 電子發(fā)燒友App
電子發(fā)燒友App


當與區(qū)塊鏈數(shù)據(jù)集一起使用時,機器學習模型往往會過度擬合。什么是過度擬合,如何解決?
使用機器學習來分析區(qū)塊鏈數(shù)據(jù)集的想法乍一看非常吸引人,但它充滿了挑戰(zhàn)。在這些挑戰(zhàn)中,缺少標記的數(shù)據(jù)集仍然是應用機器學習方法到區(qū)塊鏈數(shù)據(jù)集時需要克服的最大困難。
這些限制導致許多機器學習模型使用非常小的數(shù)據(jù)樣本進行訓練和過度優(yōu)化,從而導致一種稱為過度擬合的現(xiàn)象。今天,我想深入探討一下區(qū)塊鏈分析中的過度擬合問題,并提出一些解決方法。
過度擬合被認為是現(xiàn)代深度學習應用中最大的挑戰(zhàn)之一。從概念上講,當模型生成的假設過于針對特定數(shù)據(jù)集而導致無法適應新數(shù)據(jù)集時,就會發(fā)生過度擬合。
理解過度擬合的一個有用的類比是將其視為模型中的幻覺。本質上,當一個模型從數(shù)據(jù)集中推斷出不正確的假設時,它就會產生幻覺/過度擬合。
自從早期的機器學習以來,已經有很多關于過度擬合的文章,所以我不認為有任何聰明的方法來解釋它。在區(qū)塊鏈數(shù)據(jù)集的情況下,過度擬合是缺乏標記數(shù)據(jù)的直接結果。區(qū)塊鏈是大型的、半匿名的數(shù)據(jù)結構,在這種結構中,所有東西都用一組公共結構表示,比如交易、地址和區(qū)塊。
從這個角度來看,區(qū)塊鏈記錄的限定信息是最少的。是交易、轉賬還是付款?是個人投資者的錢包還是交易所的冷錢包?這些限定詞對于機器學習模型是必不可少的。
假設我們正在創(chuàng)建一個模型來檢測一組區(qū)塊鏈中的交換地址。這個過程需要我們使用現(xiàn)有的區(qū)塊鏈地址數(shù)據(jù)集來訓練模型,我們都知道這些數(shù)據(jù)集并不常見。如果我們使用EtherScan或其他來源的小數(shù)據(jù)集,模型可能會過度擬合并做出錯誤的分類。
使過度擬合如此具有挑戰(zhàn)性的一個方面是,很難在不同的深度學習技術中推廣。卷積神經網絡傾向于形成與遞歸神經網絡不同的過擬合模式,而遞歸神經網絡又不同于生成模式,這種模式可以外推到任何類型的深度學習模型。
具有諷刺意味的是,過度擬合的傾向與深度學習模型的計算能力成線性關系。由于深度學習代理可以生成復雜的假設,而且?guī)缀醪恍枰魏纬杀荆虼诉^度擬合的傾向就會增加。在機器學習模型中,過度擬合是一個持續(xù)的挑戰(zhàn),但在處理區(qū)塊鏈數(shù)據(jù)集時,它幾乎是一個給定的問題。解決過度擬合的明顯方法是使用更大的訓練數(shù)據(jù)集,但這并不總是可行的。在IntoTheBlock,我們經常遇到過度擬合的挑戰(zhàn)。
在區(qū)塊鏈數(shù)據(jù)集中對抗過度擬合的三個簡單策略
與過度擬合作斗爭的首要原則是認識到它。雖然沒有防止過度擬合的靈丹妙藥,但實踐經驗表明,一些簡單的、幾乎是常識的規(guī)則有助于在深度學習應用中防止這種現(xiàn)象。
在已經發(fā)布的防止過度擬合的幾十個最佳實踐中,有三個基本的思想包含了其中的大多數(shù)。
數(shù)據(jù)/假設比率
過度擬合通常發(fā)生在一個模型產生了太多的假設而沒有相應的數(shù)據(jù)來驗證它們的時候。因此,深度學習應用程序應該嘗試在測試數(shù)據(jù)集和應該評估的假設之間保持適當?shù)谋壤H欢@并不總是一個選擇。
有許多深度學習算法,如歸納學習,依賴于不斷產生新的,有時更復雜的假設。在這些場景中,有一些統(tǒng)計技術可以幫助估計正確的假設數(shù)量,從而優(yōu)化找到接近正確的假設的機會。
雖然這種方法不能提供準確的答案,但它有助于保持假設數(shù)量和數(shù)據(jù)集組成之間的統(tǒng)計平衡。哈佛大學教授萊斯利·瓦蘭特在他的書中精采地解釋了這一概念。
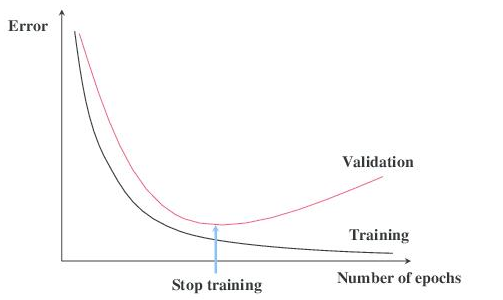
當進行區(qū)塊鏈分析時,數(shù)據(jù)/假設的比例非常明顯。假設我們正在構建一個基于一年區(qū)塊鏈交易的預測算法。
因為我們不確定要測試哪個機器學習模型,所以我們使用神經架構搜索(NAS)方法,該方法針對區(qū)塊鏈數(shù)據(jù)集測試數(shù)百個模型。
考慮到數(shù)據(jù)集只包含一年的交易,NAS方法可能會生成一個完全適合訓練數(shù)據(jù)集的模型。
支持簡單的假設
在深度學習模型中,防止過度擬合的一個概念上瑣碎但技術上困難的想法是不斷生成更簡單的假設。當然!簡單總是更好的,不是嗎?
但在深度學習算法的背景下,有什么更簡單的假設呢?如果我們需要將其歸結為一個量化的因素,我會說深度學習假設中屬性的數(shù)量與復雜度成正比。
簡單的假設往往比其他有大量屬性的假設更容易評估,無論是在計算上還是在認知上。
因此,與復雜的模型相比,簡單的模型通常不太容易過度擬合。下一個明顯的難題是如何在深度學習模型中生成更簡單的假設。
一種不太明顯的技術是根據(jù)算法的估計復雜度對其附加某種形式的懲罰。這種機制傾向于更簡單、更準確的假設,而不是更復雜、有時更準確的假設。
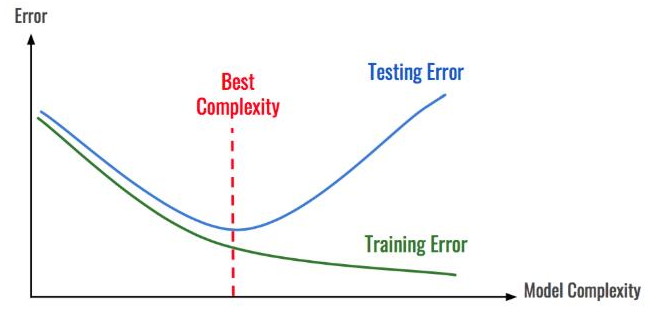
為了在區(qū)塊鏈分析中解釋這個概念,讓我們假設我們正在構建一個在區(qū)塊鏈中對支付交易進行分類的模型。
該模型使用一個復雜的深度神經網絡生成1000個特征來進行分類。如果應用于較小的區(qū)塊鏈,如Dash或Litecoin,該模型很可能會過度擬合。
偏差/方差平衡
偏差和方差是深度學習模型的兩個關鍵估計量。從概念上講,偏差是我們模型的平均預測值與我們試圖預測的正確值之間的差異。高偏差模型對訓練數(shù)據(jù)的重視程度低,模型過于簡化。它往往會導致訓練和測試數(shù)據(jù)的高誤差。
或者,方差指的是模型對給定數(shù)據(jù)點或值的預測的可變性,它告訴我們數(shù)據(jù)的分布。高方差模型對訓練數(shù)據(jù)非常重視,對未見過的數(shù)據(jù)不進行泛化。因此,這樣的模型在訓練數(shù)據(jù)上表現(xiàn)得很好,但在測試數(shù)據(jù)上有很高的錯誤率。
偏差和方差如何與過度擬合相關?在超簡單的術語中,概括的藝術可以通過減少模型的偏差而不增加其方差來概括。
在深度學習模型中,定期將生成的假設與測試數(shù)據(jù)集進行比較并評估結果是一個很好的實踐。如果假設繼續(xù)輸出相同的錯誤,那么我們就有一個很大的偏差問題,我們需要調整或替換算法。如果錯誤沒有清晰的模式,那么問題就是不一致,我們需要更多的數(shù)據(jù)。總而言之:
· 任何低復雜度的模型都會因為高偏差和低方差而傾向于擬合不足。
· 任何高復雜度的模型(深度神經網絡)都會因為低偏差和高方差而傾向于過度擬合。
在區(qū)塊鏈分析中,偏差-方差摩擦無處不在。讓我們回到我們的算法,試圖預測價格與許多區(qū)塊鏈因素。如果我們使用簡單的線性回歸方法,模型很可能不適合。然而,如果我們使用一個具有小數(shù)據(jù)集的超級復雜的神經網絡,模型可能會過度擬合。
使用機器學習來分析區(qū)塊鏈數(shù)據(jù)是一個非常新興的領域。因此,大多數(shù)模型都遇到了機器學習應用程序的傳統(tǒng)挑戰(zhàn)。
過度擬合是區(qū)塊鏈分析中無處不在的挑戰(zhàn)之一,其根本原因是缺乏標記數(shù)據(jù)和訓練過的模型。沒有什么神奇的解決方案可以解決過度擬合的問題,但是本文中列出的一些原則已經被證明對IntoTheBlock是有效的。
責任編輯:Ct









 工商網監(jiān)
工商網監(jiān)
評論