 人工智能靠人工:標注員1天要聽1000條錄音
人工智能靠人工:標注員1天要聽1000條錄音
如今,智能設備越來越多地出現在每個人的生活中,在享受它們帶來的便利時,很多人或許沒有意識到,自己說的話可能會被人工“竊聽”并分析標注,而原因是——廠商想讓這些設備變得更智能。
“放首牛德華的歌”,一段帶口音的成年女聲從電腦里響起,但機器把它識別成了“兒童”的聲音,這是機器常犯的錯誤,標注員唐頓把它修改為“成人”,緊接著還要把“牛德華”注釋為“劉德華”,好讓機器下次變得“聰明”一點。
聽寫、標注這些聲音,是唐頓五年來的日常工作。
這五年,她每天大約要聽1000個陌生人的聲音,這些聲音出現在不同場景:一位帶有南方口音的尖銳男聲發出指令“小薇你好,請播放沙漠駱駝”,背景里伴隨著車輛閃光燈滴答滴答的聲響;一位略帶不耐煩的女聲高喊“關閉導航”;偶爾,還有車主通過罵臟話發泄情緒的聲音……
唐頓不明白為何要對這些聲音進行標注,她把問題拋給領導后,得到的反饋是——“機器需要數據來自我優化”。唐頓因此調侃自己是人工智能背后的女人。
人工智能的進化,需要大量數據來“喂養”,這催生出一個全新的產業,像唐頓一樣的標注員越來越多,一個龐大的系統正在形成。
為AI打工的青年
早上8點,家在河南的張藝誠打開電腦,帶上耳機,輸入賬號密碼后進入到一個后臺系統,開始一天的工作。
1個月前,他陸續加入了兩個近2000人規模和兩個50人規模的標注團隊,每次能領到一個約有150條語音的數據包,大概要在1小時內做完,做完后才能繼續領任務。
張藝誠向燃財經展示搶到的不知來源的語音包,從內容上看場景較為私密,有“濤哥,下班了一起斗地主啊”、“好心累吶”、“你在哪”等。
相比“領”任務,張藝誠認為,用“搶”更貼切,“僧多粥少,能搶到多少取決于老大的能力。”
張藝誠向燃財經展示的50人團隊里,大家稱管理員為“老大”,老大們之間也有競爭,團隊轉錄的數據質量越高、速度越快,老大能拿到的單子就越多,才能“喂飽”團隊并繼續擴大規模。同時,團隊規模越大,對上游的話語權也就越大,能領到的單量也更多、質量也更高,這是相輔相成的關系。
不管團隊是上千人還是幾十人,新人加入都必須先經過測試,測試之后是培訓,緊接著才是領任務,最后還得有一輪人工質檢審核,因為客戶通常要求最終的準確率在95%以上。
想通過測試并不容易,需要記住繁瑣的細節規范,比如哪些客戶需要在轉寫英文字母時大寫、哪些要求小寫,哪些情況會直接視語音為“無效”,發音不清的字詞哪些需要加音標、哪些不加,“且動不動就要整批打回”,除此之外還得聽得懂特定場景的術語。

語音標注員需要遵循的標注規范(部分)
張藝誠讓燃財經嘗試轉錄了10條他收到的語音包,從內容看是發生在游戲同伴間的對話,里面出現了包括“呂布”、“李白”、“房主”等在內的王者榮耀游戲里的稱呼,通常帶有環境噪音,麥克風偶有噴麥,并不容易聽清。
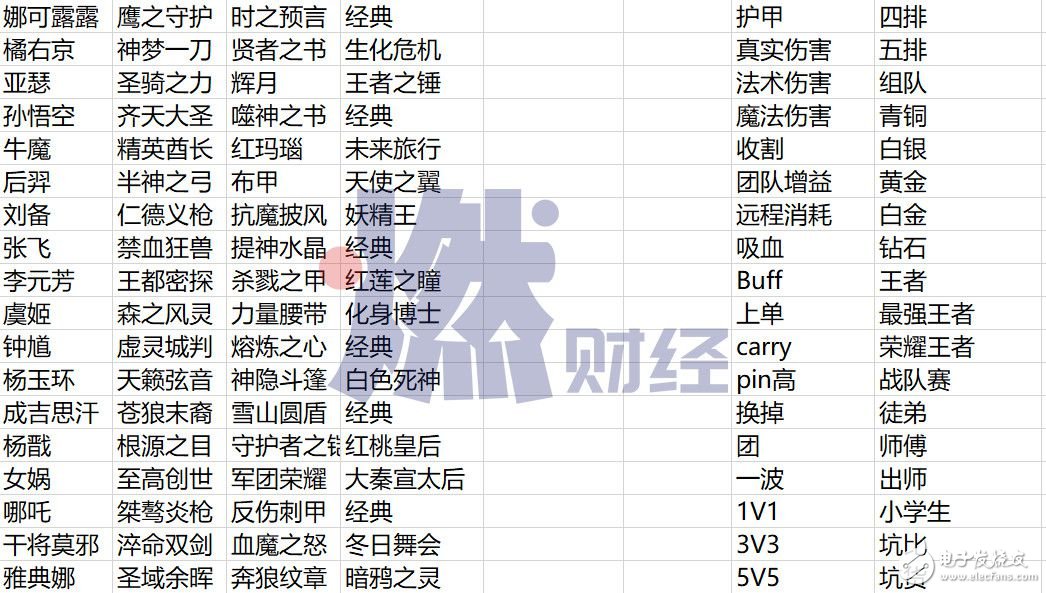
標注員需要熟悉的專業詞匯
張藝誠展示的錄音,大多來自擁有語音交互功能的產品,如車載語音、智能音箱,其中包括百度小度、天貓精靈的用戶錄音,還有來自攜程的客服錄音和來自滴滴的司乘錄音。但大部分任務并不以客戶名稱命名,而是以音頻長短來區分。
燃財經體驗后發現,交互類型的音頻多在2-5秒之間,通常夾雜噪音,大部分是用戶和語音產品的對話,少數能明顯判斷為意外觸發的錄音,且未出現暴露用戶身份信息、位置信息的情況。
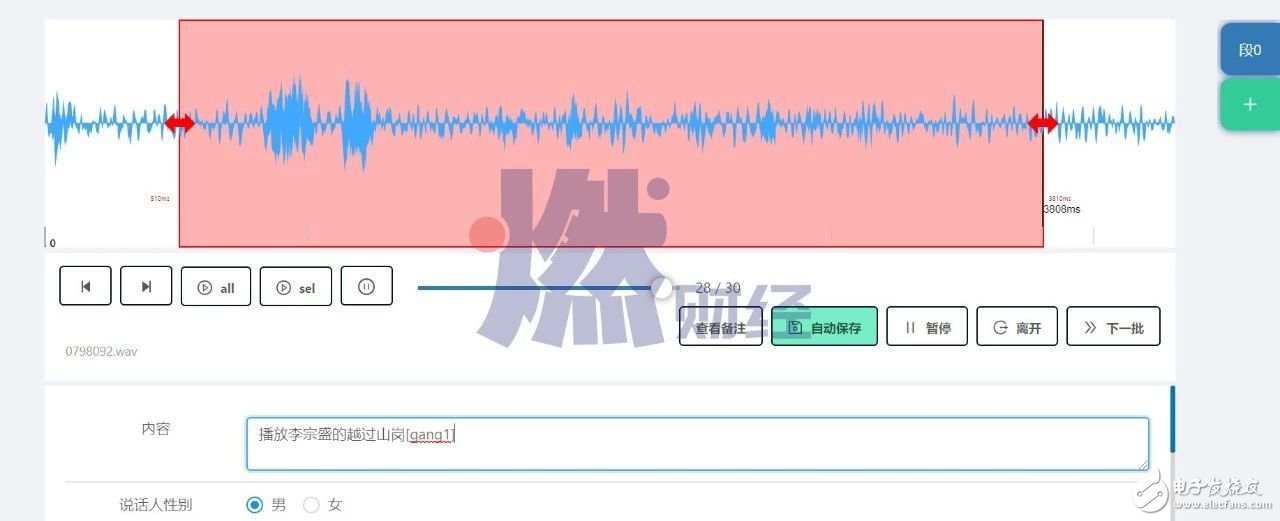
語音標注員需要用到的后臺系統及顯示界面
其中,小度音箱的轉錄注意事項注明:如果整句跟旁人聊天的無效,只有跟小度對話的才有效。
而在燃財經體驗的車載語音中,大部分為帶口音的普通話用戶,點播的歌曲類型多為東北社會搖和快手熱門歌曲。
張藝誠表示,這是一項完全沒有技術的累活,1小時有效時長錄音,能帶來100元報酬,但聽下來需要30個小時,平均時薪只有3塊多錢。即使是干了五年的唐頓,平均月薪也只有三千。
AI迫切需要成長,張藝誠和唐頓們只會越來越多,他們大多遍布在河南、山東、河北等地的四五線小城里, 夜以繼日地為世界領先的AI產品服務。
美國AI研究機構Cognilytica預計,截止2018年,全球數據標注相關產業的產值將增長66%達到5億美元,2023年產值更將翻一番,而由于大部分工作都在“水下”,具體產值尚且難以準確估算。
財大氣粗的數據服務商
與遍布在四五線小城鎮里的打工者不同,被轉錄的數據包通常由具備一定規模的人工智能公司或數據服務商發布。
在BOSS直聘上,燃財經以“數據標注員”為關鍵詞,搜索到超過100條相關職位信息,發布這類職位的公司通常處于B輪或C輪階段、具備一定的資金實力,有的直接在職責介紹中注明——“智能語音、圖片等相關數據的語義理解及標注”、“對已標注數據的清洗,保證標注數據的正確率”。
對于燃財經“數據清洗是什么”的疑問,一位負責招聘的hr回答:使用軟件對數據進行操作,不是很難。
當燃財經繼續詢問是否是“將錄音內容轉寫成文字”時,對方表示“是的”,同時透露客戶是小米,但問到具體會是什么語音包時,對方不再回復。
而在張藝誠加入的四個群背后,發布的任務大多來自一個叫海天瑞聲的公司。
公開資料顯示,該公司成立于2005年,專注于人工智能上游的數據資源服務,服務場景包括人機交互、智能家居、智慧城市等。
招股書顯示,海天瑞聲有三大主營業務,分別是數據資源定制服務、數據庫產品和數據資源相關的應用服務。前五大客戶為阿里巴巴、三星、騰訊、微軟、百度,貢獻了2018年營業收入的59.6%,總計1.1億元,其中阿里巴巴排名第一為5179萬。
2016年-2018年,海天瑞聲分別實現營業收入8422.86萬元、1.19億元、1.93億元,凈利潤為1028.93萬元、3414.96萬元、6714.16萬元。
2016年-2018年,數據資源定制服務及數據庫產品兩項收入合計占營業收入近99%,兩者毛利潤合計占比也是超過95%。海天瑞聲的招股書中,對數據資源定制服務和數據庫產品定義如圖:

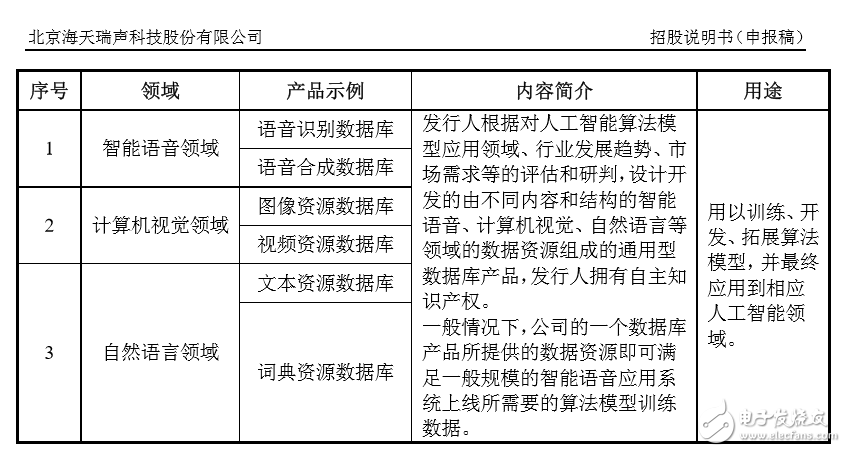
來源 / 海天瑞聲招股書
無論是從數據資源定制服務還是數據庫產品的銷售情況來看,智能語音數據資源的銷售是主要收入來源。
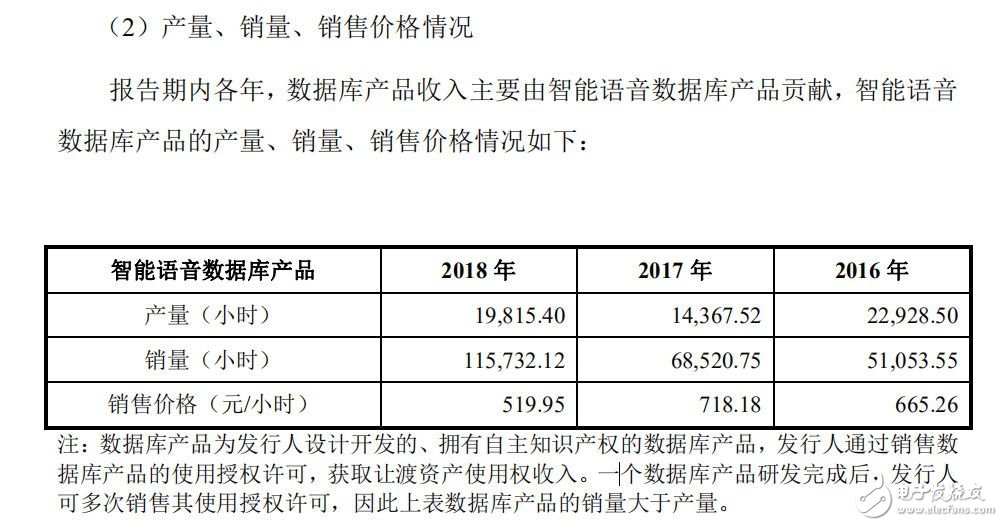
來源 / 海天瑞聲招股書
2019年,海天瑞聲還上演了一場科創板“逃跑計”。7月26日,其上會審核狀態變更為終止審核,科創板上市之路告一段落,輿論認為原因在于其核心技術不足。
從公布的軟件著作權以及在申請專利來看,海天瑞聲的大部分技術是用于語音數據采集與處理環節。可見,公司的核心技術主要體現在錄制及標注語音數據方面。

來源 / 海天瑞聲招股書
而由于錄制及標注語音數據需要大量廉價勞動力,這也是公司經常大規模招兼職的原因。
“在能看得見的未來,我們還得為AI打工”
在電影《她》中,那個由斯嘉麗·約翰遜配音的人聲智能系統Samantha擁有極高的情商,為討好使用者繼續訂閱,Samantha不僅需要讓男主人泰奧多爾完全相信她與人類無差,同時還要嘗試讓對方愛上自己,為此,永遠都不能聽錯或理解錯泰奧多爾說過的任何一個字。
這是一部來自2013年的電影,時間來到2019,距離電影中的愿景還很遙遠。
一位來自北郵人工智能研究院的研究員周洲告訴燃財經,一個好的模型數據量基本都是上百萬級別的,通過用戶自發產生的數據,才是最貼合實際業務的好數據。
“機器學習,你教他什么,他才能學會什么。以目前的技術,脫離大數據學習的強人工智能模型還是很遙遠的。”周洲說。
他解釋了AI的訓練過程:“首先,AI訓練需要一個模型,這個模型需要通過一定量的基礎標注數據進行訓練,獲得一個預期的訓練結果,比如對預測天氣的語句識別率達到60%或更高。這時候投入使用環境會產生大量的用戶數據,這些數據再經過甲方脫敏處理——去掉姓名地址等能透露用戶身份的信息,再交由人工進行二次標注。
這就來到了大量廉價標注員標注的環節。通過一些標準,把質量高的音頻篩選出來,因為引入一些冷門的數據反而會降低模型的表現。通過這些數據進一步調整模型,使模型能夠更加適合自己的業務場景,這樣就構成了一次迭代,然后不斷循環。”
具體到語音交互產品,周洲補充,如果一個音箱恰好在南方地區銷售比較好,那么他們就可以通過數據調整,對南方口音有更好的識別率。
曾做過語音交互產品的創業者告訴燃財經,目前對智能語音產品的需求是,它能聽懂我說的話并反饋給我想要的東西,而中華文化博大精深,不同地域又有不同表達,加上生活和書面語言還不一樣,這些都需要交代在系統里。
AI的生長需要優質數據喂養,而另一邊,不知情的用戶也開始反擊。
2019年4月,亞馬遜被爆在世界各地雇傭了數千名員工,對Echo音箱捕捉到的錄音進行轉錄、注釋;
7月,蘋果被爆用戶與Siri的對話可能會被錄音,并且上傳至蘋果,由蘋果分發給Siri的外包公司進行分析,迫于輿論壓力,蘋果表示暫停語音分析業務;
同月,谷歌承包商泄露了超過1000份用戶與谷歌助理交談的錄音,錄音來自于Google Home智能音箱以及語音助手。
對此,亞馬遜、蘋果、谷歌的回應基本一致,“偷聽”是為了提高各自旗下語音助手的智能性。
盡管在發布數據包前,大部分公司會對數據進行脫敏處理,但在用戶未知情的情況下,這是否觸犯了法律?
對此,有多年司法工作經驗的中經天平副主任王凱告訴燃財經,無論是否用于牟利,或者是為了提高服務和產品質量,采集和抓取用戶數據的首要原則,就是要有用戶授權。“即使是不涉及用戶身份信息的指令性錄音,如‘播放音樂’,在沒有經過授權去抓取這個數據,也屬于違法。”
市面上大部分產品以是否同意隱私協議內容作為用戶授權的方式,但對用戶來說,雖然選擇權掌握在手,大部分情況還是處于被動狀態,這是因為大部分產品只有在同意授權后才能使用。
對此,王凱表示,從法律上來說,還有一個問題,即便得到了用戶授權也要考慮到用戶是否完全了解授權的內容,授權之后是否有清晰的提示與展現,以及是否是本人進行操作等等情況。
“但回歸到問題本質,是否合法還得看最終如何去使用這個數據。如果是倒賣給第三方,或者使用在用戶不知情的地方,仍然是違法的;
如果協議中并未明確數據將會如何使用,則處于不完全告知狀態,這也存在一些法律風險,但目前并沒有一個明確的法律條款去規范,只能說如果用戶能找到明確侵權證據,那就屬于違法。”
燃財經查閱了小度音箱的用戶協議和隱私協議,協議顯示:“當您激活DuerOS程序或喚醒DuerOS設備后,我們會自動接收并記錄您與設備終端進行交互過程中產生的音頻、視頻等相關信息。”
值得注意的是,協議還表明:“若您拒絕我們收集上述信息……將導致您無法獲得相關服務。”

小度音箱用戶協議
燃財經就用戶協議向百度和阿里相關人員咨詢,截至發稿,未獲回應。
一方面,AI變得更智能需要更多用戶數據,另一方面,用戶數據屬于隱私應該保護,而法律的完善不是一朝一夕的事,這似乎形成了一個無解的困境。
是否能提出一個大膽的設想:在不久的將來,AI訓練不再依賴大數據?
對此,周洲表示,“現在已經存在一種強化學習的方式,就是機器可以通過一部分簡單學習后,自己產生數據進行自主學習,AlphaGo就是這樣。”
“但目前強化學習還只能用于規則既定、獎懲明確的場景,比如下棋、玩游戲等,下錯了就會失敗,機器人可通過獎懲的方式去學習,但現實更多情況是復雜的,很難制定一個明確的獎懲規則。”
他補充,未來確實有實現的可能性,不過這個未來有多遠就不知道了,至少在能看得見的未來,我們還得為AI打工。
“What happens on your iPhone, stays on your iPhone(在iPhone上發生的事,就讓它留在iPhone上)”,這是今年年初的CES展上,蘋果公司在會場外投放的巨型廣告宣傳語,目前看來,這可能只是一個美好的幻想。
-
機器
+關注
關注
0文章
784瀏覽量
40765 -
智能設備
+關注
關注
5文章
1062瀏覽量
50650 -
語音交互
+關注
關注
3文章
287瀏覽量
28043
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論