") 谷歌采用全新AI架構(gòu),晶體管性能得到巨幅提升
谷歌采用全新AI架構(gòu),晶體管性能得到巨幅提升
(文章來源:機(jī)器之心Pro)
TSP 的全稱是 Tensor Streaming Processor,專為機(jī)器學(xué)習(xí)等 AI 相關(guān)需求打造。該架構(gòu)在單塊芯片上可以實(shí)現(xiàn)每秒 1000 萬億(10 的 15 次方)次運(yùn)算,是全球首個(gè)實(shí)現(xiàn)該級(jí)別性能的架構(gòu),其浮點(diǎn)運(yùn)算性能可達(dá)每秒 250 萬億次(TFLOPS)。在摩爾定律走向消亡的背景下,這一架構(gòu)的問世標(biāo)志著芯片之爭(zhēng)從晶體管轉(zhuǎn)向架構(gòu)。
250 TFLOPS 浮點(diǎn)運(yùn)算性能是什么概念?目前的世界第一超級(jí)計(jì)算機(jī) Summit,其峰值算力為 200,794.9 TFLOPS,它的背后是 28,000 塊英偉達(dá) Volta GPU。如果 TSP 達(dá)到了類似的效率,僅需 803 塊就可以實(shí)現(xiàn)同樣的性能。Groq 在一份白皮書中介紹了這項(xiàng)全新的架構(gòu)設(shè)計(jì)。此外,他們還將在于美國(guó)丹佛舉辦的第 23 屆國(guó)際超算高峰論壇上展示這一成果。
我們?yōu)檫@一行業(yè)和我們的客戶感到興奮,Groq 的聯(lián)合創(chuàng)始人和 CEO Jonathan Ross 表示。頂級(jí) GPU 公司都在宣稱他們有望在未來幾年向用戶交付一款每秒百萬億次運(yùn)算性能的產(chǎn)品,但 Groq 現(xiàn)在就做到了,而且建立了一個(gè)新的性能標(biāo)準(zhǔn)。就低延遲和推理速度而言,Groq 的架構(gòu)比其他任何用于推理的架構(gòu)都要快許多倍。我們與用戶的互動(dòng)證明了這一點(diǎn)。
Groq 的 TSP 架構(gòu)是專為計(jì)算機(jī)視覺、機(jī)器學(xué)習(xí)和其他 AI 相關(guān)工作負(fù)載的性能要求設(shè)計(jì)的。對(duì)于一大批需要深度學(xué)習(xí)推理運(yùn)算的應(yīng)用來說,Groq 的解決方案是非常理想的選擇,Groq 的首席架構(gòu)師 Dennis Abts 表示,但除此之外,Groq 的架構(gòu)還能用于廣泛的工作負(fù)載。它的性能和簡(jiǎn)潔性使其成為所有高性能即數(shù)據(jù)和計(jì)算密集型工作復(fù)雜的理想平臺(tái)。
Groq 的這款架構(gòu)受到軟件優(yōu)先(software first)理念的啟發(fā)。它在 Groq 開發(fā)的 TSP 中實(shí)現(xiàn),為實(shí)現(xiàn)計(jì)算靈活性和大規(guī)模并行計(jì)算提供了一種新的范式,但沒有傳統(tǒng) GPU 和 CPU 架構(gòu)的限制和溝通開銷。在 Groq 的架構(gòu)中,Groq 編譯器負(fù)責(zé)編碼所有內(nèi)容:數(shù)據(jù)流入芯片,并在正確的時(shí)間和正確的地點(diǎn)插入,以確保計(jì)算實(shí)時(shí)進(jìn)行,沒有停頓。執(zhí)行規(guī)劃由軟件負(fù)責(zé),這樣就可以釋放出原本要用于動(dòng)態(tài)指令執(zhí)行的寶貴硬件資源。
在傳統(tǒng)的體系架構(gòu)中,將數(shù)據(jù)從 DRAM 移動(dòng)到處理器需要大量的算力和時(shí)間,而且相同工作負(fù)載上的處理性能也是可變的。在典型的工作流中,開發(fā)人員通過反復(fù)運(yùn)行工作負(fù)載或程序來對(duì)其進(jìn)行配置和測(cè)試,以驗(yàn)證和度量其平均處理性能。由于處理器接收和發(fā)送數(shù)據(jù)的方式不同,這種處理可能會(huì)得到略有差別的結(jié)果,而開發(fā)人員的工作就是手動(dòng)調(diào)整程序以達(dá)到預(yù)定的可靠性級(jí)別。
但有了 Groq 的硬件和軟件,編譯器就可以準(zhǔn)確地知道芯片的工作方式以及執(zhí)行每個(gè)計(jì)算所需的時(shí)間。編譯器在正確的時(shí)間將數(shù)據(jù)和指令移動(dòng)到正確的位置,這樣就不會(huì)有延遲。到達(dá)硬件的指令流是完全編排好的,使得處理速度更快,而且可預(yù)測(cè)。開發(fā)人員可以在 Groq 芯片上運(yùn)行相同的模型 100 次,每次得到的結(jié)果都完全相同。對(duì)于安全和準(zhǔn)確性要求都非常高的應(yīng)用來說(如自動(dòng)駕駛汽車),這種計(jì)算上的準(zhǔn)確性至關(guān)重要。
另外,使用 Groq 硬件設(shè)計(jì)的系統(tǒng)不會(huì)受到長(zhǎng)尾延遲的影響,AI 系統(tǒng)可以在特定的功率或延遲預(yù)算內(nèi)進(jìn)行調(diào)整。這種軟件優(yōu)先的設(shè)計(jì)(即編譯器決定硬件架構(gòu))理念幫助 Groq 設(shè)計(jì)出了一款簡(jiǎn)單、高性能的架構(gòu),可以加速推理流程。該架構(gòu)既支持傳統(tǒng)的機(jī)器學(xué)習(xí)模型,也支持新的計(jì)算學(xué)習(xí)模型,目前在 x86 和非 x86 系統(tǒng)的客戶站點(diǎn)上運(yùn)行。
為了滿足深度學(xué)習(xí)等計(jì)算密集型任務(wù)的需求,芯片的設(shè)計(jì)似乎正在變得越來越復(fù)雜。但 Groq 認(rèn)為,這種趨勢(shì)從根本上就是錯(cuò)誤的。他們?cè)诎灼兄赋觯?dāng)前處理器架構(gòu)的復(fù)雜性已經(jīng)成為阻礙開發(fā)者生產(chǎn)和 AI 應(yīng)用部署的主要障礙。當(dāng)前處理器的復(fù)雜性降低了開發(fā)者工作效率,再加上摩爾定律逐漸變慢,實(shí)現(xiàn)更高的計(jì)算性能變得越來越困難。
Groq 的芯片設(shè)計(jì)降低了傳統(tǒng)硬件開發(fā)的復(fù)雜度,因此開發(fā)者可以更加專注于算法(或解決其他問題),而不是為了硬件調(diào)整自己的解決方案。有了這種更加簡(jiǎn)單的硬件設(shè)計(jì),開發(fā)者無需進(jìn)行剖析研究(profiling),因此可以節(jié)省資源,更容易大規(guī)模部署 AI 應(yīng)用。與基于 CPU、GPU 和 FPGA 的傳統(tǒng)復(fù)雜架構(gòu)相比,Groq 的芯片還簡(jiǎn)化了認(rèn)證和部署,使客戶能夠簡(jiǎn)單而快速地實(shí)現(xiàn)可擴(kuò)展、單瓦高性能的系統(tǒng)。
Groq 的張量流架構(gòu)可以在任何需要的地方提供算力。與當(dāng)前領(lǐng)先的 GPU、CPU 相比,Groq 處理器的每個(gè)晶體管可以實(shí)現(xiàn) 3-6 倍的性能提升。這一改進(jìn)意味著交付性能的提升、延遲的下降以及成本的降低。結(jié)果是,Groq 的架構(gòu)使用起來更加簡(jiǎn)單,而且性能高于傳統(tǒng)計(jì)算平臺(tái)。
(責(zé)任編輯:fqj)
-
谷歌
+關(guān)注
關(guān)注
27文章
6173瀏覽量
105634 -
AI芯片
+關(guān)注
關(guān)注
17文章
1894瀏覽量
35103
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何測(cè)試晶體管的性能 常見晶體管品牌及其優(yōu)勢(shì)比較
晶體管與場(chǎng)效應(yīng)管的區(qū)別 晶體管的封裝類型及其特點(diǎn)
晶體管的輸出特性是什么
晶體管對(duì)CPU性能的影響
CMOS晶體管的尺寸規(guī)則
NMOS晶體管和PMOS晶體管的區(qū)別
GaN晶體管和SiC晶體管有什么不同
GaN晶體管的基本結(jié)構(gòu)和性能優(yōu)勢(shì)
芯片晶體管的深度和寬度有關(guān)系嗎
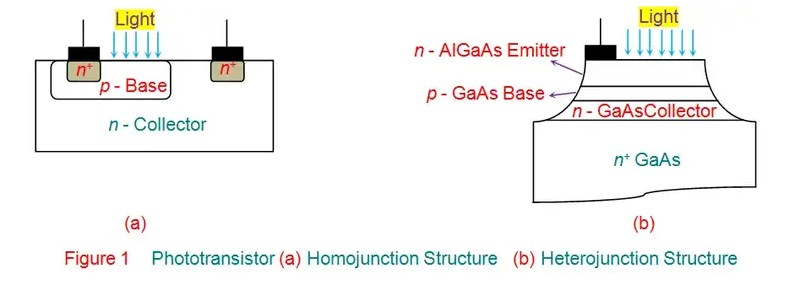
什么是光電晶體管?光電晶體管的工作原理和結(jié)構(gòu)
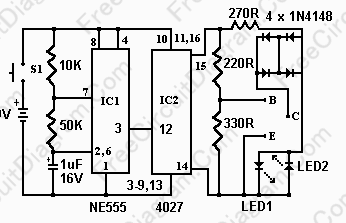
晶體管測(cè)試儀的主要作用
蘋果M3芯片有多少晶體管組成
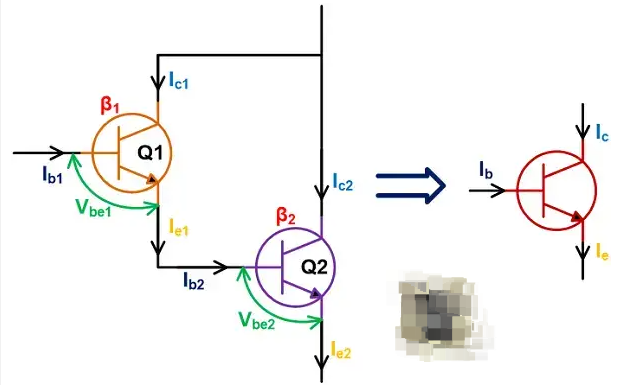
什么是達(dá)林頓晶體管?達(dá)林頓晶體管的基本電路
晶體管測(cè)試儀電路圖分享





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論