怎樣讓聊天機(jī)器人讀懂對(duì)話歷史
推薦 + 挑錯(cuò) + 收藏(0) + 用戶評(píng)論(0)
人工智能現(xiàn)在的火熱程度大家有目共睹,凱文凱利在《必然》中預(yù)測(cè)未來(lái)時(shí)代的人工智能可能會(huì)重新定義人類的意義,但時(shí)下的人工智能發(fā)展水平顯然還沒(méi)有大家想象得那么美好,仍然需要我們不斷地探索。目前眾多研究人員正深耕其中,作為其中代表的聊天機(jī)器人(Chatbot),已然成為科研界研究的熱點(diǎn)。
通常來(lái)說(shuō)聊天機(jī)器人實(shí)現(xiàn)方式有兩種:一種是基于生成式,即機(jī)器人“自己說(shuō)話”,一個(gè)字一個(gè)字創(chuàng)作出回復(fù)語(yǔ)句來(lái)。另外一種是基于檢索式,即機(jī)器人“轉(zhuǎn)發(fā)”別人的話。從互聯(lián)網(wǎng)大家的話語(yǔ)中尋找到合適的回答予以轉(zhuǎn)發(fā)。
現(xiàn)有的生成結(jié)果由于技術(shù)所限,或多或少都存在語(yǔ)句不流暢的問(wèn)題,但能夠做到“有問(wèn)必答”偶爾還能蹦出“彩蛋”。檢索的模型一般流暢性方面無(wú)須擔(dān)心,不過(guò)隨著目前網(wǎng)絡(luò)資源的日益豐富,語(yǔ)料規(guī)模也越來(lái)越大,如何從眾多語(yǔ)句中選擇合適的句子作為回復(fù)是檢索式聊天機(jī)器人的核心問(wèn)題。
雖然目前市場(chǎng)上的聊天機(jī)器人眾多,但我們見(jiàn)到的那些貌似都不是那么聰明。最直觀的一個(gè)體現(xiàn)就是前后不連貫,上下難銜接,因此在進(jìn)行檢索的時(shí)候考慮歷史信息則顯得尤為重要。那么如何讓機(jī)器人理解對(duì)話歷史信息從而聰明地進(jìn)行回復(fù)呢?微軟亞洲研究院的研究員們提出了一個(gè)模型Sequential Matching Network(SMN)。相關(guān)論文的作者吳俁談到“SMN模型可以讓聊天機(jī)器人準(zhǔn)確的理解當(dāng)前和用戶的對(duì)話歷史,并根據(jù)歷史給出最相關(guān)的回復(fù),與用戶進(jìn)行交流,達(dá)到人機(jī)對(duì)話的目的。”
但這在實(shí)現(xiàn)的過(guò)程中也遇到不少難點(diǎn),“精準(zhǔn)計(jì)算聊天歷史和候選回復(fù)的語(yǔ)義相似度十分困難,主要的挑戰(zhàn)有兩個(gè)方面:
由于聊天歷史信息繁多,如何將歷史中重要的詞語(yǔ)、短語(yǔ)以及句子選擇出來(lái),并通過(guò)這些重要部分刻畫聊天歷史,是一個(gè)亟待解決的問(wèn)題;
如何對(duì)聊天歷史中的各輪對(duì)話進(jìn)行建模,如何判斷對(duì)話歷史中的跳轉(zhuǎn),順承等關(guān)系,也是一個(gè)棘手的問(wèn)題。” 那么論文作者提出的SMN模型又是如何解決這兩個(gè)問(wèn)題的呢,接下來(lái)我們將為您解讀。
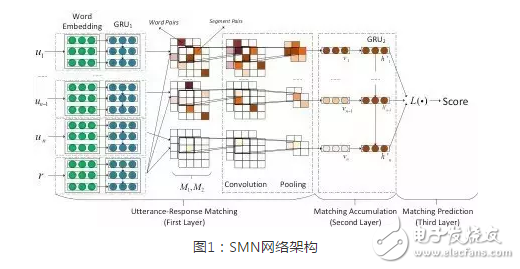
圖1:SMN網(wǎng)絡(luò)架構(gòu)
SMN模型一共分為三層。第一層為信息匹配層,對(duì)之前的歷史信息和待回復(fù)的句子進(jìn)行匹配度計(jì)算:同時(shí)進(jìn)行詞語(yǔ)(embedding向量)和短語(yǔ)級(jí)別(GRU表示)的相似度計(jì)算。然后再把這兩個(gè)矩陣分別作為卷積神經(jīng)網(wǎng)絡(luò)的一個(gè)channel,利用CNN的max-pooling進(jìn)行特征抽象,形成一個(gè)匹配向量。第二層為匹配積累層,利用一個(gè)GRU神經(jīng)網(wǎng)絡(luò),將每一句話和回復(fù)所計(jì)算出的匹配信息進(jìn)一步融合。第三層為匹配結(jié)果預(yù)測(cè)層,利用融合的匹配信息計(jì)算最終的匹配得分,在預(yù)測(cè)時(shí)他們使用三種策略,分別是只利用GRU2最后一個(gè)隱藏層(SMN_last),靜態(tài)加權(quán)隱藏層(SMN_static),和動(dòng)態(tài)加權(quán)隱藏層(SMN_dynamic)。在進(jìn)行檢索的時(shí)候,他們將最后一句的信息結(jié)合上文歷史信息中的5個(gè)關(guān)鍵詞(歷史信息中用tf-idf進(jìn)行篩選,選擇Top5關(guān)鍵詞)在系統(tǒng)中進(jìn)行檢索,然后用上述SMN網(wǎng)絡(luò)對(duì)候選結(jié)果打分從而選出回復(fù)句。
作者分別在Ubuntu語(yǔ)料(大型公開(kāi)計(jì)算機(jī)相關(guān)求助與解答語(yǔ)料)和豆瓣語(yǔ)料(作者從豆瓣小組的公開(kāi)信息中爬取并在論文中公布)上進(jìn)行了實(shí)驗(yàn),分別以Rn@K和MAP、MRR、P@1為評(píng)價(jià)指標(biāo),取得的結(jié)果均為目前最好。
作者表示“SMN不同以往的模型,第一步不進(jìn)行上下文的建模學(xué)習(xí),而是讓每句話和回復(fù)進(jìn)行匹配度計(jì)算,這樣可以盡可能多的保留上下文的信息,以避免重要信息在學(xué)習(xí)上下文的向量表示時(shí)丟失。而且SMN在對(duì)上下文句子關(guān)系建模時(shí),考慮了當(dāng)前回復(fù)的影響,使得回復(fù)成為一個(gè)監(jiān)督信號(hào),這樣可以更準(zhǔn)確的對(duì)上下文歷史進(jìn)行建模。”并且吳俁向我們透露“據(jù)我們所知,我們公布的豆瓣語(yǔ)料是第一個(gè)人工標(biāo)注的中文多輪對(duì)話語(yǔ)料。”
在談及目前的方法還有哪些不足之處時(shí),作者表示“目前我們的檢索方式有時(shí)找不到正確的候選句,所以第一步的檢索方法還有待改善,另外雖然我們的模型可以建模當(dāng)前回復(fù)和歷史信息的關(guān)系,但還是無(wú)法避免一些邏輯上的問(wèn)題,不過(guò)這也是我們未來(lái)工作的重點(diǎn),我們將繼續(xù)提高候選回復(fù)在邏輯上的連貫性”,讓我們共同期待他們的未來(lái)工作。
非常好我支持^.^
(0) 0%
不好我反對(duì)
(0) 0%
下載地址
怎樣讓聊天機(jī)器人讀懂對(duì)話歷史下載
相關(guān)電子資料下載
- 如何使用Rust創(chuàng)建一個(gè)基于ChatGPT的RAG助手 43
- 如何創(chuàng)建FPGA控制的機(jī)器人手臂? 219
- 如何創(chuàng)建FPGA控制的機(jī)器人手臂 49
- 邁爾微視MRDVS發(fā)布多模態(tài)避障相機(jī)S2 90
- iTR機(jī)器人iScrubbot系列清潔機(jī)器人實(shí)現(xiàn)數(shù)字化管理 136
- 哈爾濱工業(yè)大學(xué)研發(fā)液態(tài)金屬磁性微型軟體機(jī)器人 20
- 智能時(shí)代的三大核心技術(shù) 57
- EPR6-S工業(yè)機(jī)器人通過(guò)EtherCAT轉(zhuǎn)profinet網(wǎng)關(guān)接入西門子系統(tǒng) 135
- 智能工廠系統(tǒng)集成解決方案 25
- 奧比中光3D相機(jī)矩陣助力更強(qiáng)機(jī)器人開(kāi)發(fā) 193