 關于如何使用MATLAB 深度學習進行語義分割的方法詳解
關于如何使用MATLAB 深度學習進行語義分割的方法詳解
這篇文章展示了一個具體的文檔示例,演示如何使用深度學習和 Computer Vision System Toolbox 訓練語義分割網絡。
語義分割網絡對圖像中的每個像素進行分類,從而生成按類分割的圖像。語義分割的應用包括用于自動駕駛的道路分割和醫學診斷中的癌細胞分割。
如需了解更多文檔示例和詳細信息,建議查閱技術文檔:https://cn.mathworks.com/help
為了說明訓練過程,本示例將訓練 SegNet,一種用于圖像語義分割的卷積神經網絡 (CNN)。用于語義分割的其他類型網絡包括全卷積網絡 (FCN) 和 U-Net。以下所示訓練過程也可應用于這些網絡。
本示例使用來自劍橋大學的CamVid 數據集展開訓練。此數據集是包含駕駛時所獲得的街道級視圖的圖像集合。該數據集為 32 種語義類提供了像素級標簽,包括車輛、行人和道路。
建立
本示例創建了 SegNet 網絡,其權重從 VGG-16 網絡初始化。要獲取 VGG-16,請安裝Neural Network Toolbox Model for VGG-16 Network:
安裝完成后,運行以下代碼以驗證是否安裝正確。
vgg16();
此外,請下載預訓練版 SegNet。預訓練模型可支持您運行整個示例,而無需等待訓練完成。
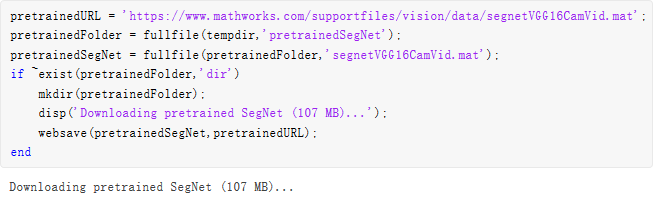
強烈建議采用計算能力為 3.0 或更高級別,支持 CUDA 的 NVIDIA GPU 來運行本示例。使用 GPU 需要 Parallel Computing Toolbox。
下載 CamVid 數據集
從以下 URL 中下載 CamVid 數據集。
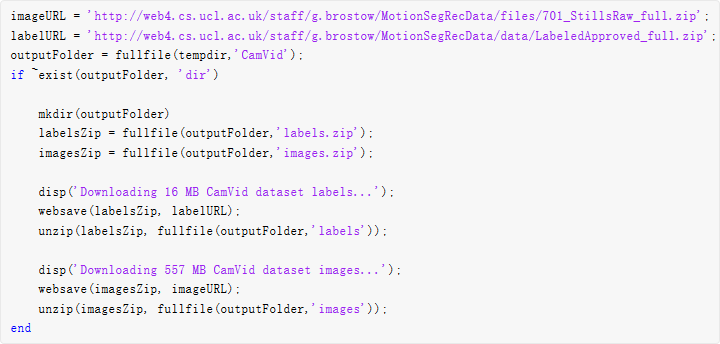
注意:數據下載時間取決于您的 Internet 連接情況。在下載完成之前,上面使用的命令會阻止訪問 MATLAB。或者,您可以使用 Web 瀏覽器先將數據集下載到本地磁盤。要使用從 Web 中下載的文件,請將上述 outputFolder 變量更改為下載文件的位置。
加載 CamVid 圖像
用于加載 CamVid 圖像。借助 imageDatastore,可以高效地加載磁盤上的大量圖像數據。
imgDir = fullfile(outputFolder,'images','701_StillsRaw_full');imds = imageDatastore(imgDir);
顯示其中一個圖像。
I = readimage(imds,1);I = histeq(I);imshow(I)
加載 CamVid 像素標簽圖像
使用imageDatastore加載 CamVid 像素標簽圖像。pixelLabelDatastore 將像素標簽數據和標簽 ID 封裝到類名映射中。
按照 SegNet 原創論文(Badrinarayanan、Vijay、Alex Kendall 和 Roberto Cipolla:《SegNet:用于圖像分割的一種深度卷積編碼器-解碼器架構》(SegNet: A Deep Convolutional Encoder-Decoder Architecture for ImageSegmentation)。arXiv 預印本:1511.00561,201)中采用的步驟進行操作,將 CamVid 中的 32 個原始類分組為 11 個類。指定這些類。
classes = [ "Sky" "Building" "Pole" "Road" "Pavement" "Tree" "SignSymbol" "Fence" "Car" "Pedestrian" "Bicyclist" ];
要將 32 個類減少為 11 個,請將原始數據集中的多個類組合在一起。例如,“Car” 是 “Car” 、 “SUVPickupTruck” 、 “Truck_Bus” 、 “Train” 和 “OtherMoving” 的組合。使用支持函數 camvidPixelLabelIDs 返回已分組的標簽 ID,該函數會在本示例的末尾列出。
labelIDs = camvidPixelLabelIDs();
使用這些類和標簽 ID 創建 pixelLabelDatastore。
labelDir = fullfile(outputFolder,'labels');pxds = pixelLabelDatastore(labelDir,classes,labelIDs);
讀取并在一幅圖像上疊加顯示像素標簽圖像。
C = readimage(pxds,1);cmap = camvidColorMap;B = labeloverlay(I,C,'ColorMap',cmap);imshow(B)pixelLabelColorbar(cmap,classes);
沒有顏色疊加的區域沒有像素標簽,在訓練期間不會使用這些區域。
分析數據集統計信息
要查看 CamVid 數據集中類標簽的分布情況,請使用countEachLabel。此函數會按類標簽計算像素數。
tbl = countEachLabel(pxds)
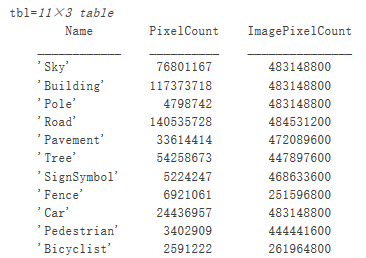
按類可視化像素計數。
frequency = tbl.PixelCount/sum(tbl.PixelCount);bar(1:numel(classes),frequency)xticks(1:numel(classes)) xticklabels(tbl.Name)xtickangle(45)ylabel('Frequency')
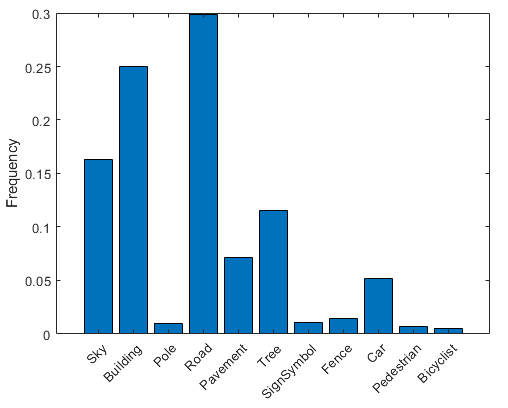
理想情況下,所有類都有相同數量的觀察結果。但是,CamVid 中的這些類比例失衡,這是街道場景汽車數據集中的常見問題。由于天空、建筑物和道路覆蓋了圖像中的更多區域,因此相比行人和騎自行車者像素,這些場景擁有更多的天空、建筑物和道路像素。如果處理不當,這種失衡可能影響學習過程,因為學習過程偏向主導類。在本示例中,您稍后將使用類權重來處理此問題。
調整 CamVid 數據的大小
CamVid 數據集中的圖像大小為 720 x 960。要減少訓練時間和內存使用量,請將圖像和像素標記圖像的大小調整為 360 x 480。resizeCamVidImages 和 resizeCamVidPixelLabels 是本示例末尾所列出的支持函數。

準備訓練集和測試集
使用數據集中 60% 的圖像訓練 SegNet。其余圖像用于測試。以下代碼會將圖像和像素標記數據隨機分成訓練集和測試集。
[imdsTrain,imdsTest,pxdsTrain,pxdsTest] = partitionCamVidData(imds,pxds);
60/40 拆分會生產以下數量的訓練圖像和測試圖像:
numTrainingImages = numel(imdsTrain.Files)
numTrainingImages = 421
numTestingImages = numel(imdsTest.Files)
numTestingImages = 280
創建網絡
使用segnetLayers創建利用 VGG-16 權重初始化的 SegNet 網絡。segnetLayers 會自動執行傳輸 VGG-16 中的權重所需的網絡操作,并添加語義分割所需其他網絡層。
imageSize = [360 480 3];numClasses = numel(classes);lgraph = segnetLayers(imageSize,numClasses,'vgg16');
根據數據集中圖像的大小選擇圖像大小。根據 CamVid 中的類選擇類的數量。
使用類權重平衡類
如前所示,CamVid 中的這些類比例失衡。要改進訓練情況,可以使用類權重來平衡這些類。使用之前通過countEachLayer計算的像素標簽計數,并計算中值頻率類權重。
imageFreq = tbl.PixelCount ./ tbl.ImagePixelCount;classWeights = median(imageFreq) ./ imageFreq

使用pixelClassificationLayer指定類權重。
pxLayer = pixelClassificationLayer('Name','labels','ClassNames',tbl.Name,'ClassWeights',classWeights)

通過刪除當前 pixelClassificationLayer 并添加新層,使用新的 pixelClassificationLayer 更新 SegNet 網絡。當前 pixelClassificationLayer 名為“pixelLabels”。使用removeLayers刪除該層,使用addLayers添加新層,然后使用connectLayers將新層連接到網絡的其余部分。

選擇訓練選項
用于訓練的優化算法是引入動量的隨機梯度下降 (SGDM) 算法。使用trainingOptions指定用于 SGDM 的超參數。

大小為 4 的 minimatch 用于減少訓練時的內存使用量。您可以根據系統中的 GPU 內存量增加或減少此值。
數據擴充
在訓練期間使用數據擴充向網絡提供更多示例,以便提高網絡的準確性。此處,隨機左/右反射以及 +/- 10 像素的隨機 X/Y 平移用于數據擴充。用于指定這些數據擴充參數。

imageDataAugmenter 支持其他幾種類型的數據擴充。選擇它們需要經驗分析,并且這是另一個層次的超參數調整。
開始訓練
使用pixelLabelImageDatastore組合訓練數據和數據擴充選擇。pixelLabelImageDatastore 會讀取批量訓練數據,應用數據擴充,并將已擴充的數據發送至訓練算法。

如果 doTraining 標志為 true,則會開始訓練。否則,會加載預訓練網絡。注意:NVIDIA Titan X 上的訓練大約需要 5 個小時,根據您的 GPU 硬件具體情況,可能會需要更長的時間。

在圖像上測試網絡
作為快速完整性檢查,將在測試圖像上運行已訓練的網絡。
I = read(imdsTest);C = semanticseg(I, net);
顯示結果。

將 C 中的結果與 pxdsTest 中的預期真值進行比較。綠色和洋紅色區域突出顯示了分割結果與預期真值不同的區域。
expectedResult = read(pxdsTest);actual = uint8(C);expected = uint8(expectedResult);imshowpair(actual, expected)
從視覺上看,道路、天空、建筑物等類的語義分割結果重疊情況良好。然而,行人和車輛等較小的對象則不那么準確。可以使用交叉聯合 (IoU) 指標(又稱 Jaccard 系數)來測量每個類的重疊量。使用jaccard函數測量 IoU。
iou = jaccard(C, expectedResult);table(classes,iou)
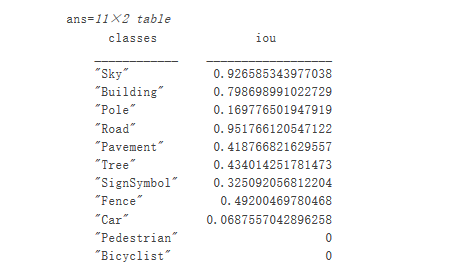
IoU 指標可確認視覺效果。道路、天空和建筑物類具有較高的 IoU 分數,而行人和車輛等類的分數較低。其他常見的分割指標包括Dice 系數和Boundary-F1輪廓匹配分數。
評估已訓練的網絡
要測量多個測試圖像的準確性,請在整個測試集中運行semanticseg。
pxdsResults = semanticseg(imdsTest,net,'MiniBatchSize',4,'WriteLocation',tempdir,'Verbose',false);
semanticseg 會將測試集的結果作為 pixelLabelDatastore 對象返回。imdsTest 中每個測試圖像的實際像素標簽數據會在“WriteLocation”參數指定的位置寫入磁盤。使用evaluateSemanticSegmentation測量測試集結果的語義分割指標。
metrics = evaluateSemanticSegmentation(pxdsResults,pxdsTest,'Verbose',false);
evaluateSemanticSegmentation返回整個數據集、各個類以及每個測試圖像的各種指標。要查看數據集級別指標,請檢查 metrics.DataSetMetrics。
metrics.DataSetMetrics

數據集指標可提供網絡性能的高級概述。要查看每個類對整體性能的影響,請使用 metrics.ClassMetrics 檢查每個類的指標。
metrics.ClassMetrics
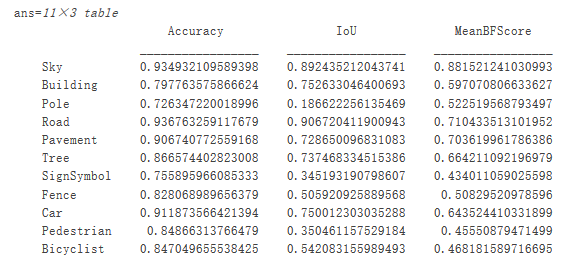
盡管數據集整體性能非常高,但類指標顯示,諸如 Pedestrian、Bicyclist 和 Car 等代表性不足的類分割效果不如Road、Sky 和 Building 等類。附加數據多一些代表性不足類樣本可能會提升分割效果。
-
網絡
+關注
關注
14文章
7589瀏覽量
89028 -
深度學習
+關注
關注
73文章
5511瀏覽量
121355
發布評論請先 登錄
相關推薦

AI大模型與深度學習的關系
語義分割25種損失函數綜述和展望

圖像分割和語義分割的區別與聯系
利用Matlab函數實現深度學習算法
基于Python的深度學習人臉識別方法
機器學習中的數據分割方法
深度學習中的時間序列分類方法
圖像分割與語義分割中的CNN模型綜述
深度學習中的無監督學習方法綜述
深度學習的模型優化與調試方法
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論