 電子發燒友App
電子發燒友App


imec 研究人員發現了有關“complementary FET”的新發現,這是一種適用于 1 nm 邏輯技術節點及以上節點的有吸引力的器件架構。
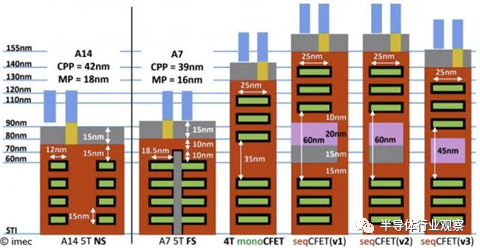
在 forksheet 場效應晶體管 (FET) 中,nFET 和 pFET 被集成到相同的結構中,并由絕緣壁(dielectric wall)隔開。這種方法導致金屬間距窄至 16 nm,這對于具有低軌道高度的高性能單元設計來說太低了。
imec 研究人員在其2022 年 VLSI 論文中強調了這一挑戰,介紹了一種complementary FET (CFET) 架構。他們還報告了改進的工藝流程如何使順序 CFET 比單片 CFET 更有前景。值得注意的是,該團隊認為這種forksheet器件架構可能會將納米片晶體管系列的可擴展性擴展到 1 nm 及以上的邏輯節點。

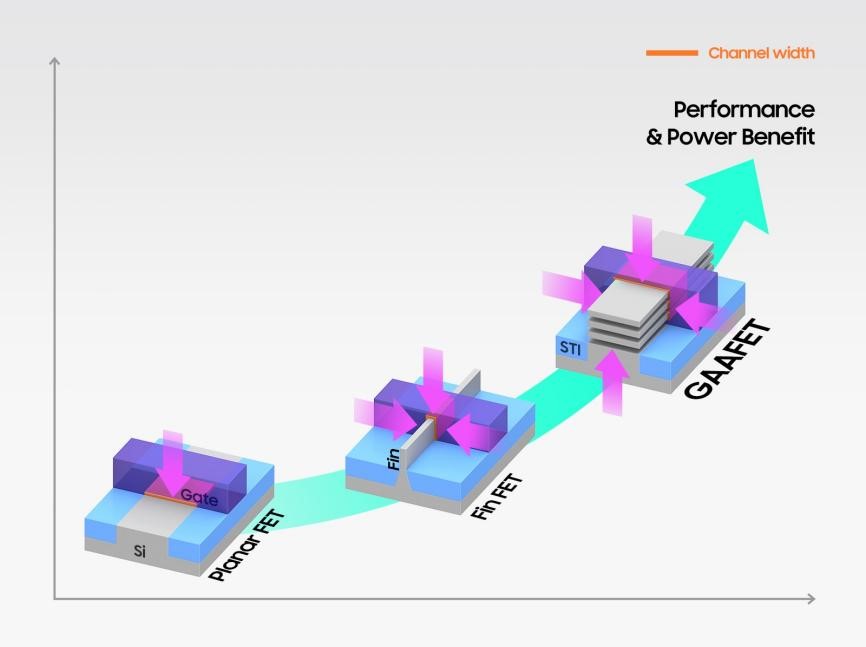
從 FinFET 到 nanosheet 到 forksheet 再到 CFET 的演變
從平面 FET 到 FinFET 的過渡
由于從平面 FET 過渡到 FinFET,晶體管尺寸減小了,而性能卻提高了。這種轉變是必要的,因為平面 FET 的性能在柵極長度減小時開始下降。FinFET 有助于維持擴展路徑。
在 FinFET 中,源極和漏極之間的溝道是 Fin 的形式。柵極纏繞在這個溝道周圍,從通道的三個側面施加控制。這種方法消除了平面 FET 遭受的短溝道效應。此外,更高的鰭片高度允許在相同區域內更高的器件驅動電流。
然而,隨著技術規模超過 5 nm,Fin 結構無法提供足夠的靜電控制。
imec 的擴展障礙解決方案:Forksheet 架構
為了實現進一步的縮放,imec 引入了一種垂直堆疊的納米片結構,其中柵極完全包裹在溝道周圍。據說這種架構提供了卓越的控制和更好的三維體積分布。
Forksheet 器件是垂直堆疊納米片的延伸。在這里,納米片由三柵極叉形結構控制,這是通過在 p 和 nFET 器件之間引入介電壁來實現的。隔離允許更緊密的 n 到 p 間距和更高的性能。隔離還將標準單元的軌道高度擴展到 4T,這意味著四個單元內金屬線可以適應標準單元高度的范圍。
然而,金屬間距的 n 區和 p 區之間的間距低至 16 nm,這對于 4T 軌道高度單元設計來說太窄了。為了最大化溝道寬度和驅動電流,imec 研究人員提出了 CFET 架構。
單片與順序
(Monolithic vs. Sequential)CFET
研究人員探索了兩種可能的集成方案來實現垂直堆疊:單片和順序。在 CFET 架構中,n 和 p 器件垂直堆疊在一起,消除了標準單元高度的 np 間距。
納米片、叉片 (FS) 和 CFET(單片和順序)的柵極橫截面
單片 CFET 流發生在三個部分:底部通道的外延生長、中間層的沉積以及頂部通道的外延生長。這種流程比順序流程更復雜,因為它會產生高縱橫比 (HAR) 垂直結構,需要進一步的圖案化。
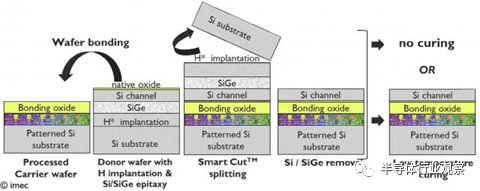
在順序制造流程中,底部器件被加工到觸點。然后,使用晶圓對晶圓鍵合技術在其頂部創建一個覆蓋半導體層。最后,集成頂層設備。這個過程更簡單,因為可以以二維方式單獨處理頂級設備。
3D 順序堆疊設備
這些過程中的每一個都有其優點和缺點。在 2022 年 VLSI 論文中,imec 研究人員提出了 4T 標準單元設計中單片 CFET 與順序 CFET 的功率性能面積成本 (PPAC) 評估。他們還評估了順序 CFET 的不同層轉移工藝。
從理論到實施
imec 報告說,從成本的角度來看,半導體制造商 SOITEC 提供了一種很有前途的層轉移工藝——一種依賴于低溫“智能切割”流程的工藝。它使用在低溫下分裂的工程體供體晶圓。研究人員發現,在概念驗證層轉移后處理的頂層設備從降低的電氣性能中恢復。

SOITEC 低溫智能切割層傳輸流程示意圖
imec 邏輯 CMOS 微縮計劃主管 Naoto Horiguchi 強調,雖然這種架構是真正的 CFET 架構,但它不是真正的 CFET 實現,因為底部器件中沒有金屬互連層。
他指出,imec 的測試工具展示了“改進的層傳輸作為順序 CFET 和其他 3D 順序堆疊實現的關鍵模塊”。在未來的研究中,imec 報告說,研究人員將致力于實現真正的順序 CFET。
1nm的關鍵技術,IMEC公布新進展
20 多年來,Cu 雙鑲嵌(dual-damascene)一直是構建可靠互連的主要工藝流程。但是,當尺寸繼續縮小并且金屬間距(metal pitches)變得像 20nm 及以下那樣緊密時,由于電阻電容 (RC) 產品的急劇增長,后端 (BEOL) 越來越受到 RC 延遲的影響。這個問題迫使互連行業尋找替代集成方案和在緊密金屬間距下具有更好品質因數的金屬。
大約五年前,imec 最初提出半鑲嵌(semi-damascene )作為銅雙鑲嵌的可行替代方案,用于集成 1nm(及以上)技術節點的最關鍵的局部 (Mx) 互連層。
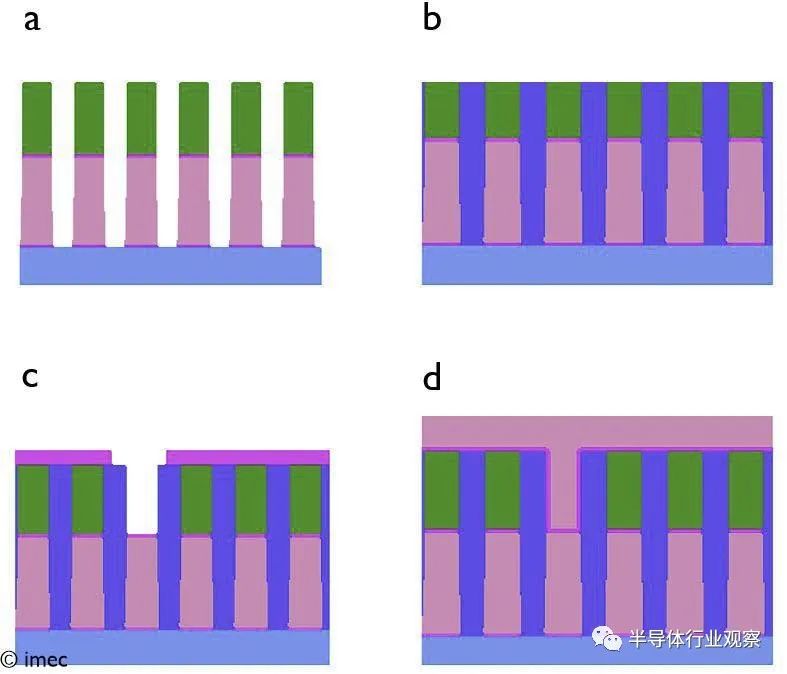
圖 1 – Imec 的半鑲嵌流程:a) Ru 蝕刻(底部局部互連線 (Mx) 的形成);b) 填空;c) 通過蝕刻;d) 通過填充和頂線 (Mx+1) 形成(如 VLSI 2022 所示)。
與雙鑲嵌不同,半鑲嵌集成依賴于互連金屬的直接圖案化來制作線條(稱為減材金屬化(subtractive metallization)),并且不需要金屬的化學機械拋光 (CMP) 來完成工藝流程。連接后續互連層的通孔以單鑲嵌方式(single-damascene fashion)圖案化,然后用金屬填充并過度填充( then filled with metal and overfilled)——這意味著金屬沉積會繼續進行,直到在電介質上形成一層金屬。然后對該金屬層進行掩膜和蝕刻(masked and etched)以形成具有正交線(orthogonal line)的第二互連層。
在金屬圖案化之后,線之間的間隙可以用電介質填充或用于在局部層處形成(部分)氣隙。請注意,在半鑲嵌流程中,一次性形成兩層(通孔和頂部金屬),就像傳統的雙鑲嵌一樣。當以雙鑲嵌進行基準測試時,這使其具有有效的成本競爭力(見圖 2)。
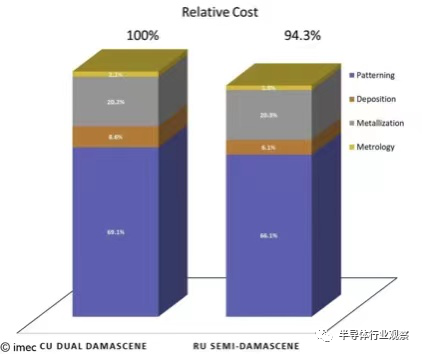
圖 2 - 18nm 金屬間距下半鑲嵌和雙鑲嵌成本的比較。
半鑲嵌集成流程的好處
與銅雙鑲嵌相比,半鑲嵌在緊密的金屬間距下具有多項優勢。Imec研究員兼 imec 納米互連項目總監Zsolt Tokei 表示:“首先,它允許更高的線路縱橫比,同時保持電容受到控制——有望帶來整體 RC 優勢。其次,沒有金屬 CMP 步驟導致更簡化和成本效益更高的集成方案。
最后,半鑲嵌集成需要無屏障(barrierless)、可圖案化的金屬,例如鎢 (W)、鉬 (Mo) 或釕 (Ru)。通過使用與銅不同,不需要金屬阻擋層的金屬,寶貴的導電區域可以被互連金屬本身充分利用,從而確保在縮放尺寸上具有競爭力的通孔電阻。” 當然,除了好處之外,在這樣的計劃獲得工業認可之前,還有許多挑戰需要解決。朝這個方向邁出的一步是實際演示雙金屬級方案。雖然僅通過仿真和建模顯示了這些好處,但 imec 首次為雙金屬級半鑲嵌模塊提供了實驗證據。
完全自對準的通孔——一個關鍵的構建塊
在小至 20nm 的金屬間距下,控制通孔降落在窄線上是半鑲嵌集成模塊成功運行的關鍵。當通孔和線路(在通孔頂部和底部)沒有正確對齊時,通孔和相鄰線路之間存在泄漏的風險。這些泄漏路徑是由小通孔的常規圖案化引起的過大覆蓋誤差造成的。
imec 技術人員的主要成員Gayle Murdoch說:“找到一種方法來制作功能性、完全自對準的通孔一直是半鑲嵌工藝的圣杯。
我們通過 imec 的集成、光刻、蝕刻和清潔團隊之間的密切合作實現了這一里程碑。通過我們完全自對準的集成方案,我們補償了高達 5nm 的重疊誤差——這是一項關鍵成就。”

圖 3 – 沿 Mx(左)和跨 Mx(右)的自對準通孔。X-TEM 顯示自對準通孔落在 18nm 間距 Ru 線上(如 VLSI 2022 所示)。
通過在間隙填充后選擇性去除氮化硅來確保底部自對準,從而允許在下部金屬線的范圍內形成通孔。朝向頂部金屬層 (Ru) 的自對準是通過 Ru 過度蝕刻步驟實現的,該步驟在通孔過度填充和 Ru 圖案化之后應用。
18nm 間距的良好電阻和可靠性——首次演示
使用具有完全自對準通孔的 Ru 減法蝕刻產生了 18nm 金屬間距的功能性雙金屬級器件。結合自對準雙重圖案化 (SADP) 的 EUV 光刻用于圖案化 9nm“寬”Ru 底部局部互連線 (Mx),而單次曝光 EUV 光刻用于印刷頂線 (Mx+1) 和通孔. 頂部金屬與氣隙相結合以抵消電容增加。
在將 Ru 與 Cu 的線路電阻與導電面積進行基準比較時,Ru 在目標金屬間距方面明顯優于 Cu。通過自對準在形態學和電學上都得到了證實。實現了出色的通孔電阻(26-18nm 金屬間距的范圍在 40 和 60Ω 之間),并且證明了 >9MV/cm 的通孔到線擊穿場。
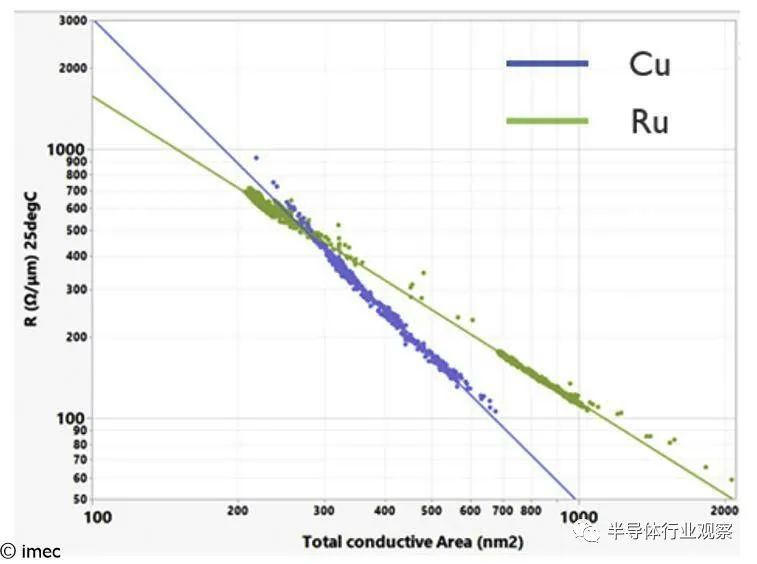
圖 4 – Ru 和 Cu 線的導電面積與線電阻的關系(如 VLSI 2022 所示)。
Zsolt Tokei:“我們展示了所有關鍵技術參數的卓越價值,包括通孔和線路電阻和可靠性。該演示表明,半鑲嵌是雙鑲嵌的一種有價值的替代方案,用于集成 1nm 技術節點及以后的前三個局部互連層。我們的具有完全自對準通孔的雙金屬層器件已被證明是關鍵的構建模塊。”
我們的演示表明,半鑲嵌是雙鑲嵌的一種有價值的替代方案,用于集成 1nm 技術節點及以后的前三個局部互連層。
通過增加線路的縱橫比(降低電阻)同時保持氣隙(控制電容),可以進一步改進。同時,imec 對使用半鑲嵌技術(允許在標準單元級別進一步減少面積)實施中線 (MOL) 和 BEOL 技術增強器有具體的想法。
Intel眼里的下一代晶體管,GAA的繼任者!
在近期舉辦的VLSI 技術和電路研討會上,專家們深入探討了最近的技術進步,并展望了將在不久的將來過渡到生產的研究工作。其中,來自英特爾組件研究小組的 Marko Radosavljevic 在題為“Advanced Logic Scaling Using Monolithic 3D Integration”的演講中提供了有關 3D 設備制造開發狀態的最新信息。
盡管仍有重大挑戰有待解決,但 Marko 提供了一個令人信服的觀點,即 3D 器件拓撲將成為新興的環柵(納米片/納米帶)器件的繼任者。
本文總結了 Marko 演講的亮點。
Marko 首先簡要回顧了導致當前 FinFET 器件和即將推出的 GAA 拓撲的最新工藝技術發展。下面的第一張圖列出了這些器件縮放特性,而下一張圖顯示了 FinFET 和 GAA 器件堆棧的橫截面圖。(圖中顯示了四個垂直納米片,用于相鄰的 nFET 和 pFET 器件。)
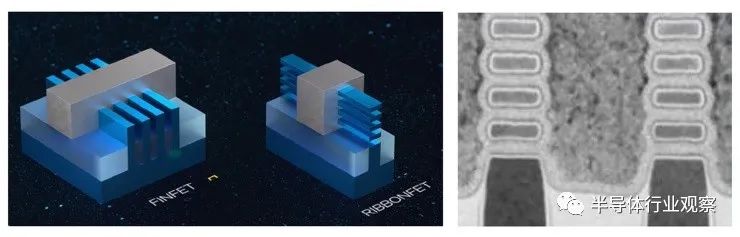
與 FinFET 的“三柵極”表面相比,GAA 拓撲改進了器件漏電流控制。(通常會集成額外的制程工程步驟,以減少最低納米片底部和襯底之間的器件柵極材料的襯底表面泄漏電流。)
此外,如下圖所示,GAA 光刻和制造在堆疊中納米片的寬度方面提供了一些靈活性。與 FinFET 器件的量化寬度 (w=(2*h)+t) 不同,設計人員在針對特定 PPA 目標優化電路方面將具有更大的靈活性。
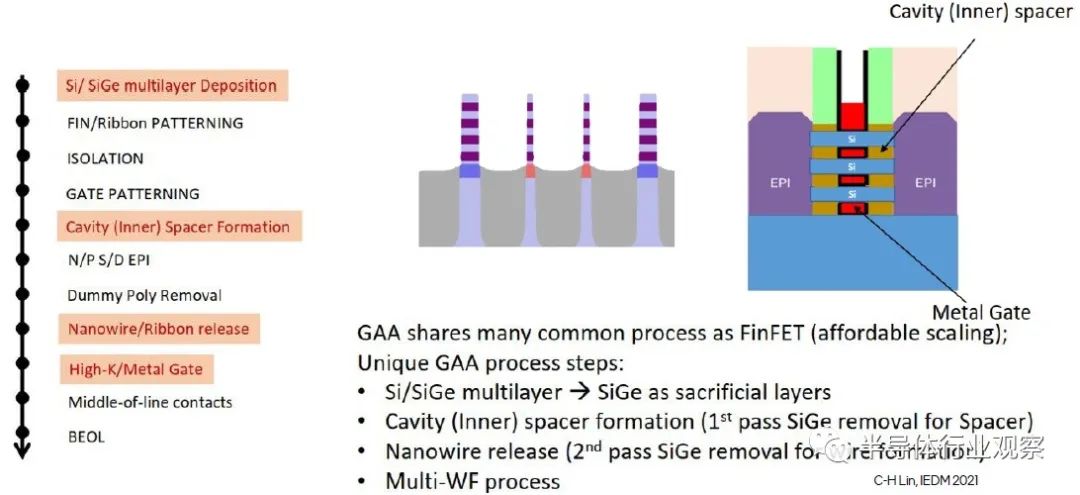
上圖還強調了一些 GAA 工藝挑戰,特別是與 FinFET 制造相比獨特的步驟:
初始 Si/SiGe 外延疊層
犧牲(sacrificial)SiGe的部分凹陷蝕刻,暴露Si層的末端以用于源極/漏極節點的外延生長
FinFET 還使用選擇性外延來擴展 S/D 節點——然而,鰭片已經暴露在柵極的任一側。GAA 器件需要對散布的 SiGe 層進行非常精確的橫向蝕刻,以在 S/D 外延之前暴露 Si 表面。
去除剩余的犧牲(sacrificial) SiGe 以“釋放”納米片表面(由 S/D Epi 支持)
在所有納米片表面上精確沉積柵極氧化物和周圍的柵極金屬
請注意,在上圖中,將沉積多種金屬柵極成分,以針對不同的器件 Vt 閾值提供不同的功函數表面電位。
3D 設備
在此背景下,Marko 分享了下圖,表明下一個工藝路線圖器件演變將是 3D 堆疊納米帶,利用在橫向 pFET 和 nFET 器件制造中獲得的工藝開發經驗。3D 堆疊器件通常表示為“CFET”(complementary ?FET)結構。
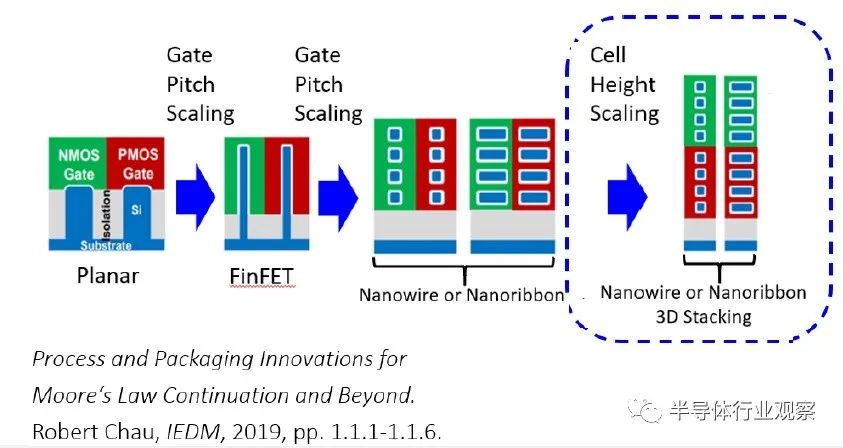
下圖說明了與橫向納米片布局相比,垂直器件堆疊能夠給邏輯單元和 SRAM 帶來顯著的微縮(a 1-1-1 device configuration for the transfer gate-pullup-pulldown in the 6T cell)。
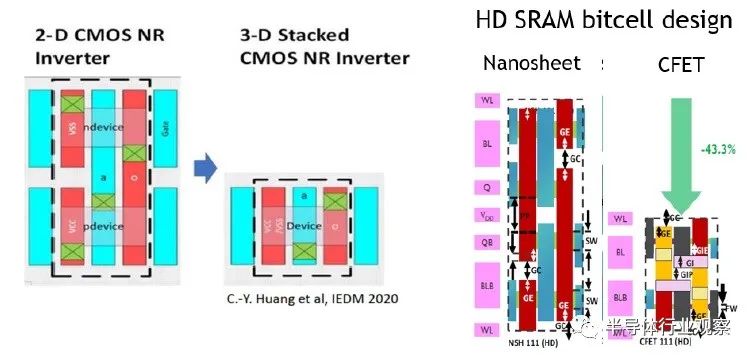
下圖擴展了上面的邏輯反相器(logic inverter)布局,以橫截面顯示器件。注意為器件提供 VDD 和 VSS 的埋入式電源軌 (BPR)。此外,請注意接觸蝕刻和金屬填充所需的重要縱橫比。
CFET 研發計劃
實際上,有兩種非常不同的 CFET 器件制造方法正在評估中——“順序”(sequential)和“單片”(monolithic,或自對準)。
1.順序 3D 堆疊
下圖說明了順序處理流程。首先制造底部器件,然后粘合(變薄的)襯底以制造頂部器件。氧化物介電層沉積并拋光在起始襯底上,用于鍵合工藝,并用作器件之間的電隔離。底部器件的存在限制了可用于頂部器件制造的熱預算。
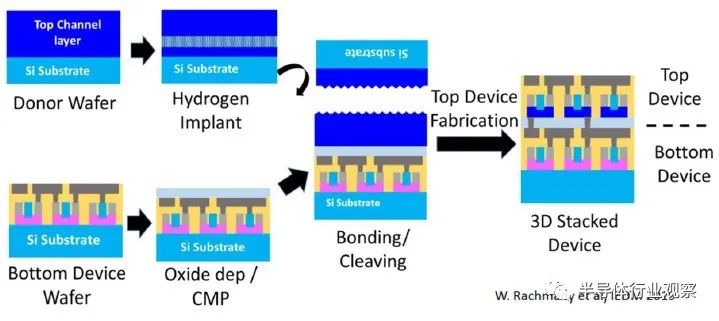
研究人員特別感興趣的是,這種方法為兩種器件類型提供了利用不同襯底材料(以及可能不同的器件拓撲)的機會。例如,下圖顯示了一個(頂部)pFET,它使用 Ge 襯底中的納米片器件制造,(底部)nFET 使用 FinFET 結構。

在上面的示例中,Ge 納米片中的 pFET 將使用 Ge/SiGe 層的起始堆疊制造,SiGe 再次用作源極/漏極生長和納米片釋放的犧牲支撐。與 Si 相比,該技術選項將利用 Ge 中更高的空穴遷移率。
分隔兩個器件層的鍵合電介質厚度是一個關鍵的工藝優化參數——薄層可降低寄生互連電阻和電容,但需要無缺陷。
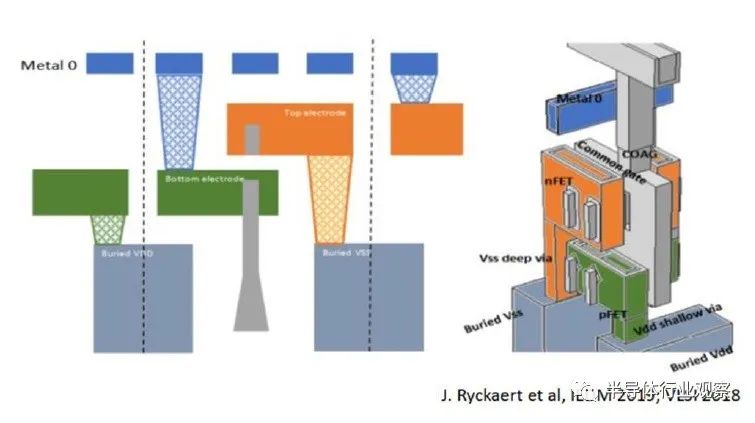
2.自對準單片 3D 堆疊
下圖顯示了單片自對準 CFET 結構的橫截面,以及高級工藝流程描述。(中間的 SiGe 層是犧牲的。)
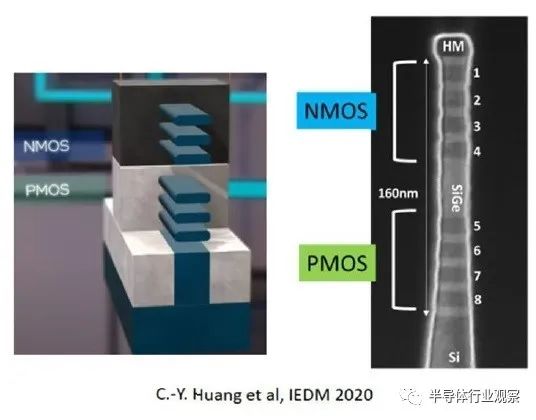
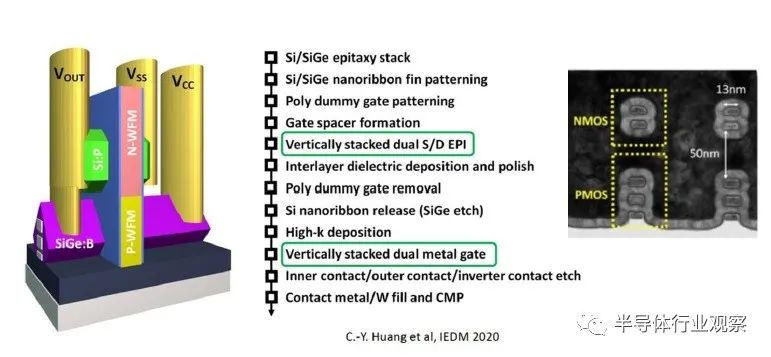
上圖中突出顯示的單片垂直器件結構獨有的兩個關鍵工藝步驟是不同的 nFET 和 pFET S/D 外延生長和柵極功函數金屬沉積。
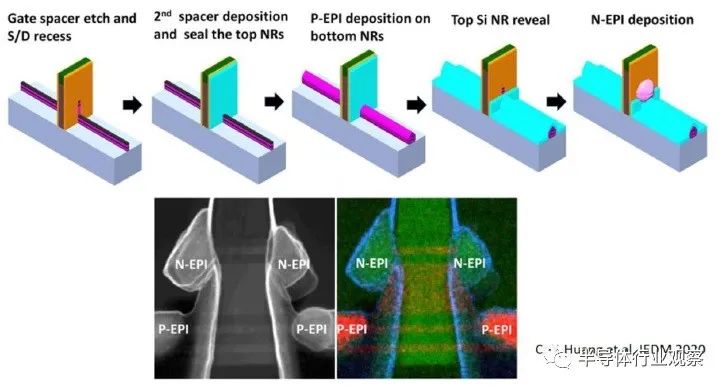
下圖說明了兩種器件類型的 S/D 外延生長過程。頂部器件納米帶在底部器件 S/D 外延生長之前接收阻擋層。然后,去除該阻擋層,露出頂部納米帶的末端,并生長頂部器件 S/D 外延。該圖還包括確認 p-epi 和 n-epi 區域沒有從其他外延生長步驟接收摻雜劑。
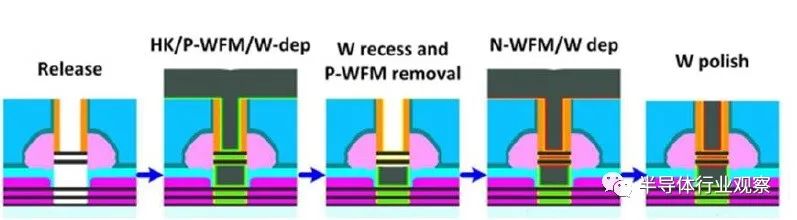
下圖描述了柵極金屬沉積的順序。隨后去除最初沉積在兩種器件類型上的金屬,用于隨后沉積用于第二(頂部)nFET的不同功函數柵極金屬。
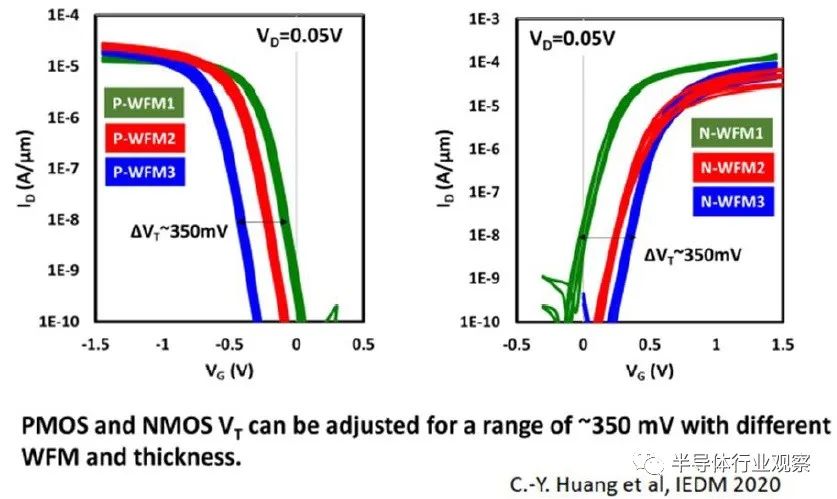
說明單片 nFET 和 pFET 的多個 Vt 器件特性范圍的實驗數據如下所示。
盡管 CFET 器件技術有望在即將到來的納米帶工藝節點上繼續改進 PPA,但關鍵考慮因素將是 CFET 器件拓撲的最終成本。Marko 介紹了以下成本估算比較,這是與 IC Knowledge LLC 合作的一部分。類別細分為:光刻、沉積、蝕刻、CMP、計量和其他。請注意,CFET 示例包括 BPR 分布,為信號路由開辟了額外的單元軌道。導致順序 CFET 成本差異的主要因素是晶圓鍵合和單獨的頂部器件處理。
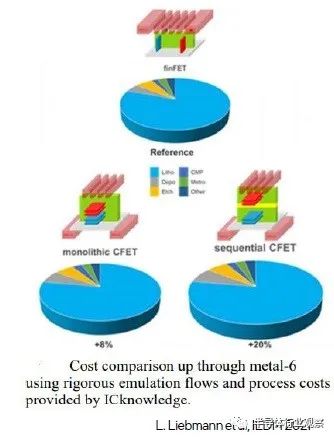
總的來說,CFET 制造的 PPAC 優勢看起來很有吸引力,盡管總 CFET 工藝成本更高。(一個更具挑戰性的權衡是使用不同襯底的順序 CFET 器件制造所提供的靈活性是否會保證額外的成本。)
盡管工藝開發挑戰仍有待解決,但 CFET 器件工藝路線圖似乎是納米帶器件很快實現生產狀態的自然延伸。
在最近的 VLSI 技術和電路研討會上,英特爾展示了他們的研發結果和來自其他研究人員的實驗數據,證明了 PPAC 的顯著優勢。FinFET 器件的壽命將通過七代工藝節點持續十多年,如下圖所示。
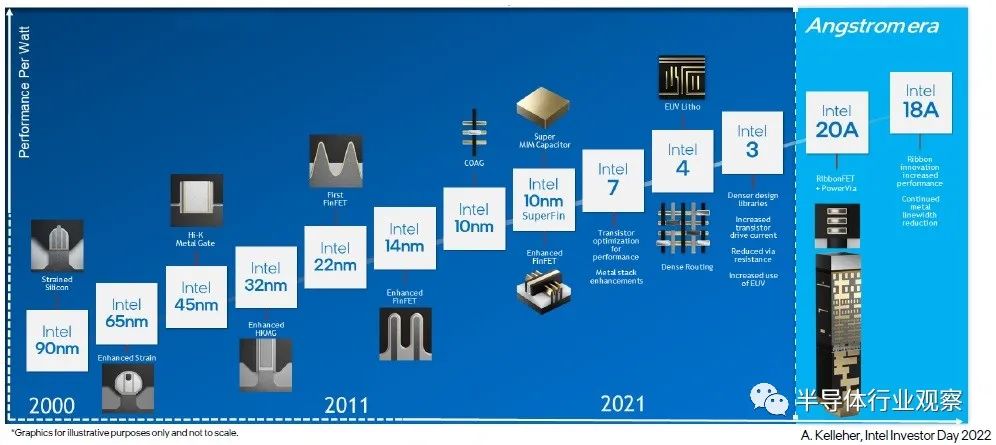
迄今為止,納米帶設備的路線圖(至少)描述了兩個節點。
CFET 器件的優勢和納米帶制造(以及建模和 EDA 基礎設施)專業知識的利用可能會縮短納米帶的壽命。
編輯:黃飛
?










 工商網監
工商網監
評論