 電子發(fā)燒友App
電子發(fā)燒友App


智能化DRAM為代表的技術(shù)方向?qū)⒊蔀楦淖兇鎯?chǔ)器市場(chǎng)格局的重要手段。
為了解決從客戶(hù)端系統(tǒng)到高性能服務(wù)器的廣泛應(yīng)用所面臨的性能和功耗挑戰(zhàn),JEDEC固態(tài)技術(shù)協(xié)會(huì)于2020年7月正式發(fā)布了下一代主流內(nèi)存標(biāo)準(zhǔn)DDR5 SDRAM的最終規(guī)范(JESD79-5),為全球計(jì)算機(jī)內(nèi)存技術(shù)拉開(kāi)了新時(shí)代的序幕。
JEDEC將DDR5描述為一種“具備革命意義”的存儲(chǔ)器架構(gòu),認(rèn)為它的出現(xiàn)標(biāo)志整個(gè)產(chǎn)業(yè)即將向DDR5服務(wù)器雙列直插式存儲(chǔ)器模塊(DIMM)過(guò)渡。
DDR5的速度比已經(jīng)超級(jí)快的DDR4還要快。與DDR4內(nèi)存的3.2Gbps最高傳輸速率相比,全新DDR5內(nèi)存則高達(dá)8.4Gbps。此外,DDR5也改善了DIMM的工作電壓,將供電電壓從DDR4的1.2V降至1.1V,從而進(jìn)一步提升了內(nèi)存的能效。兩者之間的性能、容量和功耗等指標(biāo)的具體比較見(jiàn)表1。
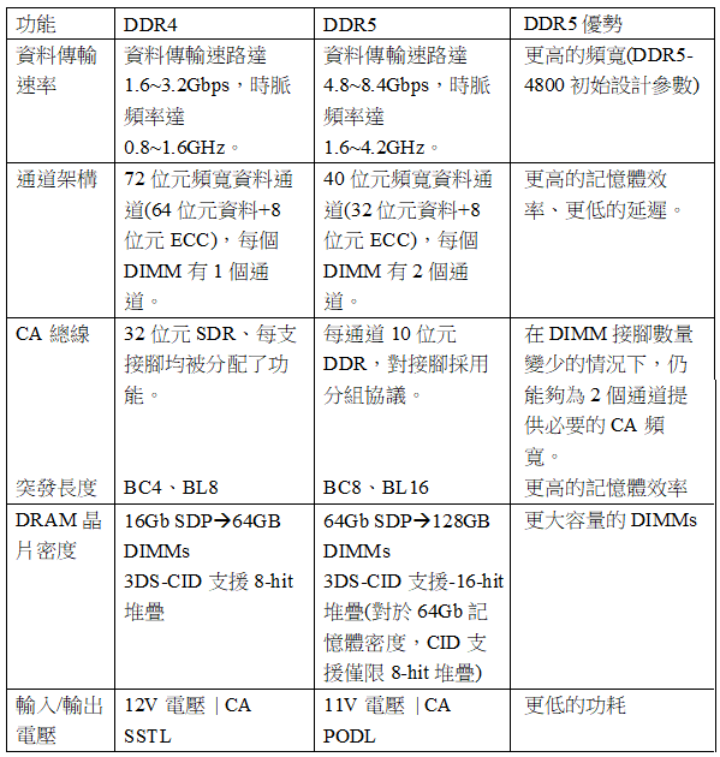
表1:DDR5與DDR4 DIMMs比較
DRAM芯片密度方面,DDR4在單裸片封裝(SDP)模式下僅支持最高16Gb的DRAM容量,而DDR5內(nèi)存標(biāo)準(zhǔn)將這一數(shù)字提高到了64Gb。這意味著,DDR5 DIMM在SDP模式下的最高容量可達(dá)256GB,是DDR4 64Gb最大容量的4倍。同時(shí),DDR5 還支持片上錯(cuò)誤更正碼、錯(cuò)誤透明模式、封裝后修復(fù)和讀寫(xiě)CRC校驗(yàn)等功能,并支持最高40個(gè)單元的堆疊,從而可使其有效內(nèi)存容量達(dá)到2TB。
在設(shè)計(jì)上,DDR5內(nèi)存保持與DDR4相同的288個(gè)引腳數(shù),不過(guò)定義不同,無(wú)法兼容DDR4插槽。DDR5 DIMM采用了彼此獨(dú)立的40位寬雙通道設(shè)計(jì)(32個(gè)數(shù)據(jù)位,8個(gè)錯(cuò)誤更正碼字節(jié)),每個(gè)通道的突發(fā)長(zhǎng)度從8字節(jié)(BL8)翻倍到16字節(jié)(BL16)。所以盡管數(shù)據(jù)位仍然是64位,但并發(fā)能力的提高使得內(nèi)存存取效率得到了提升,而且兩個(gè)通道共享寄存時(shí)鐘驅(qū)動(dòng)器,每側(cè)可提供四個(gè)輸出時(shí)鐘,能夠優(yōu)化信號(hào)完整性。
此外,DDR5還帶來(lái)了一種名為“同一區(qū)塊刷新”(SAME-BANK Refresh)的新特性。這一命令允許對(duì)每一組區(qū)塊中的單獨(dú)區(qū)塊進(jìn)行刷新,而讓其他區(qū)塊保持打開(kāi)狀態(tài),以繼續(xù)正常操作。測(cè)試資料顯示,單列DDR5模塊與DDR4雙列模塊以3200MT/s的速度進(jìn)行比較時(shí),前者性能可以提升1.28倍,在4800MT/s的入門(mén)級(jí)數(shù)據(jù)速率下,DDR5性能提升了高達(dá)1.87倍。
市場(chǎng)調(diào)研機(jī)構(gòu)Omdia分析指出,對(duì)DDR5的市場(chǎng)需求從2020年就開(kāi)始逐步顯現(xiàn),到2022年,DDR5預(yù)計(jì)將占據(jù)整個(gè)DRAM市場(chǎng)的10%,2024年則將進(jìn)一步擴(kuò)大至43%; Yole Group則預(yù)測(cè)稱(chēng),DDR5的廣泛采用應(yīng)該會(huì)從2022年的服務(wù)器市場(chǎng)開(kāi)始,2023年,手機(jī)、筆記本電腦和PC等主流市場(chǎng)也將開(kāi)始廣泛采用DDR5,出貨量明顯將會(huì)超過(guò)DDR4,屆時(shí)兩種技術(shù)間將完成快速過(guò)渡。
與DDR2、3和4的升級(jí)演進(jìn)重點(diǎn)主要集中在如何降低功耗上,移動(dòng)和終端應(yīng)用在于其主要推動(dòng)力不同,DDR5的主要推動(dòng)因素是因?yàn)殡S著CPU核心數(shù)量和運(yùn)算性能的持續(xù)增加,內(nèi)存帶寬和容量也必須成比例地?cái)U(kuò)展。
例如,2000~2019年,內(nèi)存帶寬從約1GB/s迅速提升至200GB/s,但與此同時(shí),一個(gè)系統(tǒng)中處理器核心數(shù)量也從早期的單核心、雙核心,增加到如今的60個(gè)以上。在這樣一個(gè)超多核心處理器的系統(tǒng)中,分?jǐn)偟矫總€(gè)核心上的可用帶寬嚴(yán)重不足。
推動(dòng)DDR5前進(jìn)的其他因素,還包括:處理器和內(nèi)存希望擁有相同的內(nèi)存讀取細(xì)微性(64字節(jié)快取內(nèi)存行); 相同或更好的可靠性、可用性和可服務(wù)性功能,例如必須支持單錯(cuò)誤校正和雙錯(cuò)誤檢測(cè)(single error correction/double error detection); 保持在冷卻功率范圍內(nèi)(~15W/DIMM),并控制好啟動(dòng)和內(nèi)存訓(xùn)練的時(shí)間,以免影響預(yù)期啟動(dòng)時(shí)間。
數(shù)據(jù)中心、PC與平板電腦和邊緣計(jì)算,被視作DDR5最有希望廣泛普及的三大領(lǐng)域。優(yōu)先級(jí)方面,業(yè)界普遍認(rèn)為DDR5將緊隨DDR4的步伐,率先導(dǎo)入數(shù)據(jù)中心而不是PC領(lǐng)域,以應(yīng)對(duì)運(yùn)算密集型的工作負(fù)載。考慮到PC消費(fèi)者對(duì)整機(jī)價(jià)格敏感度極高,且DDR5初期推出的價(jià)格與DDR4相比存在較高溢價(jià),所以普及速度會(huì)相對(duì)較慢。
從目前的實(shí)際情況來(lái)看,DDR4仍然保持著強(qiáng)勁的態(tài)勢(shì),DDR5還處于早期的量產(chǎn)爬坡階段,預(yù)計(jì)到2023年底DDR5的出貨量才會(huì)超過(guò)DDR4。在PC市場(chǎng),英特爾(Intel) Alder Lake處理器已經(jīng)搭配了DDR5內(nèi)存,AMD也宣布會(huì)在今年支持DDR5; 在服務(wù)器市場(chǎng),第一個(gè)DDR5服務(wù)器已經(jīng)出樣,預(yù)計(jì)會(huì)在接下來(lái)的3~6個(gè)月內(nèi)實(shí)現(xiàn)早期量產(chǎn)。這樣看來(lái),先前盛傳的“2022年將能夠真正全面進(jìn)入DDR5時(shí)代”的說(shuō)法看來(lái)有些過(guò)于激進(jìn)——畢竟2022年底已近,而支持DDR5的處理器平臺(tái)仍比較有限。
DRAM市場(chǎng)的幾大參與者包括了三星(Samsung)、美光(Micron)、SK海力士(SK Hynix)、南亞科技(Nanya)、力積電(PSMC)等,圖1展示了該領(lǐng)域主要市場(chǎng)參與者的技術(shù)演進(jìn)方向。簡(jiǎn)單而言,三星、美光與SK海力士針對(duì)DDR4、DDR5和LPDDR5應(yīng)用,已經(jīng)以15nm和14nm等級(jí)的單元設(shè)計(jì)規(guī)則發(fā)布了D1z和D1α節(jié)點(diǎn)的產(chǎn)品; 三星是最早在DRAM上采用極紫外光(EUV)微影技術(shù)的供應(yīng)商,將其應(yīng)用于D1x DDR4 DRAM模組和D1z LPDDR5規(guī)模量產(chǎn)。?
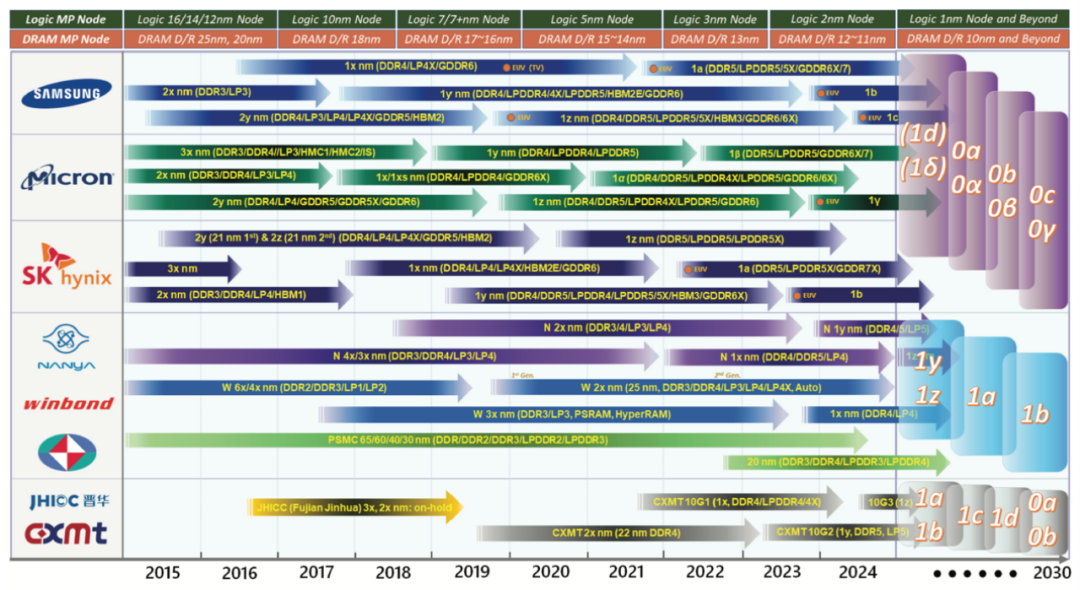
圖1:主流供應(yīng)商的DRAM制程節(jié)點(diǎn)演進(jìn)
(來(lái)源:TechInsights)
HBM3
隨著人工智能(AI)和機(jī)器學(xué)習(xí)(ML)領(lǐng)域需求的快速發(fā)展,內(nèi)存產(chǎn)品設(shè)計(jì)的復(fù)雜性正在快速上升,并對(duì)帶寬提出了更高的要求,高帶寬記憶體(HBM)成為繞過(guò)DRAM傳統(tǒng)I/O增強(qiáng)模式演進(jìn)的另一個(gè)優(yōu)秀方案。
從最開(kāi)始數(shù)據(jù)傳輸速率約為1Gbps左右的HBM1,到2016年推出的最高數(shù)據(jù)傳輸速率為2Gbps的HBM2,再到2018年推出的最高數(shù)據(jù)傳輸速率3.6Gbps的HBM2E。
而在三星發(fā)布的最新藍(lán)圖中,其HBM3技術(shù)已于今年開(kāi)始量產(chǎn),接口傳輸速率可達(dá)6.4Gbps,相比上一代提升1.8倍,從而實(shí)現(xiàn)單芯片接口帶寬819GB/s,如果使用6層堆疊可以實(shí)現(xiàn)4.8TB/s的總帶寬。到2024年,預(yù)計(jì)將實(shí)現(xiàn)接口速度高達(dá)7.2Gbps的HBM3P,這一代數(shù)據(jù)傳輸率進(jìn)一步提升10%,從而將堆疊的總帶寬提升到5TB/s以上。
除了AI/ML訓(xùn)練市場(chǎng)之外,HBM3還可用于5G、高效能運(yùn)算及其他與數(shù)據(jù)中心相關(guān)的應(yīng)用場(chǎng)景、繪圖應(yīng)用和網(wǎng)絡(luò)應(yīng)用。其發(fā)展很大程度上是由不斷上升的帶寬需求驅(qū)動(dòng),而對(duì)帶寬的需求幾乎沒(méi)有上限。換句話說(shuō),目前來(lái)看HBM的發(fā)展可能不會(huì)遇到障礙。但相較于GDDR DRAM動(dòng)輒16/18Gbps的速率,HBM3的速率仍然存在差距,而限制HBM發(fā)展的原因則主要來(lái)自?xún)煞矫妫阂皇侵虚g層,二是成本。
先進(jìn)的2.5D/3D制造是造成成本偏高的原因。眾所周知,HBM技術(shù)與其他技術(shù)最大的不同,就是采用了3D堆疊技術(shù)。HBM2E、DDR、GDDR,HBM3架構(gòu)的基本單元同樣是基于DRAM,但不同于其他產(chǎn)品將DDR進(jìn)行平鋪的做法,HBM選擇了3D堆疊,其直接結(jié)果就是接口變得更寬。比如DDR的接口位寬只有64位,而HBM透過(guò)DRAM堆疊的方式可以將位寬提升到1024位,這就是HBM與其他競(jìng)爭(zhēng)技術(shù)相比最大的差異。但這對(duì)成本比較敏感的客戶(hù)或應(yīng)用來(lái)說(shuō),使用HBM的門(mén)檻就被大幅提升了。
系統(tǒng)級(jí)創(chuàng)新將成為更大內(nèi)存系統(tǒng)的關(guān)鍵
為了解決存儲(chǔ)容量的需求,除了芯片級(jí)解決方案之外,系統(tǒng)級(jí)解決方案也是重要方向之一,使用CXL技術(shù)做內(nèi)存擴(kuò)展就極具代表性。以數(shù)據(jù)中心為例,圖2從左至右為依次展示了數(shù)據(jù)中心正在及將要經(jīng)歷的三次重要轉(zhuǎn)型。
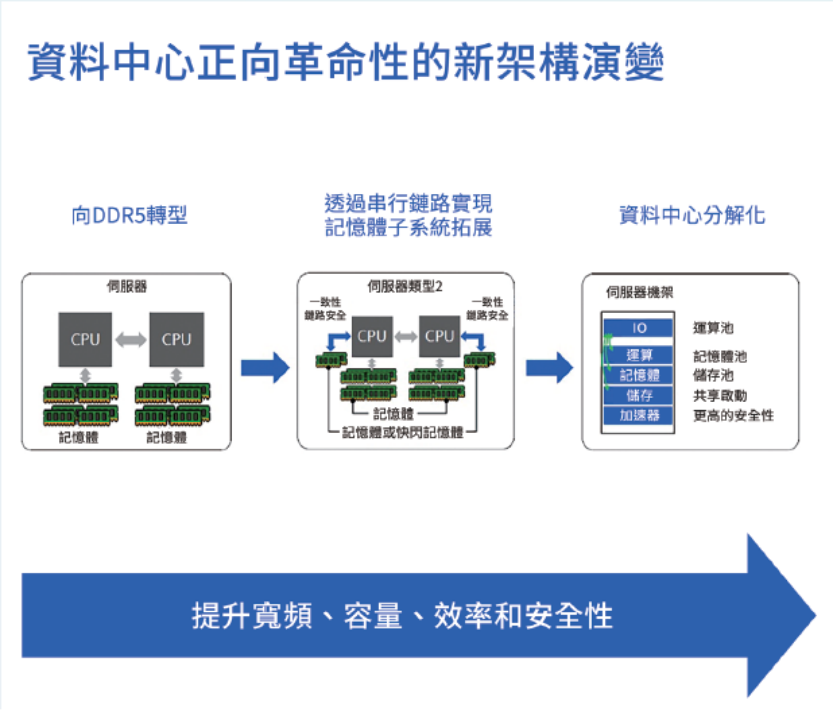
?圖2:數(shù)據(jù)中心架構(gòu)不斷演進(jìn) ?
首先,大約在2021年底,服務(wù)器內(nèi)存將會(huì)開(kāi)始向DDR5轉(zhuǎn)型。與前代產(chǎn)品DDR4相比,DDR5整體架構(gòu)較為一致,但在容量、能效等方面實(shí)現(xiàn)了大幅提升,具備現(xiàn)代化數(shù)據(jù)中心所必需的特性。
其次,預(yù)計(jì)到2022年,數(shù)據(jù)中心將會(huì)通過(guò)串行鏈路實(shí)現(xiàn)內(nèi)存子系統(tǒng)的擴(kuò)展,也就是CXL。利用CXL,就可以在傳統(tǒng)插拔式內(nèi)存條的基礎(chǔ)之上,為服務(wù)器及數(shù)據(jù)中心增加全新的內(nèi)存擴(kuò)展方式。比傳統(tǒng)插拔內(nèi)存條的方式,CXL可以進(jìn)一步提高現(xiàn)有數(shù)據(jù)中心內(nèi)存的容量和帶寬,也被稱(chēng)作“容量與帶寬的雙擴(kuò)展”。
最后,數(shù)據(jù)中心分解化。CXL的使用將讓業(yè)界更多關(guān)注資源池化和資源本身的功能效應(yīng),更高效率地分配資源。透過(guò)分解化的全新數(shù)據(jù)中心架構(gòu),運(yùn)算、內(nèi)存、存儲(chǔ)等資源將進(jìn)一步池化,從而能夠依照工作負(fù)載的具體需求,將資源定向分配。使用完成之后,這些資源又將回歸到統(tǒng)一的資源池中,等待后續(xù)的工作負(fù)載進(jìn)行重新分配。
資源池化可以將資源的利用率大幅度提高,這會(huì)為超大規(guī)模運(yùn)算,特別是云服務(wù)帶來(lái)巨大的優(yōu)勢(shì),幫助大幅度降低總體擁有成本(TCO)。因此,2019年3月,英特爾宣布聯(lián)合微軟(Microsoft)、阿里巴巴、思科(Cisco)、戴爾(Dell) EMC、Facebook、Google、惠普企業(yè)(HPE)和華為等公司,共同推出了一個(gè)全新的互連標(biāo)準(zhǔn),取名為Compute Express Link (CXL),應(yīng)用目標(biāo)鎖定互聯(lián)網(wǎng)數(shù)據(jù)中心、通訊基礎(chǔ)設(shè)施、 云端運(yùn)算與云端服務(wù)等領(lǐng)域。
如前所述,作為一種開(kāi)放的行業(yè)標(biāo)準(zhǔn),CXL可在數(shù)據(jù)中心內(nèi)的專(zhuān)用運(yùn)算、內(nèi)存、I/O和存儲(chǔ)元素之間提供高帶寬、低延遲的連接,以允許為給定的工作負(fù)載提供每個(gè)元素的最佳組合。
存儲(chǔ)器更加智能化
在傳統(tǒng)運(yùn)算設(shè)備廣泛采用的馮·諾紐曼架構(gòu)(Von Neumann architecture)中,運(yùn)算和存儲(chǔ)功能不但是分離的,而且更側(cè)重于運(yùn)算。資料在處理器和存儲(chǔ)器之間不停的來(lái)回傳輸,消耗了約80%的時(shí)間和功耗,也就是熟知的“存儲(chǔ)墻”和“功耗墻”問(wèn)題。
學(xué)術(shù)界為此想出了很多方法試圖改變這種狀況,如通過(guò)對(duì)DRAM的邏輯層和存儲(chǔ)層進(jìn)行堆疊,實(shí)現(xiàn)近內(nèi)存運(yùn)算(Near Memory Compute),或者是最好能夠?qū)⒋鎯?chǔ)和運(yùn)算有機(jī)地結(jié)合(內(nèi)存顆粒本身的算法嵌入),直接利用存儲(chǔ)單元進(jìn)行運(yùn)算,最大程度消除數(shù)據(jù)移轉(zhuǎn)所帶來(lái)的功耗。
在這一背景下,更聚焦存儲(chǔ)的新型“內(nèi)存內(nèi)運(yùn)算”(In-memory Computing)架構(gòu)誕生。從目前趨勢(shì)來(lái)看,真正對(duì)“內(nèi)存內(nèi)運(yùn)算”架構(gòu)起決定性推動(dòng)作用的,將是AI/物聯(lián)網(wǎng)(IoT)相關(guān)應(yīng)用的加速實(shí)踐。
美光針對(duì)存儲(chǔ)器與運(yùn)算架構(gòu)的發(fā)展,曾提出過(guò)三個(gè)階段的看法:第一個(gè)階段是讓內(nèi)存非常靠近邏輯運(yùn)算,用大量的高帶寬數(shù)據(jù)總線把內(nèi)存和運(yùn)算處理器更緊密連結(jié); 第二個(gè)階段是在內(nèi)存中進(jìn)行運(yùn)算處理。這個(gè)概念始于1994年,盡管實(shí)現(xiàn)量產(chǎn)在技術(shù)上存在不小的難度,軟件和邏輯也是分開(kāi)的兩部分,但消除傳輸、延遲等問(wèn)題,并且大幅提升效能; 第三個(gè)階段則是神經(jīng)形態(tài)(neuromorphic)運(yùn)算,使用內(nèi)存架構(gòu)本身做運(yùn)算。
以三星為例,其當(dāng)前主要的內(nèi)存內(nèi)運(yùn)算技術(shù)稱(chēng)為HBM-PIM,原理是在HBM內(nèi)存中直接整合運(yùn)算單元; 另一種技術(shù)方案是在DRAM旁邊直接整合加速器邏輯,以降低存去內(nèi)存的開(kāi)銷(xiāo),這樣的技術(shù)三星稱(chēng)為AXDIMM (accelerator DIMM),預(yù)計(jì)2024~2025年完成開(kāi)發(fā)。
總體而言,無(wú)論基于哪種存儲(chǔ)技術(shù),在面對(duì)內(nèi)存內(nèi)運(yùn)算時(shí),其實(shí)都存在一定的挑戰(zhàn)。但隨著ML等應(yīng)用對(duì)于內(nèi)存存取提出進(jìn)一步需求,以智能化DRAM為代表的技術(shù)方向?qū)⒊蔀楦淖兇鎯?chǔ)器市場(chǎng)格局和競(jìng)爭(zhēng)力的重要手段。
編輯:黃飛
?















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論