 電子發燒友App
電子發燒友App


過去,基于網絡的存儲的發展對網絡工程師來說并不是真正的問題:網絡速度很快,而旋轉的硬盤驅動器很慢。自然網絡升級到 10Gb、40Gb 和 100Gb 以太網足以滿足存儲系統的網絡需求。
但現在,隨著超高速固態磁盤 (SSD) 和非易失性內存高速 (NVMe) 的推出,這不再是真的!存儲團隊現在有能力使用速度極快的設備潛在地使網絡飽和。
使用 NVMe 技術(稱為 NVMe over Fabric (NVMe-oF))網絡存儲 (SAN) 對網絡提出了重大挑戰。網絡工程師需要仔細研究這一新一代存儲,以了解它們有何不同,以及它們如何滿足真正高速存儲的性能要求。
這是兩個專門針對非易失性內存快速 (NVMe)、NVMe-over-fabric (NVMe-oF) 和遠程直接內存訪問 (RDMA) 的系列文章中的第一篇。可以在此處找到關于融合以太網 (RoCE) 和 RDMA 以及如何在 Cisco Nexus 9k 系列上配置 RoCEv2 的第二篇文章。
1 什么是 NVMe?
1.1 介紹
這篇文章的目的是對 NVMe 和 NVMe-oF 的主要概念進行一般性概述,并向您展示作為網絡工程師可能遇到的不同網絡結構和協議。我不假裝在這里詳細解釋 NVMe 和 NVMe-oF 的所有規格。如果您想了解有關 NVMe 的更多信息,我在本文末尾放置了一系列您應該感興趣的鏈接。
1.2 NVMe 的來源以及它與 SCSI 的區別
直到最近,存儲系統一直基于硬盤驅動器 (HDD) 旋轉介質,帶有磁盤和移動磁頭,這是 60 多年前技術的邏輯發展。隨著驅動器技術隨著更快和更小設備的進步,存儲行業圍繞使用并行或串行總線(例如 SAS(串行連接 SCSI)或 SATA(串行 ATA))連接到 HDD 的驅動器控制器模型合并。這種從磁盤驅動器到總線到控制器再到計算機的著名且可互操作的技術鏈在性能方面非常平衡——只要磁盤驅動器像傳統的 HDD 一樣工作。
固態驅動器 (SSD) 的引入在存儲領域造成了嚴重的不平衡。突然之間,磁盤驅動器可以提供類似 RAM 的性能,具有非常低的延遲和超過 20 Gbps 的傳輸速率。這些 SSD 驅動器的第一次真正商業部署是作為傳統存儲系統中 HDD 的直接替代品。SSD 提供更高的速度、更低的延遲、更少的熱量和更少的功耗。并且無需重新設計現有的知名且廣泛部署的硬件。它們對存儲行業來說是雙贏的。
然而,簡單地將 SSD 放入現有存儲系統中存在一個缺點:它沒有充分利用底層技術潛在的性能提升。要真正從 SSD 設備的潛力中受益,需要重新考慮存儲系統連接到服務器的方式。存儲供應商在專門為基于 SSD 的存儲進行設計時嘗試了多種方法,其中最受業界關注的方法是將存儲設備直接連接到 PCI Express (PCIe) 總線。在構建了多個專有設備之后,存儲和服務器行業在 2011 年聯合起來創建了 NVMe:非易失性內存 Express。
NVMe 是一種協議,而不是形式因素或接口規范。NVMe 與其他存儲協議不同,因為它將 SSD 設備視為內存而不是硬盤驅動器。NVMe 協議從一開始就設計為通過 PCIe 接口使用,因此幾乎直接連接到服務器的 CPU 和內存子系統。在多核環境中,NVMe 效率更高,因為它允許每個核獨立地與存儲系統通信。隨著 NVMe 中的更多隊列和更深的隊列深度,多個 CPU 內核可以使 SSD 保持忙碌狀態,甚至消除內部性能瓶頸。NVMe 是一種 NUMA 感知協議,利用了較新 CPU 中內存子系統設計的進步。
1.3 從 SCSI 到 NVMe,簡而言之
1.3.1 SCSI
SCSI 將存儲視為設備(磁帶驅動器、磁盤驅動器、掃描儀等)
需要一個“說”SCSI 的適配器將 CPU 需求轉換為設備功能。
在主機和存儲之間創建 1:1 的關系。
在單隊列模型中工作:一個單隊列,每個隊列最多 64 個命令。
然后,機械磁盤驅動器演變為固態驅動器 (SSD) 或閃存:
Flash 暴露了 SCSI 的局限性,因為 flash 不旋轉,沒有什么“機械”可以等待。因此,一個命令/一個隊列系統不再有任何延遲時間。
此外,閃存所需的命令也比 SCSI 提供的要少得多。
最后,可以認為閃存就像是 PCIe RAM。這就是 NVMe 的由來。
1.3.2 NVMe
NVMe 將存儲視為內存。
CPU 可以本機與內存通信:不需要適配器。
在主機和目標之間創建多對多關系
在多隊列模型中工作:64K 隊列,每個隊列最多 64K 條命令。
總之,我們可以說 NVMe 允許主機充分利用現代 SSD 可能實現的并行度。因此,NVMe 減少了 I/O 開銷,并相對于以前的邏輯設備接口帶來了許多性能改進,包括多個長命令隊列和減少延遲。SCSI 和其他以前的接口協議是為速度慢得多的硬盤驅動器開發的,其中相對于 CPU 操作而言,請求和數據傳輸之間存在非常長的延遲,其中數據速度遠低于 RAM 速度,并且磁盤旋轉和尋道時間引起進一步的優化要求。
1.4?NVMe 定義和規范
可以在 NVM Express 組織網站上找到官方定義:https ://nvmexpress.org/——以下是摘錄:
NVM Express (NVMe) 是一種規范,它定義了主機軟件如何通過 PCI Express (PCIe) 總線與非易失性存儲器進行通信。它是所有外形尺寸(U.2、M.2、AIC、EDSFF)的 PCIe 固態驅動器 (SSD) 的行業標準。NVM Express 是定義、管理和營銷 NVMe 技術的技術行業領導者的非營利性聯盟。除了 NVMe 基本規范之外,該組織還擁有其他規范:NVMe over Fabrics (NVMe-oF),用于在網絡結構上使用 NVMe 命令,以及 NVMe 管理接口 (NVMe-MI),用于管理服務器中的 NVMe/PCIe SSD,以及存儲系統。
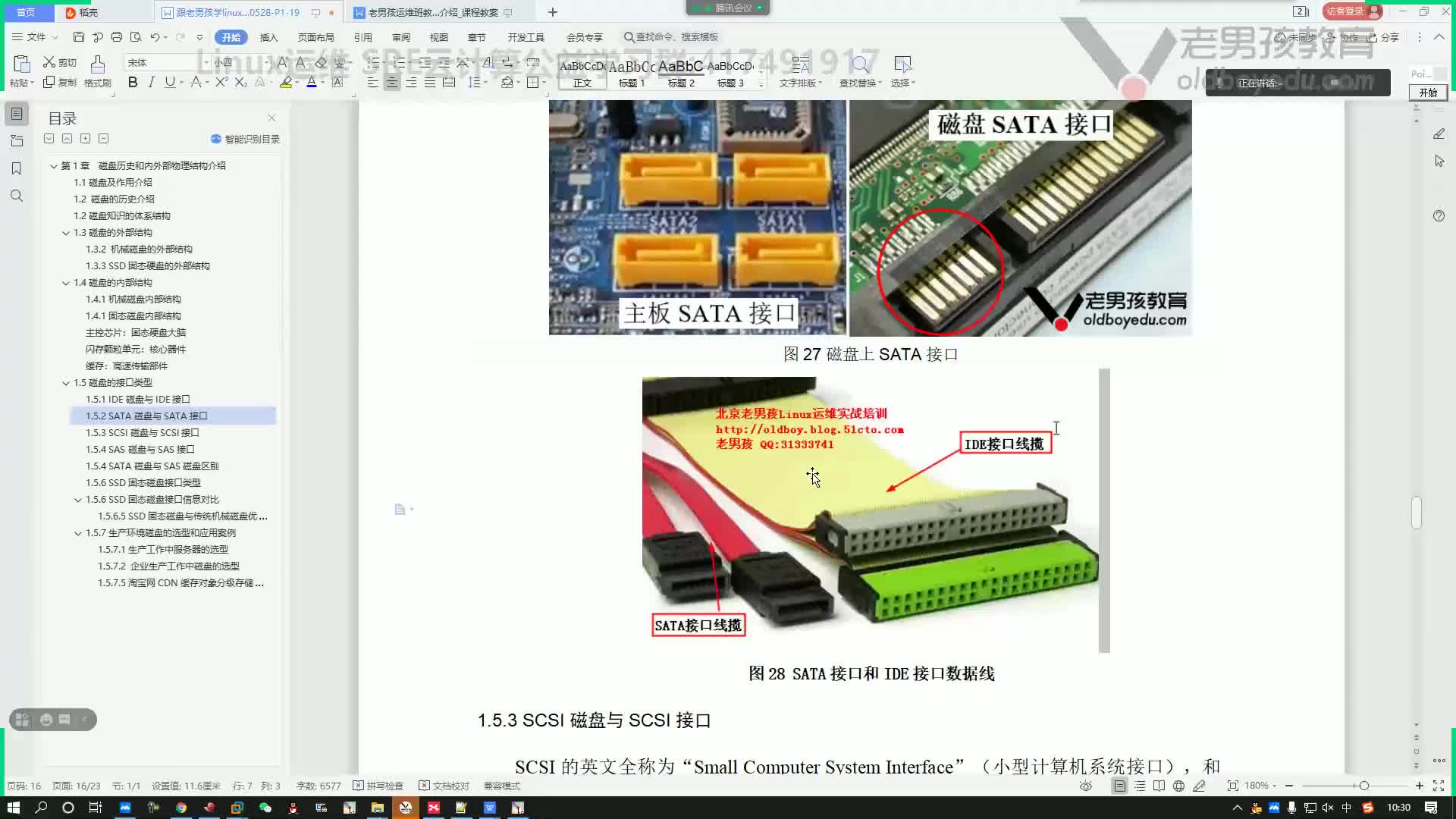
NVMe 規范是從頭開始為 SSD 設計的。它是一種更高效的接口,提供更低的延遲,并且比傳統接口(如串行 ATA (SATA))更適合 SSD。規范的第一部分是主機控制接口。NVMe 架構帶來了一種全新的高性能隊列機制,支持 65,535 個 I/O 隊列,每個隊列有 65,535 條命令(稱為隊列深度,或未完成命令的數量)。隊列映射到提供可擴展性能的 CPU 內核。NVMe 接口顯著減少了內存映射輸入/輸出命令的數量,并適應在中斷或輪詢模式下運行的操作系統設備驅動程序,以實現更高的性能和更低的延遲。
然后,NVMe、NVMe-oF 和 NVMe-MI 規范的當前版本也可以在 NVM Express 組織站點上找到,這里:https ://nvmexpress.org/developers/
2?NVMe over Fabrics (NVMe-oF)
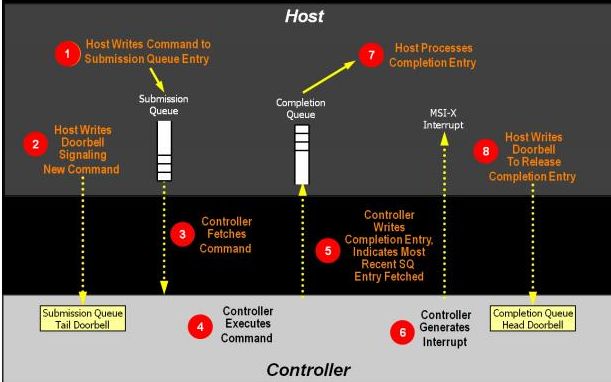
NVMe 協議不僅限于簡單地連接服務器內部的本地閃存驅動器,它還可以通過網絡使用。在這種情況下使用時,網絡“結構”支持存儲和服務器元素之間的任意連接。NVMe over Fabrics (NVMe-oF) 使組織能夠創建具有可與直連存儲相媲美的延遲的高性能存儲網絡。因此,可以在需要時在服務器之間共享快速存儲設備。將 NVMe over fabric 視為光纖通道上的 SCSI 或 iSCSI 的替代方案,具有更低的延遲、更高的 I/O 速率和更高的生產力。
服務器(或其他主機)通過網絡結構直接或間接通過控制器與 NVMe 存儲通信。如果存儲解決方案使用控制器,則控制器通過 NVMe-oF(如菊花鏈/daisy-chain)或通過其他專有或非專有解決方案與其自己的存儲目標通信。這取決于存儲供應商的實施和選擇。
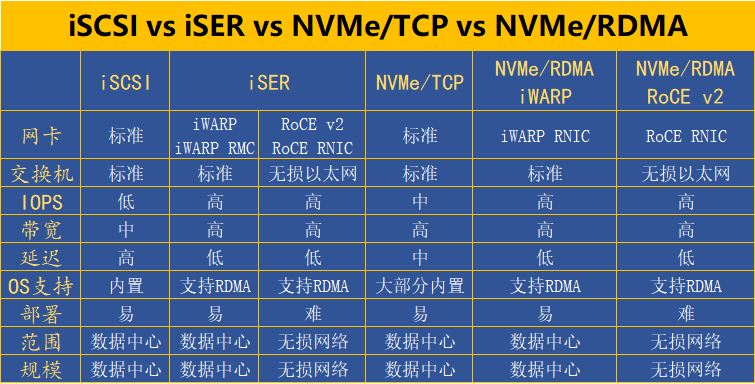
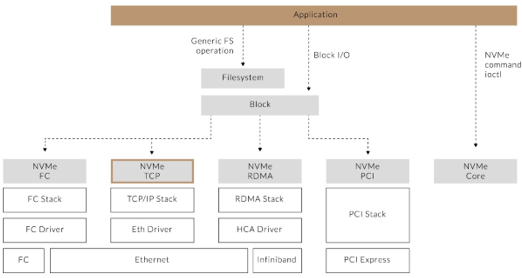
2.1 NVMe-oF 傳輸協議
作為網絡工程師,您需要了解三種官方傳輸綁定才能在您的數據中心運行 NVMe-oF:
光纖通道 (NVMe/FC)?– NVMe 啟動器(主機)與例如 Broadcom/Emulex 或 Marvell/Cavium/QLogic 主機總線適配器 (HBA) 可以通過專用光纖通道 (FC) 結構或以太網光纖通道 (FCoE) 訪問 NVMe 目標) 織物。光纖通道傳輸使用 NVMe over FC 協議 (FC-NVMe) 通過 FCP 交換將 NVMe“控制平面”膠囊(命令和響應)和“數據平面”數據消息映射到光纖通道幀。
TCP (NVMe/TCP)?– NVMe 主機和控制器通過交換 NVMe/TCP 協議數據單元(NVMe/TCP H2C 和 C2H PDU)通過 TCP 進行通信。NVMe/TCP PDU 可用于傳輸 NVMe“控制平面”封裝(命令和響應)和“數據平面”數據。作為 NVMe/FC,這是“僅消息”數據傳輸。
遠程直接內存訪問(NVMe/RDMA——在 InfiniBand 或以太網網絡上支持)?——RDMA 是一種主機卸載、主機旁路技術,它允許包括存儲在內的應用程序直接與另一個應用程序的內存空間進行數據傳輸。InfiniBand 世界中支持 RDMA 的以太網 NIC (rNIC) 或 HCA(而不是主機)管理 NVMe 源和目標之間的可靠連接。使用 RDMA,NVMe“控制平面”膠囊(命令和響應)使用消息傳輸,“數據平面”(數據)使用 RDMA 讀/寫操作等內存語義傳輸。您必須查看數據平面部分,例如 PCIe 直接內存操作。
除了這三個“官方”解決方案之外,還有其他專有解決方案允許您在網絡結構之上使用 NVMe 命令。這沒有什么問題,它們只是沒有標準化。
2.2 基于 RDMA 的 NVMe-oF
2.2.1 什么是 RDMA?
直接內存訪問 (DMA) 是設備直接訪問主機內存的能力,無需 CPU 的干預。然后,遠程直接內存訪問 (RDMA) 是在不中斷該系統上 CPU 處理的情況下訪問(讀取、寫入)遠程計算機上的內存的能力。
2.2.2 RDMA 主要優勢
零拷貝——應用程序可以在不涉及網絡軟件堆棧的情況下執行數據傳輸。數據直接發送和接收到緩沖區,而無需在網絡層之間復制。
內核繞過——應用程序可以直接從用戶空間執行數據傳輸,而無需內核參與。
無需 CPU 參與——應用程序可以訪問遠程內存,而無需在遠程服務器中消耗任何 CPU 時間。遠程內存服務器將被讀取,而無需遠程進程(或處理器)的任何干預。而且,遠程CPU的緩存不會被訪問的內存內容填滿。
2.2.3 如何使用 RDMA?
要使用 RDMA,您需要具有 RDMA 功能的網絡適配器:支持 RDMA 的以太網 NIC (rNIC),例如 Broadcom NetXtreme E 系列、Marvell/Cavium FastLinQ 或 Nvidia/Mellanox Connect-X 系列。或者,InfiniBand 世界中的 InfiniBand 主機通道適配器 (HCA)(同樣是 Nvidia/Mellanox Connect-X)。從上面寫的內容可以推斷,網絡的鏈路層協議可以是以太網或 InfiniBand。兩者都可以傳輸基于 RDMA 的應用程序。
在 Linux、Windows 和 VMware 操作系統上支持內置 RDMA。在其他操作系統上,或者對于高級功能,您可能需要下載并安裝相關的驅動程序包并進行相應的配置。
2.2.4 各種基于 RDMA 的 NVMe-oF
既然我們已經看到 RDMA 是通過網絡結構傳輸 NVMe 的三個選項之一,那么讓我們看看 RDMA 的三種變體:
InfiniBand?– InfiniBand 網絡架構本機支持 RDMA。
RoCE(RDMA over Converged Ethernet,發音為“Rocky”)
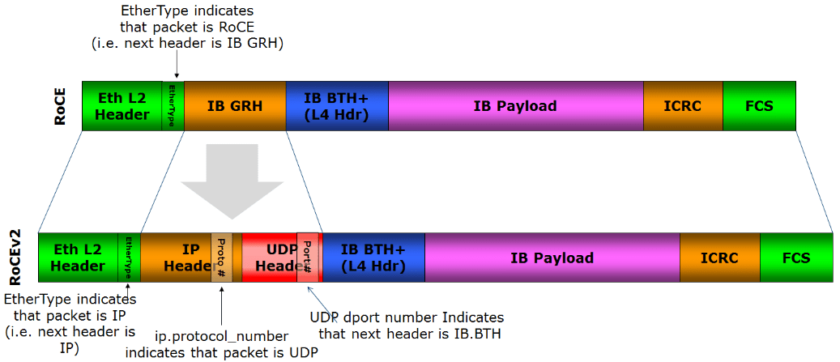
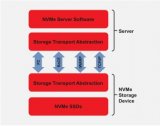
——基本上,這是通過以太網實現 RDMA。它通過在以太網上封裝 InfiniBand 傳輸數據包來實現這一點。有兩種不同的 RoCE 版本:
RoCEv1?– 以太網鏈路層協議(Ethertype 0x8915),允許同一以太網廣播域中的任意兩臺主機之間進行通信。因此,僅第 2 層,不可路由。
RoCEv2?– 使用 UDP/IP(IPv4 或 IPv6)報頭增強 RoCEv1,因此增加了第 3 層可路由性。NVMe/RoCEv2 默認使用 UDP 目標端口 4791。
這是 RoCEv1 和 v2 報頭的表示(來源 Wikipedia):
iWARP(互聯網廣域 RDMA 協議)?——基于 IETF 標準的擁塞感知協議,例如 TCP 和 SCTP。具有卸載的 TCP/IP 流量控制和管理。
即使 iWARP 和 RoCE 都使用相同的 RDMA 軟件動詞和相同類型的以太網 RDMA-NIC (rNIC),由于第 3 層/第 4 層的差異,它們無法相互通信 RDMA。今天,RoCEv2 似乎是最受歡迎的供應商選項。
2.3 NVMe-oF 網絡要求
2.3.1 協議要求
根據我們上面看到的情況,根據選擇的 NVMe-oF 解決方案有不同的要求:
專用網絡
NVMe/IB?– 通過 InfiniBand 網絡使用 RDMA。在高性能計算 (HPC) 領域非常流行。除非您在該領域或股票市場工作,否則您的數據中心可能沒有 InfiniBand 網絡。
NVMe/FC?– 需要第 5 代或第 6 代光纖通道網絡。它不使用 RDMA。已經在其數據中心擁有 FC 網絡和交換基礎設施的網絡工程師可以繼續使用這些專用資源作為 NVMe-oF 的傳輸。但是,4、16 或 32 Gbps 的典型 FC 部署速度可能不足以真正利用 NVMe 設備中可用的性能提升。
共享或融合以太網
??僅第 2 層
NVMe/FC(帶 FCoE)?——它使用以太網/FC 共享網絡基礎設施。FCoE 在 IP 層不可路由,并且不使用 RDMA。FCoE 具有與 FC 網絡相同的要求和優勢,但是您失去了在基礎架構的共享以太網部分上的網絡的可預測性。我將在下面討論網絡可預測性。
??支持第 3 層
NVMe/TCP– 使用帶有 TCP/IP 傳輸的以太網網絡,但不使用 RDMA。NVMe/TCP 似乎是最經濟的解決方案之一,因為以太網結構比 FC 基礎設施更便宜,而且實施起來最簡單。由于 NVMe/TCP 自然可路由,服務器及其存儲托架可以通過現有的以太網數據中心網絡進行通信,而無需專用的 FC 交換機和 HBA。但是,NVMe/TCP 也有缺點:最重要的是它使用服務器的計算能力,不再完全可用于運行常見的應用程序。CPU 最密集的 TCP 操作之一是計算每個數據包的奇偶校驗碼(校驗和)。另一個缺點是它比其他 NVMe-over-Fabrics 協議在傳輸中引起更多延遲。這個問題特別是由于需要在流中維護多個數據副本以避免路由級別的數據包丟失。保持非常低的延遲也非常重要(見下文)。
NVMe/iWARP?– 使用共享以太網和基于 TCP 的 RDMA。
NVMe/RoCEv2?– 使用共享以太網和基于 UDP 的 RDMA。
2.3.2 傳輸要求:有損與無損傳輸
就以太網結構上的有損與無損傳輸的需求而言,正如我們在上面看到的,RDMA 是兩個設備之間的內存到內存傳輸機制,因此理論上它不能容忍任何數據包丟失。但是,由于 iWARP 基于 TCP 協議(以及 NVMe/TCP),它可以容忍傳輸中的數據包丟失以及一些 TCP 重傳,因此 NVMe/iWARP 和 NVMe/TCP 可以通過有損網絡進行傳輸。
另一方面,RoCE 使用 UDP,它不能像 TCP 那樣從確認和重傳中受益。此外,從 RoCEv2 規范來看,您應該使用無損結構。但是,在 RoCE 協議內部有一種防止數據包丟失的機制:在數據包丟失時,將具有特定數據包序列號 (PSN) 的 NACK 控制數據包發送給發送方,以便它重新傳輸數據包。因此,說 RoCE 需要無損網絡傳輸(無損以太網)并不完全正確。RoCE 可以在無損或有損網絡中運行。
2.3.3 有關 NVMe-oF 的其他網絡信息
這是我從與專家的討論和技術研討會中收集到的一系列信息。請記住,以下信息可能會根據您的需要而有所不同,并且可能在幾個月后就已經過時了。
專用與共享以太網——與共享以太網解決方案相比,使用專用網絡(IB 或 FC)的主要缺點是價格。它當然包括維護專用網絡本身的需要,還包括人員及其技能和知識。另一方面,專用網絡的最大優勢是該網絡是可預測的。您確切地知道網絡上的內容、預期流量、延遲等。有時,尤其是在存儲方面,可預測性比其他任何事情都更重要。
NVMe/TCP 與 iWARP 與 RoCEv2 - 與 NVMe/TCP相比,使用 rNIC 的 RDMA 卸載功能可以通過減少協議處理開銷和昂貴的內存副本來顯著提升性能。但是,與所有融合基礎設施一樣,帶寬是關鍵。沒有超額訂閱,您需要密切管理和控制入站流量、隊列和流量優先級。RoCE 更是如此,它不支持(或幾乎)任何數據包丟失。
我們可以將我們的目標與我們的主機相距多遠——因為我們可以進行第 3 層路由,所以不要認為您可以將存儲遠離服務器,例如通過企業 WAN 鏈接。不,一般來說,我們會盡量讓目標遠離主機。NVMe 具有非常嚴格的端到端延遲要求,除非網絡基礎設施專門設計用于提供非常低的延遲,否則 NVMe 可能無法正常運行。
什么是可接受的延遲——每個應用程序、數據庫或核心位協議都有一個已知的延遲或 RTT 預算。您的問題應該基于此:您使用的是什么協議以及延遲要求是什么。最重要的是,如上所述,我們嘗試使目標盡可能靠近主機。
存儲結構的第 2 層與第 3 層——根據一些存儲專家的說法,存儲(尤其是塊存儲)的最佳實踐不是路由流量,主要是因為延遲原因。然而,今天的現代數據中心網絡不再基于第 2 層(STP + MLAG),而是基于具有覆蓋(VXLAN 或類似)層的第 3 層底層。所以這句話有點自相矛盾。
如果在這篇文章之后你問自己這樣的問題:“我應該建立一個專用的存儲網絡還是使用融合以太網?”或“在以太網上,我應該使用 NVMe/TCP 還是 NVMe/RDMA,然后使用 RoCEv1、RoCEv2 和 iWARP?” 和“延遲、擴展怎么樣?”
我建議您查看 J Metz 博士關于 Cisco Live 的會議:NVMe over Fabrics (NVMe-oF) 的網絡影響 – BRKDCN-2729
3 基于融合以太網的 RDMA (RoCE)
編輯:黃飛











 工商網監
工商網監
評論