 電子發燒友App
電子發燒友App


王璞博士,達坦科技(DatenLord)聯合創始人。王璞博士擁有多年云計算領域的經驗,擅長分布式計算、海量數據處理、大規模機器學習。曾供職Google美國總部,負責Google廣告部門海量數據處理平臺開發。2014年回國創業,創立數人云,專注容器技術在國內的落地和推廣。2018年,數人云被收購。2020年,創立達坦科技(DatenLord),致力打造新一代云原生存儲平臺,專注解決企業級客戶在跨云、跨數據中心方面的異構存儲、數據統一訪問需求。王璞擁有美國George Mason大學計算機博士學位,北大計算機專業碩士學位和北航力學專業學士學位。王璞發表數十篇論文,被引用累計上千次,并擁有多項云計算專利、軟著。王璞于2020年評選為騰訊云TVP。
?采用軟硬件融合的方式解決混合云場景下遠程數據訪問的性能問題
?軟硬件分層思想以及軟硬件融合對系統設計帶來的挑戰
?引入計算模型概念,以及做軟硬件設計時需要考慮的點
?并行計算模型給軟硬件系統帶來性能的提升,介紹常見的并行計算模型
?介紹幾種常見的并行計算模型的硬件架構
?軟硬件在并行場景下遇到的幾類協作與沖突問題以及解決方法
?基于 RDMA 的軟件系統設計思路,解決高性能存儲數據傳輸的問題
很高興來跟大家分享一下我們最近的工作,那天國強跟我說正好今天有兩個 RDMA 相關的話題,那我就換一個角度講,不再講 RDMA 的很多細節了。因為可能很多朋友或多或少都有些了解,我主要從另外一個角度,就是硬件融合的角度,這個也是現在比較熱門的一個話題,可能很多朋友有軟件背景或者有硬件背景,但是可能軟硬件都搞的人確實不多,對吧?講一些我們在軟硬件 CoDesign 方面的一些思考。
01 Geo-distributed Storage System
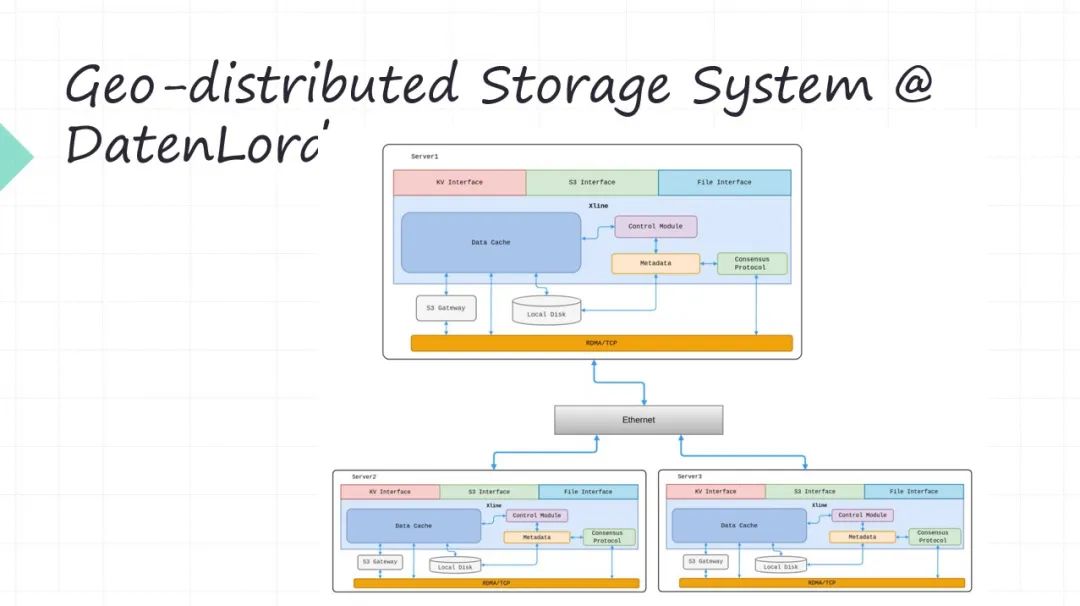
我先簡單介紹一下我們為什么要搞軟硬件融合。首先我們公司是 DatenLord,我們做的是叫 Geo-distributed Storage System。怎么理解 Geo-distributed Storage System ?就是說不同的節點,它是在不同的 Data Center,Data Center 之間有專線去連接(或者說這個上面是公有云,下面是私有云,中間是專線的連接)。這樣的這種比如多 Data Center 或者所謂 multi cloud 這個場景,現在是很多企業客戶都在關注這個場景,所謂的多云,所謂混合云等等。
這些概念里邊一個很頭疼的問題就是我的業務系統部署在不同的地方,跨 Data Center 最痛苦的就是上面的數據怎么辦?你的業務系統,比如現在都是打包成 Docker, WebFamily 或者 Serverless 這些形式去部署,部署是很靈活的,對吧?甚至現在像Serverless 將應用部署在哪里提前都不知道的。但是部署之后你的應用程序一定是會訪問數據的,對吧?數據先天又不是那么靈活的。數據絕對不是我們想放哪就放哪,想從哪訪問就從哪訪問。所以現在數據的遠程的可訪問性,這就是對于這種多云或者混合云架構帶來的最大的問題,所以我們就想嘗試解決這個問題。
就是你的業務系統部署在任何的地方都可以,當然也不是任意的,肯定有所謂的親和性的部署,但是有一定的靈活性。比如你的業務可以部署在多個 Data Center,部署在多個云上。下面的數據可以遠程去訪問,數據去搬遷這個事是吃力不討好的,那我們能不能讓數據的遠程訪問的性能大幅度提升。
所以就是為了解決遠程數據訪問的問題,所以我們用軟硬件融合的方式來把它的性能大幅度提升。因為遠程數據訪問單靠軟件是無法解決的,單靠硬件也沒辦法去搞。這是我們為什么要采用軟硬件融合的方式。
02 System Design Abstraction
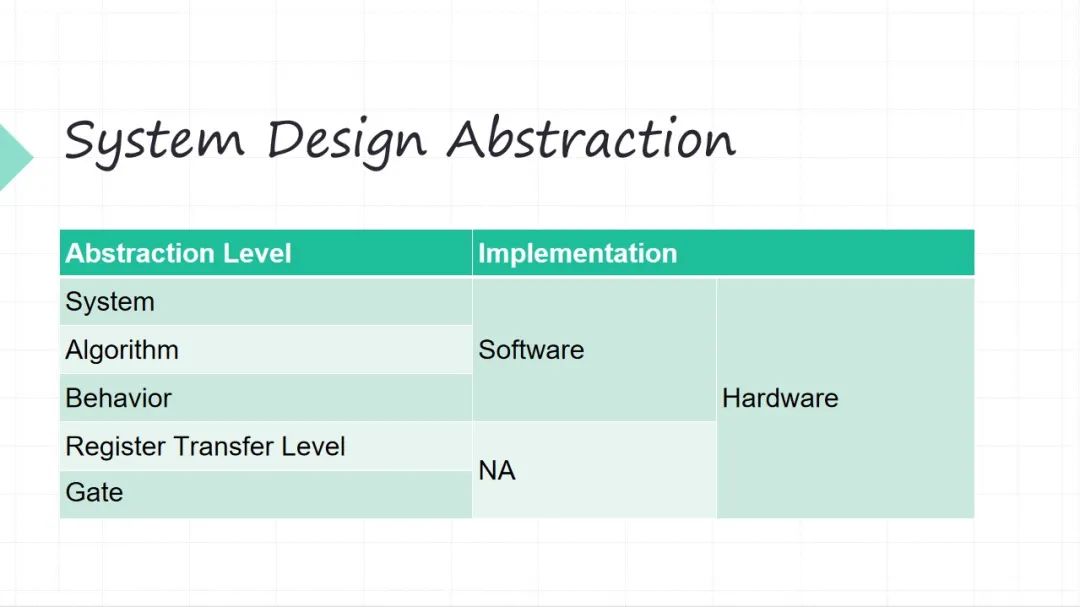
接下來簡單的列一下,我們從一個軟硬件系統的角度看我們設計的抽象層次。從上往下越來越細。上面系統整體的抽象層次,下面的算法層面,再往下行為級的層面(行為級這層面可能有些軟件同學可能不太理解,舉個例子,你的加減法操作,在軟件里面你不會再關心加減法操作怎么實現了),這三個層級軟件硬件都可以干(系統級、算法級和行為級)。再往下兩個層級、寄存器級和門級,當然還往下還有晶體管級,這些層級只能硬件干了。
所以這是不同的抽象層級軟件融合,其實比較大家一直來講比較難的一個點就是抽象層級融合起來以后會被打破。以前我們做軟件的人不會考慮硬件這么多細節,基本上不太考慮寄存器這些東西了,但是到了硬件的跨度很大,很底層的東西我得考慮,很上層的整體系統我也得考慮。所以這就是軟件融合帶來的一個設計上的挑戰。怎么去沿著原來一致的思路?比如我做系統的時候,思路不能割裂(這個事一個思路,另外的事情又個思路,這是很痛苦的),我做這種大的工程的時候,希望我的思路是一致的。
03 Software Design

簡單回顧一下軟件的題材,思路是比較容易理解的,我們先做架構設計,做完架構設計看看算法怎么回事,然后去實現,去測試。軟件的架構和硬件都是不一樣的,軟件的架構我們很多時候考慮好,比如單線程還是多線程,你是單點還是分布式等等。所以軟件里的一開始先考慮架構,我們基于現在架構設計,大家去開始實現,最后測試一下。
04 Hardware Design

硬件的設計的起點,就不一定再從架構開始了,因為硬件比較 low level ,硬件的設計的起點是計算模型 Model of Computation ,計算模型之后才是架構算法等等實現, 然后是驗證 Verification 。
05 Model of Computation

這個計算模型是什么?這最經典的兩個計算模型:圖靈機 和 Lambda 演算對吧?我們今天 CPU 都是 圖靈機 這種模型,所以為什么前面講我們做軟件的時候不會上來先考慮你計算模型?是因為我們做軟件大家默認底下是有 CPU 的嘛。所以 Model of Computation 對于軟件來講是定死的,但對于硬件我們可以采用不同的計算模型。
雖然 圖靈機 我們用了很多,但是 圖靈機 也帶來了很多的問題,比如典型我們為什么要做軟件硬件 Coding ?因為大家發現軟件很多時候處理大量數據效率并不高,因為 圖靈機 它的抽象是指令加數據,所以 圖靈機 很擅長的是做控制,指令都是控制對吧,指令里面帶了一點點數據。但是你做大量數據的處理的時候,其實今天看來為什么大家用 GPU 加速?其實 GPU 每一個 Core 還是 圖靈機,但是 GPU 一堆并行,所以想做大量數據處理的時候一定要并行,只有并行才能加速。但是 圖靈機 它是個串行模型,所以軟件本質上是串行的模型。當然今天還有多核,但多核的利用效率并不高,在并行的程度上。
所以這兩種計算模型,一個是基于是經典的 圖靈機,我們的軟件編程主要是 面向過程,從 C 開始面向過程。另一個 Lambda 演算,它后來衍生出來的就是函數式編程。函數式編程今天大家用的時候,起源就是 Lambda 開頭的。所以大家看軟件的發展也是。從單點到覺得單點計算能力有限,縱向擴展 scale up 的空間是很有限的,開始做橫向擴展 scale out,軟件不叫并行,我們叫分布式。軟件分布式的時候不好搞,這個時候借鑒了很多函數式編程。 今天我們寫很多高級語言的時候,比如像 RUST 之類的這些語言的時候,里面大量的采用了函數式編程的一些特性。為什么?因為這是底層的 Model of Computation 帶來的不一樣, Lambda Calculus 它就沒有什么指令和數據,它靠的是縮減遞歸這些東西,所以他的演算的邏輯和圖靈機是本質上的不一樣。
這個是我們一直在探索的,解決不同的問題需要用不同的 Model of Computation ,這是一個很大的挑戰。今天基本上幾乎所有的軟件都是基于 圖靈機 模型,當然有這么多年積累,肯定是有很多好處,但是缺點也很明顯,處理大量的數據,處理海量數據,性能跟不上了。提升性能?從軟件的角度對吧,借鑒一些 函數式編程 做分布式并行,這是一個維度。但是這還不夠,這還是在偏軟件層面。下一步我們想更深入地去壓榨性能,讓硬件先天并行的。
06 Software v.s. Hardware
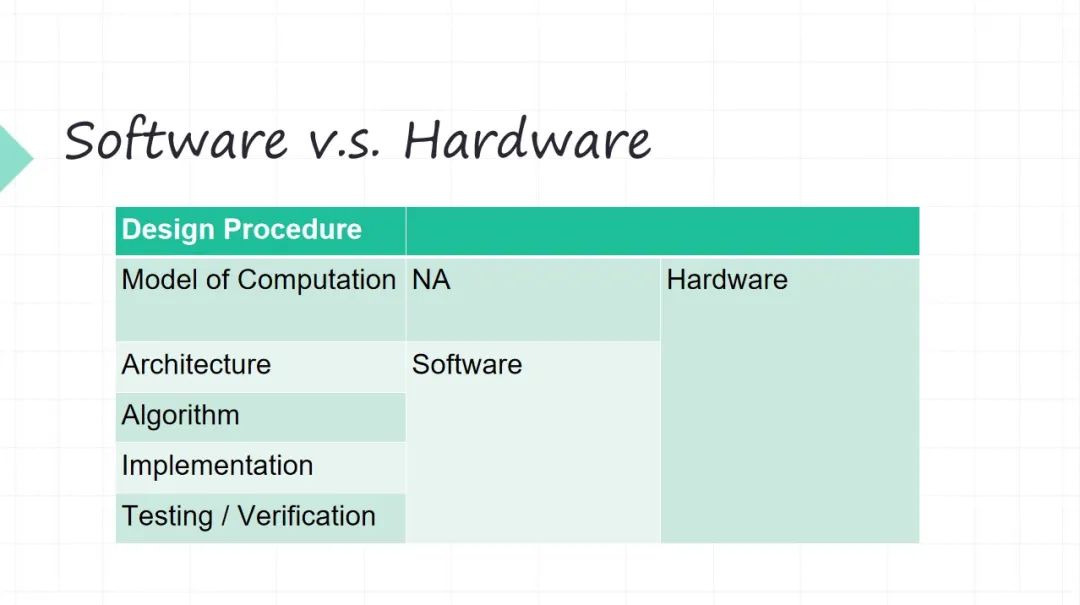
簡單地回顧一下,軟件的時候基本上是 Model of Computation ,我們很難去改變,即便今天用這種并行編程,但它底層還是跑到 CPU 上的,CPU 的計算模型是 圖靈機 模型。
當然早期(大概上個世紀七八十年代)也有人研究基于類似 Lambda Calculus 那種所謂數據流的方式做 Data Flow 模型,也是一個當年很熱的研究,但是后來輸給了 圖形機,還是 圖形機 變成了 CPU 最主流的架構。所以硬件我們在迭代的時候,根本問題就得考慮好。軟件我們沒有人再去考慮, 圖靈機模型就是一個前提假設,但硬件我可以突破 圖靈機模型。
當然今天有很多硬件,比如 Google 做 TPU( TensorProcessing Units) 的時候用的也還是 圖靈機馮諾伊曼這套模型。但是它不一樣, Google 做 TPU 的時候,它的指令很少,四五條指令,指令的力度是非常非常粗的。不像 CPU x86 幾千條指令, RISC-V 都得上百條指令(這肯定有的)。
所以在硬件我們再來設計的時候,我們就必須根據你要做的計算任務,從 Model of Computation 出發,才有后面的東西。如果沒想清楚,后面在硬件上面,你做架構,做算法,做實現,后面無從談起。
07 Model of Computation for Parallel
前面跟大家講了 Model of Computation 計算模型的概念。剛才講硬件先天并行,今天雖然有多核,但是軟件來源于圖靈機,它是個串行模型。我們今天所謂做性能加速,其實本質上就是把以前串行的事該變成并行的,這樣速度就能快了。
剛才講了,硬件我們設計的時候,第一步就要考慮計算模型是什么?計算模型這個東西,其實計算機系統過去幾十年的研究已經研究得很透徹了。在這舉了兩相對常見的,對于并行場景來講,我可以采用什么計算模型?這就不是 圖靈機,也不是 Lambda Calculus。
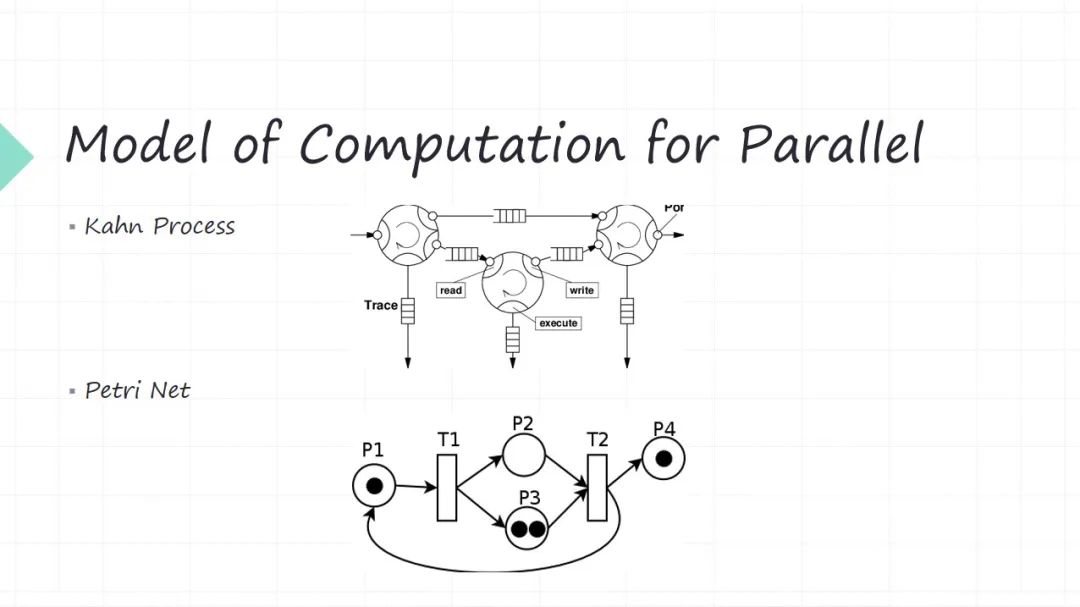
第一個模型叫做 Kahn Process,名字大家不一定那么熟悉,但是其實它的理念很簡單。每個節點是我的功能模塊,一個是生產者,另一個是它的消費者。生產者生產出來這些數據或者消息傳給消費者,消費者可能又是別人的生產者。所以其實就是生產者消費者問題,只不過這些生產者消費者之間的邏輯關系是一個網狀的,最后形成的 DAG 有向無關圖。還有很重要一點,這些消息中間都有個隊列給你緩沖一下。它假設是這些隊列是無限長的(這是一個數學上的一個很大的假設)。所以。生產者來生產數據的時候,你隊列是無限長的,所以寫操作是無阻塞的。消費者在讀取數據的時候,接收消息的時候是有可能阻塞的,因為你這個隊列有可能是空。它就是個并行的模型。
第二個模型叫做 Petri Net,可能有的朋友聽說過,這也是很常見的一個并行模型。它也是生產者和消費者模型,只不過它的建模方式和上面不一樣,它中間沒有所謂的緩沖隊列了,通過 transition 的關系來建模。圓圈代表不同的功能模塊(代表生產者),黑點代表生產資料。比如生產者(P1)黑點經過 transition 或者一個動作,它可以生產出兩個數據分別給到兩個消費者( P2 P3),這兩個數據是相同的數據,這兩個消費者( P2 P3)他拿分別拿到不同數據,他就可以變成生產者( P2 P3)。這兩個生產者都得生產出來數據才能給到后面的消費者(T2)。
并行模型中每一個功能模塊可以同時工作,只不過有的時候你上游數據不 ready,你這時候沒有數據讓你去處理。這種模型在于硬件建模是非常方便的,因為硬件它先天就是并行的。但是又不是那種 free parallel,并行工作時候你要定期去 sync ,比如模塊都是生產者也同時都是消費者,你什么時候有數據可以消費,你什么什么時候生產數據,你下游不 ready,你生產出來數據會不會丟掉等等各種各樣配合的問題。
這就是計算模型就把這些問題給你抽象出來,大家并行的時候提升性能,但是并行不是代表大家各自去自由地去跑,一定要有中間的協同,這些就是 Model of Computation 帶來的。所以這就是我們做軟件融合系統的時候,一定第一步把這個問題要想清楚,你到底解決這個問題,它是用什么樣的一個計算模型來跟他進行抽象。這些想明白的時候,剩下的東西就變得相對簡單一些。
08 Architecture in Hardware

剛才講的是并行的計算模型,接下來對硬件的階段來講,計算模型定好之后,接下來定下硬件的架構。常見的硬件架構,我這列了幾個
?有限狀態自動機(FSM),這是很常用的一個硬件模式,但狀態機它的一個缺點是什么?狀態機本質它是個串行模型(現在是第一個狀態,什么時候到第二個狀態,什么時候第三個狀態)。
?流水線(Pipeline), 是個很經典的硬件的一個并行東西,只不過流水線的不同階段處理不同的數據,但它們是在一起來工作的。
?Replica,你的模塊想并行工作,怎么辦?在硬件上我也可以搞多份。比如我的加法器和乘法器,1 個不夠用,來 10 個,100 個。
?脈動陣列(Systolic Array),是現在神經網絡里面用的很多。它是一個陣列的方式,數據在上面不停地流動每一個方框,這是一個處理節點。
所以大家看硬件設計的時候,對和軟件就很不一樣,這是常見的硬件的架構圖,我們軟件不會畫這種架構圖,因為硬件它最后你放到硅片上,在硅片上畫的東西它是個二維結構
09?Single-core Issue
硬件并行帶來了很大的問題,并行模塊之前的協同是 Model of Computation 解決的問題。
還有一個重要的問題就是硬件并行工作,一定會導致沖突。例如兩個不同模塊,你去競爭的寫同一個地方,或者一個讀一個寫,你希望先看到讀的結果還是先看到寫的結果等等。所以沖突管理這是并行的時候一定要解決的。
?Control 沖突,比如你指令的跳轉帶來的沖突問題,這因為指令是流水線,同時有多條指令在執行,你多條指令同時執行,帶來的沖突。
?Data 沖突,先讀后寫還是先寫后讀。
?Resource 沖突,CPU 里邊加法器,乘法器和 Cache 是有限的。那對于資源的競爭沖突訪問,這也是沖突。
10 Multi-core Issue

多核帶來的問題可能對于軟件的同學感受比較深一些。比如多核帶來了一個很頭疼的問題,就是內存一致性的問題。多個核的競爭的往內存里讀寫,這個時候你內存的數據怎么才能稱之為是一致的?定義了幾種 Memory Order 的一致性的級別。
?順序內存一致性 Sequential Consistency ,假設大家雖然是并行目的,但是順序地來讀寫內存顯然不會出錯,但是顯然 sequential 太強的要求了,你想要性能的時候 sequence 為了保證正確性,得是串行的來。這跟我們對性能的要求是沖突的。
?Total Store Order 就是 X86 的默認的 Order,先 store 后 load,可以亂序。
?Multi-copy Atomic 就是 RISC-V 的默認Order。你個核先寫的東西自己可以看見,如果別的核看見,都得能看見。
在借鑒 CPU 體系結構過往的一些工程經驗里邊,已經有很多實踐去來解決并行工作帶來的數據沖突的問題。這塊是個很麻煩的問題,我們做軟硬件設計的時候,這些問題你都會碰到,因為你做數據處理,一旦并行的時候,這些問題自然而就來了。而且我們做計算的時候很少碰到那種場景是純并行,完全不用考慮互相的協作,是很少很少的場景。
11 Parallel vs Distributed

不管是并行也好,還是分布式也好,是沖突的問題,我們去怎么去解決它。其實從軟件和硬件角度我們都有大量的工作。
?比如 分布式一致性 算法,像 Python 算法常用的 Raft 協議等等,它們也是在解決沖突的,只不過是在一個時間維度很大的的維度上(比如毫秒級,網絡傳輸都基本上都是毫秒)。
?到了 內存一致性 問題的時候,這個時候就到了一臺服務器了,這時候它的時間維度大概是微秒或者亞微秒,大幾十納秒等等。
?到了 CPU 里頭,這就是變成 Cache一致性 問題,考慮就是納秒級的問題了。
所以其實我們在做一個復雜的系統(計算機系統或者數字系統)的時候,為了解決性能問題,大量的用并行或者用分布式來做加速做肯定快。但是并行或者分布式加速帶來的問題就是沖突。其實協作還是小問題,沖突是最大的問題。沖突怎么做?其實有很多現有的方案,只不過這些方案不一定是大家每個人都天天在研究的東西。但是當我們下沉到軟硬件協同設計的時候,這些問題就通通都暴露出來了,為什么會暴露出來?我們平時寫軟件,我們我有一定的抽象,但是當我軟硬件聯合迭代的時候,這些抽象就打破了,所以你只能從根上你把這個問題想明白。
12 Conflict Resolution in Hardware

怎么解決沖突這個問題?其實都有很多開源的庫去解決它,每個語言里邊都有。硬件里面的沖突管理怎么做的?其實 CPU 的體系結構的研究里面講了不少,比如一個核里的流水線,各種 hazard 這些。
但是推而廣之,如果一個硬件系統,特指數字硬件 IC 這種系統,如果我們造的不是 CPU,今天做軟件融合的時候,大概率底下硬件系統不一定是個 CPU,這個時候怎么解決這些沖突?其實借鑒的方法跟軟件的思路是一致的,本質都是個都是并行工作帶來的沖突。所以解決問題的思路是一致的,只不過具體的方法不一樣。
?彈性 Elastic ,軟件是很靈活很彈性的,但硬件沒那么彈性。硬件我在設計的時候,協議層面讓大家互相的消息傳遞要變成彈性,對這個消息的 delay,要對 delay 變得不敏感(不要假設過多長時間,我把消息發給你),這些消息的 delay 你是不可控的,什么時候消息傳遞成功等等。
?保證原子性 Atomic。比如大家我們做分布式系統的時候,基本上都有一個分布式一致性的,一個節點或者一個服務保證原子性。硬件也一樣,各種沖突我也得保證原子性,其實本質上就是個 transaction 的概念。怎么保證?就需要你底干上有一些東西,所以原子性是不好做的。比如軟件里面大家用所謂各種無鎖操作,其實本質上就是用 CPU 直接提供原子操作。
?調度 Scheduling ,本質通過優先級來解決沖突問題(沖突是不可避免的)。沖突的時候誰優先級更高,誰優先級更低。
當然這幾個方法,可能彈性相對還好處理一點,有硬件協議來做,剩下的原子性,還有 Scheduling 都得我們設計硬件的都想得很清楚。
13 RDMA Software/Hardware Co-design
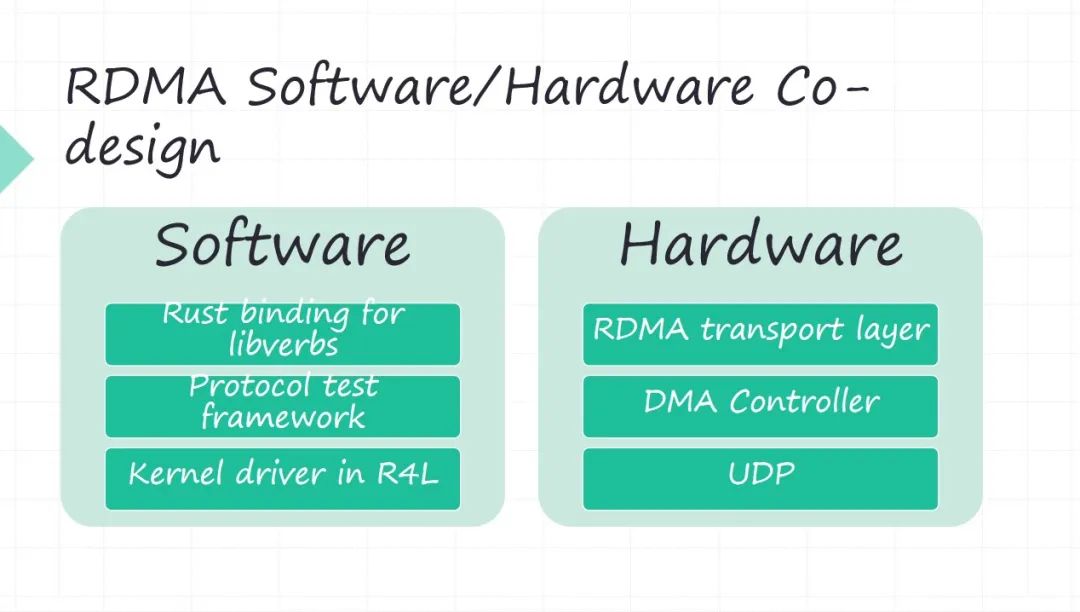
以我們做 RDMA 這樣一個軟件系統,給大家簡單介紹一下我們的思路,就說我們用 RDMA 主要是解決高性能存儲數據傳輸的問題。 RDMA 本質其實也是軟硬件的一個系統。我們為什么自己做 RDMA 的硬件,是因為 RDMA 商用的卡里邊有一些不夠靈活的地方,比如 RDMA 的擁塞控制,今天基本上就兩種解決方案,一種你就買 InfiniBand 的那套商用的方案。
但是當今數據中心我們大量用的交換機路由器還是以太網的。你要用 InfiniBand 的解決方案,那跟以太網的交換記錄器的協議都不一樣,雖然也可以融合,但是肯定不是個很優的方案,再加上成本的考慮。
今天 RDMA 落地數據中心大部分都是 RoCE 方案,所以我們也是采用 RoCE 方案, RDMA 跟以太網融合。但 RoCE 方案最大的問題是什么?流量控制對他來講是黑洞。為什么這么講?你看,比如像 InfiniBand 它解決 RDMA 的流量控制問題,他從他的鏈路層,網絡層,傳輸層,每一層都要去解決這個問題。但是到 RoCE 的時候就沒那么容易了。
RoCE 是把 RDMA 的傳輸層嫁接到了 UDP 上, UDP 根本沒有任何的流量控制和擁塞控制的管理能力,只用 RDMA 的傳輸層, RDMA 傳輸層只有很少的流量控制,而且 RDMA 傳輸層沒有擁塞控制能力。今天所有的 RDMA 的流量控制和擁塞控制,都是靠額外的算法在外層去來解決這個問題。
我們為了實現高性能傳輸的時候,就要流量控制和擁塞控制,特別是擁塞控制。我們覺得這個問題對我們是非常關鍵的,所以我們自己去搞硬件。而且擁塞控制這個東西,它還不是純硬件能解決的,上面還有軟件的很多東西。當然這些問題我們今天還沒有解決完。所以我這列的時候沒有提很多流量空投有所控制的問題。但是如果感興趣,是網絡研究的一個很大的熱點。
我們做 RDMA 軟件和硬件的時候,其實功能模塊還是比較容易理解的。
?軟件首先就是 RDMA 的 API,因為我們軟件有 Rust,我們把它做了一套 RDMA 的 API 的 Rust binding forlibverbs。再一個 RDMA 的測試是沒有什么開源的方案,所以我們自己搞了一套協議的一個測試框架。再一個還有驅動的部分(硬件必然會有驅動),今天我們看 Linux 內核已經開始采用 Rust,我們正在看用 Rust for Linux 怎么來做一個驅動,前期做了一些調研,但目前還不太成熟,所以我們還沒有真正上手在干。回到硬件這端 RDMA 的傳輸層,是要硬件實現好。
?硬件里邊 DMA 基本是 RDMA的性能瓶頸, DMA 系統的最大的 delay 都是 PCIE 帶來的。基于 PCIE的 DMA controller 怎么做高性能的 DMA 操作。包括現在新出 CXL 協議出來之后,會很大程度上解決 DMA 的性能問題, CPU 和你的外設是在同一個地址空間,再也不需要做什么內存的地址空間和 PCIE 地址空間 mmap 的問題了。
?再一個就是 RoCE 方案,是用 UDP 來傳輸的。 UDP 也搬到硬件上去實現,需要實現的這些組件。
14 RDMA Software
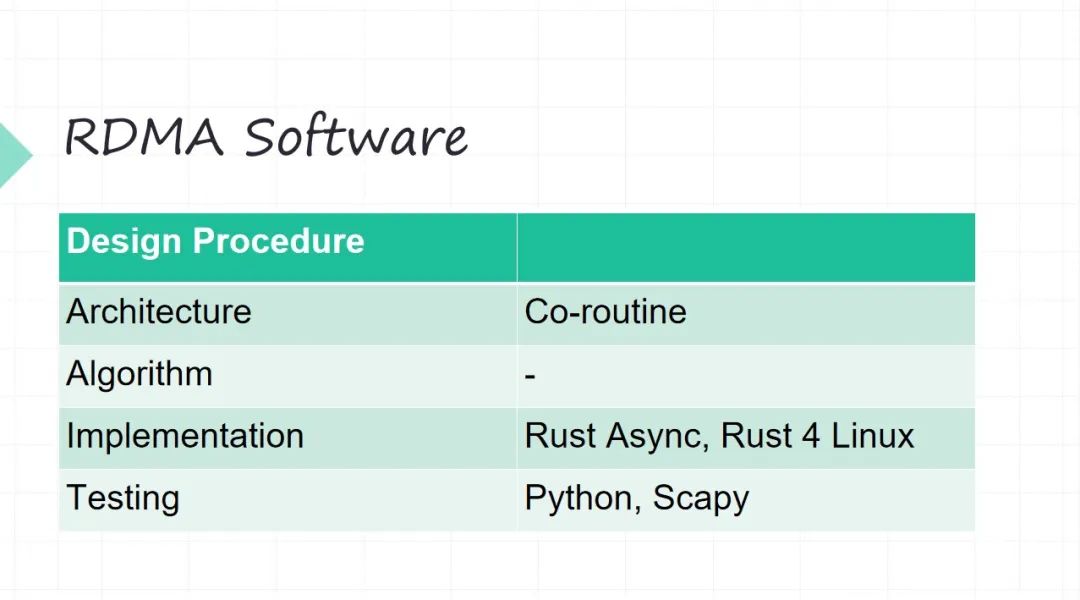
但是在實現的時候,幾個底層的抽象就不一樣。軟件可能相對好想一些,你不需要考慮 Model of Computation ,你軟件是 圖靈機 模型。
?軟件的架構。這個時候我們選一個架構,比如上面 RDMA 的這些 API 等等,我們都用協程的方式(不希望用線程這種模型,因為線程要內核來調度,我們不希望做很多的上下文切換)。
?算法不太涉及, RDMA 網絡協議不太涉及太多算法。
?軟件我們主要是用 Rust,Rust 里面就是Rust Async。驅動在內核里面用 Rust for Linux 。
?測試我們主要用 Python,在 Python 里面主要用 Scapy做網絡包的一個測試,很常見的框架。
15 RDMA Hardware
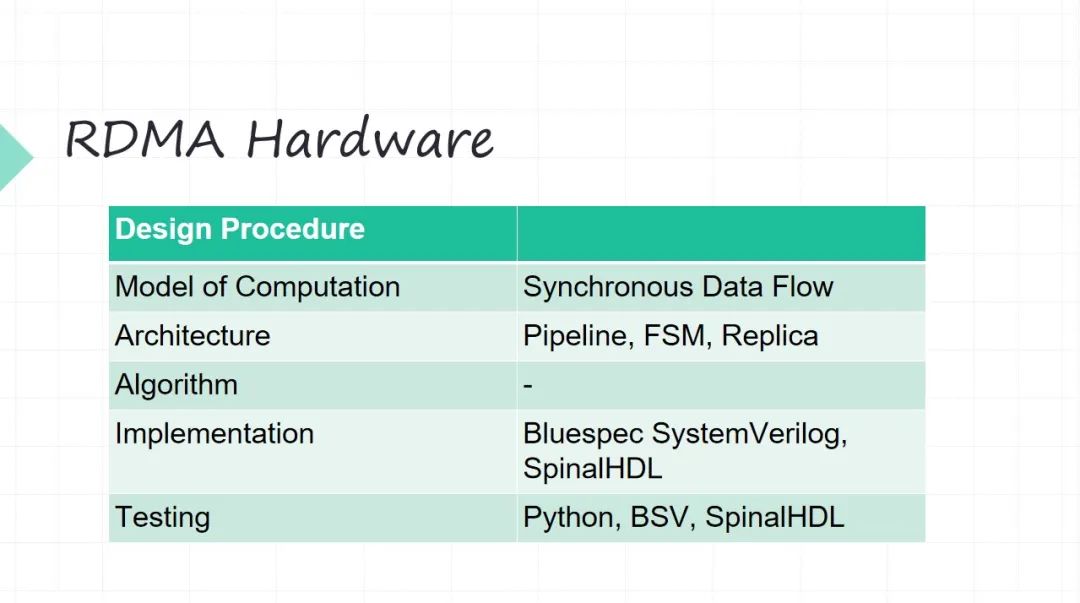
硬件的設計要從 Model of Computation 開始了。因為 RDMA 它是個網絡協議不是 CPU ,網絡協議主要是做數據傳輸。
?它的 Model of Computation 我們選擇的是叫作同步數據流模型。其實它本質上是一個前面介紹 Kahn Process的簡化。最大的簡化在于好我不同的生產者、消費者中間之間緩沖 FIFO,我這是要管理的(它不可能是無限的,硬件沒有那么多無限的資源)。同步數據的模型 它的一個很大的優點就是做了比較強的一些假設,就是每個生產者每個時刻產生一個數據,每個消費者每個時刻接收一個數據,這樣有了很強的一個假設之后,好我中間緩沖,我就可以精確地算出來了。有了 同步數據流模型之后,你的這些并行之間的調度問題也可以提前做一些安排。
?架構層面這就是用一些硬件經典的架構,比如 pipeline 流水線架構。像網絡數據進來之后,很長的一個流水線,我們最長的流水線也大概十七八級了。狀態機也少不了。整體的并行控制等等。比如 RDMA 它不同的隊列對吧?不同的 QP(Queue Pair),預先設好有多少個 QP,靠不停地去在硬件上去復制它。
?算法不涉及。
?Implementation 的時候,我們沒有采用 Verilog 傳統的硬件開發語言。用一些比較新的 Implementation 的硬件描述,主要的考慮也在于盡可能提高開發的效率。用兩個東西,一個是 Bluespec SystemVerilog,一個是 SpinalHDL。
?測試的時候,我們現在做一些基于 Python 來做硬件的 Verification。當然這兩個開發語言本質它也要寫很多測試驗證的問題。
這個是我們整個迭代硬件的一些思考和價值。
編輯:黃飛
?












 工商網監
工商網監
評論