深度解讀AlphaGo
大小:0.5 MB 人氣: 2017-10-12 需要積分:1
AlphaGo與李世石的對戰已經進行了四局。前三局世人驚嘆于AlphaGo對李世石的全面碾壓,很多人直呼人類要完。因為被視為人類智能的圣杯-圍棋,在冷酷的機器(或者是瘋狂的小狗)面前變成了唾手可得的普通馬克杯,而人類的頂尖棋手似乎毫無還手之力。3月12號的第四局,李世石終于扳回一居,而且下了幾手讓人驚嘆的好棋。特別是第 78 手,圍棋吧很多人贊為 “神之一手”,“名留青史”,“扼住命運喉嚨的一手”。因為這一局,圍棋吧的主流輿論已經從前幾天的震驚, 嘆息,傷心,甚至是認為李世石收了谷歌的黑錢轉變為驚喜,甚至認為李世石已經找到了打狗棒法。而人類要完黨則認為這比 AlphaGo 5:0 大勝更可怕,因為這只狗甚至知道下假棋來麻痹人類,真是細思極恐。
不論怎樣,AlphaGo在與人類頂尖圍棋高手的對決中已經以3勝的優勢鎖定了勝局,李世石目前只是在為人類的尊嚴而戰了。圍棋一年前還通常被認為是 10年 內都無法被人工智能攻克的防線,然而轉眼就變成了馬其諾防線了。那么這場人機大戰到底意味著什么?人類已經打開了潘多拉魔盒嗎? AlphaGo 的勝利是否意味著人工智能的黑色方碑(圖 1, 請參見電影《2001:太空漫游》)已經出現? 本文將從 AlphaGo 的原理入手逐步探討這個問題。
一、AlphaGo 的原理
網上介紹 AlphaGo 原理的文章已經有不少,但是我覺得想深入了解其原理的同學還是應該看看 Nature 上的論文原文 “Mastering the game of Go with deep neural networks and tree search”。雖然這篇文章有 20 頁,但是正文部分加上介紹部分細節的 Method 部分也就 8 頁,其中還包括了很多圖。個人覺得介紹 AlphaGo 的原理還是這篇最好。為了后面的討論方便,這里對其原理做簡要總結。
對于圍棋這類完全信息博弈,從理論上來說可以通過暴力搜索所有可能的對弈過程來確定最優的走法。對于這類問題,其難度完全是由搜索的寬度和深度來決定的。1997年 深藍解決了國際象棋,其每步的搜索寬度和深度分別約為 35 和 80 步。而圍棋每步的搜索寬度和深度則分別約為 250 和 150 步,搜索計算量遠遠超過國際象棋。減少搜索量的兩個基本原則是:1. 通過評估局勢來減少搜索的深度,即當搜索到一定深度后通過一個近似局勢判斷函數 (價值函數) 來取代更深層次的搜索;2. 通過策略函數來選擇寬度搜索的步驟,通過剔除低可能性的步驟來減少搜索寬度。很簡單的兩個原則,但難度在于減少搜索量和得到最優解之間是根本性矛盾的,如何在盡可能減少搜索量和盡可能逼近最優解之間做到很好的平衡才是最大的挑戰。
傳統的暴力搜索加剪枝的方法在圍棋問題上長期無法有大的突破, 直到 2006年 蒙特卡洛樹搜索 (Monte Carlo Tree Search) 在圍棋上得到應用,使得人工智能圍棋的能力有了較大突破達到了前所未有的業余 5-6 段的水平。MCTS 把博弈過程的搜索當成一個多臂老虎機問題(multiarmed bandit problem),采用 UCT 策略來平衡在不同搜索分支上的 Exploration 和 Exploitation 問題。MCTS 與暴力搜索不同點在于它沒有嚴格意義的深度優先還是寬度優先,從搜索開始的跟節點,采用隨機策略挑選搜索分支,每一層都是如此,當隨機搜索完成一次后,又會重新回到根節點開始下一輪搜索。純隨機的搜索其效率是極低的,如同解決多臂老虎機的問題一樣,MCTS 會記錄每次搜索獲得的收益,從而更新那些搜索路徑上的節點的勝率。在下一輪搜索時就可以給勝率更高的分支更高的搜索概率。當然為了平衡陷入局部最優的問題,概率選擇函數還會考慮一個分支的被搜索的次數,次數越少被選中的概率也會相應提高。面對圍棋這么巨大的搜索空間,這個基本策略依然是不可行的。在每次搜索過程中的搜索深度還是必須予以限制。對于原始的 MCTS 采取的策略是當一個搜索節點其被搜索的次數小于一定閾值時(在 AlphaGo 中好像是 40), 就終止向下搜索。 同時采用 Simulation 的策略,從該節點開始,通過一輪或者若干輪隨機走棋來確定最后的收益。當搜索次數大于閾值時,則會將搜索節點向下擴展。Wikipedia 上 MCTS 詞條中的示例圖(圖 2)展示了 MCTS 的四個步驟:
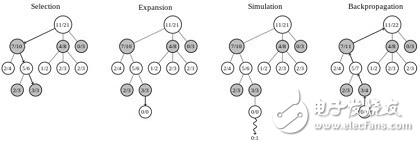
圖2
1. 選擇:根據子節點的勝率隨機選擇搜索路徑。
2. 擴展:當葉子節點的搜索次數大于閾值時向下擴展出新的葉子節點(如無先驗則隨機選擇)。
3. 仿真:從葉子節點開始隨機走棋一輪或者若干輪得到終局的收益。
4. 回傳:將此次搜索的結果回傳到搜索路徑的每個節點來更新勝率。

圖3
AlphaGo 其基本原理也是基于 MCTS 的,其實一點也不深奧。但是 AlphaGo 在 MCTS 上做了兩個主要的優化工作,使得圍棋人工智能從業余水平飛躍至職業頂尖水平。這兩個優化工作分別是策略網絡和價值網絡,這兩個網絡都是深度神經網絡,本質上是還是兩個函數。這兩個網絡分別解決什么問題呢?在原始 MCTS 中的選擇步驟中,開始的那些搜索只能純隨機的挑選子節點,其收斂效率顯然是很低的。而策略網絡以當前局勢為輸入,輸出每個合法走法的概率,這個概率就可以作為選擇步驟的先驗概率,加速搜索過程的收斂。而價值網絡則是在仿真那一步時直接根據當前局勢給出收益的估值。 需要注意的是在 AlphaGo 中,價值網絡并不是取代了隨機走棋方法,而是與隨機走棋并行(隨機走棋在 CPU 上而價值網絡在 GPU 上運行)。 然后將兩者的結果進行加權 (系數為 0.5)。當然 AlphaGo 的隨機走棋也應該是做了大量的優化工作,可能借鑒了之前的一些圍棋人工智能的工作。摘自 AlphaGo 論文的圖 3 清晰展示了策略網絡和價值網絡如何將圍棋人工智能的水平從業余水平提升到職業水平(Rollouts 就是隨機走棋)。因此 AlphaGo 的精髓就是在策略網絡和價值網絡上。
策略網絡可以抽象為, 其中 s 為當前局勢,a 為走法,其實就是在當前局勢下每一個合法走法的條件概率函數。為了得到這個函數,AlphaGo 采用的監督學習的辦法,從 KGS Go Server 上拿到的三千萬個局勢訓練了深達 13 層的深度神經網絡。這一網絡能將走法預測準確度提高到 57%。如果將這一問題看成一個多分類問題,在平均類別約為 250 個的情況下取得 57%的精確度是十分驚人的。在這個訓練過程中,其目標是更看重走法對最后的勝負影響而不僅僅是對人類走法的預測精度。 這個深度學習網絡的預測耗時也是相當大的(需要 3 毫秒)。為此 AlphaGo 又用更簡單的辦法訓練了一個快速策略函數作為備份,其預測精度只有 24.2%但是預測耗時僅為 2 微秒,低 1000 個數量級。需要注意的是,AlphaGo 實際使用的策略網絡就是從人類棋譜中學到的策略網絡,而并沒有使用通過自我對弈來強化學習獲得的策略網絡。這是因為在實際對戰中,監督學習網絡比強化學習網絡效果要好。
價值網絡是個當值函數,可以抽象為, 即當前局勢下的收益期望函數。價值網絡有 14 個隱層,其訓練是通過采用強化學習策略網絡 AlphaGo 的自我對弈過程中產生的局勢和最終的勝負來訓練這個函數。
強化學習或者說自我學習這個過程是大家對 AlphaGo 最著迷的部分,也是藥丸黨最憂心的部分。這個過程甚至被解讀成了養蠱,無數個 AlphaGo 自我拼殺,最后留下一個氣度無比的。但讀完論文發現,強化學習的作用其實并沒有那么大。首先是強化學習是在之前學習人類棋譜的監督學習網絡的基礎上進一步來學習的,而不是從 0 基礎開始。其次,強化學習網絡的并沒有用在實際博弈中,而是用在訓練價值網絡中。而且在訓練價值網絡中,并不是只使用那條最強的蠱狗,而是會隨機使用不同的狗。個人認為,強化學習在 AlphaGo 中主要是用來創造具有不同風格的狗,然后通過這些不同風格的狗訓練價值網絡,從而避免價值網絡的過擬合。這可能是因為目前人類棋譜的數量不夠用來訓練足夠多的水平高的策略網絡來支持價值網絡的訓練。
二、AlphaGo 到底從人類經驗中學到了什么?
個人認為,AlphaGo 有某種程度的超強學習能力,能夠輕松的學習人類有史以來所有下過的棋譜(只要這些棋譜能夠數字化),并從這些人類的經驗中學到致勝的秘訣。但顯然,AlphaGo 下圍棋的邏輯從人類看起來肯定是不優美的。MCTS 框架與人類棋手的布局謀篇完全沒有相同的地方,只是冷冰冰的暴力計算加上概率的權衡。策略網絡學習了大量人類的策略經驗,可以非常好的判斷應該走哪一步,但并不是基于對圍棋的理解和邏輯推理。如果你要問為什么要選擇這一步,策略網絡給出的回答會是歷史上這種情況 90%的人都會走這一步。而策略網絡呢,學習的是當前局面的勝負優勢的判斷,但是它同樣無法給出一個邏輯性的回答,而只能回答根據歷史經驗,這種局面贏的概率是 60%這樣的答案。有些人說,這種能力近乎人的直覺,但我覺得人類直覺的機制應該比這復雜得多,我們的直覺無法給出判斷的概率, 或者說人類的思維核心并不是概率性的。AlphaGo 從大量人類經驗中學到了大量的相關性的規律(概率函數),但是確沒有學習到任何的因果性規律。這應該是 AlphaGo 和人類棋手最本質的區別了。
三、AlphaGo 超越了人類的智能了嗎?
要回答這個問題,首先要明確超越的定義。如果說能打敗人類頂尖棋手,那 AlphaGo 在圍棋上的智能確實是超越了人類。 但是假設,人類再也不玩圍棋了,沒有更新的人類棋譜,AlphaGo 的圍棋智能還能提高嗎? 從前面的分析看, AlphaGo 的自我學習過程作用并不是那么大,這點我是表示懷疑的。也許人類沉淀的經驗決定了 AlphaGo 能力的上界,這個上界可能會高于人類自身頂尖高手。但是當人類不能繼續發展圍棋,AlphaGo 的能力也就會止步不前。
從理論上來說圍棋可能發生的變化數量是個 170 位數, 這是人類和計算機的能力都無法窮盡的。無論是人類的邏輯推理,還是人工智能的搜索策略,陷入局部最優是無法避免的命運。而目前 AlphaGo 的機制,決定了其肯定是跟著人類掉進坑里(某些局部最優)。如果人類不能不斷的挖掘新坑(新的局部最優,或者圍棋新的風格和流派),AlphaGo 能跳出老坑的可能性并不是太大。從這個意義上來說,AlphaGo 在圍棋上超越人類智能應該還沒有實現。
四、AlphaGo 會故意輸給李世石嗎?
12號這一局有人認為是 AlphaGo 故意輸給李世石,或者為了保存實力,或者為了能夠進入排名。但是從 Google 公開的原理來看,其顯然不具備做這樣決策的機制。AlphaGo 的機制就是追求當局取勝,完全沒有考慮各局之間的關系,更沒有人工智能偉大崛起的戰略目標。 AlphaGo 故意輸只是句玩笑而已。真要說故意,那也只可能是 DeepMind 中的人干的事情。
五、人類能否戰勝 AlphaGo?
李世石贏了一局,圍棋吧不少人都認為人類找到了克制 AlphaGo 的打狗棒法。就是不要把狗當人,不要用人的思維對待狗,我們需要大膽跳出以往的經驗,去尋找神之一手。結合前面的分析,我覺得這個思路是對的。本質上 AlphaGo 是在追隨人類圍棋的發展,如果人類不能跳出自己的窠臼,則只會被在這個窠臼中算無遺策的 AlphaGo 碾壓。人類棋手可以通過自己的邏輯推理,尋找跳出當前局部最優的方法。但這也不是一件容易的事情,跳出經驗思維,更多的可能性是陷入更大的逆勢,這對人的要求太高了,也只有頂尖棋手才有可能做到。而且 AlphaGo 也能夠不段的學習新的經驗,神之一手可能戰勝 AlphaGo 一次,但下一次就不見得有機會了。AlphaGo 就如同練就了針對棋力的吸星大法,人類對他的挑戰只會越來約困難。
六、AlphaGo 能干什么以及不能干什么?
DeepMind 的目標肯定不只是圍棋,圍棋只是一個儀式,來展示其在人工智能上的神跡。看公開報導,下一步可能是星際爭霸,然后是醫療,智能手機助手,甚至是政府,商業和戰爭決策等領域。
Demis Hassabis 在接受 The Verge 采訪時透露 DeepMind 接下來關注的核心領域將會是個人手機助手。Hassabis 認為目前的個人手機助手都是預編程的,過于脆弱,無法應變各種情況, 而 DeepMind 想通過人工智能技術,特別是無監督的自我學習方式具有真正智能的真正智能手機助手。這是因為智能手機的輸入變化太多,需要巨量的訓練樣本才能學到有用的東西。而這正是 AlphaGo 目前主要依賴的方法。為此,Hassabis 想挑戰讓機器的自我學習成為主要的學習方式, 他對此充滿了信心。但我認為這個問題可能不是那么好解決的,因為在 AlphaGo 中自我學習的作用是相對有限的。如果在圍棋這種相對簡單的環境中,自我學習的作用都相對有限,在更加復雜的環境中要能有很好的自我學習效果其挑戰會更加巨大。不過從我們 TalkingData 的角度來看,把我們的海量移動端數據和監督學習技術相結合,可能更容易實現 Hassabis 的設想。
我個人期待 AlphaGo 能夠創造更大的神跡,但同時也認為其應用還是有一定局限性的。因為并不是所有的實際問題都能找到這么多的訓練數據。尤其在政府,商業和戰爭決策上,窮盡人類歷史也找不到多少精確的訓練集,而問題本身的復雜性又是超過圍棋這種完全信息博弈的。在這種情況下,恐怕很難學到足夠準確的策略網絡和價值網絡。這就使得 AlphaGo 的方法面對這些問題,可能是完全無法解決的。
七、AlphaGo 到底意味著什么?
雖然在圍棋這一被人類自認為是智能圣杯的特定領域, AlphaGo 取得了巨大成就,但其基本機制并沒有什么顛覆性的東西。要實現強人工智能的星辰大海,目前的計算機理論和技術可能只算得上工質火箭。但是 AlphaGo 所代表的人工智能突破性的發展也不能被低估,工質火箭畢竟把人類帶入了太空時代。目前的人工智能在某些領域已經能夠更好的學習全人類的經驗的能力。也許人工智能很難創造出什么,但是至少能把人類已經達到的高度推向更高,將人類從更多的重復性勞動中解放出來,也為我們創造更好的生活,更好的環境。 AlphaGo 是人類進步史上的一個重要臺階,但是它可能并不是人工智能崛起的黑色方碑。
作者介紹:張夏天TalkingData首席數據科學家,曾在IBM中國研究院,騰訊數據平臺部,華為諾亞方舟實驗室任職。對大數據環境下的機器學習,數據挖掘有深入的研究和實踐經驗。在TalkingData負責數據挖掘和機器學習工作,為TalkingData各個產品線和服務線提供支持。
?
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
深度解讀AlphaGo下載
相關電子資料下載
- 碾壓GPT-4!谷歌DeepMind CEO自曝:下一代大模型將與AlphaGo合體 143
- ChatGPT到底有何不同 537
- Google研發人工智能機器人AlphaGo以4即將誕生 2113
- DeepMind宣布將研發更智能的AlphaGo算法 744
- 淺談嵌入式人工智能的發展趨勢 4086
- 李世石輸給谷歌AlphaGoh后,AI人工智能讓自己不再是頂尖 2315
- DeepMind阿爾法被打臉,華為論文指出多項問題 2799
- 樊麾再次負于AlphaGo,以0:5完敗于人工智能 3498
- 人工智能發展近70年來背后的故事 4634
- AlphaGo的橫空出世讓“人工智能”成為街頭巷尾人人討論的話題 971