Mesos高可用集群解決方案
大小:0.7 MB 人氣: 2017-10-10 需要積分:1
標簽:
作者:王勇橋,80后的IT攻城獅,供職于IBM多年,Mesos和Swarm社區的貢獻者。責編:魏偉,歡迎投稿和咨詢報道,詳情聯系weiwei@csdn.net
本文節選自 《程序員》,謝絕轉載,更多精彩,請 訂閱《程序員》
CSDN Docker專家群已經建立,還等什么,加入我們吧:微信搜索“ k15751091376”
本文系作者根據自己對Mesos的高可用(High-Availability)設計方案的了解以及在Mesos社區貢獻的經驗,深度剖析了Mesos集群高可用的解決方案,以及對未來的展望。
Mesos高可用架構概述
首先,我們來參考Mesos官方的設計架構,如圖1所示。
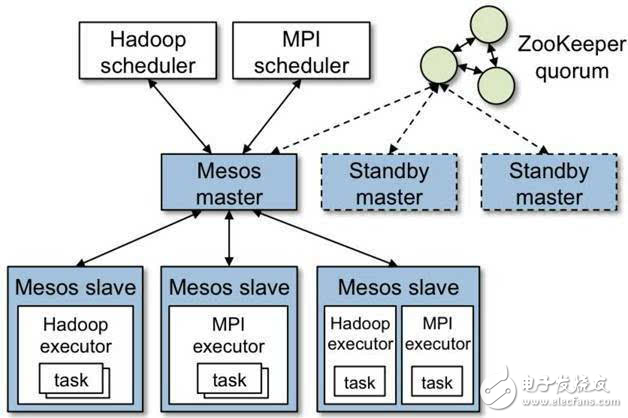
圖1 Mesos設計架構(官方)
Mesos采用的也是現在分布式集群中比較流行的Master/Slave主從集群管理架構,Mesos master節點是整個集群的中樞,它責管理和分配整個Mesos集群的計算資源,調度上層Framework提交的任務,管理和分發所有任務的狀態。這種主從架構設計簡單,能夠滿足大多數正常情況下的集群運作需求,目前仍然存在于很多分布式的系統中,比如Hadoop、MySQL集群等。但是這種簡單的設計存在一個致命缺陷,就是Mesos master必須做為一個服務程序持續存在于集群中,它雖然孤立,但是地位舉足輕重,不容有失。
在單個Mesos master節點的集群中,如果Mesos master節點故障,或者服務不可用,雖然在每一個Slave節點上的任務可以繼續運行,但是集群中新的資源將無法再分配給上層Framework,上層Framework將無法再利用已經收到的offer提交新任務,并且無法收到正在運行任務的狀態更新。為了解決這個問題,提高Mesos集群的高可用性,減少Mesos master節點故障所帶來的影響,Mesos集群采用了傳統的主備冗余模式(Active-Standby)來支持一個Mesos集群中部署多個Mesos master節點,借助于ZooKeeper進行Leader的選舉。選舉出的Leader負責將集群的資源以契約(offer)的形式發送給上層的每一個Framework,并處理集群管理員與上層Framework的請求,另外幾個Mesos master節點將作為Follower一直處于備用狀態,并監控當前的狀態,當Mesos master節點宕機,或服務中斷之后,新Leader將會很快從Follower中選出來接管所有的服務,減少了Mesos集群服務的宕機時間,大大提高集群可用性。
Mesos高可用集群部署
在Mesos高可用設計中,引入了ZooKeeper集群來輔助Leader的選舉,這在當前的分布式集群中比較流行,比如Docker Swarm高可用集群同時支持利用consul、etcd、ZooKeeper進行Leader的選舉,Kubernetes也采用了etcd等實現了自身的高可用。這種設計可以理解為大集群+小集群,小集群也就是ZooKeeper/etcd/consul集群,它們為大集群服務,比如提供Leader的選舉,為大集群提供配置數據的存儲和服務發現等功能。在一個復雜的系統中,這個小集群可以為系統的多個服務組件同時提供服務。因此在部署高可用Mesos集群時,必須首先部署好一個ZooKeeper集群。
本文主要介紹Mesos的高可用,不會詳細介紹ZooKeeper的相關知識你可以參考官方文檔(https://ZooKeeper.apache.org/)來部署。為了使讀者可以快速搭建它們自己的Mesos高可用集群,我們將使用Docker的方式在zhost1.wyq.com(9.111.255.10),zhost2.wyq.com(9.111.254.41)和zhost3.wyq.com(9.111.255.50)機器上快速的搭建起一個具有三個節點的演示ZooKeeper集群,它們的服務端口都是默認的2181。
登錄zhost1.wyq.com機器,執行如下命令啟動第一個server:
# docker run -d \
-e MYID=1 \
-e SERVERS=9.111.255.10,9.111.254.41,9.111.255.50 \
--name=zookeeper \
--net=host \
--restart=always \
mesoscloud/zookeeper
登錄zhost2.wyq.com機器,執行如下命令啟動第二個server:
# docker run -d \
-e MYID=2 \
-e SERVERS=9.111.255.10,9.111.254.41,9.111.255.50 \
--name=zookeeper \
--net=host \
--restart=always \
mesoscloud/zookeeper
登錄zhost3.wyq.com機器,執行如下命令啟動第三個server:
# docker run -d \
-e MYID=3 \
-e SERVERS=9.111.255.10,9.111.254.41,9.111.255.50 \
--name=zookeeper \
--net=host \
--restart=always \
mesoscloud/zookeeper
ZooKeeper集群搭建好之后,執行以下命令,通過指定一個不存在的znode的路徑/mesos來啟動所有的Mesos master,Mesos slave和Framework。
登陸每一個Mesos master機器,執行以下命令,在Docker中啟動所有的Mesos master:
# docker run -d \
--name mesos-master \
--net host mesosphere/mesos-master \
--quorum=2 \
--work_dir=/var/log/mesos \
--zk= zk://zhost1.wyq.com:2181,zhost2.wyq.com:2181,zhost3.wyq.com:2181/mesos
登陸每一個Mesos Agent機器,執行以下命令,在Docker中啟動所有的Mesos agent:
# docker run -d \
--privileged \
-v /var/run/docker.sock:/var/run/docker.sock \
--name mesos-agent \
--net host gradywang/mesos-agent \
--work_dir=/var/log/mesos \
--containerizers=mesos,docker \
--master= zk://zhost1.wyq.com:2181,zhost2.wyq.com:2181,zhost3.wyq.com:2181/mesos
注意:Mesosphere官方所提供的Mesos Agent鏡像mesosphere/mesos-agent不支持Docker的容器化,所以作者在官方鏡像的基礎至上創建了一個新的鏡像gradywang/mesos-agent來同時支持Mesos和Docker的虛擬化技術。
使用相同的znode路徑來啟動framework,例如我們利用Docker的方式來啟動Docker Swarm,讓它運行在Mesos之上:
$ docker run -d \
--net=host gradywang/swarm-mesos \
--debug manage \
-c mesos-experimental \
--cluster-opt mesos.address=9.111.255.10 \
--cluster-opt mesos.tasktimeout=10m \
--cluster-opt mesos.user=root \
--cluster-opt mesos.offertimeout=1m \
--cluster-opt mesos.port=3375 \
--host=0.0.0.0:4375 zk://zhost1.wyq.com:2181,zhost2.wyq.com:2181,zhost3.wyq.com:2181/mesos
注:mesos.address和mesos.port是Mesos scheduler的監聽的服務地址和端口,也就是你啟動Swarm的機器的IP地址和一個可用的端口。個人感覺這個變量的命名不是很好,不能見名知意。
用上邊的啟動配置方式,所有的Mesos master節點會通過ZooKeeper進行Leader的選舉,所有的Mesos slave節點和Framework都會和ZooKeeper進行通信,獲取當前的Mesos master Leader,并且會一直檢測Master節點的變化。當Leader故障時,ZooKeeper會第一時間選出新Leader,然后所有的Slave節點和Framework都會獲取到新Leader進行重新注冊。
ZooKeeper Leader的選舉機制
根據ZooKeeper官方推薦的Leader選舉機制:首先指定一個Znode,如上例中的/mesos(強烈建議指定一個不存在的Znode路徑),然后使用SEQUENCE和EPHEMERAL標志為每一個要競選的client創建一個Znode,例如/mesos/guid_n來代表這個client。
當為某個Znode節點設置SEQUENCE標志時,ZooKeeper會在其名稱后追加一個自增序號,這個序列號要比最近一次在同一個目錄下加入的znode的序列號大。具體做法首先需要在ZooKeeper中創建一個父Znode,比如上節中指定的/mesos,然后指定SEQUENCE|EPHEMERAL標志為每一個Mesos master節點創建一個子的Znode,比如/mesos/znode-index,并在名稱之后追加自增的序列號。
當為某個Znode節點設置EPHEMERAL標志時,當這個節點所屬的客戶端和ZooKeeper之間的seesion斷開之后,這個節點將會被ZooKeeper自動刪除。
ZooKeeper的選舉機制就是在父Znode(比如/mesos)下的子Znode中選出序列號最小的作為Leader。同時,ZooKeeper提供了監視(watch)的機制,其他的非master節點會不斷監視當前的Leader所對應的Znode,如果它被刪除,則觸發新一輪的選舉。有兩種做法:
所有的非Leader client監視當前Leader對應的Znode(也就是序列號最小的Znode),當它被ZooKeeper刪除的時候,所有監視它的客戶端會立即收到通知,然后調用API查詢所有在父目錄(/mesos)下的子節點,如果它對應的序列號是最小的,則這個client會成為新的Leader對外提供服務,然后其他客戶端繼續監視這個新Leader對應的Znode。這種方式會觸發“羊群效應”,特別是在選舉集群比較大的時候,在新一輪選舉開始時,所有的客戶端都會調用ZooKeeper的API查詢所有的子Znode來決定誰是下一個Leader,這個時候情況就更為明顯。
為了避免“羊群效應”,ZooKeeper建議每一個非Leader的client監視集群中對應的比自己節點序小一號的節點(也就是所有序號比自己小的節點中的序號最大的節點)。只有當某個client所設置的watch被觸發時,它才進行Leader選舉操作:查詢所有的子節點,看自己是不是序號最小的,如果是,那么它將成為新的Leader。如果不是,繼續監視。此 Leader選舉操作的速度是很快的。因為每一次選舉幾乎只涉及單個client的操作。
Mesos高可用實現細節
Mesos主要通過contender和detector兩個模塊來實現高可用,架構如圖2所示。
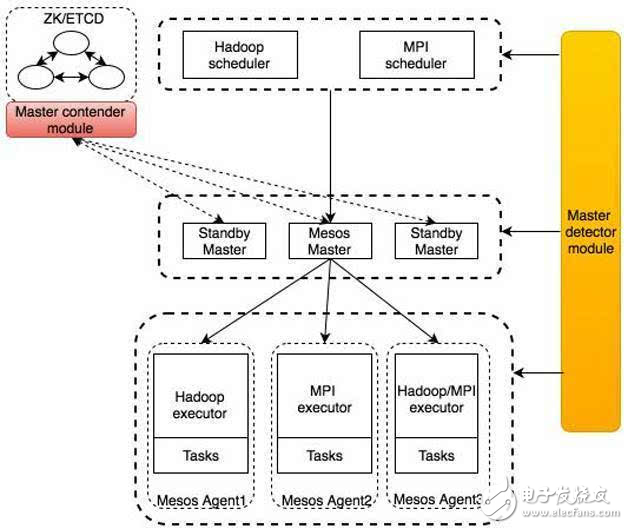
圖2 Mesos的contender和detector模塊架構圖
Contender模塊用來進行Leader選舉,它負責把每個Master節點加入到選舉的Group中(作為/mesos目錄下的一個子節點),組中每個節點都會有一個序列號,根據上文對ZooKeeper選舉機制的介紹,組中序列號最小的節點將被選舉為Leader。
以上文例子為例(假設作者部署了三個節點的Mesos master),可以查看ZooKeeper的存儲來加以驗證。
登錄到ZooKeeper集群中的某一個節點,執行如下命令鏈接到集群中的某個節點,查看這個Group:
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a6fab50e2689 mesoscloud/zookeeper “/entrypoint.sh zkSer” 50 minutes ago Up 49 minutes zookeeper
# docker exec -it a6fab50e2689 /bin/bash
# cd /opt/zookeeper/bin/
# 。/zkCli.sh -server 9.111.255.10:2181
[zk: 9.111.255.10:2181(CONNECTED) 0] ls /mesos
[json.info_0000000003, json.info_0000000004, json.info_0000000002, log_replicas]
我們可以看到在/mesos目錄下有三個帶有后綴序號的子節點,序號值最小的節點將作為master節點,查看序號最小的節點json.info_0000000002的內容如下:
[zk: 9.111.255.10:2181(CONNECTED) 1] get /mesos/json.info_0000000002
{“address”:{“hostname”:“gradyhost1.eng.platformlab.ibm.com”,“ip”:“9.111.255.10”,“port”:5050},“hostname”:“gradyhost1.eng.platformlab.ibm.com”,“id”:“93519a55-4089-436c-bc07-f7154ec87c79”,“ip”:184512265,“pid”:“master@9.111.255.10:5050”,“port”:5050,“version”:“0.28.0”}
cZxid = 0x100000018
ctime = Sun May 22 08:42:10 UTC 2016
mZxid = 0x100000018
mtime = Sun May 22 08:42:10 UTC 2016
pZxid = 0x100000018
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x254d789b5c20003
dataLength = 264
numChildren = 0
根據查詢結果,當前的Mesos master節點是
gradyhost1.eng.platformlab.ibm.com。
Detector模塊用來感知當前的master是誰,它主要利用ZooKeeper中的watcher的機制來監控選舉的Group(/mesos目錄下的子節點)的變化。ZooKeeper提供了getChildren()應用程序接口,此接口可以用來監控一個目錄下子節點的變化,如果一個新子節點加入或者原來的節點被刪除,那么這個函數調用會立即返回當前目錄下的所有節點,然后Detector模塊可以挑選序號最小的作為master節點。
每一個Mesos master會同時使用Contender和Detector模塊,用Contender進行master競選。在master節點上使用Detector模塊的原因是在Mesos的高可用集群中,你可以使用任意一個master節點的地址和端口來訪問Mesos的WebUI,當訪問一個Replica節點時,Mesos會把這個瀏覽器的鏈接請求自動轉發到通過Detector模塊探測到的master節點上。
其他的Mesos組件,例如Mesos Agent,Framework scheduler driver會使用Detector模塊來獲取當前的Mesos master,然后向它注冊,當master發送變化時,Detecor模塊會第一時間通知,它們會重新注冊(re-register)。
由于IBM在Mesos社區的推動,在MESOS-4610項目中,Mesos Contender和Detector已經可以支持以插件的方式進行加載。現在Mesos社區官方僅支持用Zookeeper集群進行Leader選舉,在支持了插件的方式加載后,用戶可以實現自己的插件,用另外的方式比如選擇用etcd(MESOS-1806)、consule(MESOS-3797)等集群進行Leader選舉。
注意:現在Mesos僅用ZooKeeper進行Leader的選舉,并沒有用它進行數據的共享。在Mesos中有一個Replicated Log模塊,負責進行多個master之間的數據共享、同步等。可以參考Mesos官方文檔獲取詳細設計(http://mesos.apache.org/documentation/latest/replicated-log-internals/)。同時為了使Mesos的高可用不依賴與一個第三方的集群,現在社區正在考慮用Replicated log替代第三方集群進行Leader選舉,具體進度可以參考MESOS-3574項目。
Mesos master recovery
在Mesos設計中,master除了要在Replicated log中持久化一些集群配置信息(例如Weights、Quota等),0集群maintenance的狀態和已經注冊的Agent的信息外,基本上被設計為無狀態的。master發生failover,新的master選舉出來之后:
它會首先從Replicated log中恢復之前的狀態,目前Mesos master會從Replicated log中recover以下信息。
Mesos集群的配置信息,例如weights,quota等。這些配置信息是Mesos集群的管理員通過HTTP endpoints來配置的。
集群的Maintenance信息。
之前注冊的所有的Agent信息(SlaveInfo)。
同時master會為Agents 的重新注冊(re-register)設置一個超時時間(這個參數通過master的slave_reregister_timeout flag進行配置,默認值為10分鐘),如果某些Agents在這個時間內沒有向新master重新注冊,將會從Replicated log中刪除,這些Agents將不能以原來的身份(相同的SlaveId)重新注冊到新的Mesos master,其之前運行的任務將全部丟失。如果這個Agent想再次注冊,必須以新的身份。同時為了對生產環境提供安全保證,避免在failover之后,大量的Agents從Replicated log中刪除進而導致丟失重要的運行任務,Mesos master提供了另外一個重要的flag配置recovery_slave_removal_limit,用來設置一個百分比的限制,默認值為100%,避免過多的Agents在failover之后被刪除,如果將要刪除的Agents超過了這個百分比,那么這個Mesos master將會自殺(一般的,在一個生產環境中,Mesos的進程將會被Systemd或者其他進程管理程序進行監管,如果Mesos服務進程退出,那么這個監管程序會自動再次啟動Mesos服務)。而不是把那些Agents從Replicated log中刪除,這會觸發下一次的failover,多次failover不成功,就需要人為干預。
另外,新的Mesos master選舉出來之后,所有之前注冊的Mesos agents會通過detector模塊獲取新的master信息,進而重新注冊,同時上報它們的checkpointed資源,運行的executors和tasks信息,以及所有tasks完成的Framework信息,幫助新master恢復之前的運行時內存狀態。同樣的原理,之前注冊的Framework也會通過detector模塊獲取到新的Master信息,向新master重新注冊,成功之后,會獲取之前運行任務的狀態更新以及新的offers。
注意:如果在failover之后,之前注冊并且運行了任務的Frameworks沒有重新注冊,那么它之前運行的任務將會變成孤兒任務,特別對于哪些永久運行的任務,將會一直運行下去,Mesos目前沒有提供一種自動化的機制來處理這些孤兒任務,比如在等待一段時間之后,如果Framework沒有重新注冊,則把這些孤兒任務殺掉。現在社區向通過類似Mesos Agents的邏輯,來持久化Framework info,同時設置一個超時的配置,來清除這些孤兒任務。具體可以參見MESOS-1719。
Mesos Agent健康檢查
Mesos master現在通過兩種機制來監控已經注冊的Mesos Agents健康狀況和可用性:
Mesos master會持久化和每個Agent之間的TCP的鏈接,如果某個Agent服務宕機,那么master會第一時間感知到,然后:
1-1. 把這個Agent設為休眠狀態,Agent上的資源將不會再offer給上層Framework。
1-2. 觸發rescind offer,把這個Agent已經offer給上層Framework的offer撤銷。
1-3. 觸發rescind inverse offer,把inverse offer撤銷。
同時,Mesos master會不斷的向每一個Mesos Agent發送ping消息,如果在設定時間內(由flag.slave_ping_timeout配置,默認值為15s)沒有收到對應Agent的回復,并且達到了一定的次數(由flag. max_slave_ping_timeouts 配置,默認值為5),那么Mesos master會:
2-1. 把這個Agent從master中刪除,這時資源將不會再offer給上層的Framework。
2-2. 遍歷這個Agent上運行的所有的任務,向對應的Framework發送TASK_LOST狀態更新,同時把這些任務從master刪除。
2-3. 遍歷Agent上的所有executor,把這些executor刪除。
2-4. 觸發rescind offer,把這個Agent上已經offer給上層Framework的offer撤銷。
2-5. 觸發rescind inverse offer,把inverse offer撤銷。
2-6. 把這個Agent從master的Replicated log中刪除。
Mesos Framework健康檢查
同樣的原理,Mesos master仍然會持久化和每一個Mesos Framework scheculer之間的TCP的連接,如果某一個Mesos Framework服務宕機,那么master會第一時間感知,然后:
把這個Framework設置為休眠狀態,這時Mesos master將不會在把資源offer給這個Framework 。
觸發rescind offer,把這個Framework上已經收到的offer撤銷。
觸發rescind inverse offer,把這個Framework上已經收到的inverse offer撤銷。
獲取這個Framework注冊的時候設置自己的failover時間(通過Framework info中的failover_timeout參數設置),創建一個定時器。如果在這個超時時間之內,Framework沒有重新注冊,則Mesos master會把Framework刪除:
4-1. 向所有注冊的Slave發送刪除此Framework的消息。
4-2. 清除Framework上還沒有執行的task請求。
4-3. 遍歷Framework提交的并且正在運行的任務,發送TASK_KILLED消息,并且把task從Mesos master和對應的Agent上刪除。
4-4. 觸發rescind offer,把這個Framework上已經收到的offer撤銷。
4-5. 觸發rescind inverse offer,把Framework上已經收到的inverse offer撤銷。
4-6. 清除Framework對應的role。
4-7. 把Framework從Mesos master中刪除。
未來展望
從我個人的角度看,Mesos高可用這個功能應該做如下增強。
現在的設計中,Mesos的高可用必須依賴一個外部的ZooKeeper集群,增加了部署和維護的復雜度,并且目前這個集群只是用來做Leader選舉,并沒有幫助Mesos master節點之間存儲和共享配置信息,例如Weights、Quota等。社區現在已經發起了一個新項目MESOS-3574,將研究和實現用Replicated log來替代ZooKeeper,幫助Mesos master選舉和發現Leader。個人認為價值比較大,它實現之后,可以大大簡化Mesos高可用架構的復雜度。
現在ZooKeeper作為搭建Mesos高可用集群的唯一選擇,可能在比較大的集成系統中不合時宜,在IBM工程師的推動下,社區已經將和Mesos高可用的兩個模塊Contender和Detector插件化,用戶可以實現自己的插件來進行Mesos master的選舉和發現,已經實現了對etcd的支持。感興趣的同學可以參考MESOS-1806項目。
另外,Mesos現在這個高可用的設計采用了最簡單的Active-standby模式,也就是說只有當前的Mesos master在工作,其他的candidate將不會做任何事情,這會導致資源的浪費。另外在特別大的Mesos集群中,master candidates并不能提供負載均衡。未來是不是可以考慮將Mesos高可用修改為Active-Active模式,比如讓master candidates可以幫助處理一些查詢的請求,同時可以幫助轉發一些寫請求到當前的master上,來提高整個集群的性能和資源利用率。
?
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%