 關于AI芯片的新動向分析和應用
關于AI芯片的新動向分析和應用
在人工智能(AI)領域,由于具有先天技術和應用優勢,英偉達和谷歌幾乎占據了AI處理器領域80%的市場份額,其他廠商,如英特爾、特斯拉、ARM、IBM以及Cadence等,也在人工智能處理器領域占有一席之地。最近幾年,我國國內也涌現出了一批AI芯片公司,如地平線、深鑒科技、中科寒武紀等。
從應用場景看,AI芯片主要有兩類,一是部署在以數據中心為代表的云端,其特點是高性能,功耗隨之也偏高;另一個是部署在消費級和物聯網的終端,其最大特點就是低功耗。
目前,AI芯片的大規模應用場景主要還是在云端。在云端,互聯網巨頭已經成為了事實上的生態主導者,因為云計算本來就是巨頭的戰場,現在所有開源AI框架也都是這些巨頭發布的。在這樣一個生態已經固化的環境中,留給創業公司的空間實際已經消失。
而在終端上,由于還沒有一統天下的事實標準,芯片廠商可以八仙過海各顯神通。目前,AI芯片在終端的應用場景主要還是手機,各大手機處理器廠商都在打AI牌,生怕錯過了熱點。
而隨著5G和物聯網的成熟,廣闊的市場空間,為終端側的AI芯片應用提供了巨大的機遇,而由于物聯網終端數量巨大,應用場景繁多,而所有終端幾乎都有一個共同的需求和特點,那就是低功耗,從而使其能長時間的穩定工作,不需要人為干預和維護,以降低運營維護成本。
云端AI芯片已經被各大巨頭把控,而終端側又有著巨大的發展空間,這使得產學研各界的眾多企業和科研機構在最近兩年紛紛投入人力和財力,進行低功耗AI芯片的研發,以期在競爭中占得先機。
VLSI 2018上的中國風
前些天,在美國檀香山召開的2018 國際超大規模集成電路研討會(2018 Symposia on VLSI Technology and Circuits,簡稱 VLSI)上,我國清華大學Thinker團隊發表了兩款極低功耗AI 芯片(Thinker-II 和 Thinker-S)的相關論文,以及一種支持多種稀疏度網絡和線上可調節功能的人工神經網絡處理器STICKER。
之所以推出以上3款AI芯片,主要基于以下行業背景和需求:深度學習的突破性發展帶動了機器視覺、語音識別以及自然語言處理等領域的進步,然而,由于深度神經網絡巨大的存儲開銷和計算需求,功耗成為 Deploy AI Everywhere 的主要障礙,人工智能算法在移動設備、可穿戴設備和 IoT 設備中的廣泛應用受到了制約。
為克服上述瓶頸,清華大學 Thinker 團隊對神經網絡低位寬量化方法、計算架構和電路實現進行了系統研究,提出了支持低位寬網絡高能效計算的可重構架構,設計了神經網絡通用計算芯片Thinker-II和語音識別芯片Thinker-S。Thinker-II 芯片運行在 200MHz 時,其功耗僅為10mW;Thinker-S芯片的最低功耗為141微瓦,其峰值能效達到90TOPs/W。這兩款芯片有望在電池供電設備和自供能IoT設備中廣泛應用。
Thinker-S
Thinker-S中設計了一種基于二值卷積神經網絡和用戶自適應的語音識別框架,同時利用語音信號處理的特點,提出了時域數據復用、近似計算和權值規整化等優化技術,大幅度優化了神經網絡推理計算。Thinker-S 芯片采用 28nm 工藝,單次推理計算中每個神經元上消耗的能量最低僅為 2.46 皮焦。
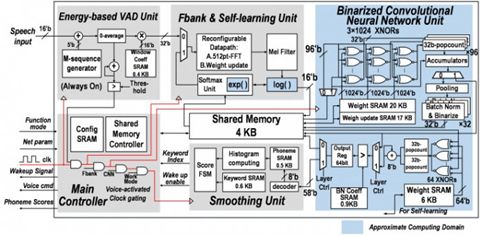
圖:Thinker-S 芯片架構
Thinker-Ⅱ
該芯片中設計了兩種二值/三值卷積優化計算方法及硬件架構,大幅降低了算法復雜度、有效去除了冗余計算。此外,針對由稀疏化帶來的負載不均衡問題,設計了層次化均衡調度機制,通過軟硬件協同的兩級任務調度,有效提升了資源利用率。Thinker-II 芯片采用 28nm 工藝,通過架構和電路級重構,支持神經網絡通用計算。
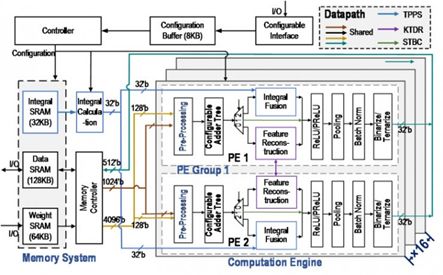
圖:Thinker-II 芯片架構
STICKER神經網絡加速器
通過動態配置人工智能芯片的運算和存儲電路,實現了對不同稀疏度神經網絡的自適應處理,大幅提升了人工智能加速芯片的能量效率。該論文作為人工智能處理器分會場的首篇論文,得到了本屆VLSI技術委員會的高度認可,一同入選的論文還包含了IBM, Intel, Renesas等公司的相關工作。
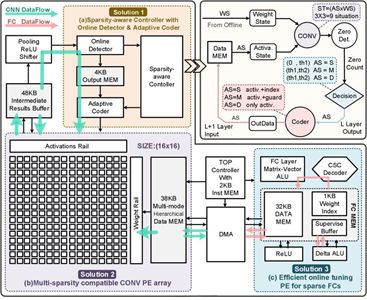
圖:STICKER神經網絡加速器硬件架構
據悉,STICKER是世界首款全面支持不同稀疏程度網絡,且同時支持片上網絡參數微調的神經網絡加速芯片。通過片上自適應編碼器、多模態計算單元以及多組相連存儲架構技術,實現了針對不同稀疏程度神經網絡的動態高效處理,大幅提升能量效率,并減少芯片面積。針對傳統神經網絡加速器無法片上調整網絡參數以適應物聯網應用場景中目標及環境多變的問題,首次使用了片上微調稀疏神經網絡參數的技術,以極低的開銷實現片上神經網絡參數的自適應調整。相比于傳統加速器,該工作極限能效高達62.1 TOPS/W(為目前有報道的8bit人工智能處理器的最高值)。

圖:Sticker芯片照片
KAIST的DNPU
韓國科學技術院KAIST的Dongjoo Shin等人在ISSCC 2017上提出了一個針對CNN和RNN結構可配置的加速器單元DNPU,除了包含一個RISC核之外,還包括了一個針對卷積層操作的計算陣列CP和一個針對全連接層RNN-LSTM操作的計算陣列FRP,DNPU支持CNN和RNN結構,能效比高達8.1TOPS/W。該芯片采用了65nm CMOS工藝。
ENVISION
比利時魯汶大學的Bert Moons等在2017年IEEE ISSCC上提出了能效比高達10.0TOPs/W的、針對卷積神經網絡加速的芯片ENVISION,該芯片采用28nm FD-SOI技術,包括一個16位的RISC處理器核,1D-SIMD處理單元進行ReLU和Pooling操作,2D-SIMD MAC陣列處理卷積層和全連接層的操作,還有128KB的片上存儲器。
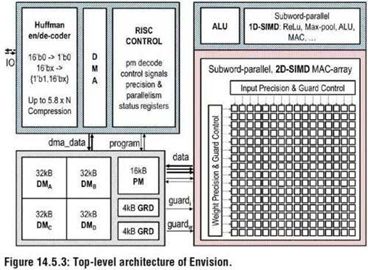
SCALLDEEP
普渡大學的Venkataramani S等人在計算機體系結構頂級會議ISCA 2017上提出了針對大規模神經網絡訓練的人工智能處理器SCALLDEEP。
該論文針對深度神經網絡的訓練部分進行針對性優化,提出了一個可擴展服務器架構,且深入分析了深度神經網絡中卷積層,采樣層,全連接層等在計算密集度和訪存密集度方面的不同,設計了兩種處理器core架構,計算密集型的任務放在了comHeavy核中,包含大量的2D乘法器和累加器部件,而對于訪存密集型任務則放在了memHeavy核中,包含大量SPM存儲器和tracker同步單元,既可以作為存儲單元使用,又可以進行計算操作,包括ReLU,tanh等。
論文作者針對深度神經網絡設計了編譯器,完成網絡映射和代碼生成,同時設計了設計空間探索的模擬器平臺,可以進行性能和功耗的評估,性能則得益于時鐘精確級的模擬器,功耗評估則從DC中提取模塊的網表級的參數模型。該芯片采用了Intel 14nm工藝進行了綜合和性能評估,峰值能效比高達485.7GOPS/W。
Myriad X
英特爾為了加強在人工智能芯片領域的實力,收購了機器視覺公司Movidius。
Movidius在2017年推出了Myriad X,這是一款視覺處理器(VPU,visionprocessing unit),是一款低功耗的SoC,用于在基于視覺的設備上加速深度學習和人工智能——如無人機、智能相機和VR / AR頭盔。

Myriad X是全球第一個配備專用神經網絡計算引擎的片上系統芯片(SoC),用于加速設備端的深度學習推理計算。該神經網絡計算引擎是芯片上集成的硬件模塊,專為高速、低功耗且不犧牲精確度地運行基于深度學習的神經網絡而設計,讓設備能夠實時地看到、理解和響應周圍環境。引入該神經計算引擎之后,Myriad X架構能夠為基于深度學習的神經網絡推理提供1TOPS的計算性能。
百花齊放
一些傳統AI服務廠商將自己的服務進行垂直拓展,比如的自然語音處理廠商云知聲從自己的傳統語音業務出發,開發了UniOne語音AI芯片,用于物聯網IoT設備。
相對于語音市場,安防更是一個AI芯片扎堆的大產業,如果可以將自己的芯片置入攝像頭,是一個不錯的場景,也是很好的生意。包括云天勵飛、海康威視等廠商都在大力開發安防領域的AI嵌入式芯片,而且已經完成了一定的商業化部署。
AI芯片發展趨勢
在計算機體系結構頂級會議ISSCC 2018,“Digital Systems: Digital Architectures and Systems”分論壇主席Byeong-GyuNam對AI芯片,特別是深度學習芯片的發展趨勢做了概括,去年,大多數論文都在討論卷積神經網絡的實現問題,今年則更加關注兩個問題:一,如果更高效地實現卷積神經網絡,特別是針對手持終端等設備;二,關于全連接的非卷積神經網絡,如RNN和LSTM。
為了獲得更高的能效比,越來越多的研究者把精力放在了低精度神經網絡的設計和實現上,如1bit的神經網絡。這些新技術使深度學習加速器的能效比從去年的幾十TOPS/W提升到了今年的上百TOPS/W。有些研究者也對數字+模擬的混合信號處理實現方案進行了研究。對數據存取具有較高要求的全連接網絡,有些研究者則借助3D封裝技術來獲得更好的性能。
總之,AI芯片在終端側的發展潛力巨大,且應用場景眾多,品類也多,這就更適合眾多初創的、中小規模AI芯片企業的胃口。相信隨著5G和物聯網的大面積鋪開,低功耗AI芯片將是未來的主要發展方向,只要相關標準能夠確定,則商機無限。
-
處理器
+關注
關注
68文章
19375瀏覽量
230441 -
人工智能
+關注
關注
1792文章
47482瀏覽量
239162 -
AI芯片
+關注
關注
17文章
1898瀏覽量
35121
發布評論請先 登錄
相關推薦
從2014中國(成都)電子展看測試測量行業新動向
從IIC-China管窺電子制造與測試測量新動向
電池韓國KC認證法規新動向
技術新動向微生物細菌驅動的電池!
梳理了部分企業籌劃2018年新能源汽車的最新動向

數字服貿 智啟未來 服貿會透露高水平開放新動向

國內無線產品核準法規新動向






 工商網監
工商網監
評論