給CPU直接開掛!從OpenPOWER的CAPI+FPGA看第二代異構計算 - 全文
什么是異構計算?可能在很多人看來感覺高深莫測,我們可以先用一個比喻來簡單的解釋一下。比如在做簡單的整數算數時,知道算法口訣的人,心算即可,但遇到比較復雜的算數問題時,就得需要一個計算器了,但在這個運算過程中,一些簡單的計算可以提前由心算完成再輸入計算器,比如計算“(5+2)÷26”,可能我們直接就輸入“7÷26”了。又或者是完全交給計算器進行計算,但這也需要人腦控制手指進行計算器的數值輸入,此時你的大腦與計算器就構成了完成這道數學計算任務的“異構計算系統(tǒng)”。
?
日常生活中最常見的異構計算——人腦+計算器
就像你的大腦的結構與計算器完全不一樣,異構計算,顧名思義就是在系統(tǒng)內參與計算的執(zhí)行單元在指令集架構(ISA, Instruction Set Architectures)層面是不同的。最為典型的例子,就是通用計算圖形處理器(GPGPU,General-Purpose computing on Graphics Processing Units),與現場可編程門陣列 (FPGA,Field-Programmable Gate Array)。從嚴格意義上講,ISA相同,只是處理核心大小同的組合,并不算是異構計算,比如英特爾的x86處理器+MIC(集成眾核加速器),以及ARM處理器的big.LITTLE大小核心的混合設計。
異構計算簡史
為什么要用異構計算,想想開頭的例子就清楚了,如果人腦就是主流的通用處理器的話,那么異構計算就是為這個處理器額外配備的“計算器”,用來執(zhí)行更高復雜度的計算或應用,而這種復雜度主要指的就是超大規(guī)模的并行處理,對于更擅長串行處理的CPU來說是一個極大的互補。
異構計算的概念本身其實并不新鮮,最早可以追溯到30年前(在某些定義中,則是以指令集的處理模式來區(qū)分異構,但基本上已并非是主流概念),可要談到異構計算的真正崛起,則要從2001年用GPU實現通用矩陣計算開始,而標志性事件發(fā)生在2005年,GPU終于在執(zhí)行LU分解(用于解線性方程組)的性能方面戰(zhàn)勝了CPU,從那之后,基于GPU的大規(guī)模并行計算方案開始嶄露頭角。
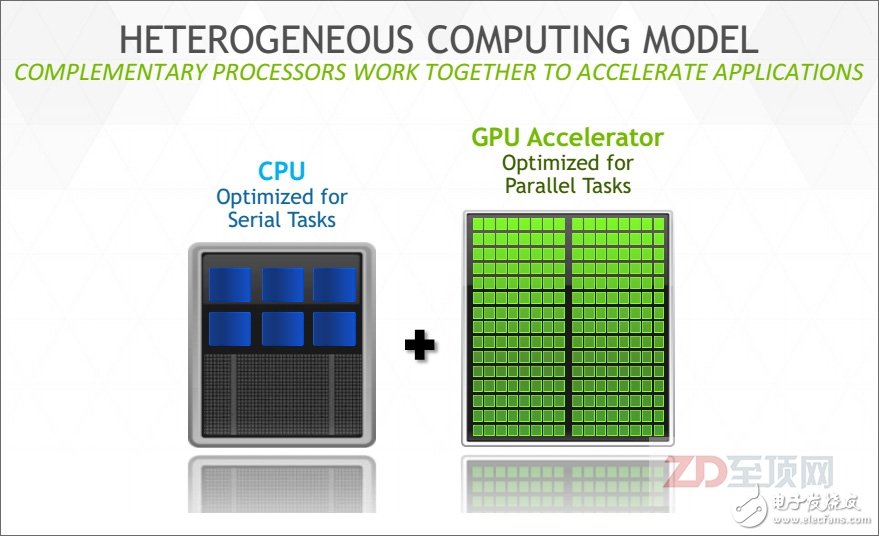
?
CPU+GPGPU是目前最為知名的異構計算組合,也是第一代異構計算的典型代表
2007年,NVIDIA推出了專門用于簡化GPU應用編程的統(tǒng)一計算設備架構(CUDA,Compute Unified Device Architecture),它標志著GPU的通用計算應用開發(fā)開始走向易用、成熟。時至今日,GPU+CPU的異構計算系統(tǒng)已經越來越多的出現在高性能計算系統(tǒng)(HPC),大大彌補了CPU在浮點運算方面的能力。
當然,在GPGPU之前其實還有多種芯片在向通用計算領域邁進,其中之一就是FPGA,它是最可匹敵于GPGPU的異構計算技術。
?
2012年英特爾發(fā)布的Atom E6x5C嵌入式處理器,就已經在單Socket封裝上整合了Altera的FPGA,但這個FPGA的主要任務不是計算,而是針對不同應用場景的I/O定制化與指定的信號處理,很難用于通用場合
FPGA于1985年誕生,很快就開始嘗試在通用計算領域的運用,可以說比GPGPU的出現還要早。GPGPU所擅長的浮點運算,FPGA同樣也在積極參與,但成果遠沒有GPGPU顯著(看看超級計算機全球TOP500的排名配置就知道了),而在整數型運算方面,雖然FPGA更有優(yōu)勢,可惜那時的計算量除非個別應用,普遍并不大,CPU自己就能搞定,所以FPGA加速更多用于細分應用市場,應用規(guī)模相對來說并不大。不過,隨著物聯網、大數據、人工智能、機器學習等新興的大規(guī)模數據處理需求的不斷涌現,現在它的機會要來了,而且底層互聯 技術也比當前的異構系統(tǒng)更為先進,它就是由OpenPOWER CAPI所開辟的新一代異構計算平臺,主打CAPI+FPGA的組合。
而在我看來,它們其實是開啟了第二代異構計算的時代。
FPGA如何為應用加速?
從第一款FPGA芯片于1985年由Xilinx(賽靈思)正式推出至今,已經有30年歷史,它是在可編程陣列邏輯(PAL,Programmable Array Logic)、通用陣列邏輯(GAL,Generic Array Logic)、復雜可編程邏輯器件(CPLD,Complex Programmable Logic Device) 等技術的基礎上進一步發(fā)展的產物。與CPU不同的是,它的邏輯是硬件可編程的,而CPU則是通過軟件編程來執(zhí)行相應的計算,和專用集成電路(ASIC,Application Specific Integrated Circuit)相比,它又相當于一種半成品的邏輯芯片,ASIC則是針對某類應用進行專門的固化設計,以達到最優(yōu)的性能。
從字面意思上就可以想像得到FPGA是一個可隨意定制內部邏輯的陣列,并且可以在用戶現場進行即時編程修改內部的硬件邏輯,這一點是CPU和ASIC都無法做到的。要想明白FPGA的原理,的確需要一定的數字電路基礎,在此只做簡要的介紹,以解釋為什么FPGA可以在某些工作上比CPU更為出色。

?
FPGA的內部主要是由用于實現硬件邏輯的邏輯塊(LB,Logic Block)、負責LB互聯的內部互聯交換節(jié)點(IS,Interconnection Switch)以及負責輸入輸出的I/O Block組成,它們都是可編程的,而隨著技術的進步,FPGA芯片里也越來越多的集成相關的固定器件與硬核(IP)電路,如乘法器、數字信號處理器(Digital Signal Processor)等,以進一步加速相關的運算,并完善相關的功能(比如I/O)
?

?
LB是FPGA內的基本邏輯單元,是FPGA可實現邏輯編程的基礎,而在LB中最常用的邏輯編程器件就是查找表(LUT,Look Up Table,又稱直譯表),通過編程它可以實現輸入與輸出的直接對應關系,從而實現了輸入與輸出的硬邏輯,在應用時,直接根據輸入的值,通過LUT給出相應的輸出值。輸入的組合根據輸入端口數量而定,比如4個端口就可實現16種輸入組合(2的4次方),而一個LB可以包含有多個LUT,實現更復雜的邏輯組合
FPGA的內部總體架構,主要是由實現硬件邏輯的邏輯塊(LB)、負責LB互聯的內部互聯交換節(jié)點(IS)以及負責輸入輸出的I/O Block組成。由于幾乎所有的邏輯電路都是通過不同門電路的組合來實現的,所以FPGA其實就是提供了數量眾多的門電路,讓用戶用硬件描述語言(HDL,Hardware Description Language)自行設計它們各自的邏輯狀態(tài)與相互之間的邏輯關系,從而讓被編程的FPGA變成為某種專用芯片,所以說FPGA是ASIC的半成品,不無道理。
事實上,FPGA在早期的一個重要的用途就是為了更好的設計ASIC,畢竟等ASIC生產出來再實驗的成本太大,而通過FPGA可以提供進行復雜的邏輯測試,來驗證ASIC的設計,并進行反復的優(yōu)化,當邏輯優(yōu)化到相當水平后,再以更為直接的邏輯實現方法形成ASIC電路,以達到更好的性能。但隨著FPGA自身的性能、能力與可實現邏輯的復雜度的不斷提升,已經逐漸可以直接代替一些中等規(guī)模的ASIC來使用,并在整體功耗上,保持對CPU的明顯優(yōu)勢。
在國內率先開發(fā)CAPI+FPGA加速卡解決方案的恒揚科技股份有限公司,大數據采集與分析產品經理張軍這樣形容FPGA,“FPGA就是一張白紙,(最終的邏輯電路)想畫什么完全由設計師決定,而 CPU或者等其他軟件編程的器件就像鉛筆畫素描畫(已經有了框架),設計師是在上面涂色彩。” 事實上,FPGA可以實現怎樣的能力,主要就取決于它所提供的門電路的規(guī)模。
現在主流的FPGA內部均采用了SRAM編程方式(SRAM本身就是一個邏輯部件可用于LUT,而SRAM晶體管可用于內部互聯鏈路的選通組合),可以實現快速的硬件編程,并能無限次的重復使用。雖然SRAM的特性決定了關機后內部邏輯組合就會消失,但基于SRAM的編程在每次開機時都可以從外部的Flash芯片即時加載FPGA配置文章,加載(編程)速度為毫秒級,所以完全不影響使用。在處理性能上,由于FPGA的邏輯實現是通過硬件編程來獲得,所以開發(fā)人員可以將指定的算法邏輯,直接以FPGA內部不同門電路的硬邏輯組合來實現,而且現在越來越多的FPGA內部都增加了固化的乘法器、DSP等處理單元,進一步加快了相關運算的處理速度。
從某種角度上說,FPGA內部其實并沒有所謂的“計算”,最終結果幾乎是“電路直給”,因此執(zhí)行效率就大幅提高。當然,由于采用的是通用的門電路組合,在某些效率上FPGA仍然不及ASIC極致,但是可重復更新內部邏輯的靈活性,再加上在固定算法上遠高于CPU的效率,讓FPGA在應用領域迅速得到重視。然而需要指出的是,用FPGA的門電路實現整數運算邏輯,要比實現浮點運算邏輯簡單得多,所以FPGA的加速優(yōu)勢也更多的體現在整數性運算,而整數運算正是當前主流企業(yè)級應用的主要運算方式,而這也是為什么GPGPU更多的用于浮點運算領域(如HPC),FPGA更多用于整數加速領域的一大原因。
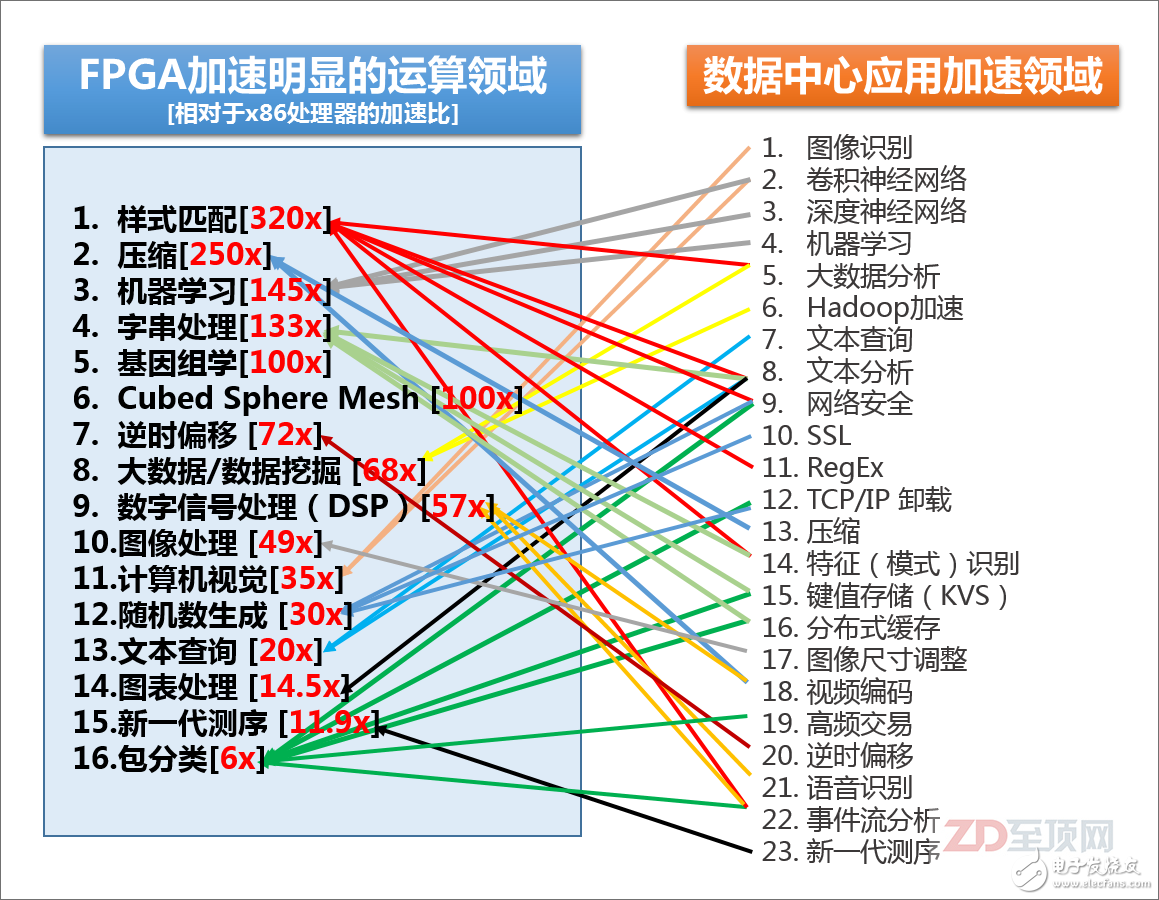
?
賽靈思總結的,目前FPGA相對于主流的x86處理器,在某些領域里的加速比,以及目前數據中心里可用到FPGA加速的領域,可以說80-90%的大規(guī)模并行密集應用都可以被FPGA加速,尤其是以整數應用為主。當然,并不是說FPGA不能用于浮點運算,但相對來說,整數型加速對于FPGA更容易實現,相對于GPGPU也有更明顯的優(yōu)勢。另外,請注意很多IT基礎設施的底層信息處理方面,如安全、加密、網絡加速、鍵值存儲也在FPGA的應用范疇之內,其“實用性”顯然比GPGPU更為廣泛
但是,傳統(tǒng)的FPGA加速設計,均是以I/O總線與CPU平臺相連,比如常見的PCIe,在系統(tǒng)內部以一個I/O設備存在,所以在實際的應用中,對于應用開發(fā)者本身來說仍然有較大的難度。這次CAPI的出現,則從根本上解決了這個難題,從而以FPGA的加速優(yōu)勢得以獲得更充分的發(fā)揮。
OpenPOWER CAPI簡介
OpenPOWER是以IBM、NVIDIA、Mellanox、Google、TYAN為首的5家公司于2013年8月發(fā)起的一個技術推廣聯盟,截止到2015年6月,OpenPOWER會員數量超過了130家,來自于中國的廠商就超過了20家。
OpenPOWER所推廣的技術就是基于IBM POWER8及以后的處理器與平臺技術,這其中POWER8處理器所具備的一致性加速處理器接口(CAPI,Coherent Accelerator Processor Interface)就是一個重要的技術點,也正是它讓FPGA迅速成為了新一代異構計算的亮點。

?
CAPI的基本原理就是通過在POWER處理器(從POWER8開始)內部設置一個一致性加速處理器代理(CAPP,Coherent Accelerator Processor Proxy),而在外置的加速卡上,則內置POWER處理器服務層(PSL,POWER Service Layer),其與CAPP配合,為加速卡在CPU上打通了一個“后門”。加速卡(PSL)與CPU(CAPP)之間采用成熟的PCIe總線+CAPI協(xié)議進行數據傳輸,但不用走復雜的PCIe I/O模式,并獲得了與CPU對等訪問虛擬內存地址的能力。目前POWER8內部共有兩個CAPP,單CPU可外接兩個CAPI加速卡
CAPI最為關鍵的重點就在于一致性(Coherent),它是能實現CAPI外設與CPU對等訪問內存的關鍵,否則在應用編程上仍然要有較大的調整。而之所以能實現這一設計,是因為在IBM提供的PSL硬核模塊(可以集成于合作伙伴的芯片,或寫入FPGA)中包含有256KB的緩存,而在CPU內部,CAPP則負責維護CAPI一側的緩存行目錄,以保證CPU級的緩存一致性(CC,Cache Coherency )。這就相當于在CPU內部額外增加了一個特殊的處理核心(相當于給CPU開了一個外掛),其對于內存的訪問與其他“正常的”CPU核心是對等的,納入到統(tǒng)一的CC范疇,這就與傳統(tǒng)的通過PCIe插卡實現加速的方式有了本質的不同。

?
在具體的FPGA加速應用中,應用透過CAPP與PSL的連接,掛載加速卡指向已經設置好的內存數據,PSL與CAPP一起協(xié)同,讓FPGA里的加速功能單元(AFU,Accelerator Functional Unit)可以與CPU實現對等訪問——可直接看到應用所指向的虛擬內存地址,并通過PCIe總線與應用溝通
在CAPI+FPGA的應用中,用戶先將相關應用的加速算法,以HDL(目前主要是Verilog HDL和VHDL)寫入FPGA,構成加速功能單元(AFU),它就是上文提到的那個“外掛的特殊CPU核心”。然后再通過PSL與CAPP的協(xié)同,將AFU“嵌入”到CPU里,被應用發(fā)現并直接調用。由于緩存一致性的保證,AFU可以直接讀寫應用所管理的虛擬內存空間,以一種嵌入式的外掛處理模式實現應用的加速。從某種意義上說,“外掛”的AFU的作用有點像CPU的加速指令集(比如SSE、MMX等),但可靈活變換且效率明顯更高。

?
在非CAPI加速體系中,傳統(tǒng)的加速卡是以一個I/O設備存在的,這必然需要虛擬地址的重新影射,從而在內存中會生成3個數據副本,并需要大量的驅動訪問指令,后果就是延遲的增加
?

?
在CAPI體系下,CAPI加速器與CPU實現了對等訪問,共享虛擬地址,數據無需轉手,直接在加速器與應用之間進行溝通。在實際使用時也很簡單,CAPI加速卡可以安裝在任何提供PCIe3.0接口的OpenPOWER Linux服務器上。應用軟件只需要調用一個CAPI函數,即可直接利用CAPI加速,而在對Linux更新驅動后,即可直接調用原有IM/GM等兼容接口函數
?

?
由于CAPI接口并非傳統(tǒng)意義上的I/O驅動模式,直接走硬件代理與CPU溝通,所以從應用的全局視角,數據的訪問步驟明顯降低(FPGA與CPU對等訪問),讓數據訪問效率大幅度提高,總延遲約是傳統(tǒng)模式的1/36,同時這種應用加速設計,對于應用的編程修改影響最小
?

?
一個典型的CAPI加速器,從準備加速到完成加速的溝通流程相當的簡潔明了,可以基本總結為——應用:CAPI加速器,我看到你了;CAPI加速器:應用,我已經為你準備好了;應用:我要處理的數據在內存地址AddrX處,剩下的工作就交給你了;CAPI加速器:好的,沒問題;(開始循環(huán)加速)……CAPI加速器:報告應用,已經處理完畢;應用:好的,你先休息吧,有事我再叫你
從以上圖片可以看出,由于CC特性的加入,讓CAPI加速卡避開了傳統(tǒng)I/O設備的驅動模式,直接以“硬件代理”的方式嵌入應用的執(zhí)行,因此在總體的命令開銷方面有明顯的減少,這直接帶來的效果就是延遲大幅降低——總延遲約只有傳統(tǒng)加速模式的1/36,并且?guī)砹烁蟮暮锰帯捎跊]有了傳統(tǒng)I/O設備層,應用平臺為了適配加速器的編程修改非常小,應用開發(fā)者完全可以將應用做成自適應模式,在非CAPI平臺上采用傳統(tǒng)的處理模式,當發(fā)現系統(tǒng)有CAPI加速器則自動打開CAPI模式,這顯然非常有利于CPAI加速模式在相關應用領域里的普及。
在具體的應用環(huán)境中,目前CAPI還不能用于虛擬化平臺(比如OpenKVM),但完全支持基于Linux核心的Docker容器平臺(現在的CAPI全面支持Ubuntu 14.10)。按照IBM未來的發(fā)展規(guī)劃,新一代CAPI正在路上,它將基于PCIe 4.0規(guī)格(也可能會采用新的總線接口),并稍加改動,連接帶寬較PCIe 4.0稍微提高,以抵銷CAPI協(xié)議的開銷,從而讓加速器可以充分利用到PCIe的帶寬。另外,CAPI的虛擬化(多個應用可以分時復用加速器)也將是必然的,并且單一PSL未來可以掛載多個AFU,在FPGA內部可以同時具備4個AFU,PSL分別為它們保存各自的虛擬空間地址,并與CAPP一起保持緩存一致性,這就相當于給系統(tǒng)同時配備了4個外掛核心。在操作系統(tǒng)方面,未來還將支持AIX、RedHat等OS,這將意味著除了PowerLinux平臺,傳統(tǒng)的AIX POWER服務器上的應用也將能享受到CAPI加速。
CAPI+FPGA應用實戰(zhàn)
借助于OpenPOWER聯盟,很多廠商都投入到了CAPI+FPGA的加速卡設計中,中國的恒揚科技股份有限公司(Semptian)即是其中之一,其最新推出的Semptian NSA-120是一款基于XILINX Kintex UltraScale FPGA的CAPI PCIe板卡,采用PCIE x8 Gen3 接口規(guī)格,支持兩路DDR3 1600 SODIMM(容量為2x8GB),而首先投入的AFU,是針對大數據存儲中常用的糾刪碼(Erasure Code)的編/解碼加速。

?
糾刪碼是應對降低海量分布式存儲占用空間的常用手段,相對于傳統(tǒng)的3復本冗余的存儲模式(相當于3x容量占用),糾刪碼冗余的存儲容量只相當于原數據量的1.4x,降低了超過50%的存儲空間需求,但在大規(guī)模數據讀寫過程中,糾刪碼的實時編/解碼運算對于服務器CPU來說將是一個比較大的占用,在分布式應用架構中,這意味著將影響應用本身的性能
?

?
通過Semptian NSA-120的加速,獲得了明顯的糾刪碼的性能提升,如果再多加一塊Semptian NSA-120(雙CPU配置時最多可插4塊),性能還會進一步提高
?

?
為了進一步方便ISV與AFU的開發(fā)者,恒揚科技專門提供了NPL(NSA Platform Layer),即FPGA基礎平臺,幫助AFU開發(fā)者硬件無感知的開發(fā)AFU算法單元
根據恒揚科技大數據采集與分析產品經理張軍的介紹,目前FPGA的編程環(huán)境已經有了很大的改善,這其中OpenCL開發(fā)平臺的發(fā)展直到了重要的推進作用。雖然現在仍然很初級,但對于傳統(tǒng)的應用開發(fā)者來說,借助OpenCL開放的標準化平臺,已經可以相對較為容易的上手,而在底層編程部分,仍然會通過FPGA廠商的專用工具進行HDL編譯,再寫入FPGA。此外,FPGA廠商也在像NVIDIA那樣,提供自己的集成開發(fā)環(huán)境(IDE),它的作用相當于CUDA之于GPGPU,為開發(fā)者提供更完整的工具包,加速FPGA的編程。比如賽靈思的 SDAccel開發(fā)環(huán)境,就可為賽靈思的FPGA加速OpenCL、C和C++內核的開發(fā)與部署。相應的CAPI-FPGA加速卡廠商,也會提供底層平臺,方便開發(fā)者基于自己的板卡進行AFU開發(fā)。比如恒揚科技就提供了NPL和相關的SDK,可以讓開發(fā)者專心于AFU的算法實現。
另一個典型的CAPI加速實例則是外置存儲加速,IBM基于CAPI控制卡+自己的FlashSystem全閃存陣列,提供了一套NoSQL數據引擎,由于CAPI將傳統(tǒng)的PCIe控制卡的I/O開銷省去,大大降低了系統(tǒng)延遲,成為KVS數據平臺更好的選擇。

?
IBM基于支持CAPI+全閃存陣列而推出NoSQL數據加速引擎,配套全閃存陣列可以通過CAPI加速卡直接訪問應用內存空間,大大降低了數據傳輸的延遲,非常有利于單筆數據訪問量少,但IO密集的鍵值存儲(KVS,Key-Value Store)平臺
?

?
通過與非CAPI控制卡連接的性能相對比,可以看出由于CAPI連接并不是傳統(tǒng)的I/O驅動模式,而近似于CPU直聯,所以在IOPS性能與延遲性能上較傳統(tǒng)的PCIe控制卡有明顯的提升,不過如果是大數據塊傳輸,CAPI控制卡在總帶寬上可能會有一定劣勢,但到下一代CAPI這將不再是問題
第二代異構計算與未來應用愿景
如果說以GPGPU為主,大幅度提高系統(tǒng)浮點運算能力是第一代異構加速計算的典型特征的話,我們現在可以基本總體出以FPGA為主,所謂的第二代異構計算的一些重要特征:第一:具備緩存一致性的內存訪問能力,這是最為重要的特征,與第一代異構計算有了本質的不同,并對應用編程具備了明顯的友好性;第二:基于FPGA可靈活配置加速模塊,毫無疑問,在第二代異構計算中,FPGA將是一大主角,它本身靈活的可編程性為應用加速提供了豐富的應用場景;第三、它將隆重開啟整數運算加速的大門,隨著FPGA編程的便利性進一步提高,FPGA的整數型加速將會迅速普及(當然絕不是說FPGA不能用于浮點加速,只是看應用比例),這對于當前的大數據、海量視頻處理、圖像匹配等新興需求不謀而合,就像當初GPGPU與科學計算的發(fā)展相得益彰一樣,第二代異構計算將把相應的整數型應用的性能帶到新的高度。
當然,看到這一趨勢的不僅僅是IBM與OpenPOWER,CPU巨頭英特爾以167億美元收購FPGA第二大廠Altera的用意也不言自明。在不久前結束的IDF15上(英特爾信息技術峰會2015美國站),英特爾正式發(fā)布了CPU通過QPI直聯FPGA的方案設計。

?
采用QPI接口與CPU互聯,明擺著是沖著緩存一致性而來,這與CAPI的思路異曲同工,并且在服務器的配置上給出了新的可能(比如FPGA芯片Socket化或直接板載),這與CAPI有了明顯的不同,可謂各有利弊,但共同點都是開啟了第二代異構計算的時代
當越來越多的FPGA加速芯片以各種緩存一致性的方式接入系統(tǒng)之后,由于FPGA的SRAM高速編程模式,理論上講FPGA可以迅速的且無限次的更新內置的AFU,以應對不同的應用加速需求。這就給我們打開了一個想像空間——能否像Docker管理容器鏡像那樣,基于云+端的概念建立起一個AFU鏡像的集散中心呢?事實上,OpenPOWER聯盟也正在為此而努力——建立AFU鏡像商店。

?
OpenPOWER CAPI-FPGA加速卡AFU鏡像商店的更新流程(筆者猜想繪制,謹供參考)
屆時,任何相關的開發(fā)者、ISV都可以將自己針對某些具體的FPGA卡(經CAPI認證)所編寫的AFU鏡像(其實就是FPGA的編程配置文件),上傳至AFU商店供其他用戶免費或有償使用。相關的AFU用戶則可以像Docker那樣,根據自己應用加速的需求與FPGA加速卡的型號,免費或付費下載相應的AFU鏡像,通過全局的管理平臺,分發(fā)給指定服務器上的CAPI更新控制器,由后者與指定的FPGA加速卡(一臺服務器可以有多塊加速卡,選擇更新)PSL內的AFU更新模塊一起加載AFU鏡像。加載的方式有兩種,一種是完整的FPGA重寫(所有的門電路重寫,包括PSL),另一種則是AFU單獨更新。前者需要重起服務器,而后者則可以在線動態(tài)更新。目前100萬門的FPGA的配置文件容量也就在50MB左右,由于是基于SRAM的硬件編程,100ms內即可更新完畢,用戶幾乎沒有察覺,但服務器的加速功能就已經完全改變了。
我們可以試想一下這樣的場景,對于某個內置CAPI+FPGA加速器的服務器集群,可以靈活的根據工作負載的需求改變FPGA中的AFU模塊,讓這個集群迅速具備針對新負載的加速能力,這對于集群高效的多場景靈活復用顯然是很有幫助的,而這種模式也是GPGPU、DSP、ASIC等加速方式很難做到的。
展望未來,從某種角度上講,GPGPU與FPGA在未來的應用系統(tǒng)中,將根據自身的特長有所側重。如果將CPU比作人的話,GPGPU更像是高級計算器,為人類提供強大的科學計算的能力,做好學術研究,而FPGA更像是為某類工作定制的效率工具,執(zhí)行大量的固定而高度重復化的工作,大幅度提高人類的日常生活與工作效率(比如洗衣機、生產機器人),而人在未來更多的就是負責管理,用好計算器與效率工具——CPU的角色相信也會如此,隨著技術的不斷發(fā)展,更多的浮點與整數運算任務將會被GPGPU、FPGA、DSP、ASIC等不同的加速器所分擔。
從第二代異構計算至第二代分布式計算?
基于上文所分析的CAPI+FPGA所展現出來的能力,我們進一步從單服務器延展至整個分布式計算的架構,這就需要我們從一個更為廣闊的全局視角來看待第二代異構計算所帶來的關鍵影響。不久前,IBM提出的“第二代分布式計算”理念也正是基于這一全局的層次來建立的(據說在9月16日會召開發(fā)布會進行專門的闡述 )。
IBM中國研究院的高級研究員陳飛表示,IBM提出的第二代分布式計算要有四個重要的特征,第一個特征:加速器的軟硬件接口有統(tǒng)一的接口規(guī)范,以便于更好的協(xié)同管理與普適(第一代分布式計算的接口標準較為統(tǒng)一,畢竟只有CPU本身,相對更標準化),這方面CAPI就是一個標準化接口的嘗試。第二個特征:加速器可以被動態(tài)的在線被設備發(fā)現以及加載。比如不需要要求系統(tǒng)的重啟,但現在的加速器如果要改變功能,一般都要要求重啟,或者是重啟一些軟件服務,但CAPI+FPGA則沒有這個顧慮。第三個特征:分布式的系統(tǒng)要具備全局異構資源的調度能力,也就是說它能決定哪些應用運行在一個具有這種加速硬件的計算節(jié)點上,還是跑在一個普通的純CPU的計算節(jié)點上。第四個特征:應該軟件本身,具備兼容CPU運行模式和異構硬件運行模式的能力。

NVIDIA推出NVLINK互聯總線,除了可作為GPU之間的互聯外,還可用于CPU與GPU的互聯,并也將具備緩存一致性的內存訪問能力,IBM的POWER9處理器(預計2017年下半年發(fā)布)將具備這一接口,這就意味著在POWER9平臺上NVIDIA的GPU也會獲得與CAPI同樣的對等訪問能力,這樣的GPGPU加速能力也將是POWER9獨有的(在英特爾x86平臺上,與CPU的互聯連接仍然是傳統(tǒng)的PCIe模式,NVLINK僅用于NVIDIA GPU之間的互聯),對IBM所提出的第二代分布式計算理念無疑是一個有力支撐
從以上定義中,我們可以看出,正是CAPI+FPGA所具備的一些關鍵特性(緩存一致性、在線更新性、AFU替換能力等)為IBM所提出的第二代分布式計算打下了理論基礎。當然,對于這個定義,我仍然有一些異議,畢竟從總體上講,這個分布式處理的基礎架構與應用分布處理的模式,和第一代相比并沒有本質的不同,更多是分布式節(jié)點上處理模式的創(chuàng)新,并且由于加速體系標準的更加多樣化,也讓其普適性受到懷疑,除非有非常強大的全局管理平臺來屏蔽掉底層的硬件差異性,否則全局上的“加速孤島”現象不可避免(雖然對于具體的用戶來說,這可能不是問題)。
但是,不管怎樣,第二代異構計算的模式,的確打開了我們的想像空間,它是否真的帶來理想中的第二代分布式計算體系,還要看IBM、英特爾以及加速器、方案集成等前沿廠商的共同努力!不過,可以肯定的是,不管這種新興的處理模式將如何稱謂,它對于新時代下的信息處理平臺(大數據分析、物聯網、人工智能、機器學習等)所帶來的明顯幫助,以及為最終用戶創(chuàng)造的巨大價值,都將是毋庸置疑的!
- 第 1 頁:給CPU直接開掛!從OpenPOWER的CAPI+FPGA看第二代異構計算
- 第 2 頁:OpenPOWER CAPI簡介
- 第 3 頁:第二代異構計算與未來應用愿景
本文導航
非常好我支持^.^
(1) 100%
不好我反對
(0) 0%
相關閱讀:
- [電子說] Blackwell GB100能否在超級計算機和AI市場保持領先優(yōu)勢? 2023-10-24
- [電子說] 3線串行數據通訊EEPROM的使用 2023-10-23
- [電子說] 浩辰軟件深耕CAD領域 致力于成為行業(yè)標桿企業(yè) 2023-10-23
- [電子說] SymPy:四行代碼秒解微積分 2023-10-21
- [電子說] 強固型智慧工廠解決方案:BOXER-6406-AND 2023-10-21
- [電子說] 飛秒激光器在醫(yī)學上的應用 2023-10-21
- [電子說] TCP/IP協(xié)議和OPC協(xié)議的區(qū)別 2023-10-20
- [電子說] 機器視覺系統(tǒng)的基本原理 機器視覺技術的發(fā)展現狀和應用 2023-10-19
( 發(fā)表人:郭婷 )