����802.16d�Ķ��rͬ���㷨���M��FPGA���F
����0 ����
����WiMAX ( Wordwide Interoperability for Mi��crowave Access)�Ǵ������нӿڝM��IEEE 802��16�˜ʵČ����o��ͨ��ϵ�y������IEEE�˜���2004�궨�x�˿��нӿڵ������(PHY)����802��16d�f�h��ԓ�f�hҎ��������ݔ����ͻ�lģʽ���{�Ʋ���OFDM���g���ڽ��նˣ��������_���{������ҵ���̖����ʼλ�ã���ˣ�����M�ж��r��Ӌ��������r�����_���Ϳ����������صĴa�g�ɔ_�������lƫ��Ӌ���ڶ��r��Ӌ֮���M�У�������r��Ӌ���ʴ_��Ҳ��Ӱ��lƫ�Ĺ�Ӌ���ܣ��Ķ���������OFDMϵ�y�����½�����ˣ�����ڶ̕r�g�Ȍ����Ք����M�п��ٜʴ_�Ķ��rͬ����
����Ŀǰ���õĶ��r�㷨�����Ӌ�����е����P�ԡ�����Ӌ����s����Ӳ���YԴ���ķdz��������ԣ�ĿǰOFDMϵ�y�е�ͬ���㷨��ܛ���������������е�Ӳ���������������YԴ̫����o����ͬ��ģ�K�ͽ��ղ��ֵ�����ģ�K������һƬоƬ�С����ą���IEEE 802��16d����ӎ��Y���������һ�N�͏��s�ȵĎ�ͬ���Ͷ��rͬ�����㷨��ԓ�㷨����FPGA�������^���YԴ�팍�F��
����1 OFDM�еķ�̖���rͬ���㷨
�������ڶ��rͬ���㷨���о������w�Ͽ��Է֞�����һ�������OFDM���еĽY����������OFDM��̖������ǰ�YCP�ķ������@ͨ�����Q��ѭ�hǰ�Yͬ���������ڶ��������OFDM�в��댧�l����Ӗ����̖�ķ������ڃ��ͬ�������У���һ�������ߴ����Ե���Beek����������Ȼ��Ӌ�����䃞�c�Dz���Ҫ�~����_�N���������ͨ�ŵ�Ч�ʣ�����ȱ�c�ǹ�Ӌ�ĕr�g�^�L�����Ҍ��lƫ�������^���У��ڶ��������ߴ����Ե���Schmidl��Cox���������PN�������P�Ե�SCA�㷨���@һ�N�㷨���lƫ��Ӱ��^С�����ҹ�Ӌ�ĕr�g�������^�̣��dz��m������ͻ�lͨ��ϵ�y��
����2 �m��802��16d�Ķ��rͬ���㷨
����IEEE 802��16d���x��һ�M�����Ӗ����̖��������ͬ�����ŵ���Ӌ���@�M�����Ӗ����̖������Ӗ�����к��LӖ�����Ѓɲ��֣����ж�Ӗ�����а���4���؏͵�64�c��������ѭ�hǰ�Y(CP)���LӖ�����а����ɂ��؏͵�128�c��������ѭ�hǰ�Y���ڰl��ˣ�����OFDM��̖�ټ��϶�Ӗ�����к��LӖ�����У������ɵĎ��^���^�l�͞V������A��D�D�Q����ͨ�^��׃�l���ɰl�͵��ŵ��С����ڽ��նˣ��t���Î��^��Ӗ�����Ё��M��ͬ��������ʹ���rͬ�������lƫ��Ӱ푣�ͬ�r�������^�̕r�g����ɣ����IJ���SCA�㷨��ԓ�㷨�ֿɼ��֞��ӕr�����P�㷨�ͱ������л����P�㷨���
����2��1 �ӕr�����P��
����ͨ���x�ö�Ӗ�����Ё��M�ж��rͬ�������O���յ��Ļ����������О�rn��n��ԓ���е���̖��Ȼ�������н��^�ɂ����Ӵ���R��P������R�ǽ�����̖�ͽ�����̖�ӕr�Ļ����Pϵ����P�ǻ����Pϵ���������g������̖���������˴��ڵ�ֵ�������ЛQ�Ěwһ�������ͽ��չ��ʵĽ^��ֵ�Ǫ����ģ��乫ʽ���£�
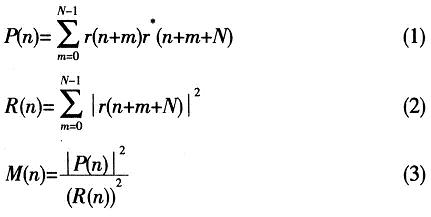
����ʽ�У�N�鴰���L�ȣ�N=64������Ӗ�����е����ڣ�d�ڴ��Ȼ��ӕr����ͬ�rӋ��M(n)��ֵ�����]�а���ǰ���ֽY������̖���F�r���õ���M(n)ֵͨ���dz�С(�hС��1)��������ǰ���ֽY������̖���F�r��������M(n)ֵѸ�����ߣ��������Fһ���_�A�������ķ�ֵ�ӽ���1������M(n)ֵ������Ҫһ���r�g���������ԓ�㷨�����ܾ��_���r��ֻ�m�ϴ��Եęz�y���Ƿ��_���D1��ʾ��̓������ʾ��̖���F�rM(n)������׃����r��
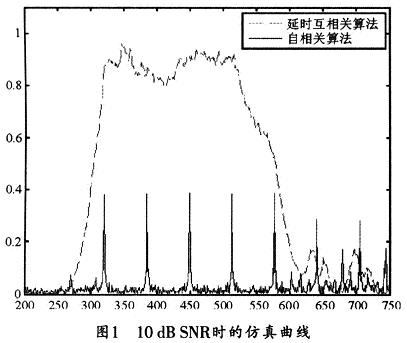
����2��2 �����P��
��������IEEE 802��16d�f�h�е�ǰ���־������õĻ����P���ԣ��ʿ�����֪��Ӗ�����кͽ������������ӻ����P������֪��Ӗ�����кͽ��յ�Ӗ������ǡ�Ì��R�r������a��һ����ֵ����ֵ���ʵ�λ������Ӗ����̖����ʼ�c����ˣ�����ͨ�^���һ����P�ķ�ֵλ�Á������_�Ķ��rͬ�����㷨��ʽ���£�
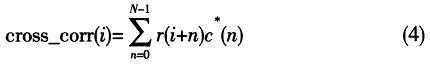
����ʽ�У�c(n)���Ӗ����̖�ڱ��صď��Ƙӱ���N���Ӗ����̖�Ę�ֵ�c��������֪��Ӗ�����кͽ���Ӗ������ǡ�Ì��R�r��Ҳ���a��һ����ֵ�������������D1�еČ�������ʾ��ԓ�㷨��ȱ�c�������lƫ��Ӱ푡�
�����������Ϸ����������㷨�����Ͽ��]�����������t�����P���������_�r�����Fһ����ֵƽ�_��ԓ���������ܴ_�������_�Ĝʴ_�r�̣��������c�������л����P�㷨�������ܵ��lƫ��Ӱ푶����¶��rƫ�
��3 �㷨���M
����ᘌ������㷨�IJ��㣬�Ɍ�����Ը��M���Ա��Cͬ�r�������õ����ܺ�Ӳ�����F�Ŀ����ԡ����M�㷨�nj��ɷN�㷨�Y�������M���Ϲ�Ӌ�����ȴ_��һ�������_�Ĵ���ƽ�_�������@��ƽ�_���ҵ������P��ֵ�����������ֵ�g����ȣ���ô�ɸ������һ����ֵ���Д���һ����̖���_ʼ���@�N�Ϲ�Ӌ���k����ܛ������r�������õ����ܣ�����Ҫ��Ӳ���ό��F�t���^���y��������ӕr�����P�㷨�У�Ӌ��M(n)��ֵ�mȻ�ɲ��õ����㷨��ÿ��Ӌ��ֻ��1�Ώ͔��\������ɼӷ��\�㣻���������PӋ���У����O������̖�����c����16λ��������ôӋ��һ�������P��ֵ��Ҫ16λ������64�Ώ͔��˷����@Ȼ������Ҫ��Ӳ���YԴ�_�N�dz����ҕ�Ӱ�ϵ�y���\���ٶȡ��@��Ӳ���ϣ����YԴ����̫����o�����F�����˼���㷨�Ĺ�Ӌ���Ⱥ͌��F�ď��s�ԣ��б�Ҫ���㷨���Mһ�����M���������Ք����M�ж��A�����Եõ�d[n]=Q[r(n)]������Q��ʾ�͔���������Ҋ��ʽ��
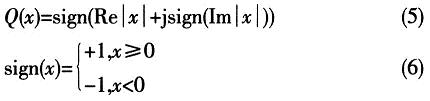
���������@�N���M�������P�㷨���ӕr�����P�㷨�M���Ϲ�Ӌ�ķ���������D2��ʾ��
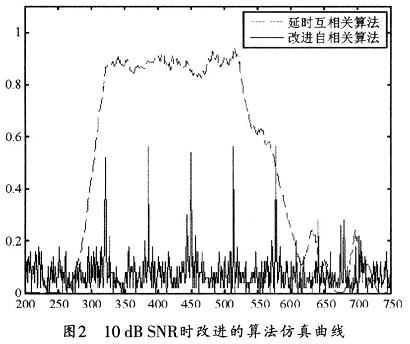
�������D1�͈D2�M�Ќ��ȿ�֪���@�N�����Ք������A�����ķ������p���㷨�����ܣ����ǣ����ڎ��Ĵ���λ���ѱ�������һ������֮�ȣ���ˣ�ֻ�������ֵ�Ϳ��Դ_����һ��OFDM��̖�Ĝʴ_λ�á��@�N�������ܱ��C��Ӌ���ȣ����ܝM��Ӳ���YԴ�����ʵ�Ҫ��
����4 ����FPGA���F
����4��1 �����P�ӕrģ�K��FPGA���F
���������Mһ�������\�㣬Ҳ���Բ��M���㷨�еĚwһ���\�㣬��ֱ��Ӌ��R(n)��ֵ��������ʽ�����飺
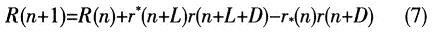
�����D3��ʾ�������P�ӕrģ�K��Ӳ���M�ɽY��������Ҫ��FIFO�ӕr��Ԫ���͔��\�������ӷ�����ȡģģ�K�M�ɡ����Џ͔��˷�����ֱ��ʹ��IP�ˁ팍�F���@��ֱ��ʹ���Ă������˷����̓ɂ��ӷ�������ʡ�YԴ��
���������ն˽��^��׃�l��I·��Q·�����֞��·����ģ�K��I·��Q·���������ӕrһ���r����ڣ��@�Ǟ��˺�Q·����������ͬ�ĕr�ӣ��˺����M��FIFO���^64���r����ڵ��ӕr��Q·���������M��ȡ�෴���\�㡣�@�����͔���ܗ�\���ஔ����ȡ�෴�������͔��˷��������p�ĽY������FIFO�M���ӕr����������ϵ�y�ď͔��c���p�����ӕr64���r����ڵď͔��M�Џ͔��˷��\�㡣���ڃ�·��������16λ���c�����������^�\�����ɞ�33λ�����˹�ʡ�YԴ���Ɍ����ýY���ĸ�5λ�͵�12λ��ȥ�����@������Ӱ��\��ľ��ȡ����^�͔��˷��\��Č�����̓���ٷքe���^64���r����ڵ�FIFO�ӕr�������ӕrǰ��Ĕ������p���\�㣬Ȼ��Ӌ��ĽY�����ۼ��\�㡣�ۼ���ݔ���ĽY�����^ȡģģ�K���ɵõ�������̓���Ľ^��ֵ��Ȼ�ɲ��ֽY����ӣ��ٌ���ӽY���c�T��ֵ���^�����^�T�ބt����־λ�øߡ�����ע���T��ֵ���xȡ��Ӱ푎��z�y�ķ��������ڲ��õ����ϙz�y���������m���U���T���������OӋ�O�����T��ֵ���ֵ��1��4��
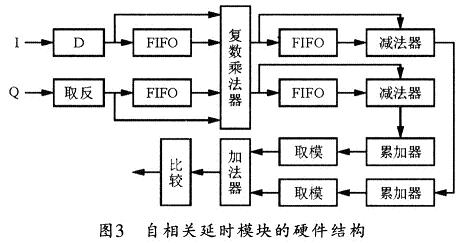
����4��2 �����Pģ�K��FPGA���F
���������Pģ�K��Ҫ��ƥ���\���Ԫ��ȡģ���ͼӷ����M�ɡ����M���㷨ֻ��ݔ�딵���ķ�̖λ�c�������еķ�̖λ�M�����P�\�㣬��Ҏ��ݔ���̖����ȡֵ��1��ݔ���̖��ؓȡֵ�飭1����������ݔ�딵���ķ�̖�ͱ������еķ�̖���ɵ�16�Nݔ����ȫ���У������п��ܵ����P�\��ֵ��ô�����\��ģ�K�У��@�ӾͿ��Ը���ݔ�딵���ķ�̖���x�����P�\��ĽY�����@��Ч�ڰя͔����P�\�㺆���锵���x�����팍�F��
�����D4��ʾ�黥���Pģ�K��FPGA���F��D������I��Q��·�����M��ģ�K��ȡ�������λ������λ�Ĵ�����Ȼ���c����������ƥ���\�㡣ƥ���\��ģ�K��64�������x������126���ӷ����M�ɣ��ӷ��\�����6����ˮ���팍�F���@�ӣ���ʹϵ�y���\�����ʸ��ߡ�
����4��3 ����Y������
����ϵ�y�еĸ�ģ�K�ɲ���Verilog HDL�Z���OӋ������ʹ��Xilinx��˾�����OӋ�h��ISE�е�ModelSim SE 6��0����ɷ��棬����Y����D5��ʾ������frame_re_dout��frame_im_dout������ϵ�y�Č�����̓��������abs_out���ӕr�����P�㷨��ȡģ��ӵĽY����frame_head������ӕr�����P�㷨ʹ�������ߕr�õ���һ����ֵƽ�_��top_flag����M�����P�㷨Ӌ�����õķ�ֵ���D�е������Pƽ�_����5����ֵ���@�cMATLAB����Y�������������Xilinx��˾Virtex��proϵ��xc2vp30�����M�Ќ��F������߉��Ԫʹ���ʞ�8����ϵ�y��߹����l�ʞ�236��373 MHz ��

����5 �Y���Z
�����������о�����802��16d��OFDM���rͬ���㷨�Ļ��A�������һ�N���M���㷨������FPGA���������Ӳ���·�OӋ������Y������ԓ�㷨�ڱ�����ԭ�㷨�������ܵ�ͬ�r���ɹ�ʡӲ���YԴ�������ڰ�ͬ��ģ�K�ͽ��ղ�������ģ�K�����چ�оƬ�С�ͬ�r��ԓ�㷨Ҳ���ƏV����������ǰ���ֽY����802��1 1a�ȅf�h�С�