 如何快速認識Ceph/CephFS,最簡單的方式就是快速應用它
如何快速認識Ceph/CephFS,最簡單的方式就是快速應用它
大數據需要大存儲,尤其是文件存儲,Hadoop組件之一HDFS也因此得到了快速發展。隨著AI時代的來臨,機器學習對于大存儲提出了更高的要求。 分布式、并行、高速、在線擴展、高可用、可靠、安全等等,現代機器學習尤其是深度學習,要做大模型和超大模型訓練,要迭代數以TB級別甚至PB級別的樣本,要做類似spark的checkpoint,要做動態感知計算和網絡環境的調度,等等復雜負載,對文件系統的這些需求逐漸都變成了剛需。
壹
當前比較流行的分布式文件系統,包括HDFS、Ceph/CephFS、Lustre、GPFS、GlusterFS等,各具特點,并應用于一些特定的場景。作為開源項目的佼佼者,Ceph/CephFS因提供了對象存儲、塊存儲、文件系統三種接口,得到了最為廣泛的應用。常規的場景中,對象存儲可以搭建企業級網盤,塊存儲可以作為OpenStack/KVM的鏡像后端,文件存儲可以替代HDFS支持大數據。 在云原生大行其道的今天,Ceph也沒有落后腳步。目前已經提供了Kubernetes/Docker存儲的原生支持。
貳
了解Ceph的人,大都會認為Ceph是一個相對復雜的系統,尤其當磁盤規模達到千塊甚至萬塊時。Ceph經受住了長時間的應用考驗,也說明其架構設計非常之優秀。
在OPPO的機器學習平臺里,Ceph也在發揮著極其重要的作用,提供了諸如深度模型 分布式訓練、 代碼 和 數據共享 、 訓練任務容災 、 模型急速發布 等能力。Ceph的應用場景遠不僅如此,但因為Ceph系統太過“復雜”,導致很多架構師或者技術經理不敢輕易觸碰。
誠然,采納和應用一門新技術,向來不是一個簡單容易的過程,但認識或者理解一門新技術,對于我們這些混跡于IT和互聯網圈的同學,可能從來都不是什么難事兒。
叁
如何快速認識Ceph/CephFS,最簡單的方式就是快速應用它 。 如果想要理解它的原理,看代碼便是最直接的方式。后面,我們用源碼構建并運行一個小型的Ceph,全面感知下Ceph的魅力。對于了解Docker的同學,可以在容器里進行這個嘗試。
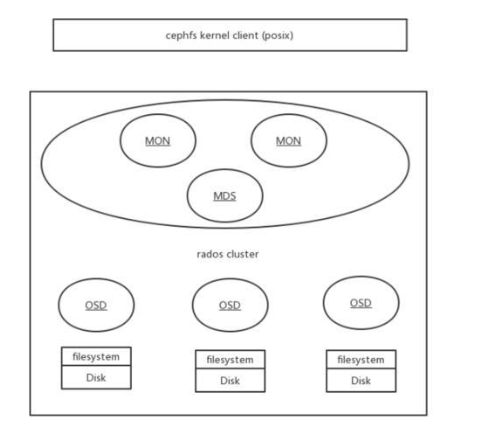
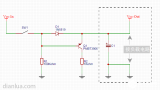
以下演示如何快速編譯并啟動一個 管理三塊磁盤的 分布式文件系統 。圖中Rados Cluster即為構造的Ceph存儲集群, CephFS Kernel Client 是實現Linux VFS標準的內核模塊,兩者通過網絡傳遞磁盤IO。
準備階段
假設物理機ip為10.13.33.36,新啟的容器ip為10.244.0.5
第一步: 準備好編譯和運行的操作系統容器
第二步: 在容器內安裝編譯和運行Ceph的環境依賴庫

第三步: 下載Ceph源代碼并解壓進入代碼工程目錄

第四步: 依賴準備
第五步: 編譯Ceph

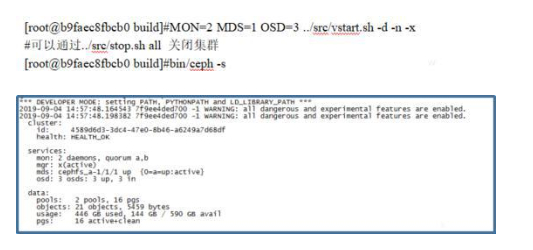
第六步: 啟動Ceph集群并檢查Ceph Cluster狀態
第七步:客戶端掛載CephFS文件系統

第八步: 客戶端檢測并使用CephFS文件系統

肆
通過以上簡單操作,即使是在未能熟悉mon/mds/osd服務功能,不用了解CRUSH算法原理,不懂cmake和make編譯系統的情況下, 也可以快速體驗到一個原生的Ceph/CephFS。
上述的Ceph集群虛擬管理了三塊disk(filesystem),并通過CephFS接口暴露文件系統接口,客戶端主機通過掛載該CephFS到/tmp/oppofs目錄,所有讀寫/tmp/oppofs目錄和文件的IO都會通過網絡傳遞給Ceph Rados Cluster,并分發給三塊disk。
當disk分布在多個主機時,在不同主機配置并啟動相對應的OSD進程即可,每塊磁盤的IO都是通過OSD進程進行管理。對Ceph性能和功能有特殊需求的場景,也可以通過直接調整源代碼來定制。
Ceph本身具備的能力足以支撐起成千上萬塊磁盤,但因磁盤數量高速增長引來的其他相關挑戰,就需要各位實踐者去不斷學習和積累相關的知識去應對了。 Ceph作為領先的大數據存儲解決方案 , 應用場景將會越來越豐富 。
-
磁盤
+關注
關注
1文章
379瀏覽量
25234 -
機器學習
+關注
關注
66文章
8428瀏覽量
132837 -
大數據
+關注
關注
64文章
8899瀏覽量
137579
發布評論請先 登錄
相關推薦
tmp117有快速測試的方法嗎?

基于DPU的Ceph存儲解決方案
帶你快速認識 HarmonyOS

如何快速生成Modbus指令?教程來啦

如何快速入門FPGA
如何快速入門FPGA?

余電快速泄放電路






 工商網監
工商網監
評論