TCP一定能保證數(shù)據(jù)不丟失嗎?
?
?
TCP 是一個(gè)可靠的傳輸協(xié)議,那它一定能保證數(shù)據(jù)不丟失嗎?
這次,就跟大家探討這個(gè)問題。
數(shù)據(jù)包的發(fā)送流程
首先,我們兩個(gè)手機(jī)的綠皮聊天軟件客戶端,要通信,中間會通過它們家服務(wù)器。大概長這樣。
 聊天軟件三端通信
聊天軟件三端通信但為了簡化模型,我們把中間的服務(wù)器給省略掉,假設(shè)這是個(gè)端到端的通信。且為了保證消息的可靠性,我們盲猜它們之間用的是TCP協(xié)議進(jìn)行通信。
 聊天軟件兩端通信
聊天軟件兩端通信為了發(fā)送數(shù)據(jù)包,兩端首先會通過三次握手,建立TCP連接。
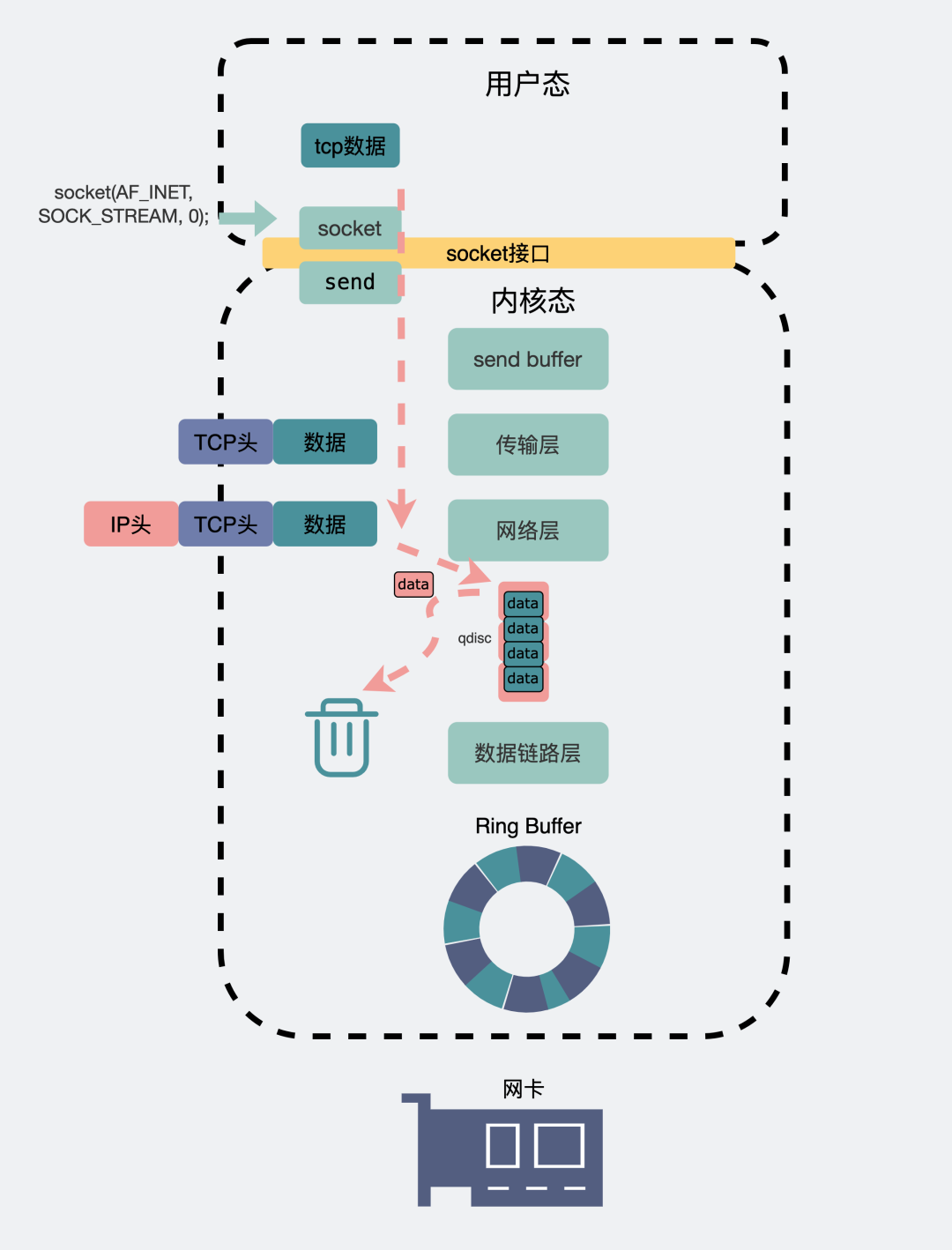
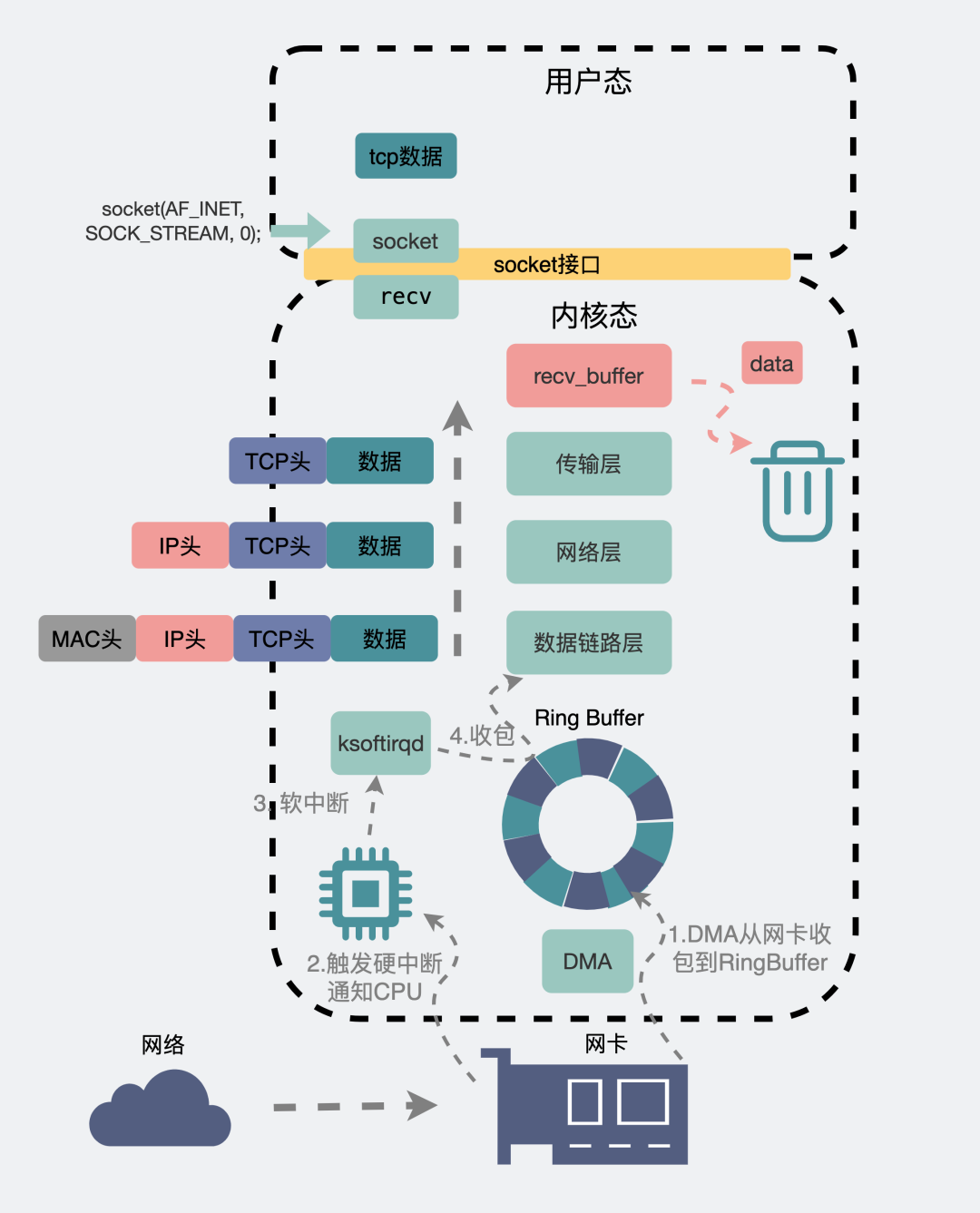
一個(gè)數(shù)據(jù)包,從聊天框里發(fā)出,消息會從聊天軟件所在的用戶空間拷貝到內(nèi)核空間的發(fā)送緩沖區(qū)(send buffer),數(shù)據(jù)包就這樣順著傳輸層、網(wǎng)絡(luò)層,進(jìn)入到數(shù)據(jù)鏈路層,在這里數(shù)據(jù)包會經(jīng)過流控(qdisc),再通過RingBuffer發(fā)到物理層的網(wǎng)卡。數(shù)據(jù)就這樣順著網(wǎng)卡發(fā)到了紛繁復(fù)雜的網(wǎng)絡(luò)世界里。這里頭數(shù)據(jù)會經(jīng)過n多個(gè)路由器和交換機(jī)之間的跳轉(zhuǎn),最后到達(dá)目的機(jī)器的網(wǎng)卡處。
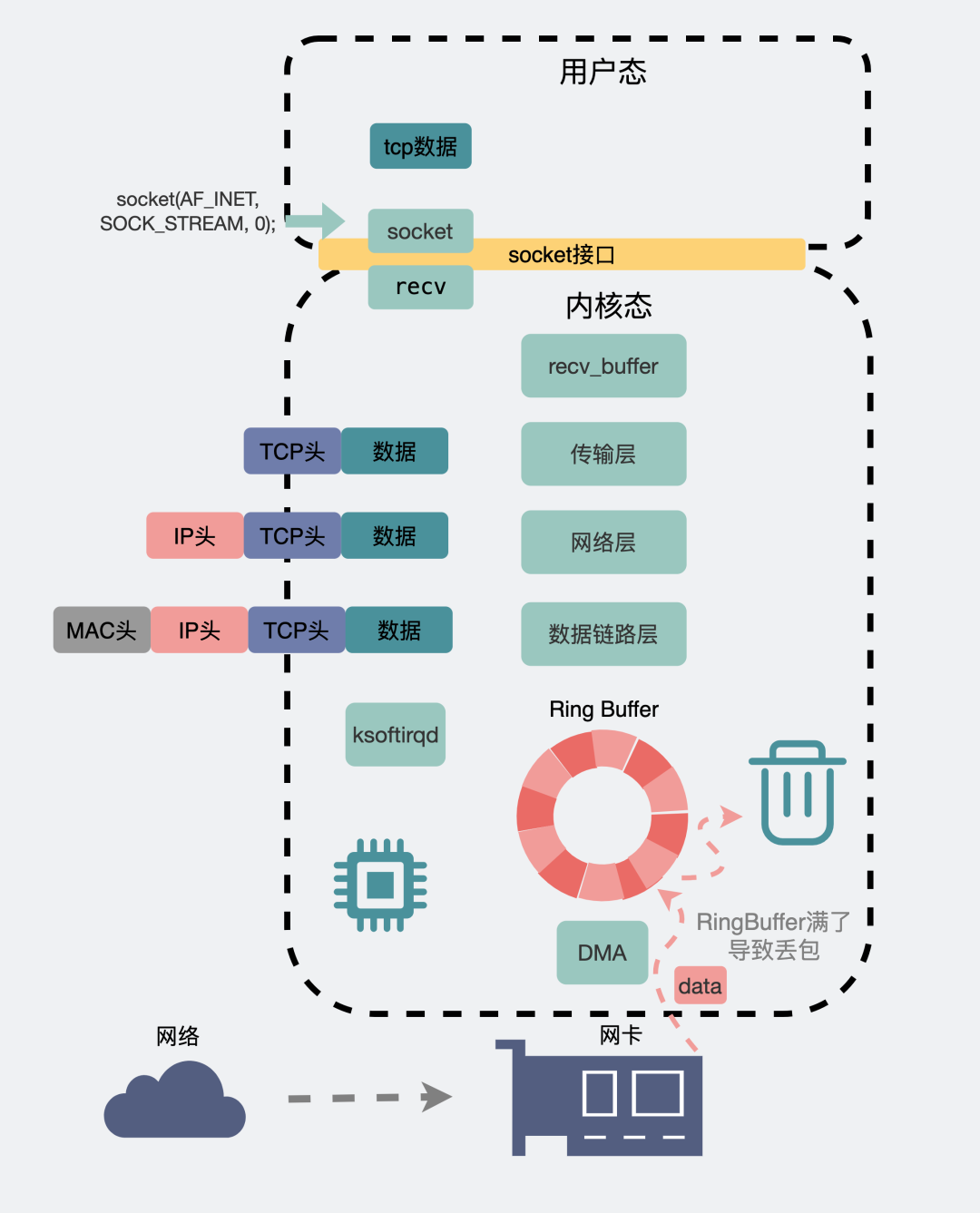
此時(shí)目的機(jī)器的網(wǎng)卡會通知DMA將數(shù)據(jù)包信息放到RingBuffer中,再觸發(fā)一個(gè)硬中斷給CPU,CPU觸發(fā)軟中斷讓ksoftirqd去RingBuffer收包,于是一個(gè)數(shù)據(jù)包就這樣順著物理層,數(shù)據(jù)鏈路層,網(wǎng)絡(luò)層,傳輸層,最后從內(nèi)核空間拷貝到用戶空間里的聊天軟件里。
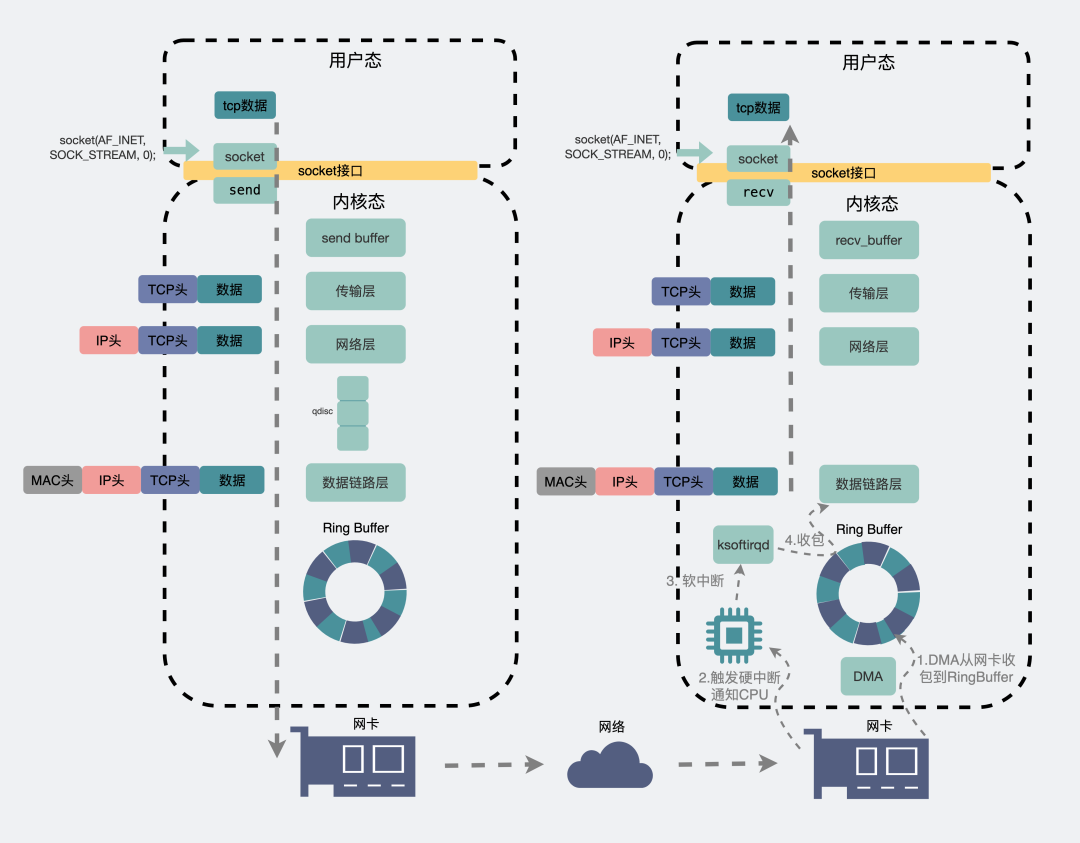 網(wǎng)絡(luò)發(fā)包收包全景圖
網(wǎng)絡(luò)發(fā)包收包全景圖畫了那么大一張圖,只水了200字做解釋,我多少是有些心痛的。
到這里,拋開一些細(xì)節(jié),大家大概知道了一個(gè)數(shù)據(jù)包從發(fā)送到接收的宏觀過程。
可以看到,這上面全是密密麻麻的名詞。
整條鏈路下來,有不少地方可能會發(fā)生丟包。
但為了不讓大家保持蹲姿太久影響身體健康,我這邊只重點(diǎn)講下幾個(gè)常見容易發(fā)生丟包的場景。
建立連接時(shí)丟包
TCP協(xié)議會通過三次握手建立連接。大概長下面這樣。
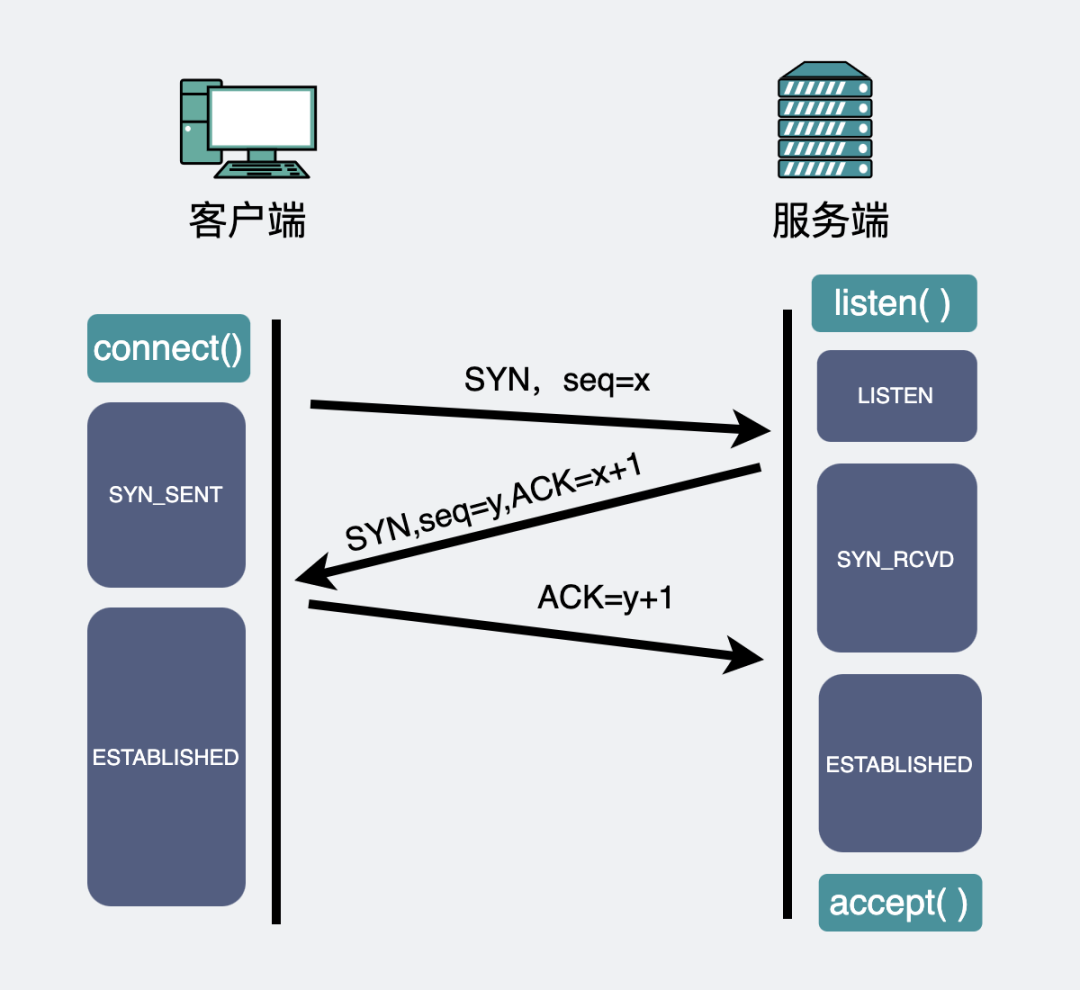 TCP三次握手
TCP三次握手在服務(wù)端,第一次握手之后,會先建立個(gè)半連接,然后再發(fā)出第二次握手。這時(shí)候需要有個(gè)地方可以暫存這些半連接。這個(gè)地方就叫半連接隊(duì)列。
如果之后第三次握手來了,半連接就會升級為全連接,然后暫存到另外一個(gè)叫全連接隊(duì)列的地方,坐等程序執(zhí)行accept()方法將其取走使用。
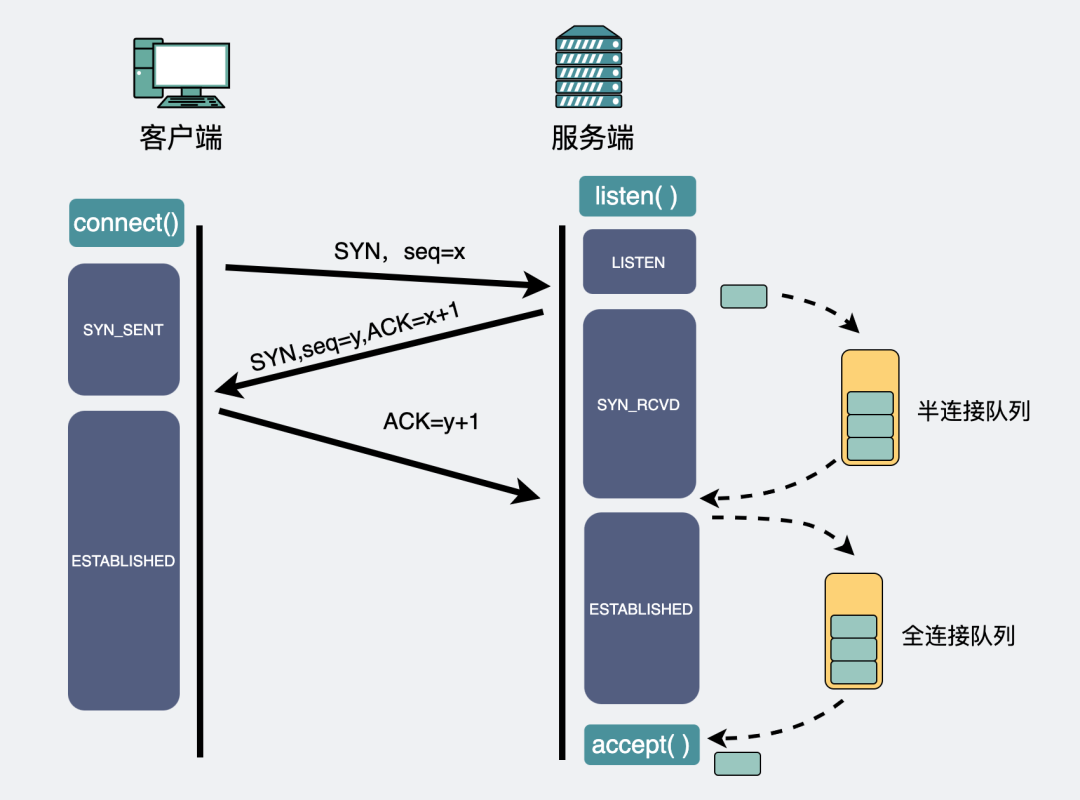 半連接隊(duì)列和全連接隊(duì)列
半連接隊(duì)列和全連接隊(duì)列是隊(duì)列就有長度,有長度就有可能會滿,如果它們滿了,那新來的包就會被丟棄。
可以通過下面的方式查看是否存在這種丟包行為。
#?全連接隊(duì)列溢出次數(shù)
#?netstat?-s?|?grep?overflowed
????4343?times?the?listen?queue?of?a?socket?overflowed
#?半連接隊(duì)列溢出次數(shù)
#?netstat?-s?|?grep?-i?"SYNs?to?LISTEN?sockets?dropped"
????109?times?the?listen?queue?of?a?socket?overflowed?
從現(xiàn)象來看就是連接建立失敗。
流量控制丟包
應(yīng)用層能發(fā)網(wǎng)絡(luò)數(shù)據(jù)包的軟件有那么多,如果所有數(shù)據(jù)不加控制一股腦沖入到網(wǎng)卡,網(wǎng)卡會吃不消,那怎么辦?讓數(shù)據(jù)按一定的規(guī)則排個(gè)隊(duì)依次處理,也就是所謂的qdisc(Queueing Disciplines,排隊(duì)規(guī)則),這也是我們常說的流量控制機(jī)制。
排隊(duì),得先有個(gè)隊(duì)列,而隊(duì)列有個(gè)長度。
我們可以通過下面的ifconfig命令查看到,里面涉及到的txqueuelen后面的數(shù)字1000,其實(shí)就是流控隊(duì)列的長度。
當(dāng)發(fā)送數(shù)據(jù)過快,流控隊(duì)列長度txqueuelen又不夠大時(shí),就容易出現(xiàn)丟包現(xiàn)象。
 qdisc丟包
qdisc丟包
可以通過下面的ifconfig命令,查看TX下的dropped字段,當(dāng)它大于0時(shí),則有可能是發(fā)生了流控丟包。
#?ifconfig?eth0
eth0:?flags=4163<UP,BROADCAST,RUNNING,MULTICAST>??mtu?1500
????????inet?172.21.66.69??netmask?255.255.240.0??broadcast?172.21.79.255
????????inet6?fe80:3eff269f??prefixlen?64??scopeid?0x20<link>
????????ether?003e26:9f??txqueuelen?1000??(Ethernet)
????????RX?packets?6962682??bytes?1119047079?(1.0?GiB)
????????RX?errors?0??dropped?0??overruns?0??frame?0
????????TX?packets?9688919??bytes?2072511384?(1.9?GiB)
????????TX?errors?0??dropped?0?overruns?0??carrier?0??collisions?0
當(dāng)遇到這種情況時(shí),我們可以嘗試修改下流控隊(duì)列的長度。比如像下面這樣將eth0網(wǎng)卡的流控隊(duì)列長度從1000提升為1500.
#?ifconfig?eth0?txqueuelen?1500
網(wǎng)卡丟包
網(wǎng)卡和它的驅(qū)動(dòng)導(dǎo)致丟包的場景也比較常見,原因很多,比如網(wǎng)線質(zhì)量差,接觸不良。除此之外,我們來聊幾個(gè)常見的場景。
RingBuffer過小導(dǎo)致丟包
上面提到,在接收數(shù)據(jù)時(shí),會將數(shù)據(jù)暫存到RingBuffer接收緩沖區(qū)中,然后等著內(nèi)核觸發(fā)軟中斷慢慢收走。如果這個(gè)緩沖區(qū)過小,而這時(shí)候發(fā)送的數(shù)據(jù)又過快,就有可能發(fā)生溢出,此時(shí)也會產(chǎn)生丟包。
 RingBuffer滿了導(dǎo)致丟包
RingBuffer滿了導(dǎo)致丟包我們可以通過下面的命令去查看是否發(fā)生過這樣的事情。
#?ifconfig
eth0:??RX?errors?0??dropped?0??overruns?0??frame?0
查看上面的overruns指標(biāo),它記錄了由于RingBuffer長度不足導(dǎo)致的溢出次數(shù)。
當(dāng)然,用ethtool命令也能查看。
#?ethtool?-S?eth0|grep?rx_queue_0_drops
但這里需要注意的是,因?yàn)橐粋€(gè)網(wǎng)卡里是可以有多個(gè)RingBuffer的,所以上面的rx_queue_0_drops里的0代表的是第0個(gè)RingBuffer的丟包數(shù),對于多隊(duì)列的網(wǎng)卡,這個(gè)0還可以改成其他數(shù)字。但我的家庭條件不允許我看其他隊(duì)列的丟包數(shù),所以上面的命令對我來說是夠用了。。。
當(dāng)發(fā)現(xiàn)有這類型丟包的時(shí)候,可以通過下面的命令查看當(dāng)前網(wǎng)卡的配置。
#ethtool?-g?eth0
Ring?parameters?for?eth0:
Pre-set?maximums:
RX:????????4096
RX?Mini:????0
RX?Jumbo:????0
TX:????????4096
Current?hardware?settings:
RX:????????1024
RX?Mini:????0
RX?Jumbo:????0
TX:????????1024
上面的輸出內(nèi)容,含義是RingBuffer最大支持4096的長度,但現(xiàn)在實(shí)際只用了1024。
想要修改這個(gè)長度可以執(zhí)行ethtool -G eth1 rx 4096 tx 4096將發(fā)送和接收RingBuffer的長度都改為4096。
RingBuffer增大之后,可以減少因?yàn)槿萘啃《鴮?dǎo)致的丟包情況。
網(wǎng)卡性能不足
網(wǎng)卡作為硬件,傳輸速度是有上限的。當(dāng)網(wǎng)絡(luò)傳輸速度過大,達(dá)到網(wǎng)卡上限時(shí),就會發(fā)生丟包。這種情況一般常見于壓測場景。
我們可以通過ethtool加網(wǎng)卡名,獲得當(dāng)前網(wǎng)卡支持的最大速度。
#?ethtool?eth0
Settings?for?eth0:
????Speed:?10000Mb/s
可以看到,我這邊用的網(wǎng)卡能支持的最大傳輸速度speed=1000Mb/s。
也就是俗稱的千兆網(wǎng)卡,但注意這里的單位是Mb,這里的b是指bit,而不是Byte。1Byte=8bit。所以10000Mb/s還要除以8,也就是理論上網(wǎng)卡最大傳輸速度是1000/8 = 125MB/s。
我們可以通過sar命令從網(wǎng)絡(luò)接口層面來分析數(shù)據(jù)包的收發(fā)情況。
#?sar?-n?DEV?1
Linux?3.10.0-1127.19.1.el7.x86_64??????2022年07月27日?????_x86_64_????(1?CPU)
08時(shí)35分39秒?????IFACE???rxpck/s???txpck/s????rxkB/s????txkB/s????rxcmp/s???txcmp/s??rxmcst/s
08時(shí)35分40秒??????eth0??????6.06??????4.04??????0.35????121682.33???0.00????0.00?????0.00
其中 txkB/s是指當(dāng)前每秒發(fā)送的字節(jié)(byte)總數(shù),rxkB/s是指每秒接收的字節(jié)(byte)總數(shù)。
當(dāng)兩者加起來的值約等于12~13w字節(jié)的時(shí)候,也就對應(yīng)大概125MB/s的傳輸速度。此時(shí)達(dá)到網(wǎng)卡性能極限,就會開始丟包。
遇到這個(gè)問題,優(yōu)先看下你的服務(wù)是不是真有這么大的真實(shí)流量,如果是的話可以考慮下拆分服務(wù),或者就忍痛充錢升級下配置吧。
接收緩沖區(qū)丟包
我們一般使用TCP socket進(jìn)行網(wǎng)絡(luò)編程的時(shí)候,內(nèi)核都會分配一個(gè)發(fā)送緩沖區(qū)和一個(gè)接收緩沖區(qū)。
當(dāng)我們想要發(fā)一個(gè)數(shù)據(jù)包,會在代碼里執(zhí)行send(msg),這時(shí)候數(shù)據(jù)包并不是一把梭直接就走網(wǎng)卡飛出去的。而是將數(shù)據(jù)拷貝到內(nèi)核發(fā)送緩沖區(qū)就完事返回了,至于什么時(shí)候發(fā)數(shù)據(jù),發(fā)多少數(shù)據(jù),這個(gè)后續(xù)由內(nèi)核自己做決定。
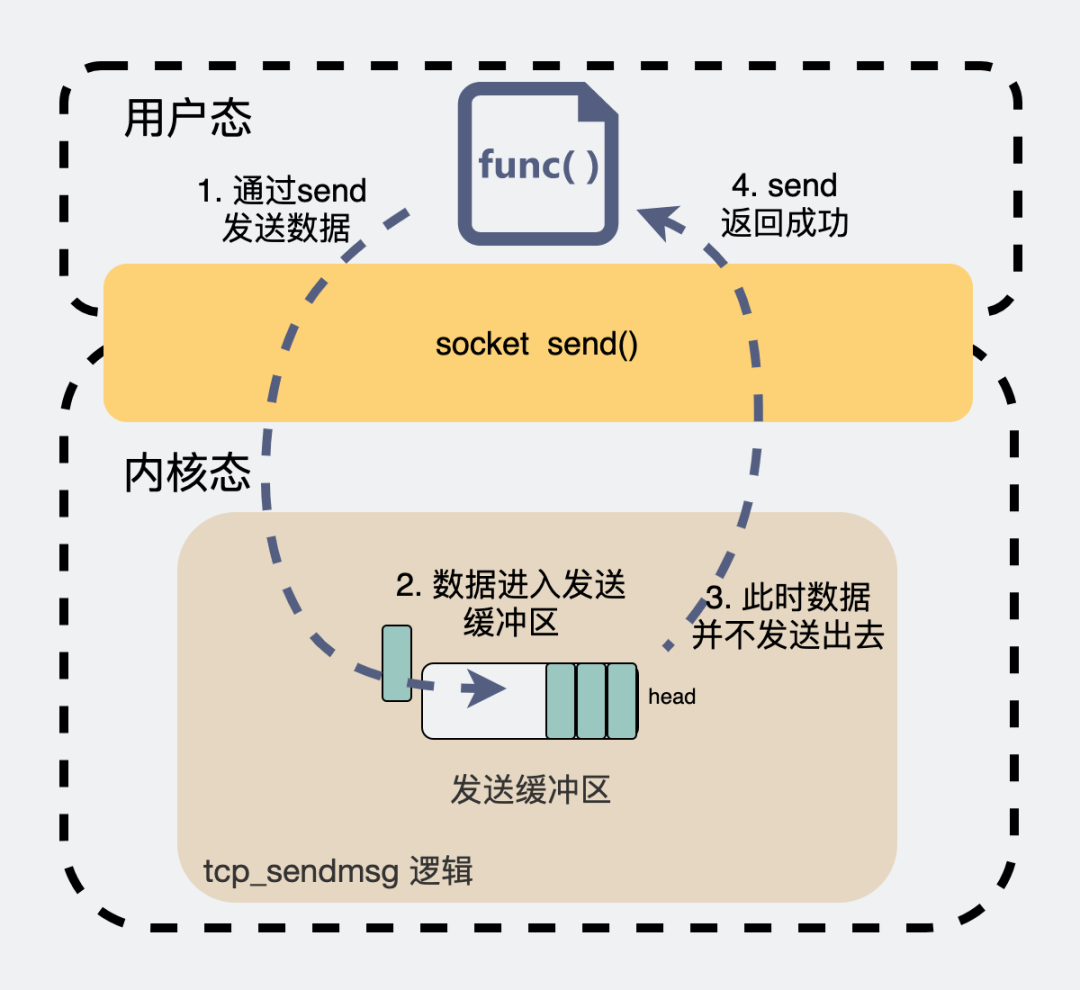 tcp_sendmsg邏輯
tcp_sendmsg邏輯而接收緩沖區(qū)作用也類似,從外部網(wǎng)絡(luò)收到的數(shù)據(jù)包就暫存在這個(gè)地方,然后坐等用戶空間的應(yīng)用程序?qū)?shù)據(jù)包取走。
這兩個(gè)緩沖區(qū)是有大小限制的,可以通過下面的命令去查看。
#?查看接收緩沖區(qū)
#?sysctl?net.ipv4.tcp_rmem
net.ipv4.tcp_rmem?=?4096????87380???6291456
#?查看發(fā)送緩沖區(qū)
#?sysctl?net.ipv4.tcp_wmem
net.ipv4.tcp_wmem?=?4096????16384???4194304
不管是接收緩沖區(qū)還是發(fā)送緩沖區(qū),都能看到三個(gè)數(shù)值,分別對應(yīng)緩沖區(qū)的最小值,默認(rèn)值和最大值 (min、default、max)。緩沖區(qū)會在min和max之間動(dòng)態(tài)調(diào)整。
那么問題來了,如果緩沖區(qū)設(shè)置過小會怎么樣?
對于發(fā)送緩沖區(qū),執(zhí)行send的時(shí)候,如果是阻塞調(diào)用,那就會等,等到緩沖區(qū)有空位可以發(fā)數(shù)據(jù)。
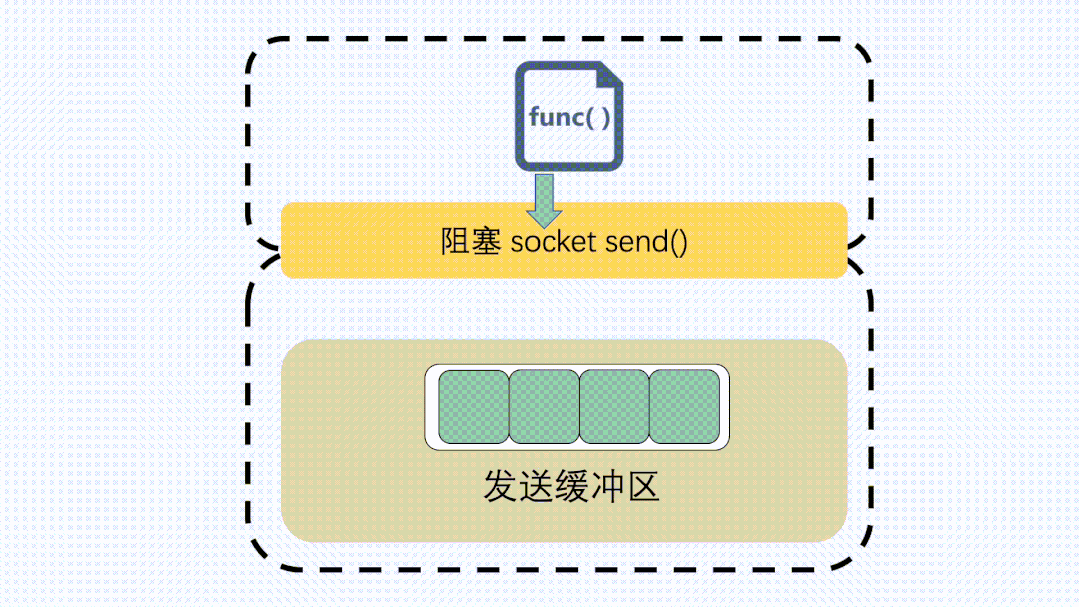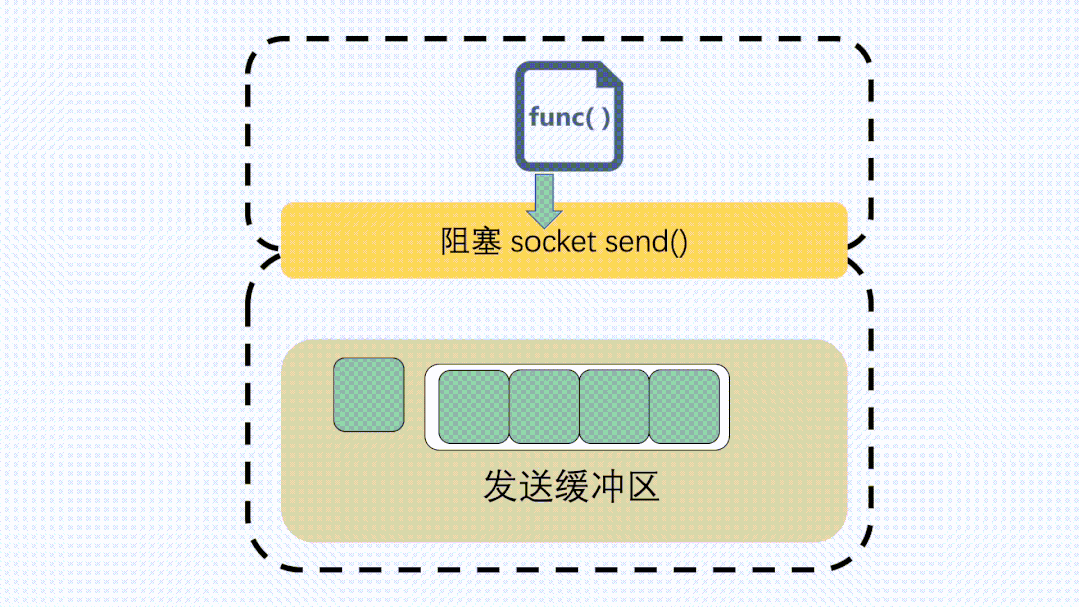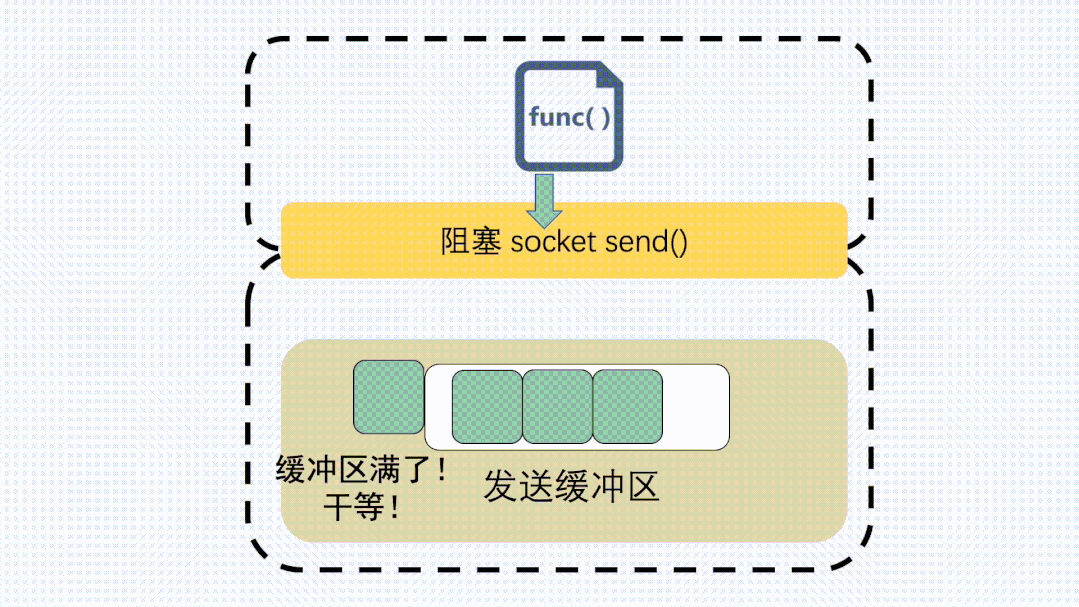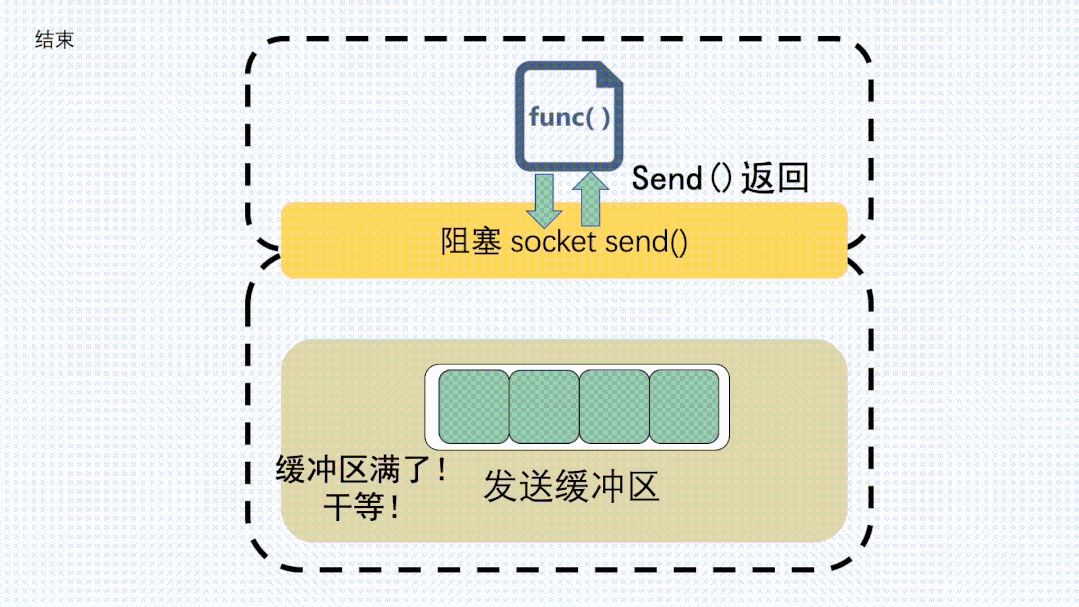 send阻塞
send阻塞
如果是非阻塞調(diào)用,就會立刻返回一個(gè) EAGAIN 錯(cuò)誤信息,意思是 ?Try again。讓應(yīng)用程序下次再重試。這種情況下一般不會發(fā)生丟包。
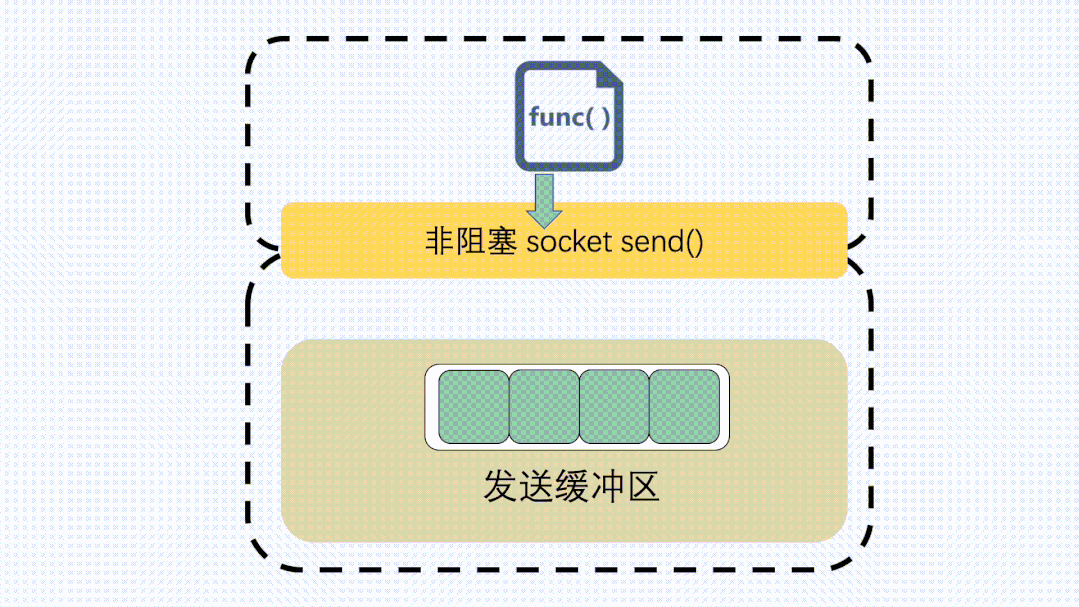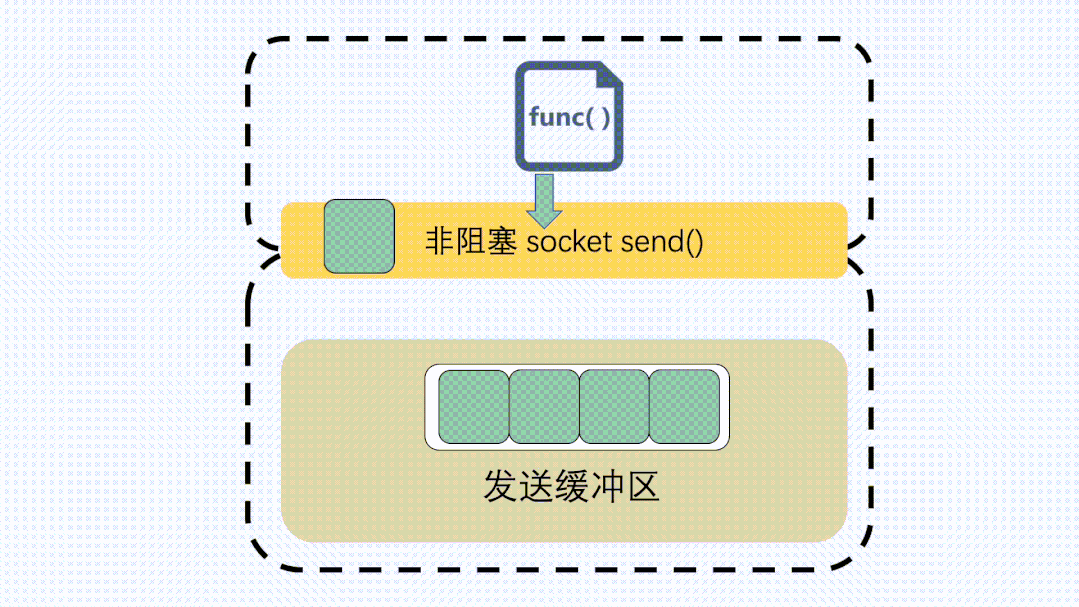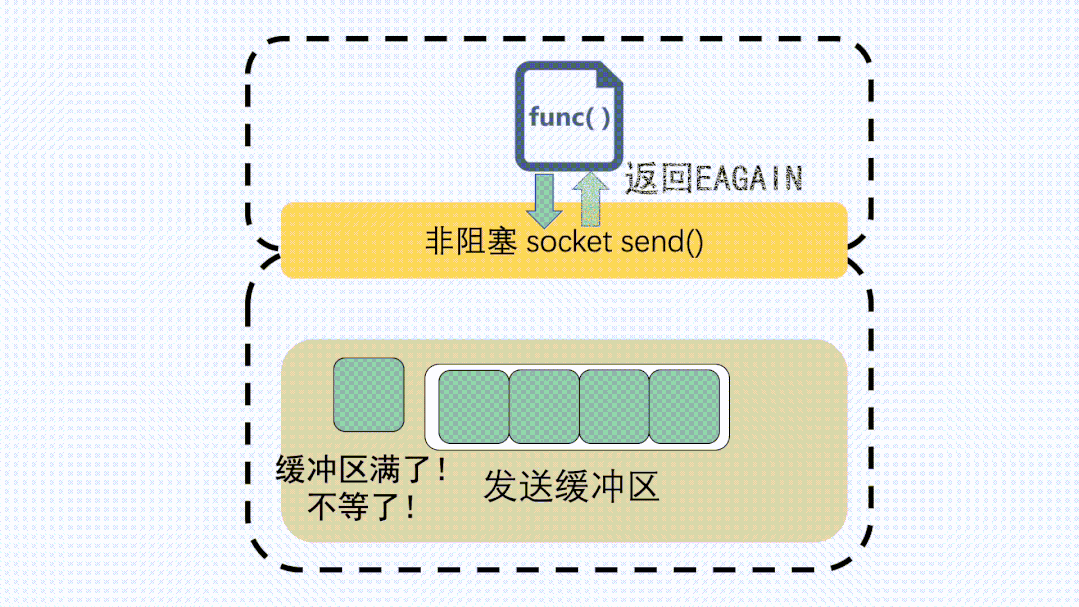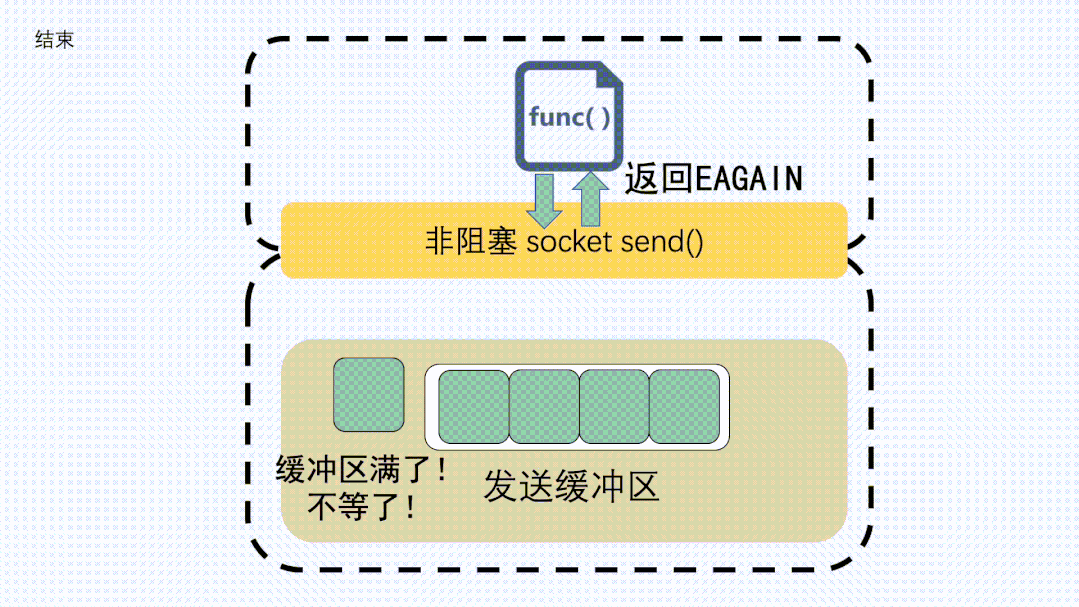 send非阻塞
send非阻塞
當(dāng)接受緩沖區(qū)滿了,事情就不一樣了,它的TCP接收窗口會變?yōu)?,也就是所謂的零窗口,并且會通過數(shù)據(jù)包里的win=0,告訴發(fā)送端,"球球了,頂不住了,別發(fā)了"。一般這種情況下,發(fā)送端就該停止發(fā)消息了,但如果這時(shí)候確實(shí)還有數(shù)據(jù)發(fā)來,就會發(fā)生丟包。
 recv_buffer丟包
recv_buffer丟包
我們可以通過下面的命令里的TCPRcvQDrop查看到有沒有發(fā)生過這種丟包現(xiàn)象。
cat?/proc/net/netstat
TcpExt:?SyncookiesSent?TCPRcvQDrop?SyncookiesFailed
TcpExt:?0??????????????157??????????????60116
但是說個(gè)傷心的事情,我們一般也看不到這個(gè)TCPRcvQDrop,因?yàn)檫@個(gè)是5.9版本里引入的打點(diǎn),而我們的服務(wù)器用的一般是2.x~3.x左右版本。你可以通過下面的命令查看下你用的是什么版本的linux內(nèi)核。
#?cat?/proc/version
Linux?version?3.10.0-1127.19.1.el7.x86_64
兩端之間的網(wǎng)絡(luò)丟包
前面提到的是兩端機(jī)器內(nèi)部的網(wǎng)絡(luò)丟包,除此之外,兩端之間那么長的一條鏈路都屬于外部網(wǎng)絡(luò),這中間有各種路由器和交換機(jī)還有光纜啥的,丟包也是很經(jīng)常發(fā)生的。
這些丟包行為發(fā)生在中間鏈路的某些個(gè)機(jī)器上,我們當(dāng)然是沒權(quán)限去登錄這些機(jī)器。但我們可以通過一些命令觀察整個(gè)鏈路的連通情況。
ping命令查看丟包
比如我們知道目的地的域名是 baidu.com。想知道你的機(jī)器到baidu服務(wù)器之間,有沒有產(chǎn)生丟包行為。可以使用ping命令。
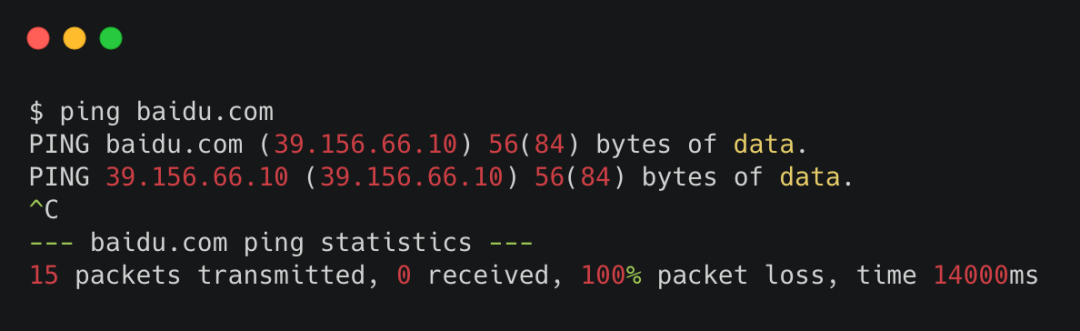 ping查看丟包
ping查看丟包
倒數(shù)第二行里有個(gè)100% packet loss,意思是丟包率100%。
但這樣其實(shí)你只能知道你的機(jī)器和目的機(jī)器之間有沒有丟包。
那如果你想知道你和目的機(jī)器之間的這條鏈路,哪個(gè)節(jié)點(diǎn)丟包了,有沒有辦法呢?
有。
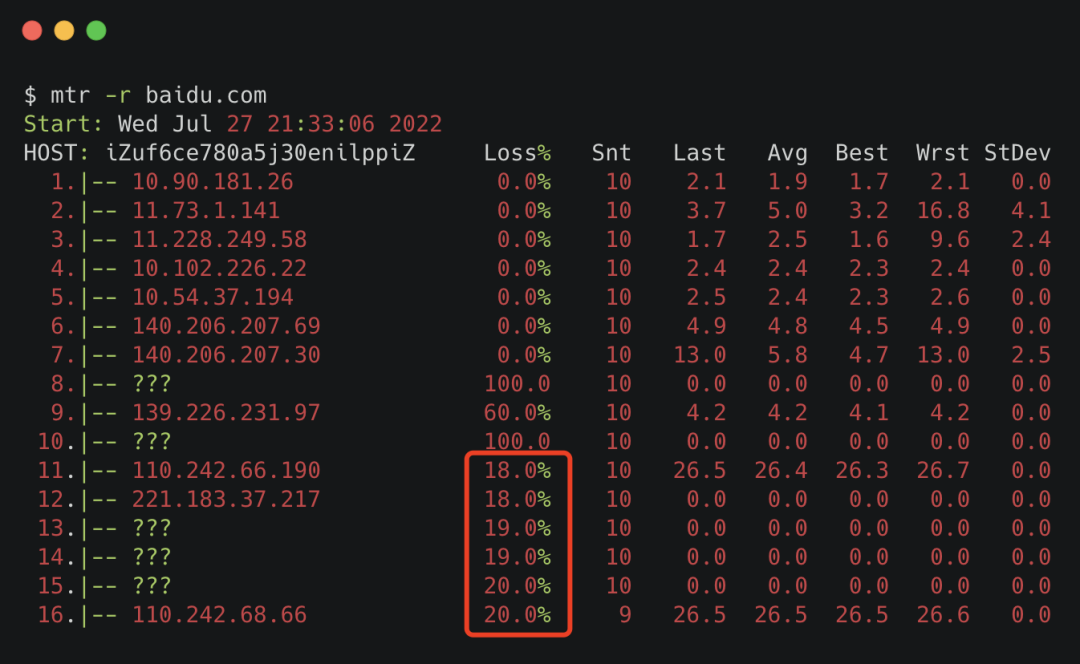
mtr命令
mtr命令可以查看到你的機(jī)器和目的機(jī)器之間的每個(gè)節(jié)點(diǎn)的丟包情況。
像下面這樣執(zhí)行命令。
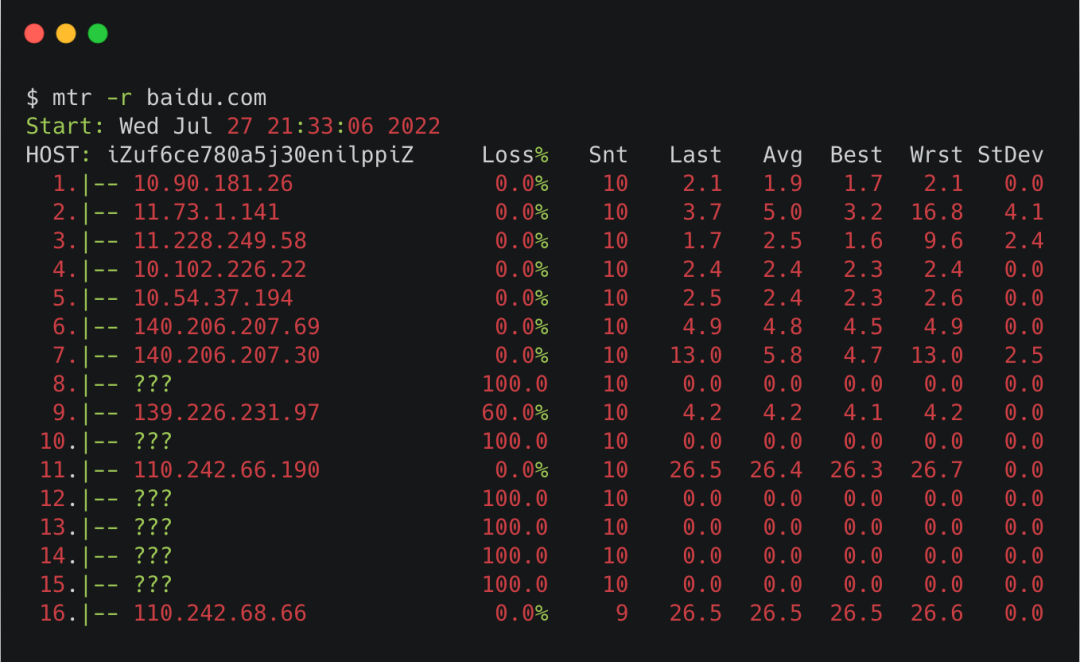 mtr_icmp
mtr_icmp其中 -r 是指report,以報(bào)告的形式打印結(jié)果。
可以看到Host那一列,出現(xiàn)的都是鏈路中間每一跳的機(jī)器,Loss的那一列就是指這一跳對應(yīng)的丟包率。
需要注意的是,中間有一些是host是???,那個(gè)是因?yàn)?strong style="font-weight:bold;line-height:1.75em;color:#304FFE;">mtr默認(rèn)用的是ICMP包,有些節(jié)點(diǎn)限制了ICMP包,導(dǎo)致不能正常展示。
我們可以在mtr命令里加個(gè)-u,也就是使用udp包,就能看到部分???對應(yīng)的IP。
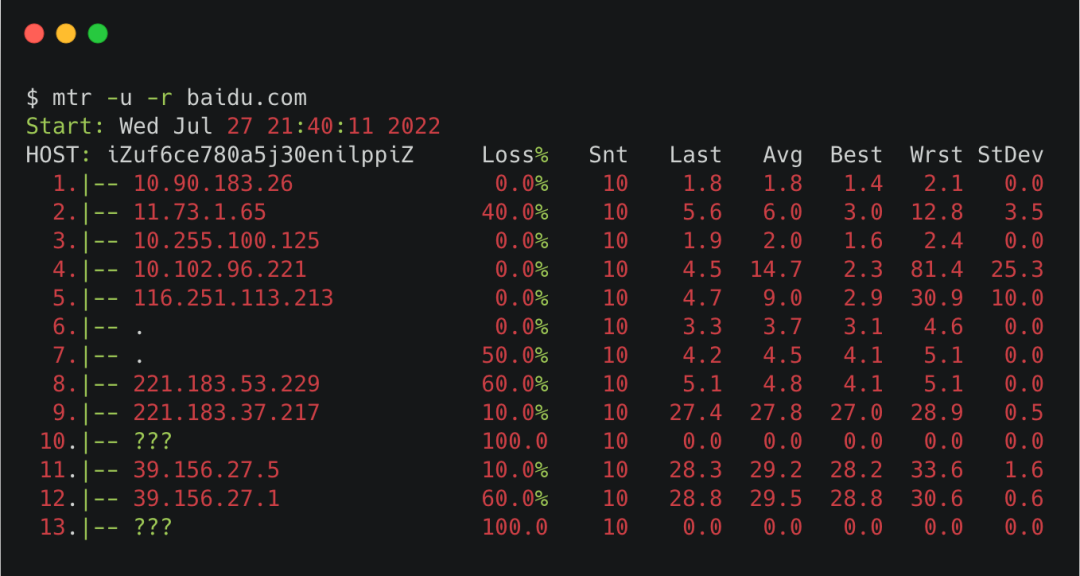 mtr-udp
mtr-udp把ICMP包和UDP包的結(jié)果拼在一起看,就是比較完整的鏈路圖了。
還有個(gè)小細(xì)節(jié),Loss那一列,我們在icmp的場景下,關(guān)注最后一行,如果是0%,那不管前面loss是100%還是80%都無所謂,那些都是節(jié)點(diǎn)限制導(dǎo)致的虛報(bào)。
但如果最后一行是20%,再往前幾行都是20%左右,那說明丟包就是從最接近的那一行開始產(chǎn)生的,長時(shí)間是這樣,那很可能這一跳出了點(diǎn)問題。如果是公司內(nèi)網(wǎng)的話,你可以帶著這條線索去找對應(yīng)的網(wǎng)絡(luò)同事。如果是外網(wǎng)的話,那耐心點(diǎn)等等吧,別人家的開發(fā)會比你更著急。
發(fā)生丟包了怎么辦
說了這么多。只是想告訴大家,丟包是很常見的,幾乎不可避免的一件事情。
但問題來了,發(fā)生丟包了怎么辦?
這個(gè)好辦,用TCP協(xié)議去做傳輸。
 TCP是什么
TCP是什么
建立了TCP連接的兩端,發(fā)送端在發(fā)出數(shù)據(jù)后會等待接收端回復(fù)ack包,ack包的目的是為了告訴對方自己確實(shí)收到了數(shù)據(jù),但如果中間鏈路發(fā)生了丟包,那發(fā)送端會遲遲收不到確認(rèn)ack,于是就會進(jìn)行重傳。以此來保證每個(gè)數(shù)據(jù)包都確確實(shí)實(shí)到達(dá)了接收端。
假設(shè)現(xiàn)在網(wǎng)斷了,我們還用聊天軟件發(fā)消息,聊天軟件會使用TCP不斷嘗試重傳數(shù)據(jù),如果重傳期間網(wǎng)絡(luò)恢復(fù)了,那數(shù)據(jù)就能正常發(fā)過去。但如果多次重試直到超時(shí)都還是失敗,這時(shí)候你將收獲一個(gè)紅色感嘆號。
?這時(shí)候問題又來了。
假設(shè)某綠皮聊天軟件用的就是TCP協(xié)議。
那文章開頭提到的女生,她男朋友回她的消息時(shí)為什么還會丟包?畢竟丟包了會重試,重試失敗了還會出現(xiàn)紅色感嘆號。
于是乎,問題就變成了,用了TCP協(xié)議,就一定不會丟包嗎?
用了TCP協(xié)議就一定不會丟包嗎
我們知道TCP位于傳輸層,在它的上面還有各種應(yīng)用層協(xié)議,比如常見的HTTP或者各類RPC協(xié)議。
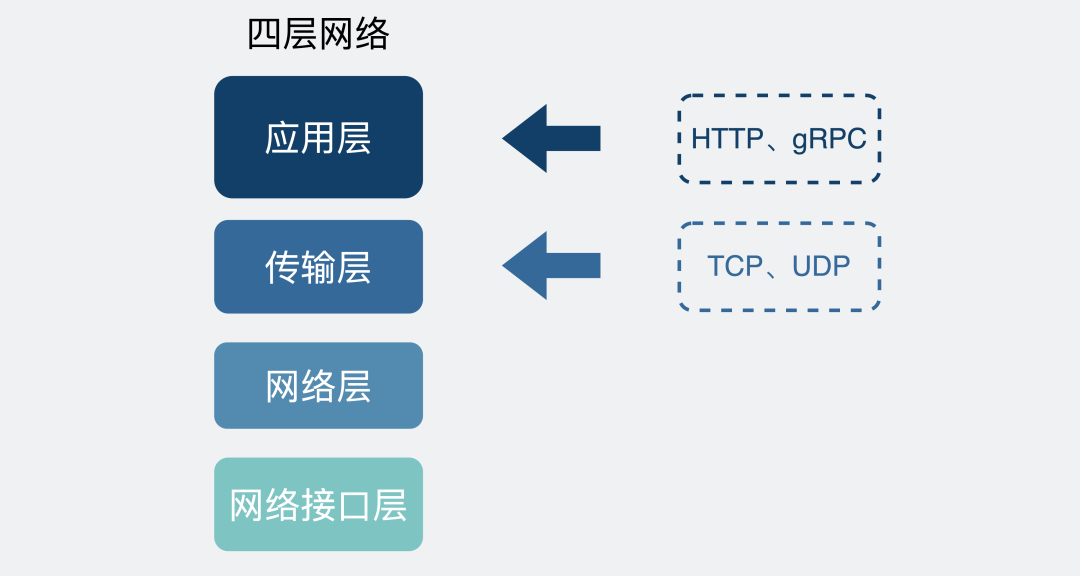 四層網(wǎng)絡(luò)協(xié)議
四層網(wǎng)絡(luò)協(xié)議TCP保證的可靠性,是傳輸層的可靠性。也就是說,TCP只保證數(shù)據(jù)從A機(jī)器的傳輸層可靠地發(fā)到B機(jī)器的傳輸層。
至于數(shù)據(jù)到了接收端的傳輸層之后,能不能保證到應(yīng)用層,TCP并不管。
假設(shè)現(xiàn)在,我們輸入一條消息,從聊天框發(fā)出,走到傳輸層TCP協(xié)議的發(fā)送緩沖區(qū),不管中間有沒有丟包,最后通過重傳都保證發(fā)到了對方的傳輸層TCP接收緩沖區(qū),此時(shí)接收端回復(fù)了一個(gè)ack,發(fā)送端收到這個(gè)ack后就會將自己發(fā)送緩沖區(qū)里的消息給扔掉。到這里TCP的任務(wù)就結(jié)束了。
TCP任務(wù)是結(jié)束了,但聊天軟件的任務(wù)沒結(jié)束。
聊天軟件還需要將數(shù)據(jù)從TCP的接收緩沖區(qū)里讀出來,如果在讀出來這一刻,手機(jī)由于內(nèi)存不足或其他各種原因,導(dǎo)致軟件崩潰閃退了。
發(fā)送端以為自己發(fā)的消息已經(jīng)發(fā)給對方了,但接收端卻并沒有收到這條消息。
于是乎,消息就丟了。
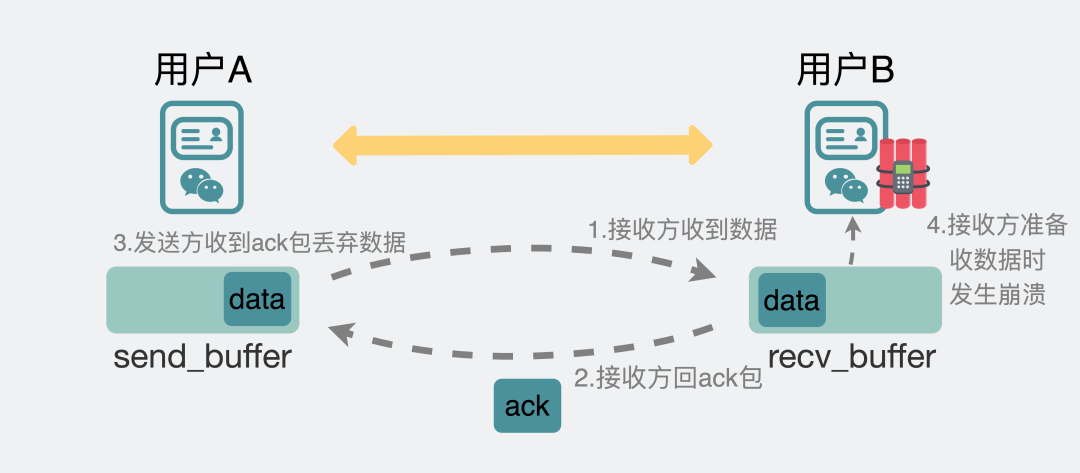 使用TCP協(xié)議卻發(fā)生丟包
使用TCP協(xié)議卻發(fā)生丟包雖然概率很小,但它就是發(fā)生了。
合情合理,邏輯自洽。
這類丟包問題怎么解決?
故事到這里也到尾聲了,感動(dòng)之余,我們來聊點(diǎn)掏心窩子的話。
其實(shí)前面說的都對,沒有一句是假話。
但某綠皮聊天軟件這么成熟,怎么可能沒考慮過這一點(diǎn)呢。
大家應(yīng)該還記得我們文章開頭提到過,為了簡單,就將服務(wù)器那一方給省略了,從三端通信變成了兩端通信,所以才有了這個(gè)丟包問題。
現(xiàn)在我們重新將服務(wù)器加回來。
聊天軟件三端通信大家有沒有發(fā)現(xiàn),有時(shí)候我們在手機(jī)里聊了一大堆內(nèi)容,然后登錄電腦版,它能將最近的聊天記錄都同步到電腦版上。也就是說服務(wù)器可能記錄了我們最近發(fā)過什么數(shù)據(jù),假設(shè)每條消息都有個(gè)id,服務(wù)器和聊天軟件每次都拿最新消息的id進(jìn)行對比,就能知道兩端消息是否一致,就像對賬一樣。
對于發(fā)送方,只要定時(shí)跟服務(wù)端的內(nèi)容對賬一下,就知道哪條消息沒發(fā)送成功,直接重發(fā)就好了。
如果接收方的聊天軟件崩潰了,重啟后跟服務(wù)器稍微通信一下就知道少了哪條數(shù)據(jù),同步上來就是了,所以也不存在上面提到的丟包情況。
可以看出,TCP只保證傳輸層的消息可靠性,并不保證應(yīng)用層的消息可靠性。如果我們還想保證應(yīng)用層的消息可靠性,就需要應(yīng)用層自己去實(shí)現(xiàn)邏輯做保證。
那么問題叒來了,兩端通信的時(shí)候也能對賬,為什么還要引入第三端服務(wù)器?
主要有三個(gè)原因。
-
第一,如果是兩端通信,你聊天軟件里有
1000個(gè)好友,你就得建立1000個(gè)連接。但如果引入服務(wù)端,你只需要跟服務(wù)器建立1個(gè)連接就夠了,聊天軟件消耗的資源越少,手機(jī)就越省電。 - 第二,就是安全問題,如果還是兩端通信,隨便一個(gè)人找你對賬一下,你就把聊天記錄給同步過去了,這并不合適吧。如果對方別有用心,信息就泄露了。引入第三方服務(wù)端就可以很方便的做各種鑒權(quán)校驗(yàn)。
- 第三,是軟件版本問題。軟件裝到用戶手機(jī)之后,軟件更不更新就是由用戶說了算了。如果還是兩端通信,且兩端的軟件版本跨度太大,很容易產(chǎn)生各種兼容性問題,但引入第三端服務(wù)器,就可以強(qiáng)制部分過低版本升級,否則不能使用軟件。但對于大部分兼容性問題,給服務(wù)端加兼容邏輯就好了,不需要強(qiáng)制用戶更新軟件。
所以看到這里大家應(yīng)該明白了,我把服務(wù)端去掉,并不單純是為了簡單。
總結(jié)
- 數(shù)據(jù)從發(fā)送端到接收端,鏈路很長,任何一個(gè)地方都可能發(fā)生丟包,幾乎可以說丟包不可避免。
- 平時(shí)沒事也不用關(guān)注丟包,大部分時(shí)候TCP的重傳機(jī)制保證了消息可靠性。
- 當(dāng)你發(fā)現(xiàn)服務(wù)異常的時(shí)候,比如接口延時(shí)很高,總是失敗的時(shí)候,可以用ping或者mtr命令看下是不是中間鏈路發(fā)生了丟包。
- TCP只保證傳輸層的消息可靠性,并不保證應(yīng)用層的消息可靠性。如果我們還想保證應(yīng)用層的消息可靠性,就需要應(yīng)用層自己去實(shí)現(xiàn)邏輯做保證。
審核編輯 :李倩
?
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
相關(guān)閱讀:
- [電子說] 環(huán)旭電子推出Pisces企業(yè)級無線路由器助力企業(yè)應(yīng)對高密度數(shù)據(jù)挑戰(zhàn) 2023-10-24
- [電子說] 拆機(jī)看看華為路由器的天線與濾波器 2023-10-24
- [電子說] 工業(yè)路由器一般都用哪種協(xié)議? 2023-10-24
- [汽車電子] 汽車電子電氣架構(gòu)車控軟件系統(tǒng)詳解 2023-10-23
- [電子說] SR-MPLS是什么?SR-MPLS的實(shí)際應(yīng)用 2023-10-23
- [移動(dòng)通信] 如何解決局域網(wǎng)ip地址不夠用問題? 2023-10-23
- [電子說] CPE一般支持哪些工作模式?與MIFI相比,優(yōu)勢在哪里? 2023-10-22
- [電子說] 介紹一種具備RDMA功能的FPGA網(wǎng)卡實(shí)現(xiàn)方案—RNIC 2023-10-22
( 發(fā)表人:李倩 )