 MATLAB數據建模方法中的機器學習方法介紹
MATLAB數據建模方法中的機器學習方法介紹
近年來,全國賽的題目中,多多少少都有些數據,而且數據量總體來說呈不斷增加的趨勢, 這是由于在科研界和工業界已積累了比較豐富的數據,伴隨大數據概念的興起及機器學習技術的發展, 這些數據需要轉化成更有意義的知識或模型。 所以在建模比賽中, 只要數據量還比較大, 就有機器學習的用武之地。
1.MATLAB機器學習概況
機器學習 ( Machine Learning ) 是一門多領域交叉學科,它涉及到概率論、統計學、計算機科學以及軟件工程。機器學習是指一套工具或方法,憑借這套工具和方法,利用歷史數據對機器進行“訓練”進而“學習”到某種模式或規律,并建立預測未來結果的模型。
機器學習涉及兩類學習方法(如圖1):有監督學習,主要用于決策支持,它利用有標識的歷史數據進行訓練,以實現對新數據的標識的預測。有監督學習方法主要包括分類和回歸;無監督學習,主要用于知識發現,它在歷史數據中發現隱藏的模式或內在結構。無監督學習方法主要包括聚類。
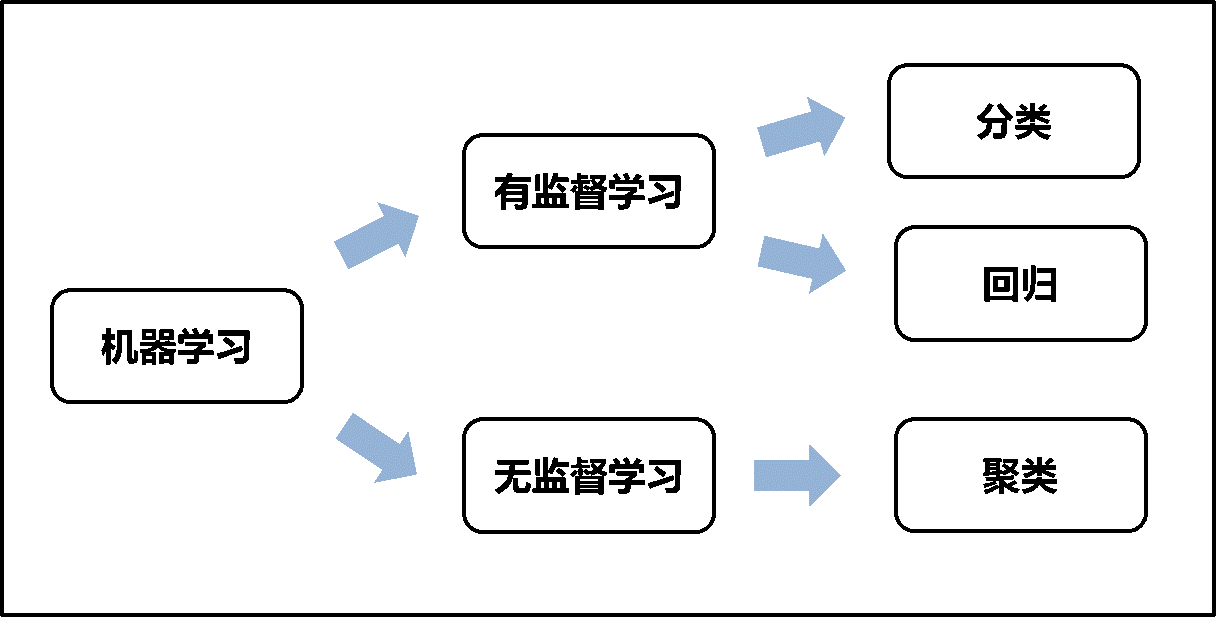
圖1 機器學習方法
MATLAB 統計與機器學習工具箱(Statistics and Machine Learning Toolbox)支持大量的分類模型、回歸模型和聚類的模型,并提供專門應用程序(APP),以圖形化的方式實現模型的訓練、驗證,以及模型之間的比較。
分類
分類技術預測的數據對象是離散值。例如,電子郵件是否為垃圾郵件,腫瘤是癌性還是良性等等。 分類模型將輸入數據分類。 典型應用包括醫學成像,信用評分等。MATLAB 提供的分類算法包括:

圖2 分類算法家族
回歸
回歸技術預測的數據對象是連續值。 例如,溫度變化或功率需求波動。 典型應用包括電力負荷預測和算法交易等。回歸模型包括一元回歸和多元回歸,線性回歸和非線性回歸,MATLAB 提供的回歸算法有:

圖3 回歸算法家族
聚類
聚類算法用于在數據中尋找隱藏的模式或分組。聚類算法構成分組或類,類中的數據具有更高的相似度。聚類建模的相似度衡量可以通過歐幾里得距離、概率距離或其他指標進行定義。MATLAB 支持的聚類算法有:

圖4 聚類算法家族
以下將通過一些示例演示如何使用 MATLAB 提供的機器學習相關算法進行數據的分類、回歸和聚類。
2.分類技術
支持向量機(SVM)
SVM 在小樣本、非線性及高維數據分類中具有很強的優勢。在 MATLAB 中,可以利用 SVM 解決二分類問題。同時也可以使用 SVM 進行數據的多分類劃分。
1) 二分類
以下示例顯示了利用 MATLAB 提供的支持向量機模型進行二分類,并在圖中畫出了支持向量的分布情況(圖5中圓圈內的點表示支持向量)。MATLAB 支持 SVM 的核函數(KernelFunction 參數)有:線性核函數(Linear),多項式核函數(Polynomial)、高斯核函數(Gaussian)。
%% 支持向量機模型
loadfisheriris;
% 數據只取兩個分類:‘versicolor' 和 'virginica'
inds = ~strcmp(species,'setosa');
% 使用兩個維度
X = meas(inds,3:4);
y = species(inds);
tabulate(y)
Value Count Percent
versicolor 50 50.00%
verginica 50 50.00%
%% SVM模型訓練,使用線性核函數
SVMModel = fitcsvm(X, y,'KernelFunction','linear');
%% 查看進行數據劃分的支持向量
sv = SVMModel.SupportVectors;
figure
gscatter( X( : , 1) , X( : , 2) ,y)
holdon
plot(sv( : , 1) , sv( : , 2) ,'ko','MarkerSize', 10)
legend('versicolor','virginica','Support Vector')
holdoff
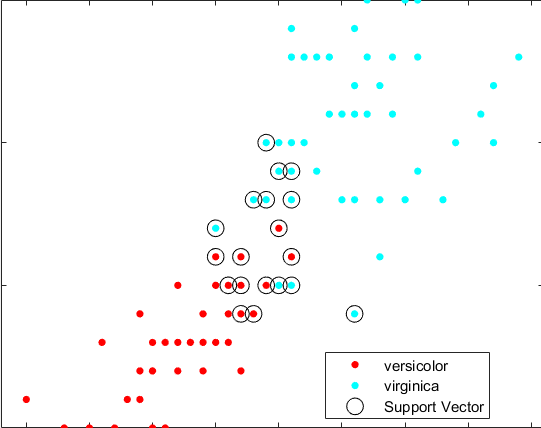
圖5 支持向量分布
2)多分類
MATLAB 多分類問題的處理是基于二分類模型.下面的示例演示如何利用 SVM 的二分類模型并結合 fitcecoc 函數解決多分類問題。
% 導入Fisher' s iris數據集
loadfisheriris
X = meas;
Y = species;
tabulate(Y)
Value Count Percent
setosa 50 33.33%
versicolor 50 33.33%
virginica 50 33.33%
% 創建SVM模板(二分類模型),并對分類變量進行標準化處理
% predictors
t = templateSVM('Standardize', 1);
% 基于SVM二分類模型進行訓練并生成多分類模型
Mdl = fitcecoc( X, Y,'Learners', t , . . .'ClassNames', {'setosa','versicolor','virginica'})
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: [ ]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3*1 cell}
CodingName: 'onevsone'
MATLAB 的 fitcecoc 函數支持多種二分類模型,例如, templateKNN, templateTree, templateLinear, templateNaiveBayes, 等等。
3. 回歸
回歸模型描述了響應(輸出)變量與一個或多個預測變量(輸入)變量之間的關系。 MATLAB 支持線性,廣義線性和非線性回歸模型。以下示例演示如何訓練邏輯回歸模型。
邏輯回歸
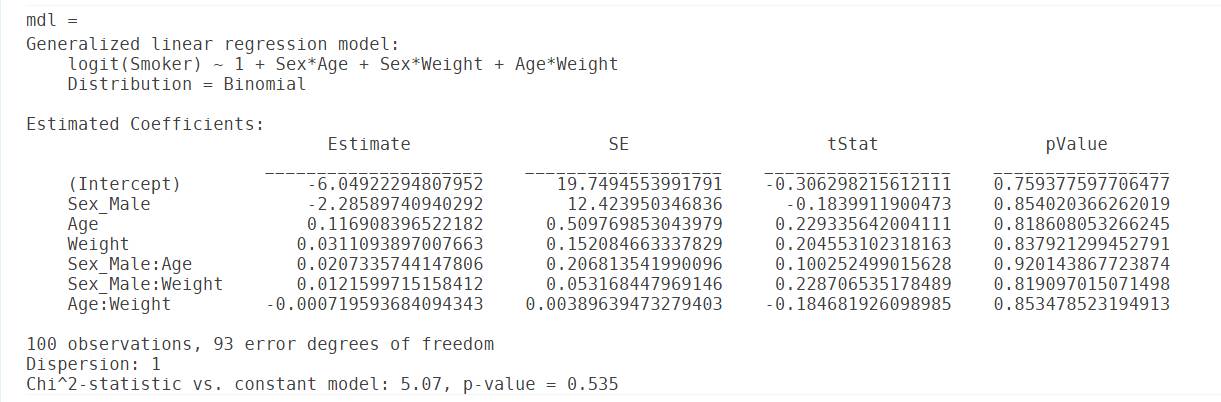
在 MATLAB 中,邏輯回歸屬于廣義線性回歸的范疇,可以通過使用 fitglm 函數實現邏輯回歸模型的訓練。
% 判定不同體重、年齡和性別的人的吸煙概率
loadhospital
dsa = hospital;
% 指定模型使用的計算公式
% 公式的書寫方式符合 Wilkinson Notation, 詳情請查看:
% http://cn.mathworks.com/help/stats/wilkinson-notation.html
modelspec ='Smoker ~ 1+ Age + Weight + Sex + Age:Weight + Age:Sex + Weight:Sex';
% 通過參數 ’Disribution' 指定 ‘binomial' 構建邏輯回歸模型
mdl = fitglm(dsa, modelspec,'Distribution','binomial')
4.聚類
聚類是將數據集分成組或類。 形成類,使得同一類中的數據非常相似,而不同類中的數據差異非常明顯。
層次聚類
下面以層次聚類方法為例,演示如何利用 MATLAB 進行聚類分析。
% 數據導入
loadfisheriris
% MATLAB中層次聚類是通過linkage函數實現
% 通過參數可以配置距離計算方法
% 類內距離的計算方法:'euclidean' ,歐幾里得距離
eucD = pdist(mean ,'euclidean');
% 類間距離的計算方法:'ward' ,最小化兩個類內點之間聚類平方和
Z = linkage(eucD,'ward');
% 使用 cophenetic 相關系數評價聚類計算過程(類內距離最小,類間距離最大)
% 值越大表明距離計算結果越好
cophenet(Z, eucD)
ans = 0.872828315330562
%生成4個類別的聚類結果
c = cluster(Z,'maxclust', 4);
可以顯示層次聚類生成的聚類樹,使用 dendrogram 函數:
% 查看層次聚類樹
dendrogram(Z)
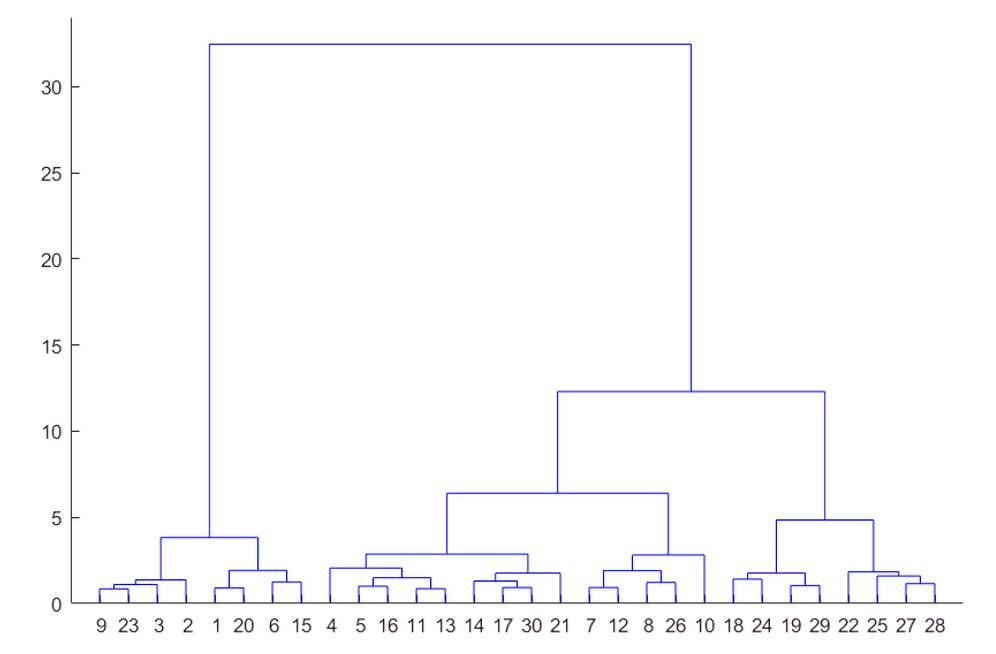
圖6 層次聚類
以上只是簡單的介紹了一下 MATLAB 支持的機器學習算法的使用方式,更多的信息可以查看 MathWorks 官網和 MATLAB 幫助文檔。
-
函數
+關注
關注
3文章
4341瀏覽量
62800 -
機器學習
+關注
關注
66文章
8428瀏覽量
132837 -
數據分析
+關注
關注
2文章
1455瀏覽量
34090
發布評論請先 登錄
相關推薦
傳統機器學習方法和應用指導

什么是機器學習?通過機器學習方法能解決哪些問題?






 工商網監
工商網監
評論