 電子發(fā)燒友App
電子發(fā)燒友App


隨著數(shù)據(jù)洪流時代的到來,AI技術(shù)應用的重要性日益凸顯,而AI芯片的設計開發(fā)成為AI技術(shù)發(fā)展的關(guān)鍵一環(huán)。由于應對數(shù)據(jù)處理的優(yōu)先級和方式不同,AI芯片所要面對的是海量數(shù)據(jù)處理。避免存儲對于芯片時鐘頻率造成的拖累,跨越“存儲墻”對于芯片性能提升的障礙已成為半導體行業(yè)廣泛探討的話題。而當“存儲優(yōu)先架構(gòu)”(SFA)解決方案被提出來,我們似乎找到了開啟未來AI芯片性能提升的金鑰匙。
“存儲墻”阻隔AI芯片性能大跨步提升
傳統(tǒng)芯片的設計基于馮·諾依曼架構(gòu)體系(如下圖),是一種將程序指令存儲器和數(shù)據(jù)存儲器合并在一起的類PC設計概念結(jié)構(gòu)。
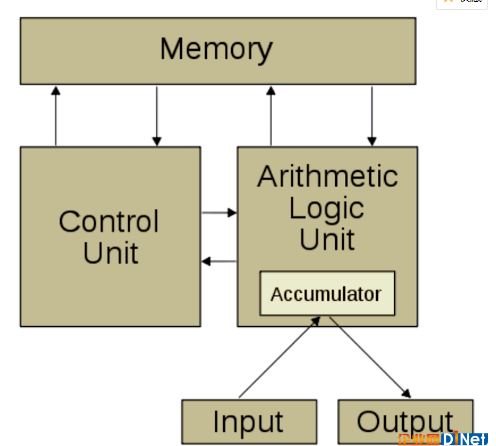
馮·諾依曼架構(gòu)體系
在這種相對傳統(tǒng)的芯片設計思路中,計算模塊和存儲單元相互分離,數(shù)據(jù)從處理單元外的存儲器提取,處理之后再返回存儲器。以往我們的計算機應用場景下,這種架構(gòu)能夠較好的發(fā)揮頻率優(yōu)勢,解決少量的復雜任務,并通過提高制程工藝不斷提升頻率達到芯片的性能提升。
而當我們面對數(shù)據(jù)洪流時代的AI場景時,包括深度學習神經(jīng)網(wǎng)絡、云計算、邊緣計算等AI或AI相關(guān)場景中,與x86平臺復雜運算相比計算任務往往是規(guī)模宏大的簡單運算。由于馮·諾依曼架構(gòu)的邏輯設計上,讀取返回存儲結(jié)構(gòu)所消耗的時間巨大,大規(guī)模的數(shù)據(jù)計算會造成存儲的讀取和返回遠跟不上芯片的頻率,產(chǎn)生嚴重的延遲,成為芯片整體性能的瓶頸,這也就是現(xiàn)代應用場景下的“存儲墻”的由來。
摩爾定律曲線已進入難以提升的“紅區(qū)”
“存儲墻”不僅造成了在大規(guī)模數(shù)據(jù)面前,芯片整體的性能下降,也進一步對于未來升級制程工藝提出更嚴峻的挑戰(zhàn)。畢竟如今摩爾定律已經(jīng)失效,在當前的技術(shù)工藝基礎上,繼續(xù)提升晶體管集成率縮小集成尺寸將會變得越來越困難。這會直接影響未來CPU、GPU、FPGA、ASIC性能的提升。可以毫不夸張地說,目前大部分針對AI、加速神經(jīng)網(wǎng)絡處理的研發(fā)創(chuàng)新,都是在與“存儲墻”這個問題作斗爭。
解決“存儲墻”的思路和方式
既然“存儲墻”問題在當下這個應用場景下需要被解決,就要有合理化的思路。針對跨越“存儲墻”目前業(yè)界有幾種優(yōu)化思路,基本上都是圍繞著更高、更快、更強幾個維度,與咱們的奧運精神還挺像的。
硬性提升存儲器的帶寬和頻率,這種方式其實目前沿用的傳統(tǒng)性能提升方式之一。去年的AMD曾經(jīng)在顯卡的設計上采用了高帶寬顯存HBM就是一個思路類似的例子,通過提高帶寬的方式提升存儲器與GPU交流。雖然這能夠在一定程度上帶來GPU芯片效率的提升,但是這樣處理也會對制造工藝提出新的要求,顯然HBM比普通顯存造價要更高、良率更低。而且雖然存儲效率由于帶寬增大實現(xiàn)了提升,但是轉(zhuǎn)化到實際芯片的運算效率非常有限。這是一種優(yōu)化之道,但并不能徹底跨越工藝限制的終極解決辦法。
AMD為GPU做的HBM高帶寬顯存方案
動態(tài)調(diào)整頻率則是通過軟硬件動態(tài)調(diào)整存儲器的讀寫頻率,來降低訪問調(diào)度的隨機性,實現(xiàn)更多預訪問,讓訪問變得更有序,進一步提升訪問效率,進而降低延遲。此種手段實施并不簡單,并且理論上提升的幅度十分有限,雖然可以一定程度上優(yōu)化,但并不足以應付未來AI場景的百倍千倍數(shù)據(jù)吞吐,畢竟每小時TB級別海量數(shù)據(jù)才是AI世界的真實常態(tài)。
將存儲結(jié)構(gòu)盡量靠近核心,做成片上存儲也是一種熱門思路。精簡的訪問路徑使得邏輯核心與存儲的訪問精度得到顯著提升,盡可能利用工藝極限提升存儲器的訪問效率。這種方式的理論上可以在減少訪問延遲5-10倍以上,這種量級的優(yōu)化進步對比之前的幾種方式就來得非常可觀。
在思路和技術(shù)兩個維度發(fā)現(xiàn)傳統(tǒng)芯片的“存儲墻”瓶頸之后,下一步就是從思想和技術(shù)兩方面進行突破,這也就引出了我們今天的核心“存儲優(yōu)先架構(gòu)”。
“存儲優(yōu)先架構(gòu)”原理和優(yōu)勢所在
簡單來理解,存儲優(yōu)先架構(gòu)實際上就是片上存儲技術(shù)+架構(gòu)思想革新,是技術(shù)手段變革和思想革新的雙重結(jié)合。
之前我們已經(jīng)提到了片上存儲這種設計方式的好處,它能夠帶來成倍的存儲訪問效率提升。但是片上存儲這套思路實際上技術(shù)本身沒有對架構(gòu)思想進行變革,依舊是按照馮·諾依曼架構(gòu)來的一套體系,雖然得益于片上存儲技術(shù),訪問的效率大大提升了,但是由于架構(gòu)不變,訪問的步驟依舊較多,這帶來了存儲效率的浪費。
于是,在片上存儲技術(shù)的基礎上,探境科技提出了一種顛覆性的思想,以存儲為中心帶動計算,重新設計整個AI芯片的架構(gòu)——即“存儲優(yōu)先架構(gòu)”(SFA)。
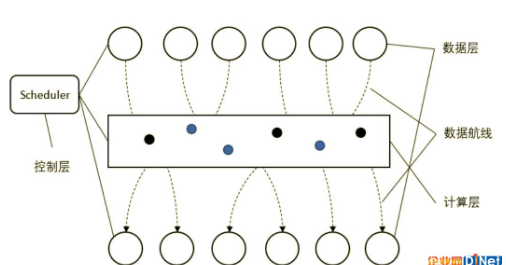
探境科技提出的“存儲優(yōu)先架構(gòu)”
上圖是存儲優(yōu)先架構(gòu)的示意圖,通過對比馮·諾依曼架構(gòu)示意圖,我們從上圖可以觀察到存儲架構(gòu)包括數(shù)據(jù)層、計算層和控制層組成,它們以存儲調(diào)度為核心邏輯形成一套計算架構(gòu),數(shù)據(jù)在存儲之間的遷移過程中同時完成計算,計算就那么自然而然隨著數(shù)據(jù)轉(zhuǎn)移同時進行了。理論上這種設計方案的能效能提升10-100倍,計算資源利用率提升40-50%,同時對DDR的占用率也能夠?qū)崿F(xiàn)大幅度下降。這就好像從前城里10萬老百姓辦手續(xù),不但路遠,還要跑很多趟。現(xiàn)在百姓雖然已經(jīng)多達500萬,但是提高了辦事效率,辦事窗口離家門口更近了,還允許一次性辦齊。
據(jù)了解,目前探境科技全新的存儲優(yōu)先架構(gòu)并不僅僅只是停留在理論層面,而是真真正正已經(jīng)流片,并即將推向商用領域。在今年10月份舉行的IC WORLD大會上面,探境科技發(fā)布了即將推出的語音、圖像序列AI芯片和IP授權(quán)。這些產(chǎn)品可以被用在AI計算、邊緣計算、安放前端協(xié)處理、語音喚醒、命令詞識別、語義理解、通用降噪、自動駕駛等多個前沿領域。
存儲優(yōu)先架構(gòu)應用到實際能帶來什么體驗革新?舉個例子:
目前智能音箱一個使用痛點就是語音控制和反饋的延遲。智能音箱需要聽到用戶的喚醒詞進行喚醒,并在得到指令內(nèi)容之后,將內(nèi)容的聲音數(shù)據(jù)回傳到云端,進行分析和處理得到結(jié)果之后再返回到智能音箱播放出來。這中間由于信號、網(wǎng)絡延遲等一系列問題就會導致最終用戶體驗質(zhì)量的大幅下降,等待2、3秒也就成了常態(tài)。如果智能音箱采用存儲優(yōu)先架構(gòu)的AI芯片,能夠在本地接受內(nèi)容之后直接處理為結(jié)果,不需要回傳云端和大數(shù)據(jù)比對、分析和運算,實現(xiàn)高效的邊緣計算,這將根本性提升最終的用戶體驗。智能音箱如是,自動駕駛?cè)缡牵腔坌铝闶廴缡牵腔鄢鞘蟹椒矫婷娑茧x不開完整的AI、云計算、邊緣計算的配合。
摩爾定律注定失效,存儲優(yōu)先架構(gòu)或是AI芯片的未來
從某種意義上來說,摩爾定律是基于馮·諾依曼架構(gòu)提出的,而馮·諾依曼架構(gòu)本身的結(jié)構(gòu)路徑基于指令集模式的處理邏輯,存在對于海量數(shù)據(jù),尤其是不規(guī)則海量數(shù)據(jù)處理的先天短板。所以不管是摩爾定律和還是x86基礎的馮·諾依曼架構(gòu),它們隨著人類社會發(fā)展以及數(shù)據(jù)量的不斷攀升,是注定必將失效的。或者反過來說,我們海量數(shù)據(jù)洪流的時代漸漸淘汰舊的芯片規(guī)則約束,正催生芯片架構(gòu)進行一次大的革新。
存儲優(yōu)先架構(gòu)以其邏輯步驟精簡+片上存儲技術(shù)手段的方式,得到雙重性能提升,實現(xiàn)了以存儲調(diào)度為核心的計算架構(gòu),這的確是一次前所未有的創(chuàng)新實踐。隨著探境科技流片量產(chǎn)和隨后的應用場景部署,存儲優(yōu)先架構(gòu)的AI芯片必將幫助終端設備實現(xiàn)更多自動化的、低延遲的邊緣計算,以改善最終的智慧生活體驗。關(guān)于存儲優(yōu)先架構(gòu)的AI芯片產(chǎn)品以及未來的具體應用進展,我們不妨持續(xù)關(guān)注拭目以待。
責任編輯:ct









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論