 基于無監督學習和圖學習的大數據挖掘
基于無監督學習和圖學習的大數據挖掘
在IJCAI-2019期間舉辦的騰訊TAIC晚宴和Booth Talk中,來自TEG數據平臺的張長旺向大家介紹了自己所在用戶畫像組的前沿科研結果:
1. 非監督短文本層級分類;
2. 大規模復雜網絡挖掘和圖表示學習。
其所在團隊積極與學術界科研合作,并希望有夢想、愛學習的實力派加入,共同研究和應用半監督/弱監督/無監督學習、小樣本學習、大規模復雜網絡挖掘和圖表示學習等做大數據挖掘。
科研結果1:非監督短文本層級分類
首先以下用戶和AI算法的對話,顯示了現實業務中使用現有監督文本分類算法的遇到的一些困境和問題:
算法需要海量訓練數據
算法模型用戶不可控
算法不能很好的適應類目的變化
我們分析現有監督算法的主要問題在于沒有真正的知識, 沒有對于文本和類目的真正的理解。現有算法只是在學習大量人工標注訓練樣本里面的模式。為了解決這個問題,我們啟動了一個叫做: 基于關鍵詞知識與類目知識的非監督短文本層級分類的探索項目。
項目的主要思想是引入關鍵詞和類目兩種知識來幫助算法理解關鍵詞和類目的含義。然后基于知識進行文本的分類和標注。關鍵詞知識主要來自3個方面包括:關鍵詞的網絡搜索上下文、關鍵詞的百科上下文、關鍵詞到類目詞的后驗關聯概率。我們提出類目語義表達式來支持用戶表達豐富的類目本身和類目之間的關系的語義。這兩樣知識的引入幫助算法擺脫了對于大量人工標注訓練樣本的依賴,同時算法分類的過程做到了人工可理解,人工可控制。
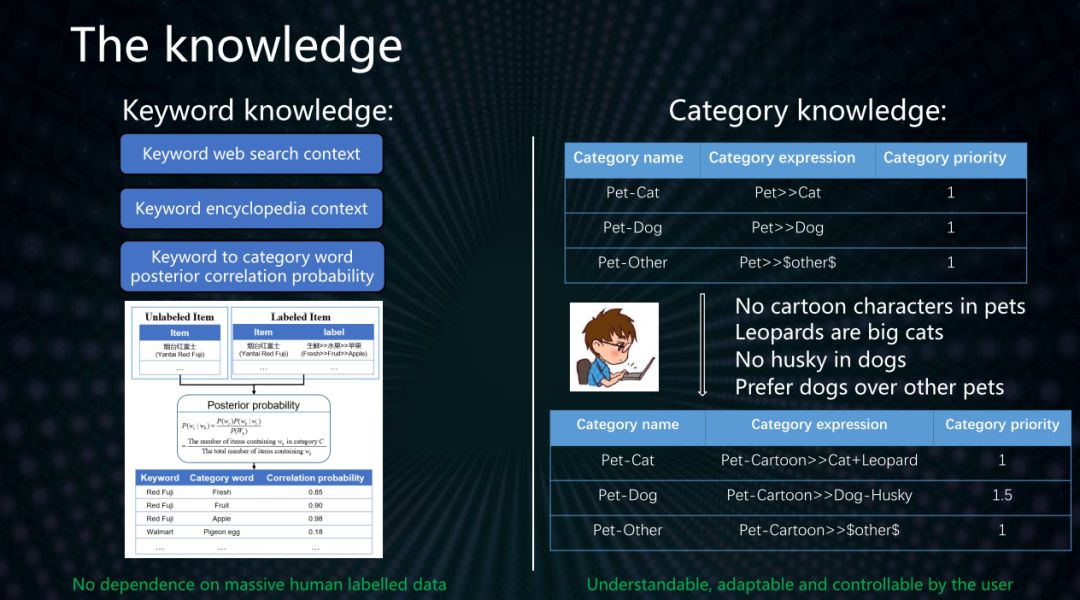
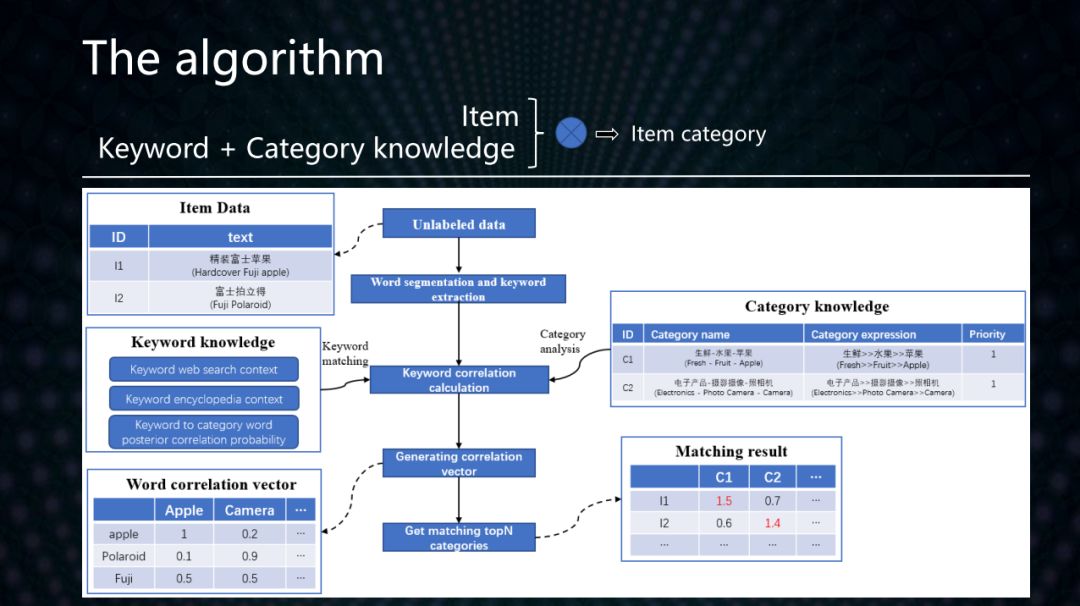
基于關鍵詞和類目知識的無監督文本層級分類算法流程如下:
對文本提取關鍵詞
根據關鍵詞知識計算關鍵詞到類目詞的相關度詞向量
根據關鍵詞的相關度詞向量計算文本的相關度詞向量
根據文本的相關度詞向量和類目語義表達式計算文本與每個類目的匹配度
每個文本被分為與之匹配度最高的類目
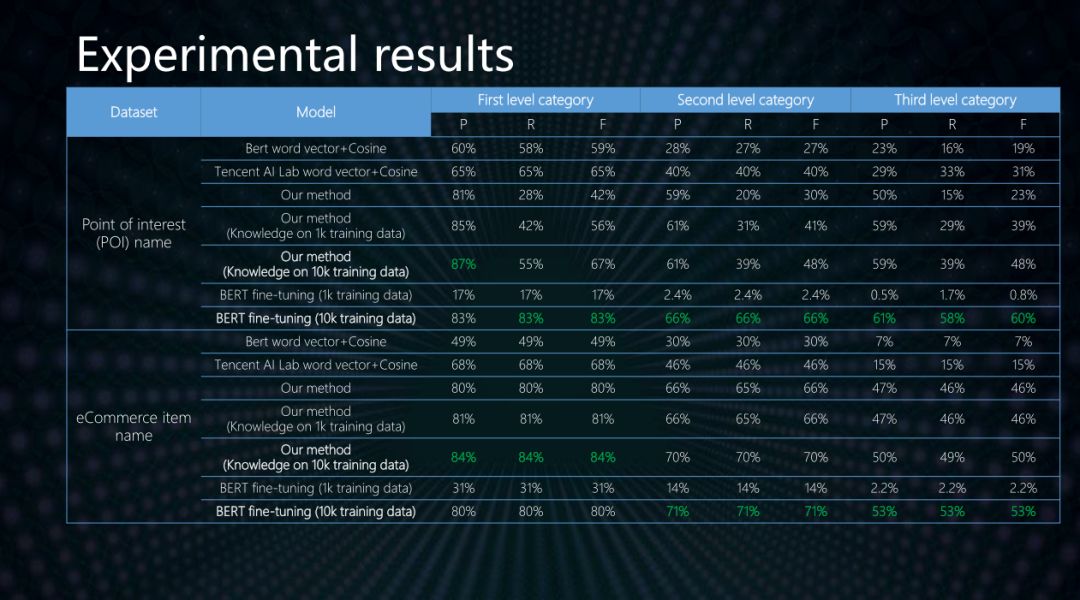
通過在兩個文本分類數據集合上面的實驗,我們發現,我們自研的算法能夠在沒有訓練樣本的情況下提供質量可用的結果,其一級類目準確率能夠達到80%,并且明顯高于現有其他非監督算法。
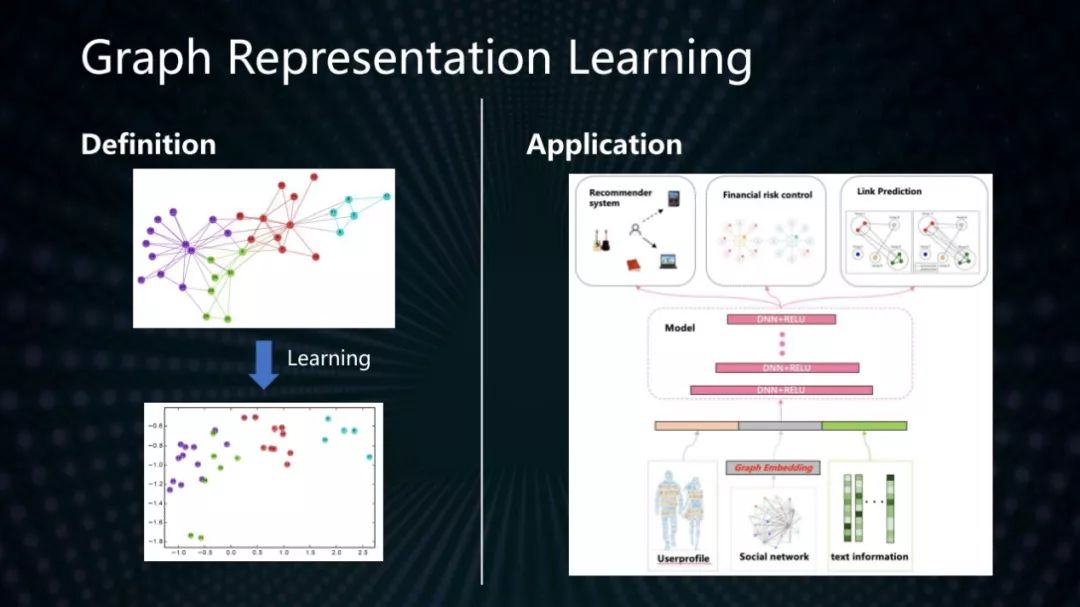
科研結果2:大規模復雜網絡挖掘和圖表示學習
Network Representation Learning 或者說 Graph Embedding 是復雜網絡最新的研究課題,意在通過神經網絡模型,把圖結構向量化,為節點分類、鏈路預測、社團發現等挖掘任務提供方便有效的特征,以克服圖結構難以應用到機器學習算法中的難題。
本次我們在IJCAI發表的學術論文“Identifying Illicit Accounts in Large Scale E-payment Networks - A Graph Representation Learning Approach”創新性提出結合邊屬性的圖卷積神經網絡模型,彌補了現有算法無法利用邊屬性為節點分類提供更多信息的不足。
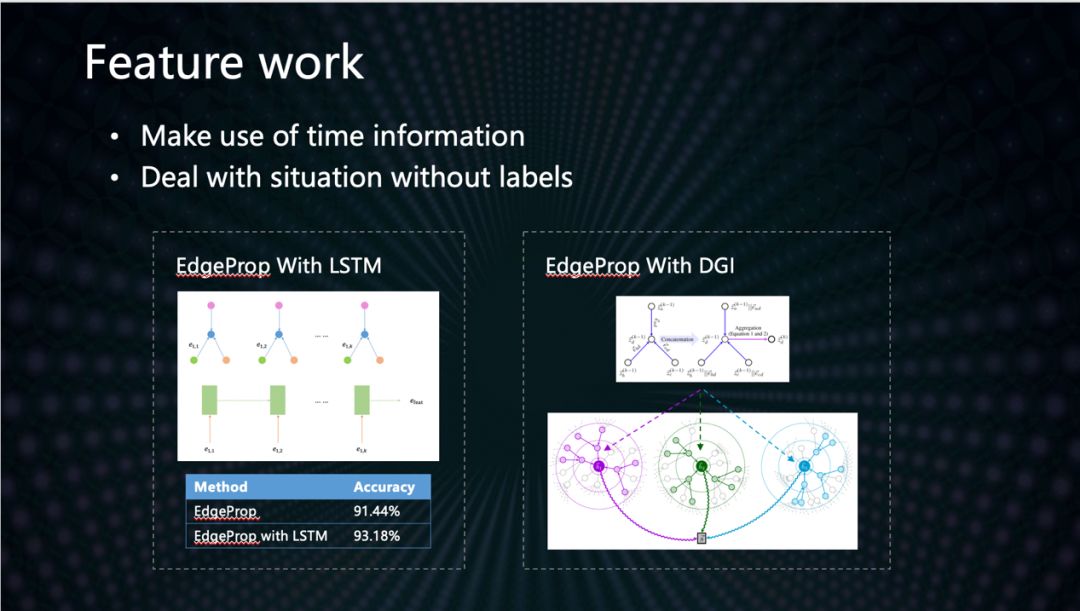
現有的圖學習算法,絕大部分都忽視了邊上信息的價值。在這里我們提出了一種可以把邊的信息傳輸到節點表示結果的改進的GCN算法。算法主要思路是在做GCN里面周邊鄰居節點向量的聚合計算之前,把每個節點連接邊的Embedding向量拼接在對應鄰居節點的Embedding向量后面。實驗顯示,我們的算法對于金融分類問題具有更優的結果。我們團隊正在進一步優化模型,正在研發利用時序的GCN模型,以可以利用邊的時序交互信息,從而更好的表示動態網絡。

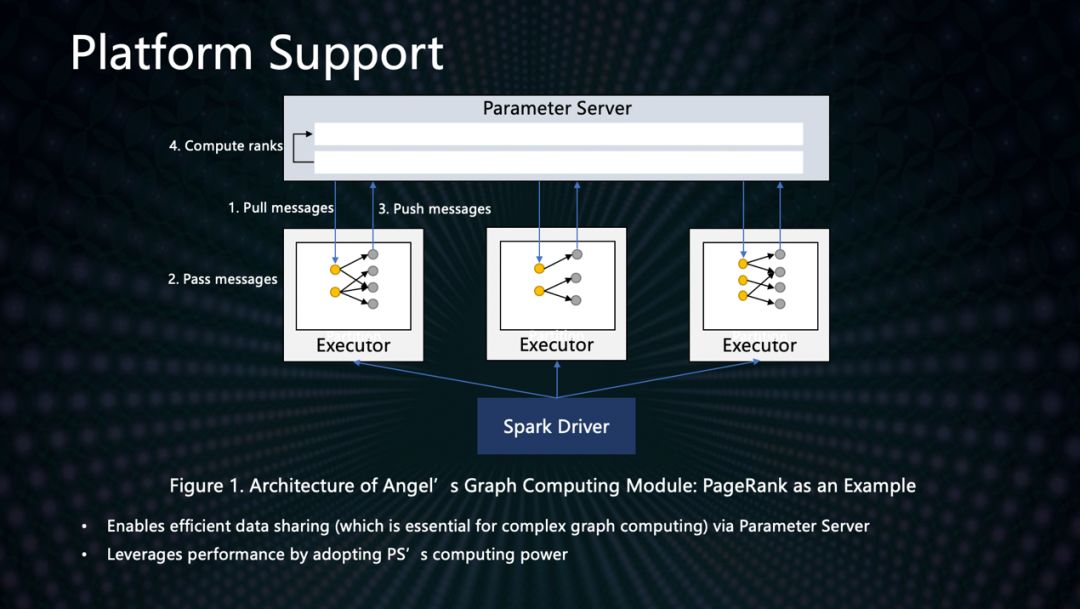
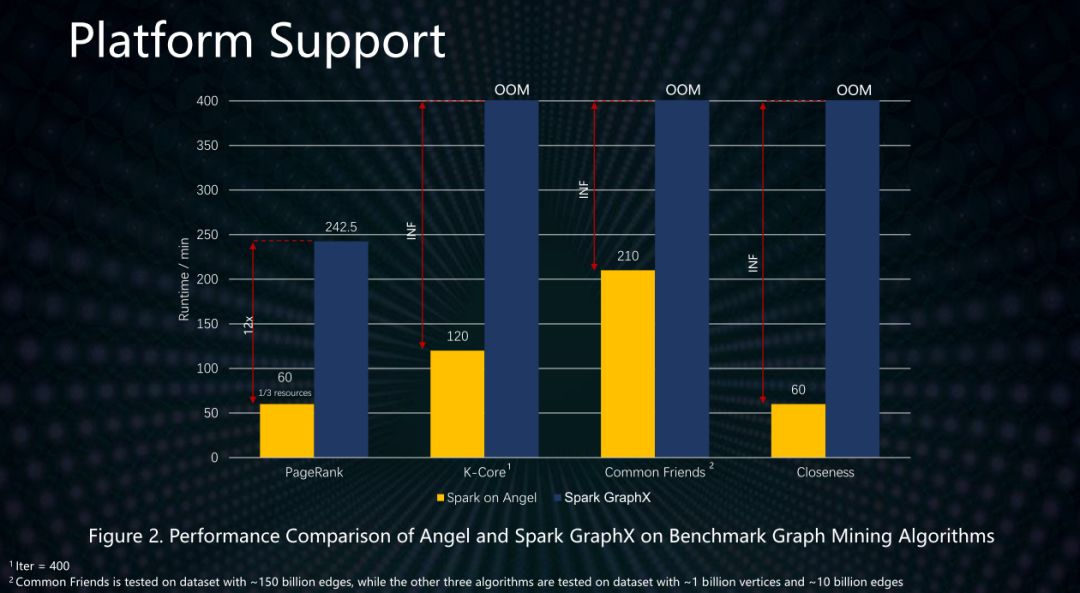
同時,數平數據中心研發的Angel參數服務器平臺,針對關系型數據結構,在計算性能上對圖算法做了優化,極大加速了PageRank等算法的計算速度,比如計算用戶中心度的Closeness算法,性能比基于Spark GraphX的算法提升了6.7倍。下圖顯示對于大型圖的計算,我們Angle框架的速度具有明顯的優勢。
我們所在團隊積極與學術界科研合作,并希望有夢想、愛學習的實力派加入,共同研究和應用半監督/弱監督/無監督學習、小樣本學習、復雜網絡挖掘和圖表示學習做大數據挖掘。
-
算法
+關注
關注
23文章
4612瀏覽量
92901 -
大數據
+關注
關注
64文章
8889瀏覽量
137446
原文標題:IJCAI2019報告:基于無監督學習和圖學習的大數據挖掘
文章出處:【微信號:Tencent_TEG,微信公眾號:騰訊技術工程官方號】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
時空引導下的時間序列自監督學習框架

基于大數據與深度學習的穿戴式運動心率算法

【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
基于FPGA的類腦計算平臺 —PYNQ 集群的無監督圖像識別類腦計算系統
圖機器學習入門:基本概念介紹

無監督深度學習實現單次非相干全息3D成像

機器學習基礎知識全攻略
Meta發布新型無監督視頻預測模型“V-JEPA”
數據挖掘的應用領域,并舉例說明
描繪未知:數據缺乏場景的缺陷檢測方案






 工商網監
工商網監
評論