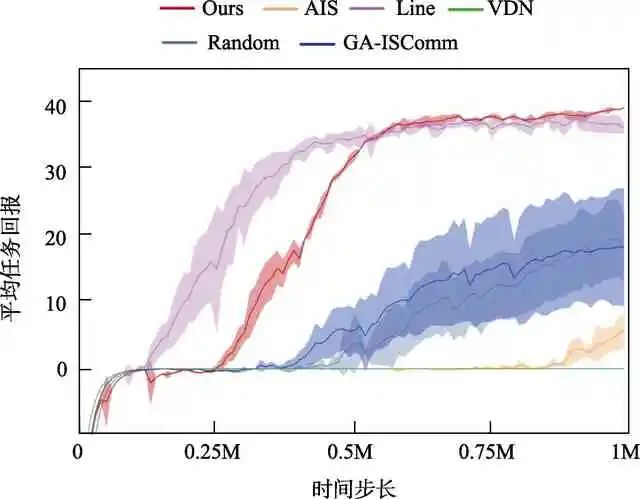
圖3 不同通信拓?fù)浣Y(jié)構(gòu)對(duì)意圖分享的影響Fig.3 Influence of different communication topologies on intention sharing
此外,在仿真環(huán)境下分別進(jìn)行 20輪獨(dú)立試驗(yàn),得到完成任務(wù)過(guò)程中本文提出的層級(jí)通信結(jié)構(gòu)和傳統(tǒng)兩兩通信結(jié)構(gòu)下的平均通信次數(shù),如表1所示。結(jié)果表明,本文的動(dòng)態(tài)層級(jí)通信結(jié)構(gòu)的平均通信次數(shù)為 5.8次,傳統(tǒng)兩兩通信結(jié)構(gòu)的平均通信次數(shù)為25.9次,本文提出的基于動(dòng)態(tài)層級(jí)通信結(jié)構(gòu)的多無(wú)人機(jī)協(xié)同策略完成任務(wù)需要的平均通信次數(shù)減少約77%。
表1 不同通信拓?fù)浣Y(jié)構(gòu)下的平均通信次數(shù)Table 1 Average communication times under different communication topologies

5 結(jié)束語(yǔ)
本文針對(duì)通信受限環(huán)境中的多無(wú)人機(jī)協(xié)同決策問(wèn)題,提出一種基于動(dòng)態(tài)層級(jí)網(wǎng)絡(luò)通信架構(gòu)的通信強(qiáng)化學(xué)習(xí)協(xié)同策略。通過(guò)將多無(wú)人機(jī)系統(tǒng)建模為層級(jí)通信網(wǎng)絡(luò),提升無(wú)人機(jī)對(duì)全局狀態(tài)的信念;在此基礎(chǔ)上引入線性值分解網(wǎng)絡(luò),實(shí)現(xiàn)更為準(zhǔn)確的效用分配。針對(duì)多無(wú)人機(jī)協(xié)同圍捕場(chǎng)景的仿真結(jié)果表明,與傳統(tǒng)強(qiáng)化學(xué)習(xí)算法相比,本文提出的通信強(qiáng)化學(xué)習(xí)策略可以顯著減少無(wú)人機(jī)間的通信次數(shù),同時(shí)在一定程度上避免潛在的信息欺騙問(wèn)題,完成任務(wù)需要的平均通信次數(shù)相比于傳統(tǒng)兩兩通信結(jié)構(gòu)減少約77%。本文所提出的基于動(dòng)態(tài)層級(jí)網(wǎng)絡(luò)通信架構(gòu)的多無(wú)人機(jī)通信強(qiáng)化學(xué)習(xí)協(xié)同算法可為通信受限環(huán)境中的多無(wú)人機(jī)協(xié)同任務(wù)提供技術(shù)支撐,未來(lái)將考慮把該算法遷移到物理環(huán)境以驗(yàn)證其在真實(shí)場(chǎng)景中的有效性,并進(jìn)一步探索其在體系化作戰(zhàn)決策方面的應(yīng)用可能。另一方面,本文尚未對(duì)通信拒止環(huán)境下的多無(wú)人機(jī)協(xié)同策略進(jìn)行探討,未來(lái)將考慮開(kāi)展基于隱式信息共享的協(xié)同方法研究,進(jìn)一步探索通信拒止環(huán)境下的多無(wú)人機(jī)協(xié)同策略與方法。
?
?
編輯:黃飛
?











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論