 基于Haar和HoG特征的前車檢測方法深度解讀
基于Haar和HoG特征的前車檢測方法深度解讀
Adaboost是一種迭代算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),然后把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。
一 Boosting 算法的起源
boost 算法系列的起源來自于PAC Learnability(PAC 可學習性)。這套理論主要研究的是什么時候一個問題是可被學習的,當然也會探討針對可學習的問題的具體的學習算法。這套理論是由Valiant提出來的,也因此(還有其他貢獻哈)他獲得了2010年的圖靈獎。
PAC 定義了學習算法的強弱
弱學習算法---識別錯誤率小于1/2(即準確率僅比隨機猜測略高的學習算法)
強學習算法---識別準確率很高并能在多項式時間內完成的學習算法
同時 ,Valiant和 Kearns首次提出了 PAC學習模型中弱學習算法和強學習算法的等價性問題,即任意給定僅比隨機猜測略好的弱學習算法 ,是否可以將其提升為強學習算法 ? 如果二者等價 ,那么只需找到一個比隨機猜測略好的弱學習算法就可以將其提升為強學習算法 ,而不必尋找很難獲得的強學習算法。 也就是這種猜測,讓無數牛人去設計算法來驗證PAC理論的正確性。
不過很長一段時間都沒有一個切實可行的辦法來實現這個理想。細節決定成敗,再好的理論也需要有效的算法來執行。終于功夫不負有心人, Schapire在1996年提出一個有效的算法真正實現了這個夙愿,它的名字叫AdaBoost。AdaBoost把多個不同的決策樹用一種非隨機的方式組合起來,表現出驚人的性能!
第一,把決策樹的準確率大大提高,可以與SVM媲美。
第二,速度快,且基本不用調參數。
第三,幾乎不Overfitting。我估計當時Breiman和Friedman肯定高興壞了,因為眼看著他們提出的CART正在被SVM比下去的時候,AdaBoost讓決策樹起死回生!Breiman情不自禁地在他的論文里贊揚AdaBoost是最好的現貨方法(off-the-shelf,即“拿下了就可以用”的意思)。(這段話摘自統計學習那些事)
二 Boosting算法的發展歷史
Boosting算法是一種把若干個分類器整合為一個分類器的方法,在boosting算法產生之前,還出現過兩種比較重要的將多個分類器整合 為一個分類器的方法,即boostrapping方法和bagging方法。我們先簡要介紹一下bootstrapping方法和bagging方法。
1)bootstrapping方法的主要過程
主要步驟:
i)重復地從一個樣本集合D中采樣n個樣本
ii)針對每次采樣的子樣本集,進行統計學習,獲得假設Hi
iii)將若干個假設進行組合,形成最終的假設Hfinal
iv)將最終的假設用于具體的分類任務
2)bagging方法的主要過程 -----bagging可以有多種抽取方法
主要思路:
i)訓練分類器
從整體樣本集合中,抽樣n* < N個樣本 針對抽樣的集合訓練分類器Ci
ii)分類器進行投票,最終的結果是分類器投票的優勝結果
但是,上述這兩種方法,都只是將分類器進行簡單的組合,實際上,并沒有發揮出分類器組合的威力來。直到1989年,Yoav Freund與 Robert Schapire提出了一種可行的將弱分類器組合為強分類器的方法。并由此而獲得了2003年的哥德爾獎(Godel price)。
Schapire還提出了一種早期的boosting算法,其主要過程如下:
i)從樣本整體集合D中,不放回的隨機抽樣n1 < n個樣本,得到集合 D1
訓練弱分類器C1
ii)從樣本整體集合D中,抽取 n2 < n個樣本,其中合并進一半被C1 分類錯誤的樣本。得到樣本集合D2
訓練弱分類器C2
iii)抽取D樣本集合中,C1 和 C2 分類不一致樣本,組成D3
訓練弱分類器C3
iv)用三個分類器做投票,得到最后分類結果
到了1995年,Freund and schapire提出了現在的adaboost算法,其主要框架可以描述為:
i)循環迭代多次
更新樣本分布
尋找當前分布下的最優弱分類器
計算弱分類器誤差率
ii)聚合多次訓練的弱分類器
三 Adaboost 算法
AdaBoost 是一種迭代算法,其核心思想是針對同一個訓練集訓練不同的分類器,即弱分類器,然后把這些弱分類器集合起來,構造一個更強的最終分類器。(很多博客里說的三個臭皮匠賽過諸葛亮)
算法本身是改變數據分布實現的,它根據每次訓練集之中的每個樣本的分類是否正確,以及上次的總體分類的準確率,來確定每個樣本的權值。將修改權值的新數據送給下層分類器進行訓練,然后將每次訓練得到的分類器融合起來,作為最后的決策分類器。
完整的adaboost算法如下

簡單來說,Adaboost有很多優點:
1)adaboost是一種有很高精度的分類器
2)可以使用各種方法構建子分類器,adaboost算法提供的是框架
3)當使用簡單分類器時,計算出的結果是可以理解的。而且弱分類器構造極其簡單
4)簡單,不用做特征篩選
5)不用擔心overfitting!
四 Adaboost 舉例
也許你看了上面的介紹或許還是對adaboost算法云里霧里的,沒關系,百度大牛舉了一個很簡單的例子,你看了就會對這個算法整體上很清晰了。
下面我們舉一個簡單的例子來看看adaboost的實現過程:
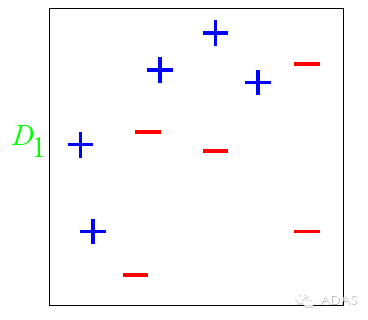
圖中,“+”和“-”分別表示兩種類別,在這個過程中,我們使用水平或者垂直的直線作為分類器,來進行分類。
第一步:

根據分類的正確率,得到一個新的樣本分布D2-,一個子分類器h1
其中劃圈的樣本表示被分錯的。在右邊的途中,比較大的“+”表示對該樣本做了加權。
也許你對上面的?1,ɑ1怎么算的也不是很理解。下面我們算一下,不要嫌我啰嗦,我最開始就是這樣思考的,只有自己把算法演算一遍,你才會真正的懂這個算法的核心,后面我會再次提到這個。
算法最開始給了一個均勻分布 D 。所以h1 里的每個點的值是0.1。ok,當劃分后,有三個點劃分錯了,根據算法誤差表達式
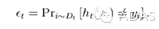
得到 誤差為分錯了的三個點的值之和,所以?1=(0.1+0.1+0.1)=0.3,而ɑ1 根據表達式的可以算出來為0.42. 然后就根據算法 把分錯的點權值變大。如此迭代,最終完成adaboost算法。
第二步:

根據分類的正確率,得到一個新的樣本分布D3,一個子分類器h2
第三步:
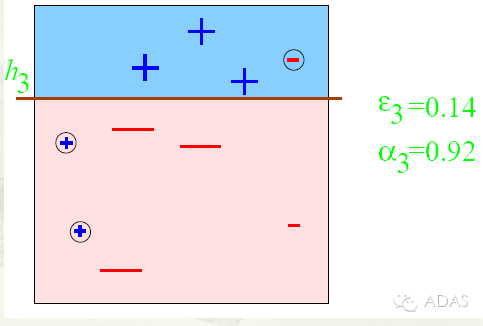
得到一個子分類器h3
整合所有子分類器:
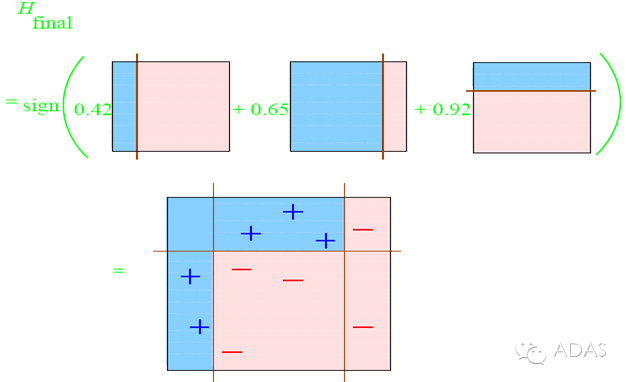
因此可以得到整合的結果,從結果中看,及時簡單的分類器,組合起來也能獲得很好的分類效果,在例子中所有的。
五 Adaboost 疑惑和思考
到這里,也許你已經對adaboost算法有了大致的理解。但是也許你會有個問題,為什么每次迭代都要把分錯的點的權值變大呢?這樣有什么好處呢?不這樣不行嗎? 這就是我當時的想法,為什么呢?我看了好幾篇介紹adaboost 的博客,都沒有解答我的疑惑,也許大牛認為太簡單了,不值一提,或者他們并沒有意識到這個問題而一筆帶過了。然后我仔細一想,也許提高錯誤點可以讓后面的分類器權值更高。然后看了adaboost算法,和我最初的想法很接近,但不全是。 注意到算法最后的表達式為
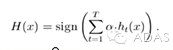
,這里面的a 表示的權值,是由
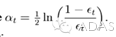
得到的。而a是關于誤差的表達式,到這里就可以得到比較清晰的答案了,所有的一切都指向了誤差。提高錯誤點的權值,當下一次分類器再次分錯了這些點之后,會提高整體的錯誤率,這樣就導致 a 變的很小,最終導致這個分類器在整個混合分類器的權值變低。也就是說,這個算法讓優秀的分類器占整體的權值更高,而挫的分類器權值更低。這個就很符合常理了。到此,我認為對adaboost已經有了一個透徹的理解了。
六 總結
最后,我們可以總結下adaboost算法的一些實際可以使用的場景:
1)用于二分類或多分類的應用場景
2)用于做分類任務的baseline
無腦化,簡單,不會overfitting,不用調分類器
3)用于特征選擇(feature selection)
4)Boosting框架用于對badcase的修正
只需要增加新的分類器,不需要變動原有分類器
由于adaboost算法是一種實現簡單,應用也很簡單的算法。Adaboost算法通過組合弱分類器而得到強分類器,同時具有分類錯誤率上界隨著訓練增加而穩定下降,不會過擬合等的性質,應該說是一種很適合于在各種分類場景下應用的算法。
-
分類器
+關注
關注
0文章
152瀏覽量
13183 -
學習算法
+關注
關注
0文章
15瀏覽量
7469 -
檢測方法
+關注
關注
0文章
50瀏覽量
9782
發布評論請先 登錄
相關推薦
一種基于Haar小波變換的彩色圖像人臉檢測方法

基于HOG的快速人體檢測方法

關于HoG算法的介紹
HOG特征提取算法并行加速
圖像識別中人體檢測的HOG特征提取方法解析
HOG特征以及提取算法的實現過程

一種新的目標分類特征深度學習模型
人工智能汽車的前車檢測介紹






 工商網監
工商網監
評論