 電子發燒友App
電子發燒友App


今天和大家聊聊數據庫。
什么是數據庫?
這個問題相信對學編程的朋友們來說過于簡單了,大家想必都是增刪改查的好手。
但如果讓你說出 10 種不同類型的數據庫,閣下該如何應對?
這篇文章,是對數據庫技術的一個小科普,希望能幫大家了解到更多元化的數據庫,便于拓寬學習思路和項目的技術選型。
關系型數據庫
首先是我們接觸最多的、也是入門后端必學的 關系型數據庫 。
在關系型數據庫中,數據以 表 的形式進行組織和存儲,每個表就像一個 Excel 表格,包含多個 行 和多個 列 。
就比如我們經典的學生管理系統,把學生信息存儲到關系型數據庫中,結構大概是這樣的:
| 學號 | 學生姓名 | 所屬班級號 |
|---|---|---|
| 1 | 小李 | 1 |
| 2 | 小魚 | 2 |
| 3 | 小皮 | 3 |
?
上述學生表格中,每一行代表一個學生的信息,每一列代表學生的一個屬性。我們可以使用結構化查詢語言 SQL 來對關系型數據庫表的數據進行靈活地查詢、選擇、過濾等。
而關系型數據庫最大的特點,就是表和表之間可以 存在關系 。比如學生管理系統中還可以有班級表,結構如下:
?
| 班號 | 班級名稱 |
|---|---|
| 1 | 快樂班 |
| 2 | 泰酷班 |
| 3 | 躺平班 |
?
那如果我想知道某個學生所屬的班級信息,只需要在查詢時將學生表的 所屬班級號 和班級表的 班號 進行關聯,而不用把所有表格的列存儲在一起,非常靈活。
通過 SQL 可以連接查詢多張表,得到下面的查詢結果:
| 學號 | 學生姓名 | 所屬班級號 | 班級名稱 |
|---|---|---|---|
| 1 | 小李 | 1 | 快樂班 |
| 2 | 小魚 | 2 | 泰酷班 |
| 3 | 小皮 | 3 | 躺平班 |
除了查詢靈活、數據表間存在關系外,關系型數據庫還具有很多其他的優點。
比較重要的是 數據一致性 ,關系型數據庫遵循 ACID 原則(原子性、一致性、隔離性和持久性),支持事務,可以保證多個操作同時進行時,數據的狀態保持一致。比如 A 給 B 轉賬,A 扣錢 的同時 B 也會加錢,不會出現 A 扣了錢 B 卻沒收到錢的情況。
兼顧查詢的靈活和寫入的準確性,使得關系型數據庫幾乎可以被應用于任何項目中!比如 CRM(客戶關系管理)和 HRM(人力資源管理)等各類管理系統、數據分析系統、金融銀行系統等。
比較經典的關系型數據庫產品有 MySQL、Oracle、PostgreSQL、Microsoft SQL Server 等。其中,MySQL 由于開源又易學,已經成為后端開發同學必學的數據庫技術。
關系型數據庫的底層核心實現是 基于關系模型的數學理論 ,最常見的實現方式是使用 B+ 樹來存儲索引結構,基于其平衡性,能夠在存儲大量數據時保持高效的查詢性能,并且兼顧增刪改操作的性能。
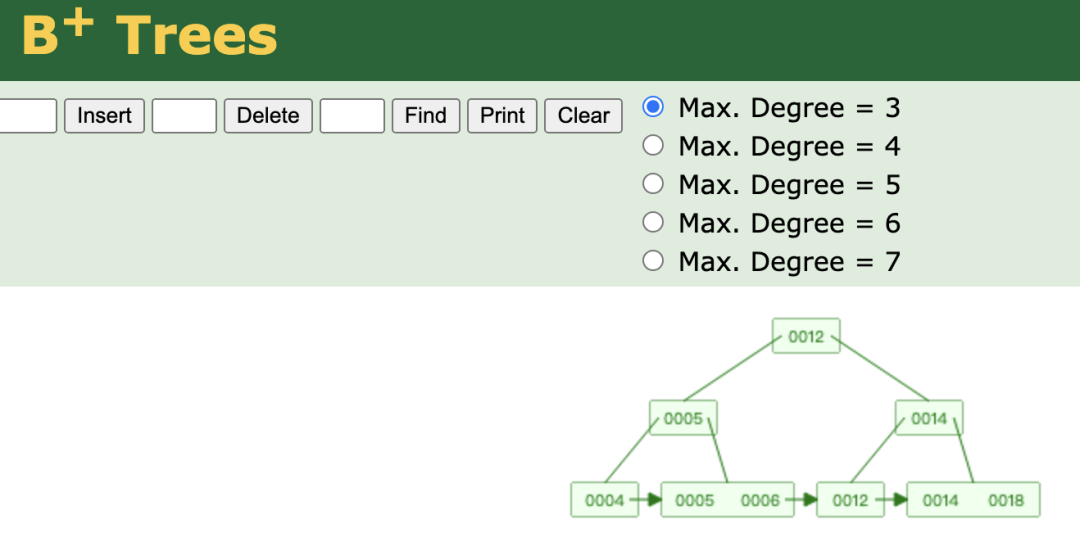
對于大多數項目,用 MySQL 等關系型數據庫來存儲數據就足夠了。但關系型數據庫不是銀彈!在某些場景下,比如要存儲的數據間沒有關系時,它并不是最佳的選擇。
舉個例子,當我們要寫一篇文章,沒有必要把數據存儲到 Excel 表格里,可能直接將單篇文本放到 Word 里會更方便閱讀和修改。
這個時候,我們就需要與之互補的 非關系型數據庫 。
非關系型數據庫
非關系型數據庫又叫 NoSQL。最簡單的理解方式:關系型數據庫適用于存儲相互之間 存在關系的數據表 ,那么非關系型數據庫適用于關系不強的、結構相對靈活的、需要被快速訪問的數據,比如字符串、JSON 等。
實際項目開發中,最常用的非關系型數據庫當屬 KV 數據庫。
KV 即 Key-Value,數據是以 鍵值對 的方式存儲在數據庫中的。可以理解為一個 HashMap,數據庫中存儲的每個鍵都 唯一對應 一個值。鍵和值都可以是任意類型的數據,例如字符串、數字、數組等,非常靈活。
比如存儲每位用戶的個人信息,結構大概是這樣的:
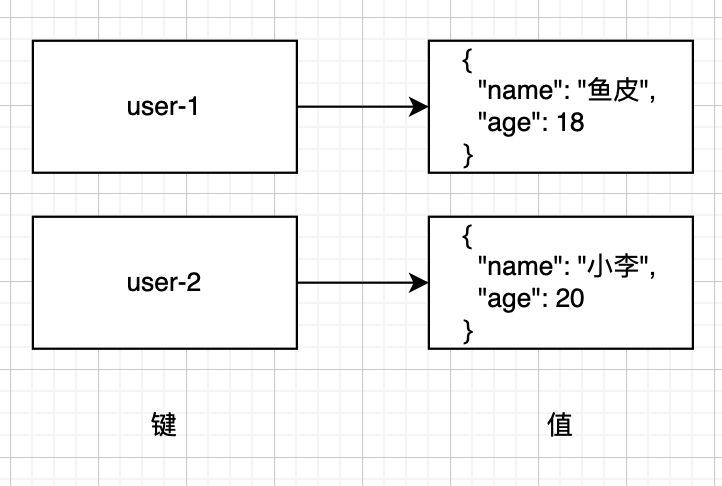
由于 KV 存儲的結構簡單清晰,我們能夠很輕松地根據某個鍵查找出對應的值,無論是讀寫數據性能都非常高。
此外,KV 數據庫還具備良好的可擴展性,由于數據間不存在直接關聯,我們可以把鍵值對放到多個機器上存儲,通過數據分片、負載均衡等策略來支持海量數據的高并發訪問。
由于高性能和高可擴展性,KV 數據庫被廣泛應用于緩存、分布式會話、分布式鎖、實時統計等場景。
最經典的 KV 數據庫當屬 Redis 了,它是開源的、基于內存的、高性能的數據庫,不僅支持豐富的數據類型和功能,還有持久化等重要特性,也是后端同學必學的技術。其他的常用 KV 數據庫有 LevelDB、RocksDB、Apache Cassandra 等。
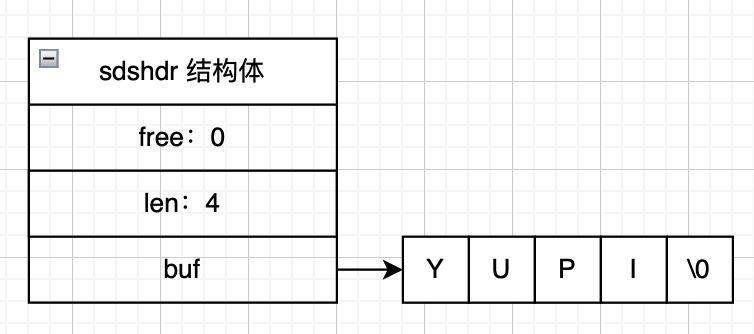
KV 數據庫的底層實現比較靈活,常見的實現方式是使用哈希表來存儲鍵值對。不同類型的值對應的實現方式也不同,比如 Redis 的字符串存儲采用簡單動態字符串(SDS)實現。
解決特定問題的數據庫
相信很多同學對數據庫的印象就停留在 MySQL 和 Redis。的確,以上兩類數據庫幾乎已經可以解決所有問題!
但是,未必是最適合的。
就像你完全可以用電腦自帶的記事本軟件來查看和編輯 HTML 網頁文件,但是往往會選擇一個更專業的開發工具來替代它。
數據庫也是一樣,除了傳統的關系和非關系型數據庫之外,還有很多用于解決特定問題的數據庫。它們往往針對特定的數據結構和應用場景進行了專門的優化和設計,能夠提供更高效快捷的數據查詢和存儲,滿足特定領域的需求。
比如下面 8 種數據庫:
搜索引擎數據庫
顧名思義,搜索引擎數據庫是為了實現搜索引擎功能的數據庫。
它適用于存儲和管理大量的文本內容數據,并提供更快速、準確、靈活的全文檢索功能。
比如想要讓用戶更輕松地在你的博客內搜索文章,就可以使用搜索引擎數據庫。
為什么它能做到更快更靈活的搜索呢?這是因為在搜索引擎數據庫中,數據一般是以 倒排索引 的方式存儲的。
倒排索引和傳統的關系表有什么區別呢?
以存儲博客文檔為例,傳統的關系型數據庫存儲結構是:
?
| 文檔 id | 文檔內容 |
|---|---|
| 1 | 感謝關注魚皮 |
| 2 | 魚皮是一名程序員 |
| 3 | 感謝關注菜鳥教程 |
?
我們能夠根據 id 來查找到對應的單篇文檔,也可以通過搜索精確的關鍵詞,來查找到多篇文檔。
比如搜索 “魚皮”,能搜出文檔 1、2。
但是,如果你搜索 “魚皮程序員”,是無法得到搜索結果的,因為沒有任何一個文檔的內容,完全包含 “魚皮程序員” 這個詞(文檔內容 2 只有 “魚皮”、“程序員” 這兩個詞)。
而在搜索引擎數據庫中,首先會將文檔內容按照單詞進行分割,也就是 分詞 。然后再構建單詞到文檔 id 的映射,示例結構如下:
?
| 單詞 | 文檔 id |
|---|---|
| 感謝 | 1, 3 |
| 關注 | 1, 3 |
| 魚皮 | 1, 2 |
| 程序員 | 2 |
?
有了上述的倒排索引,當用戶搜索 “魚皮程序員” 時,搜索引擎數據庫會先對搜索詞進行分詞,得到 “魚皮” 和 “程序員”,然后根據這兩個詞匯就能找到文檔 id 1、2 了。不用再去遍歷表內所有的數據,實現了更靈活、快速的 模糊搜索 。
此外,搜索引擎數據庫還支持 相關性排序 ,能夠根據用戶的搜索詞對所有搜索結果進行打分,把最接近的文檔排到最上面。
主流的搜索引擎數據庫技術有 Elasticsearch、Apache Solr、Apache Lucene 等,一般更建議大家學習 Elasticsearch,這玩意更新迭代得老快了。
文檔數據庫
顧名思義,文檔數據庫適用于存儲和管理 半結構化的 文檔數據,比如存儲 JSON 格式。
相比于關系型數據庫中明確定義的表格行列,文檔數據庫的數據結構是類似于文檔的層次化結構,每個文檔都是獨立的,可以包含多個不同類型和格式的數據。
比如存儲博客文章,示例結構如下:
?
| 文檔 ID | 文檔數據 |
|---|---|
| 1 | {"_id": 1, "title": "文章標題1", "content": "這是文章1的內容"} |
| 2 | {"_id": 2, "title": "文章標題2", "author": "程序員魚皮"} |
?
當我們要給某個文檔新增一個字段時,不需要像關系型數據庫一樣改變表結構,非常靈活!
除了靈活之外,文檔數據庫也有很高的可擴展性,適用于內容管理系統(比如博客)、文檔協同編輯系統等。
個人比較推薦學習的文檔數據庫是 MongoDB,入門難度極低,對前端同學也很友好。當然,Couchbase 也是不錯的。
時序數據庫
時序數據庫是一種專門用于高效存儲和處理 時間序列 的數據庫系統。
時間序列是指以時間作為主要維度的數據序列,即每個數據單元都包含 時間戳 。
舉個例子,在實時溫度監測系統中,我們需要 每分鐘連續 收集并觀察當前的溫度,數據結構示例如下:
?
| 時間戳 | 設備ID | 溫度值 |
|---|---|---|
| 2023-07-01 10:00 | Device001 | 25.5 |
| 2023-07-01 10:01 | Device001 | 25.7 |
| 2023-07-01 10:02 | Device001 | 25.8 |
| 2023-07-01 10:03 | Device001 | 26.2 |
| 2023-07-01 10:04 | Device001 | 26.5 |
| 2023-07-01 10:05 | Device001 | 26.3 |
?
有了這些數據,我們就能夠按照時間范圍進行高效查詢、聚合分析、數據可視化。
因此,時序數據庫非常適用于物聯網(比如傳感器數據)、日志監控、金融交易數據分析等場景。
主流的時序數據庫技術有 InfluxDB、TimescaleDB 等。一般情況下,建議將時序數據庫配合 Grafana 監控看板一起使用,實現數據存儲 + 快速可視化。
不同時序數據庫底層的存儲方式也不同,我們可以簡單理解為,時序數據庫會根據 時間 字段構建索引,查詢時通過索引去定位實際數據。比如 InfluxDB 使用 TSM(Time-Structured Merge Tree)作為存儲引擎,底層使用 B+ 樹來存儲時間索引。
向量數據庫
向量數據庫是專門用于存儲和處理 高維向量數據 的數據庫系統。
什么是向量?每個向量可以表示一個實體,并且包含多個維度的數值。
舉個例子,在人臉識別系統中,我們可以通過人臉的 特征 來判斷是否為熟人。每張人臉圖像,都對應一個向量;每個人臉向量有可能包含成百上千個特征,比如鼻子大小、眼睛大小等,每個特征就是一個維度。
對應的數據結構示例如下:
| 人臉 ID | 人臉特征向量 |
|---|---|
| 1 | [0.1, 0.2, 0.3, ..., 0.5] |
| 2 | [0.1, 0.3, 0.2, ..., 0.4] |
在上述表格中,人臉特征向量是一個浮點數數組。數組的每個下標就表示一個特征(維度),比如下標 0 的數值表示鼻子的大小,下標 1 的數值表示眼睛大小,以此類推。。。
我們只需要對比向量,就能夠判斷出人臉的相似度。
向量數據庫能夠高效存儲多維向量數據、計算向量的相似度、并實現各種不同算法的相似性搜索,適用于圖像識別、特征提取和匹配、推薦系統等場景。值得一提的是,AI 技術的發展也帶來了一波向量數據庫技術的熱潮,可以利用向量數據庫存儲投喂給 AI 的訓練 Embeddings 數據。
主流的向量數據庫技術有 Milvus、Pinecone、Faiss 等,有些數據庫(比如 PostgreSQL)可能也支持存儲向量類型的字段。
關于向量數據庫的底層實現,還是比較復雜的。類似于上面提到的時序數據庫,向量數據庫的實現關鍵也是索引的設計。常見的向量索引結構有倒排索引、KD 樹、球樹等,可以理解為對相似的向量數據進行了分組和編碼,從而實現更快速地檢索匹配相似向量。此外,向量數據庫往往也會采用并行計算來加速處理。
空間數據庫
空間數據庫是專門用于存儲和處理 地理空間數據 的數據庫系統。
地理空間數據是指基于地理 坐標系 的 幾何對象 ,比如某個物體所處的經緯度或三維坐標(點)、某個物體的輪廓(線)、某個物體的表面(面)等。
舉個例子,假如你想存儲自己房間內每個物體的位置信息,對應的數據結構可能是:
| 物體 ID | X 坐標 | Y 坐標 | Z 坐標 |
|---|---|---|---|
| 1 | 2.5 | 3.0 | 1.8 |
| 2 | 1.0 | 4.2 | 2.3 |
| 3 | 3.7 | 2.1 | 1.5 |
使用空間數據庫,能夠高效地存儲、查詢和分析空間數據,比如計算兩個空間是否相交、對路徑進行規劃、可視化地理空間等。
空間數據庫不僅是地理信息系統(GIS)的核心組件,還能用于實現位置導航、城市路面規劃等場景。
對于具體的空間數據庫技術,我了解得不多,只知道可以用 PostGIS 插件來為 PostgreSQL 支持空間數據管理能力,朋友們可以幫忙補充下。
?
至于空間數據庫的底層實現,最關鍵的部分依然是索引。常見的 空間索引 結構有 R 樹、Quadtree 等,這些結構可以對空間數據進行劃分、聚合和編碼,從而加速空間范圍的查詢處理。此外,空間數據庫涉及大量的空間分析算法,比如最近鄰查詢、空間關系查詢等。時間有限,不做展開說明了。
圖形數據庫
圖形數據庫是專門用于存儲和處理 圖形結構數據 的數據庫系統。
注意,這里的圖形可不是三角形、長方形,而是指 由節點和邊構成 的圖形結構。
比如我們要存儲一個朋友圈關系網(即 FoF:朋友的朋友),對應的圖形可能是:
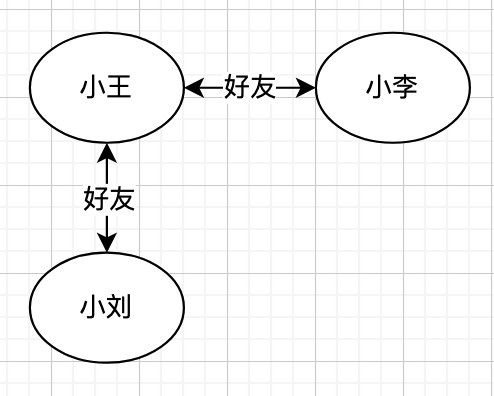
上圖中,每個用戶可以表示為一個節點,用戶之間的好友關系可以表示為邊。
在圖形數據庫中,需要 2 個表格來存儲。
節點信息表:
| 節點 id | 節點名 |
|---|---|
| 1 | 小王 |
| 2 | 小李 |
| 3 | 小劉 |
邊信息表:
| 邊 id | 邊類型 | 起始節點 | 結束節點 |
|---|---|---|---|
| 1 | 好友 | 1 | 2 |
| 2 | 好友 | 1 | 3 |
?
通過存儲這些節點和邊的信息,圖形數據庫就能實現快速 查詢及分析 朋友圈網中的用戶關系,并且挖掘出用戶的社交情況、和其他用戶的隱藏關系等。
由此,圖形數據庫非常適于構建社交網絡關系圖譜、推薦系統、知識圖譜等。
比較主流的圖形數據庫有 Neo4j、TigerGraph 等,都支持復雜的圖形操作和算法、以及分布式擴展,能夠通過并行計算加速圖形處理。
圖形數據庫的核心實現相信學過算法的朋友們并不陌生,主要是用了類似鄰接表、鄰接矩陣等方式實現節點和邊數據的存儲,并且通過構建圖形索引進行加速。
列存數據庫
這是一種 非常主流 的數據庫!區別于傳統的行式數據庫,列存數據庫以列作為基本的存儲單位,把每列的數據存儲在一起。
拿某公司每天的收入來舉個例子,傳統的行式(關系型)數據庫是這么存儲的:
| 日期 | 銷售額 | 成本 | 利潤 |
|---|---|---|---|
| 2022-01-01 | 500 | 600 | -100 |
| 2022-01-02 | 280 | 450 | -170 |
| 2022-01-03 | 290 | 480 | -190 |
而在列存數據庫中,底層大概是這么存儲的,相當于對矩陣做了一次轉置:
| 日期 | 2022-01-01 | 2022-01-02 | 2022-01-03 |
|---|---|---|---|
| 銷售額 | 500 | 280 | 290 |
| 成本 | 600 | 450 | 480 |
| 利潤 | -100 | -170 | -190 |
這樣一來,如果我們要統計這幾天公司的總利潤,不需要依次讀取每一行的數據,直接 讀取所需 的利潤那一列進行計算即可,從而提高了數據分析和聚合操作的效率。
此外,從計算機底層來分析,把相同類型的數據在同一列中連續存儲,可以實現更好的數據壓縮效果、節約空間。
因此,列存數據庫適用于實時數據分析、OLAP、大規模數據倉庫等場景。
比較主流的列存數據庫技術有 Apache HBase、ClickHouse、Druid 等,都是大數據方向同學的必修課。
ClickHouse 官方演示
多模數據庫
最后要講的數據庫也最特別,區別于上面所有存儲單一數據模型的數據庫,多模數據庫能夠 同時存儲處理多種不同類型的數據 ,比如關系型數據、文檔數據、圖形數據等,非常靈活。
就拿大家學編程時最常做的電商系統來舉例。如果沒有多模數據庫,你要用關系型數據庫來存儲商品簡略信息(比如商品名稱、價格),要用文檔數據庫來存儲可能長達幾十頁的商品詳情,要用圖數據庫來存儲商品推薦關系。每次看數據庫信息時,要分別到三個數據庫中查看。
如果使用多模數據庫,可以直接在同一個數據庫里統一存儲和管理不同類型的數據,非常方便。
此外,多模數據庫還支持事務,能夠更輕松地實現數據的一致性和完整性,不需要手動實現跨庫事務、跨庫數據同步等等。
比較常用的多模態數據庫技術有 ArangoDB、OrientDB 等,不過一般情況下,我們在開發中也很少會用到這種數據庫,感興趣的話再學習即可。
編輯:黃飛
?










 工商網監
工商網監
評論