 關于自動生成高效的代碼的方法分析和分享
關于自動生成高效的代碼的方法分析和分享
代碼生成作為一個普遍存在的成熟技術,已經被國內外很多知名企業采用,并將生成的代碼直接部署在產品中。這些客戶普遍反應,代碼生成的確很大幅度地提高產品開發的效率,縮短產品開發周期。
雖然已有很多代碼生成技術的成功案例,產生的代碼效率仍是新用戶普遍關心的問題(可能是最關心的問題)。
在 2018 MATLAB EXPO 用戶大會上,三位資深的 MathWorks 技術專家受邀跟大家聊聊代碼生成那些事,通過多個具體實例,詳細解釋用戶在使用 MATLAB/Simulink 代碼生成技術中遇到的問題和困惑。
產生出來的代碼效率能行嗎?
首先,好的模型能產生出好的代碼。
根據很多用戶反饋,在大部分情況下,生成的代碼的運行速度和手寫代碼差不多,使用的資源要比手寫明顯的小。然而,如果直接采用默認的選項直接進行代碼生成而不對模型進行任何準備工作,生成的代碼效率將無法滿足預期。
產生出來的代碼的效率是和搭建的 Simulink 模型與 MATLAB 代碼直接相關。這句話不難理解——好的模型能產生出好的代碼。可是什么是好的模型呢?
以 HDL 代碼生成為例:用戶在 Simulink 里很快的搭建好算法模型,確認數值結果正確就開始產生 HDL 代碼,卻發現效率并不理想。這是因為在算法模型里沒有任何架構的優化,也沒有時序的信息(比如節拍寄存器)。其實只要在模型里正確的地方加入幾個寄存器,產生出來的代碼效率就會提高了。
其次,提高生成代碼的效率還需要利用產品提供的優化功能,按照自己的需求設置優化參數。
默認參數設置是為了讓大家能夠最快、最容易的產生代碼,而不是適用于所有場景下的最優設置,最優的設計一定是結合具體的問題的設置。
例如,有些硬件工程師使用默認設置產生出的 HDL 代碼占用的資源很的要求很高,不能滿足要求。問題關鍵在于沒有使用 HDL Coder 中提供的優化功能,比如資源復用流處理等。這些功能可以幫用戶找到模型中可復用的資源,根據用戶的設置,自動優化使用的資源。
此外,生成代碼的時候不僅要對使用資源進行優化,建議用戶使用HDLCoder 對主頻進行優化并對代碼定制。要對具體的要求采用不同的優化手段,才能產生出最優的代碼。
第三,混合使用手寫代碼和自動產生的代碼。
很多用戶有一些誤解,認為代碼生成必須全部采用自動的方法,其實,代碼生成手段并沒有這些限制,反而會帶來不必要的負擔。
如果在算法中的某個模塊已經有很成熟的代碼,用戶可以結合自動產生的代碼和手寫代碼的好處,通過設置參數直接使用指定的已有代碼,提高整體效率。
通過調整算法模型、正確使用優化功能,或適當混用手寫和自動產生的代碼來提高總體效率,用戶將體會到基于模型的設計方法的好處。
拿正確的模型去生成代碼
代碼生成工具是沒有糾錯功能的,它只能忠實于你的模型去產生代碼。如果模型不經過充分驗證,或者說不能確保模型是正確的,那么代碼也就沒法保證正確。在基于模型的設計開發流程中,做到“拿正確的模型去生成代碼”,你的流程就比別人強很多了。
但是,什么樣的模型算是正確的模型?能跑出預期的結果的模型就一定是“正確的模型”嗎?
正確的模型應該是在現有的工具水平下,經過充分驗證的模型。由于在產品化中,所有驗證工作最終都會被算到開發成本里面。所以要應該根據項目的要求,選擇合適的驗證手段。
從是否要運行模型來看,模型驗證可以劃分為“靜態驗證”和“動態驗證”。
靜態驗證
在模型建立之后,首先需要做的是自動化的“靜態檢查”。建模規范檢查(比如目前行業普遍采用的MAAB),是很多公司都在做的事情。除了規范檢查之外,建議使用 Simulink Design Verifier 檢查是否有數據溢出和死邏輯,這兩種錯誤比違反一些建模規則更嚴重,可能會導致系統失效。
除了自動化的靜態檢查之外,“評審”是經常被大家忽略的靜態驗證方式。自動化靜態驗證和人工靜態驗證之間的順序很重要,直接關系到開發效率問題。在評審之前完成自動化靜態檢查,可以幫助開發者發現問題,提高開發效率。
動態驗證
動態,也就是讓模型的功能跑起來。從效率上考慮,建議先做單元測試,再做集成測試。
單元測試應該是整個驗證環節里工作量最大的環節,要重點關注結構覆蓋率問題。具體多少的覆蓋率算是合格,還有不少的爭論。想要達到比較好的覆蓋率,需要對模型的復雜度進行控制,復雜度一定不能太高,否則沒法提升覆蓋率。
集成測試可以一定程度的驗證接口問題、調度問題、模塊間的需求問題等,是非常有必要的。對于龐大系統,集成測試需要分階段進行:先做組件級的集成,再做系統級的集成,讓驗證工作可實現。
完成以上提到的各種驗證,基本上可以認為這是正確的模型了。使用驗證過的正確模型配置數據,才可以生成的成熟的代碼。當然,生成的代碼還需要做一個對比測試,驗證代碼和模型之間功能上是否一致,也就是我們常說的 SIL 和 PIL 測試。
使用 MATLAB 算法自動生成代碼
基于模型的設計流程和自動代碼生成在汽車等行業基本上已經是標準手段,然而在大多使用 MATLAB 語言的通信和數據分析領域,代碼生成的接受度還不是那么地高。用戶大多選擇留在 MATLAB 中,享受 MATLAB 語言的彈性。
如何在保持 MATLAB 的條件下,提升代碼生成的效率呢?
用戶普遍關注以下兩點:
如何充分使用MATLAB算法開發的"設計模式"
如何重用已有的 C 或者 C++ 代碼。
MATLAB 算法開發的“設計模式”借鑒于軟件的設計模式這個概念,具體可以理解為一些 MATLAB 的編碼規則。一個簡單的“設計模式”用例:要想讓 MATLAB 運行效率夠高,應該盡量采用矩陣運算替代 for 循環。
在代碼生成中也存在很多類似的模式。這些設計模式能夠針對具體的硬件結構,產生出更加有效的代碼,并且提升算法的抽象度。不僅可以提升代碼運行效率,對于長期維護算法代碼也很幫助。
以深度學習為例:
在 MATLAB R2017b 中發布的 GPU Coder 可以把通用的 MATLAB 代碼轉化為 CUDA C 代碼。
在 GPU Coder 中,我們也總結了一些能夠提升對 GPU 這種架構運行效率的模式。很多人不了解 GPU 架構,可以把它理解成多核處理器構成的集群。例如stencilKernel 這個高階函數就總結了一種類似于二維濾波的計算模式。
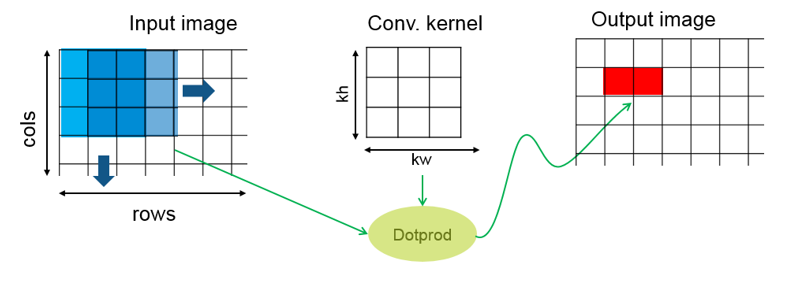
* 高階函數就是那些輸入參數為函數的函數。MATLAB 代碼生成中匯集了很多類似的高階函數,理論上用通用的 MATLAB 代碼都能實現相應的功能。
充分使用這些算法模式(或設計模式),能夠提高算法的抽象程度,同時有利于產生更加高效的代碼。
那么如何混用現有的 C 或者 C++ 代碼?
首先,非常不推薦用戶為了提升效率而手寫 C 代碼生成 MEX 嵌入到 MATLAB 中。這不僅無法實現提速,反而可能比 MATLAB 更慢。另外手寫 MEX 非常繁瑣,并且容易出錯。同時通過 MEX 接口引入的函數很難應用到生成的代碼之中。
對于項目中遺留的 C 代碼,高效的做法是在 MATLAB 中直接調用 C 代碼,通過代碼生成的方法自動產生可以被 MATLAB 調用的 MEX 函數。
double foo(double in1, double in2);
function y =callfoo %#codegen
y = coder.ceval('foo', 10, 20);
上面這段代碼在生成 MEX 函數的時候,自動會做好調用包裝的工作,而在 C 代碼生成的時候,自動會直接調用已有代碼,而不會有任何的額外調用封裝,一舉兩得。
同理,在 Simulink 中,最簡單便捷的方式是在 Stateflow 中直接調用手工 C 代碼,讓 Simulink 自行完成編譯鏈接的工作,同時方便算法調整和更改。在 MATLAB 和 Simulink 中混合已有代碼的方法很多,建議用戶選擇靈活性夠高,同時還能兼顧開發效率和執行的方法實現。
-
數據
+關注
關注
8文章
7030瀏覽量
89034 -
效率
+關注
關注
0文章
149瀏覽量
20053 -
代碼
+關注
關注
30文章
4788瀏覽量
68612
發布評論請先 登錄
相關推薦
探索設計稿自動生成Flutter代碼的技術方案
源代碼解析工具與自動化流程圖生成解決方案
鑒源實驗室·ISO 26262中測試用例的得出方法-等價類的生成和分析

關于Makefile自動生成-autotools的使用

ISEDA首發!大語言模型生成的代碼到底好不好使

Simulink自動生成代碼現階段的學習筆記






 工商網監
工商網監
評論