 如何通過張量的降維來降低卷積計算量(CP分解)
如何通過張量的降維來降低卷積計算量(CP分解)
引言
在CNN網絡中卷積運算占據了最大的計算量,壓縮卷積參數可以獲得顯著的硬件加速器的性能提升。在即將介紹的這篇論文中,作者就是通過張量的降維來降低卷積計算量的。作者通過CP分解將一個4D張量分解成多個低維度的張量,并且最后通過微調參數來提升網絡精度。
1 原理
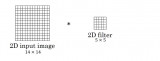
CNN卷積參數可以看做一個4D的張量。其中兩個維度是對應一幅feature map的兩個空間方向。一個方向對應輸入feature map,另外一個維度為輸出feature map方向。一個全卷積運算是對應每個輸入feature map卷積求和,如圖所示。通過CP分解,一個全卷積運算變成了連續多步一維卷積運算。圖中S維度是多個輸入feature map堆疊成的,dxd是feature map的空間維度。卷積核在feature map兩個空間維度進行劃窗運動,圖中一個綠色方塊內的結果求和得到一幅輸出feature map中的一個像素點。T是多幅輸出feature map堆疊成的。
那么這樣的分解如何來保證和全卷積結果的不變呢?其實是要保證kernel不變就行了。然后再通過一些數學變化將全卷積變為連續多步卷積。已知一個二維矩陣可以進行如下分解:
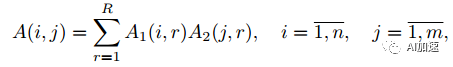
其中R是矩陣A的秩。計算量的降低取決于A的秩,秩越小,那么就可以被分解為更小矩陣,計算量降低的就越大。如果A的秩為其維度d,那么如果保持分解后秩不變,那么計算量是不能減小的,所以關鍵是看矩陣的秩的大小,秩的大小反映了網絡的信息冗余度。將之推廣到多維張量,有:

假設A張量維度為n1xn2x…nd,那么通過上述分解,參數量就大為降低,為(n1+n2+…nd)R個。
對于二維矩陣,可以使用SVD方式來計算分解的矩陣。但是當維數大于2,則無法使用這種方式了。作者選擇了非線性最下平方差(non-linear least squares)方法,其通過降低L2項來獲得分解矩陣。NLS方法計算的1維分解矩陣精度更好。
4D張量分解了,那么如何來將卷積計算分解為多步連續運算呢?一個全卷積運算表示為:

K為卷積核,維度為dxdxSxT。經過分解后卷積核為:
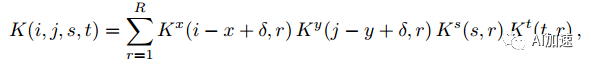
然后通過重新排序可以得到連續多步卷積運算:

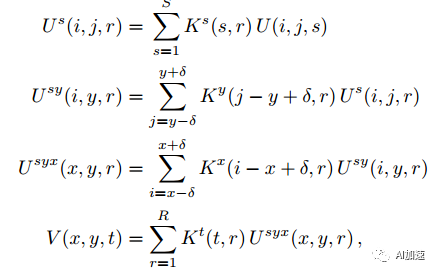
2 實驗
在字符識別上,作者使用4層卷積網絡,在不進行CP降維時,識別精度為91.2%。通過CP降維后,精度降低了1%,但是識別速率提升了8.5倍。
在ALEXNET網絡上,CP降維實現了6.6倍速率提升,但是精度只降低了1%。
結論
CP分解降低了權重的秩,進而降低了計算量以及參數總量。多適用于小型的分類網絡。
-
卷積
+關注
關注
0文章
95瀏覽量
18530 -
硬件加速器
+關注
關注
0文章
42瀏覽量
12820
原文標題:【網絡壓縮四】CP分解
文章出處:【微信號:FPGA-EETrend,微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

張量計算在神經網絡加速器中的實現形式
FFT與DFT計算時間的比較及圓周卷積代替線性卷積的有效性實
TensorFlow教程|張量的階、形狀、數據類型
卷積神經網絡一維卷積的處理過程
降維空時自適應處理研究
融合朋友關系和標簽的張量分解推薦算法
基于TTr1SVD的張量奇異值分解
谷歌宣布開源張量計算庫TensorNetwork及其API
如何使用FPGA實現高光譜圖像奇異值分解降維技術
淺析卷積降維與池化降維的對比





 工商網監
工商網監
評論