 電子發燒友App
電子發燒友App


支持向量機的車牌定位設計方法
1 引 言
????? 智能交通系統是一個熱點研究領域,受到日益廣泛的關注。車牌識別系統(LPR)是計算機視覺、模式識別技術在智能交通領域的一個重要應用,包括車牌定位、車牌字符分割、字符識別三部分。其中車牌定位是整個系統中的關鍵步驟。
目前車牌定位方法主要有:
??????? (1)基于Hough變換的方法,分析車牌具有明顯的矩形邊框,利用Hough變換檢測區域邊界實現定位。
??????? (2)基于邊緣檢測的方法,利用了車牌字符邊緣豐富的特征,結合數學形態學或區域生長方法實現牌照定位。
?????? (3)基于神經網絡的方法,利用圖像的顏色或紋理特征訓練神經網絡,然后用訓練好的分類器對圖像各個像素進行分類,再對分類結果綜合,得到牌照的準確定位。然而由于光照不均、污染等因素影響,可能使得牌照區域邊界不明顯或存在多個干擾區域,從而增加了準確定位的難度。
??????? 要提高車牌定位的精度,應充分利用他自身提供的信息,突出車牌區域而抑制非車牌區域。車牌區域有著豐富的紋理,尋找一種良好性能的分類器,凸現這種紋理特征,使他與其他區域區別開來。支持向量機(Support Vector Machine,SVM)正是這樣一種分類學習機制,建立在結構風險最小化(Structural Risk Minimization,SRM)準則之上,已經在文本識別,人臉識別,紋理分類等模式識別領域取得了成功。
??????? 本文使用SVM機制自動定位車牌區域,首先對每幅訓練圖像切分成若干個N×N大小的圖像子塊,把每個字塊分別標注為車牌和非車牌區域兩類,提取子塊圖像的特征向量訓練SVM分類器;然后使用該分類器對測試圖像中的各個像素進行分類,最后通過后期處理結合車牌的先驗知識實現車牌區域的定位。
??????? 2 SVM原理
??????? SVM基于SRM準則構造最優超平面,使每類數據之間間隔最大,同時保持分類誤差盡可能小。Cover定理指出:一個復雜的模式識別分類問題,在高維空間比低維空間更容易線性可分。實際上SVM實現了這樣的思想:通過某種事先選擇的非線性映射將向量x映射到一個高維特征空間,然后在這個空間中構造最優分類超平面。
??????? 對于兩類模式分類問題,在非線性可分的情況下,通過一個非線性變換φ:x→φ (x),將給定的模式數據映射到高維特征空間,再構造分類超平面,表示為決策面:
|
|
?????? 考慮到兩類樣本離決策面都應有一定距離,決策面應滿足不等式約束:
|
|
??????? 完全滿足式(2)的超平面是不存在的。考慮到存在一些樣本不能被決策面正確分類,引入松弛變量ξi(≥0),約束條件式(2)變為:
|
|
???? 滿足要求的超平面不止一個,尋找最優超平面可以歸結為二次規劃問題:
|
|
????? 其中C被稱為懲罰因子,通過C可以在分類器的泛化能力和誤分率之間進行折衷。利用拉格朗日函數求解可得優化問題(4)的對偶形式,最大化函數:
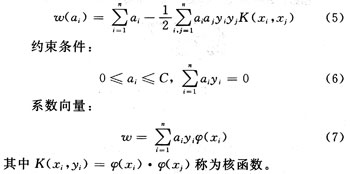 |
?????? 求解式(5)可以得到ai,代入式(7)可以確定ω,分類函數可表示為:
|
|
?????? 3 SVM定位車牌區域
?????? 車牌區域準確定位是一種非線性可分的模式分類問題。
?????? 3.1 特征提取
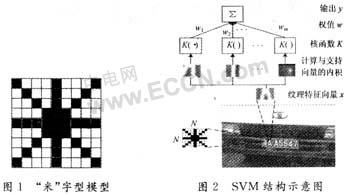
??????? 利用SVM自身結構可以實現有效的特征提取,選擇直接提取像素灰度特征。圖像像素點之間不是孤立的,相互之間存在著相關性,體現了一種紋理。可以通過提取一些特定像素的灰度值作為整幅圖像的特征,同時減少了計算量。首先將每幅圖像切割成若干個N×N子塊,再將每一子塊標注為牌照區域(+1)和非牌照區域(-1)兩類,然后使用圖1所示“米”字型模型提取像素灰度值(圖中陰影為要提取的像素點)。這樣每幅子圖的特征維數由N×N減少到4N-3,提高了訓練和分類速度。
????? 3.2 SVM分類器
?????? SVM分類器分為三層結構,結構示意見圖2。輸入層的維數為子圖的特征維數4N-3,輸入值是灰度值。隱含層的維數是由訓練獲得的支持向量決定,即由訓練階段自動獲得,而且二次規劃在凸集下的解是全局最優解,避免陷入局部最小。隱含層計算輸入向量與支持向量之間的內積,完成非線性映射,通過核函數一步來實現的。輸出層的輸出就是對隱層的輸出與權值ωi的乘積求和,權值aiyi也是在訓練中獲得的。
 |
?????? SVM中研究最多的核函數主要有三類:多項式、徑向基函數(RBF)和多層Sigmoid神經網絡。實驗中使用的是多項式核函數,形式為:
|
|
?????? 作為一種基于樣本學習的方法,我們希望訓練樣本集盡可能地大,以獲得比較充分的代表性。然而考慮到實際的限制,這個尺寸又必須是適中的。因此,問題就是如何構造一個全面又可行的訓練樣本集。對于車牌定位問題,所有包含牌照區域的圖像可以作為正樣本,困難點是收集負樣本,因為實際上存在太多的不包含牌照的圖像可以作為負樣本。如何在這些圖像中選取具有代表性的子集,實驗中采用了一種叫“自舉”(bootstrap)的方法,他已被Sung和Poggio成功地應用于人臉識別。主要思想就是一些負樣本(非牌照)是在訓練中獲得而不是在訓練以前,具體實現步驟如下:
?????? (1)建立包含正樣本(牌照區域)和負樣本(非牌照區域)的訓練集合N1;
?????? (2)用N1訓練SVM;
?????? (3)用訓練好的SVM分類器對隨機選取的非牌照樣本進行分類測試,收集那些被錯分為牌照的樣本;
?????? (4)隨機選取20%的錯分類樣本加入到訓練集N1;
?????? (5)重復(2)~(4)步直至沒有再發現錯分的樣本;
?????? (6)使用最終獲得的N1訓練SVM。
?????? 圖3顯示了一些用于訓練的樣本。
?????? 最后,用訓練好的SVM分類器掃描全圖,根據輸出類別,對每個N×N小窗口的中心像素做出判斷。如果輸出+1就認為他是牌照區域,賦值為255;否則,則認為他不是牌照區域,賦值為0。如圖4(a)所示。
?????? SVM通過訓練選擇對分類超平面起決定作用的支持向量,就像選擇了一組特定的濾波器,突出了牌照區域。在SVM分類器中濾波器的數目和系數是在訓練中自動獲得的。
 |
?????? 3.3 分割牌照區域
?????? 對每個像素做出分類判斷后,得到一個二值圖像,還必須進行一些處理,其目的是合并感興趣區域和去除噪聲。本文采用數學形態學對二值圖像進行處理,在此基礎之上再做水平和垂直兩個方向的投影,最后,根據投影并結合車牌自身的一些先驗知識,如長寬比、車牌的字符數、字符間距,實現牌照區域的定位。分割過程主要包括以下幾個步驟:
?????? (1)首先訓練SVM分類器,用他掃描圖像,對像素進行分類,獲得分類后的二值圖像。
?????? (2)應用數學形態學方法對分類結果所得圖像進行處理、去除噪聲。
?????? (3)再對圖像做水平投影和高斯迭代平滑處理。
?????? (4)確定牌照水平區域:在平滑處理后的水平投影圖中,獲取峰值點以及與這些峰值點最接近的左右側谷值點,由左右側谷值點確定一個水平區域的高度g,峰值大于車牌最小寬度F時,該區域是車牌可能所在的水平區域。其中:F=Rmin×g,Rmin為標準車牌寬高比的最小值。
?????? (5)確定牌照垂直區域:對于車牌可能所在的水平區域進行垂直投影(同樣采取高斯疊代平滑),由垂直投影圖將水平區域分成一塊塊較小的區域,計算出最大字符間距D,將間距小于等于D的區域合并。其中:D=Tmax×Rmax×g,Rmax為標準車牌寬高比的最大值,Tmax為標準車牌最大字符間距與車牌寬度之比。合并后區域的寬高比大于Rmin的為車牌可能所在的區域。
?????? (6)牌照的確定與分割:根據標準車牌的字符個數和筆劃數的范圍,檢測各區域水平方向上的跳變化次數,若在該范圍內則認為該區域為車牌所在的區域,然后在含有牌照的原圖中切出與(4)中相應的區域。
?????? 4 實驗結果分析
?????? 實驗收集了200幅車牌圖像,任意選取100幅作為訓練樣本,還收集了一些不包含車牌的圖像作為自舉訓練方法的樣本。
?????? 程序使用Microsoft VC++6.0編寫。訓練和識別所用的圖像子塊尺寸N取15,特征數據歸一化在0~1之間。核函數多項式的次數d的值取5,SVM的懲罰因子C取100,訓練SVM的算法采用的是JohnC.Platt提出的序列最小優化算法。剩余100幅圖像作為測試樣本,其中能正確定位的有93幅,有7幅沒有正確定位。引起錯誤的原因主要有圖像中相似的字符區域過多或者圖像本身過于模糊,相似區域過多干擾了牌照區域,而圖像模糊則損失了牌照區域有用的紋理信息。實驗結果表明,SVM在小樣本下可以獲得較好的識別效果。
?????? 圖4給出了圖3(b)中示例圖像車牌定位過程,圖4(a)為經過SVM分類輸出的二值圖,圖4(b)為數學形態學濾波處理后的結果,圖4(c)為最終車牌定位結果。
 |
?????? 5 結 語
?????? 車牌定位是一種非線性可分問題,牌照區域包含了豐富的紋理信息,利用這個特征可以實現牌照區域的定位。本文使用SVM對含牌照的汽車圖像中像素進行分類,再經過數學形態學處理并結合牌照先驗知識實現定位。實驗表明該方法取得了較好的定位效果。










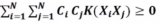






 工商網監
工商網監
評論