 基于狀態的系統監測(CbM)方法及系統設計
基于狀態的系統監測(CbM)方法及系統設計
我們可以學著了解設備發出的正常聲音是什么樣的。當聲音出現變化時,我們可以確認出現異常。然后我們可以了解是什么問題,通過這樣的方式把聲音和特定的問題聯系在一起。識別異常可能需要進行幾分鐘的訓練,但將聲音、振動和原因結合起來實施診斷可能需要一輩子的時間。經驗豐富的技工人員和工程師可能具備這種知識,但他們屬于稀缺資源。單單通過聲音本身識別問題可能相當困難,即使使用錄音、描述性框架或接受專家親自培訓也是如此。
因此,ADI團隊在過去20年里一直致力于理解人類是如何解讀聲音和振動的。我們的目標是建立一個系統,能夠學習來自設備的聲音和振動,破譯它們的含義,以檢測異常行為,并進行診斷。本文詳細介紹了OtoSense的體系結構,它是一種設備健康監測系統,支持我們所說的計算機聽覺,讓計算機能夠理解設備行為的主要指標:聲音和振動。
該系統適用于任何設備,可以實時工作,無需網絡連接。它已被應用于工業應用,支持實現一個可擴展的高效設備健康監測系統。
本文探討了引導開發OtoSense的原則,以及在設計OtoSense期間,人類聽覺所發揮的作用。然后,本文討論了聲音或振動特性的是如何被設計出來的、如何從這些特性了解其代表的意義,以及在持續學習中如何不斷改變和改進OtoSense,用于執行愈加復雜的診斷,且結果更為精準。
指導原則為了保證耐用、不可知且高效,OtoSense設計理念秉持幾個指導原則:
-
從人類神經學中獲得靈感。人類可以以一種非常節能的方式學習和理解他們聽到的任何聲音。
-
能夠學習靜態聲音和瞬態聲音。這需要不斷調整功能和持續實施監測。
-
在靠近傳感器的終端進行識別。應該無需通過網絡連接遠程服務器來做出決策。
-
與專家互動,向他們學習,前提是盡可能避免干擾他們的日常工作,且過程要盡可能愉悅。
人類聽覺系統和對 OtoSense 的解析
聽覺是一種關乎生存的感覺。它是對遙遠的、看不見的事件的整體感覺,在出生前就已成熟
人類感知聲音的過程可以用四個熟悉的步驟來描述:聲音的模擬獲取、數字轉換、特征提取和解讀。在每個步驟中,我們都會將人耳與 OtoSense 系統比較。
-
模擬獲取和數字化。中耳中的膜和杠桿捕捉聲音,然后調整阻抗,將振動傳輸到充液腔道中,在那里,另一層膜會根據信號中存在的光譜成分選擇性地移位。這反過來彎曲了彈性單元,這些單元發出數字信號,反映出彎曲程度和強度。然后,這些單獨的信號通過按頻率排列的平行神經傳遞到初級聽覺皮層。
-
在 OtoSense 中,這項工作由傳感器、放大器和編解碼器來完成。數字化過程使用固定的采樣速率,可在 250 Hz 和 196kHz 之間調節,波形在 16 位編碼,然后存儲到大小在 128 到4096 之間的緩沖區。
-
-
特性提取發生在初級皮層:頻率域特性,如主頻率、諧波和頻譜形狀,以及時間域特性,如脈沖、強度變化和在大約 3 秒時間窗內的主要頻率成分。
-
OtoSense 使用一個時間窗,我們稱之為塊,它以固定的步長移動。這個塊的大小和步長范圍為 23 毫秒到 3 秒,具體由需要識別的事件和在終端提取特性的采樣率決定。在下一節中,我們會就 OtoSense 提取的特性進行更詳細地解釋。
-
-
解析發生在聯絡皮層,它融合了所有的感知和記憶,并賦予聲音以含義(比如通過語言),在塑造感知期間起著核心作用。解析過程會組織我們對事件的描述,遠遠不止是對它們進行命名這么簡單。為一個項目、一個聲音或一個事件命名可以讓我們賦予它更大、更多層的含義。對于專家來說,名字和含義能讓他們更好地理解周圍的環境。
-
這就是為什么 OtoSense 與人的互動始于基于人類神經學的視覺、無監督的聲音映射。OtoSense 利用圖形表示所有聽到的聲音或振動,它們按相似性排列,但不嘗試創建固定分類。這讓專家們能夠組織屏幕上顯示的組,并為它們命名,而無需嘗試人為創建有界線的類別。他們可以根據自身的知識、感知和對 OtoSense 最終輸出的期望構建語義地圖。對于同樣的音景,汽車機械師、航空工程師,或者冷鍛壓力機專家,甚至是研究相同領域,但來自不同公司的人員,都可以按不同的方式進行劃分、組織和標記。OtoSense則與塑造語言意義一樣,使用相同的自下而上的方法來給定意義。
-
經過一段時間(如之前所示,時間窗或塊),我們會給某個特征分配一個單獨的編號,用于描述該時間內聲音或振動的給定屬性/質量。OtoSense 平臺選擇特性的原則如下:
-
對于頻率域和時域,特征都應該盡可能完整地描述環境,供盡可能多的細節。它們必須描述靜止的嗡嗡聲,以及咔噠聲、嘩啦聲、吱吱聲和任何瞬間變化的聲音。
-
特征應盡可能按正交方式構成一個集合。如果一個特征被定義為“塊上的平均振幅”,那么就不應該有另一個特征與之高度相關,例如“塊上的總光譜能量”。當然,正交性可能永遠無法實現,但不應將任何一種表述為其他特征的組合,每種特征都必須包含單一信息。
-
特性應該最小化計算量。我們的大腦只知道加法、比較和重置為0。大多數OtoSense特性都被設計成增量,這樣每個新示例都可以通過簡單的操作修改特性,而不需要在完整的緩沖區,或者更為糟糕的,在塊上重新進行計算。最小化計算量還意味著可以忽略標準物理單元。例如,嘗試用值(以dBA為單位)表示強度是沒有意義的。如果需要輸出dBA值,則可以在輸出時完成(如果必要)。
在OtoSense平臺的2到1024個特性中,有一部分描述了時域。它們要么是直接從波形中提取,要么是從塊上任何其他特性的演化中提取。在這些特性中,有些包括平均振幅和最大振幅、由波形線性長度得到的復雜度、振幅變化、脈沖的存在與否和其特性、第一個和最后一個緩沖區之間相似性的穩定性、卷積的超小型自相關或主要頻譜峰值的變化。
在頻域上使用的特性提取自 FFT。FFT 在每個緩沖區上計算,產生從 128 到 2048 個單獨頻率的輸出。然后,該過程創建一個具 有所需維數的向量,該向量比FFT小得多,但仍能細致地描述環境。OtoSense最初使用一種不可知的方法在對數頻譜上創建大小相同的數據桶。然后,根據環境和要識別的事件,這些數據桶將重點放在信息密度高的頻譜區域,要么是從能夠熵最大化的無監督視角,要么是從使用標記事件作為指導的半監督視角來判斷。這模擬了我們的內耳細胞結構,在語言信息密度最大的地方,語音細節更密集。
結構:支持終端和本地數據OtoSense在終端位置實施異常檢測和事件識別,無需使用任何遠程設備。這種結構確保系統不會受到網絡故障的影響,且無需將所有原始數據塊發送出去進行分析。運行 OtoSense 的終端設備是一種自包含系統,可以實時描述所鑒聽設備的行為。
運行AI和HMI的OtoSense服務器一般托管在本地。云架構可以將多個有意義的數據流聚合成為OtoSense設備的輸出。對于一個專門處理大量數據并在一個站點上與數百臺設備交互的AI 來說,使用云托管的意義不大。
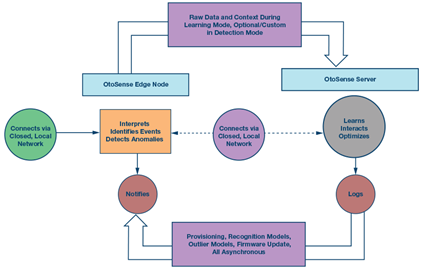
圖1. OtoSense 系統
從特性到異常檢測正常/異常評估無需與專家進行太多交互。專家只需要幫忙確定表示設備聲音和振動正常的基線。然后,在推送給設備之前,先將這個基線在 Otosense 服務器上轉換為異常模型。
然后,我們使用兩種不同的策略來評估傳入的聲音或振動是否正常:
-
第一種策略是我們所說的“常態性”,即檢查任何進入特性空間的新聲音的周圍環境、它與基線點和集群的距離,以及這些集群的大小。距離越大,集群越小,新的聲音就越不尋常,異常值也就越高。當這個異常值高于專家定義的閾值時,相應的塊將被標記為不尋常,并發送到服務器供專家查看。
-
第二種策略非常簡單:任何特性值高于或低于特性定義的基線的最大值或最小值的傳入塊都被標記為“極端”,并發送到服務器。
異常和極端策略的組合很好地涵蓋了異常的聲音或振動,這些策略在檢測日漸磨損和殘酷的意外事件方面也表現出色。
從特征到事件識別特征屬于物理領域,含義屬于人類認知。要將特征與含義聯系起來,需要OtoSenseAI和人類專家之間展開互動。我們花了大量時間研究客戶的反饋,開發出人機界面(HMI),讓工程師能夠高效地與OtoSense交互,設計出事件識別模型。這個HMI允許探索數據、標記數據、創建異常模型和聲音識別模型,并測試這些模型。
OtoSense Sound Platter(也稱為splatter)允許通過完整概述數據集來探索和標記聲音。Splatter在完整的數據集中選擇最有趣和最具代表性的聲音,并將它們顯示為一個混合了標記和未標記聲音的 2D 相似性地圖。
圖2. OtoSense Sound Platter 中的 2D splatter 聲音地圖。
任何聲音或振動,包括其環境,都可以通過許多不同的方式進行可視化——例如,使用 Sound Widget(也稱為 Swidget)。
圖3. OtoSense sound widget (swidget)。
在任何時候,都可以創建異常模型或事件識別模型。事件識別模型是一個圓形的混淆矩陣,它允許 OtoSense 用戶探索混淆事件。
圖4. 可以基于所需的事件創建事件識別模型
異常可以通過一個顯示所有異常和極端聲音的界面進行考察和標記。
圖5. 在 OtoSense 異常可視化界面中,聲音分析隨時間的變化。
持續學習過程—從異常檢測到日益復雜的診斷OtoSense 的設計初衷是向多位專家學習,并且隨著時間推移,進行越來越復雜的診斷。常見過程是 OtoSense 和專家之間的循環:
-
異常模型和事件識別模型都是在終端運行。這些模型為潛在事件發生的概率以及它們的異常值創建輸出。
-
超出定義閾值的異常聲音或振動會觸發異常通知。使用 OtoSense 的技術人員和工程師可以檢查該聲音和其前后聲音信息。
-
然后,這些專家會對這個異常事件進行標記。
-
對包含這些新信息的新識別模型和異常模型進行計算,并推送給終端設備。
ADI提供的OtoSense技術旨在使聲音和振動專業知識在任何設備上都持續可用,且無需連接網絡來執行異常檢測和事件識別。在航空航天、汽車和工業監測應用中,該技術被越來越多地用于設備健康監測,這表示,在曾經需要專業知識,以及涉及嵌入式應用的場景中,尤其是對于復雜設備而言,該技術都表現出了不錯的性能。
-
ADI
+關注
關注
146文章
45857瀏覽量
250971 -
深度學習
+關注
關注
73文章
5510瀏覽量
121345
原文標題:聽懂聲音——ADI人工智能如何大幅延長設備的正常運行時間?
文章出處:【微信號:analog_devices,微信公眾號:analog_devices】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CBM3085AS
CBM803L
CBM803L
01-07-06-CBM8655_CBM8656精密運算放大器

CBM8047
CBM811-3T

電梯運行狀態監測系統:關鍵信息監測與安全高效運行新保障
工業設備狀態在線監測系統物聯網解決方案
電氣設備的絕緣在線監測與狀態維修探究





 工商網監
工商網監
評論