 Hbase的基礎性介紹與入門
Hbase的基礎性介紹與入門
無論是 NoSQL,還是大數據領域,HBase 都是非常"炙熱"的一門數據庫。本文將對 HBase 做一些基礎性的介紹,旨在入門。
一、簡介
HBase 是一個開源的、面向列的非關系型分布式數據庫,目前是Hadoop體系中非常關鍵的一部分。在最初,HBase是基于谷歌的 BigTable 原型實現的,許多技術來自于Fay Chang在2006年所撰寫的Google論文"BigTable"。與 BigTable基于Google文件系統(File System)一樣,HBase則是基于HDFS(Hadoop的分布式文件系統)之上而開發的。
HBase 采用 Java 語言實現,在其內部實現了BigTable論文提到的一些壓縮算法、內存操作和布隆過濾器等,這些能力使得HBase 在海量數據存儲、高性能讀寫場景中得到了大量應用,如 Facebook 在 2010年11 月開始便一直選用 HBase來作為消息平臺的存儲層技術。HBase 以Apache License Version 2.0開源,這是一種對商業應用友好的協議,同時該項目當前也是Apache軟件基金會的頂級項目之一。
有什么特性
基于列式存儲模型,對于數據實現了高度壓縮,節省存儲成本
采用 LSM 機制而不是B(+)樹,這使得HBase非常適合海量數據實時寫入的場景
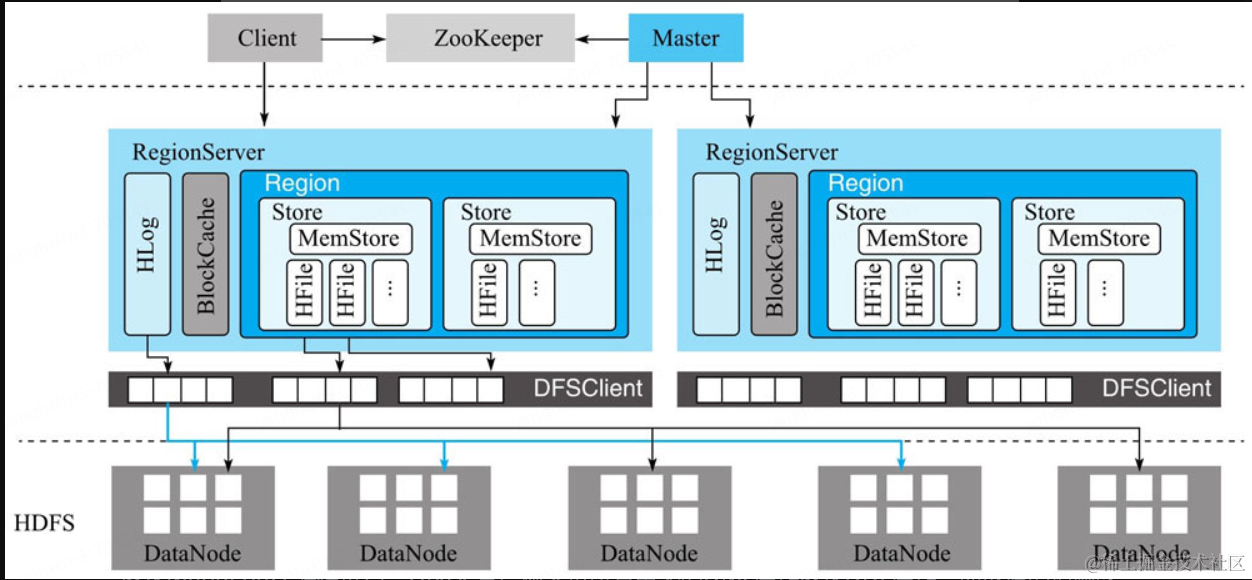
高可靠,一個數據會包含多個副本(默認是3副本),這得益于HDFS的復制能力,由RegionServer提供自動故障轉移的功能
高擴展,支持分片擴展能力(基于Region),可實現自動、數據均衡
強一致性讀寫,數據的讀寫都針對主Region上進行,屬于CP型的系統
易操作,HBase提供了Java API、RestAPI/Thrift API等接口
查詢優化,采用Block Cache 和 布隆過濾器來支持海量數據的快速查找
與RDBMS的區別
對于傳統 RDBMS 來說,支持 ACID 事務是數據庫的基本能力,而 HBase 則使用行級鎖來保證寫操作的原子性,但是不支持多行寫操作的事務性,這主要是從靈活性和擴展性上做出的權衡。
ACID 要素包含 原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)以及持久性(Durability)
總體來說, HBase 與傳統關系數據庫的區別,如下表所示:
二、數據模型
下面,我們以關系型數據庫的一個數據表來演示 HBase 的不同之處。
先來看下面這張表:
這里記錄的是一些家庭設備上報的狀態數據(DeviceState),其中包括設備名、狀態、時間戳這些字段。
在 HBase 中,數據是按照列族(Column Family,簡稱CF)來存儲的,也就是說對于不同的列會被分開存儲到不同的文件。那么對于上面的狀態數據表來說,在HBase中會被存儲為兩份:
列族1. 設備名
列族2. 狀態
這里Row-key是唯一定位數據行的ID字段,而Row-key 加上 CF、Column-Key,再加上一個時間戳才可以定位到一個單元格數據。其中時間戳用來表示數據行的版本, 在HBase中默認會有 3 個時間戳的版本數據,這意味著對同一條數據(同一個Rowkey關聯的數據)進行寫入時,最多可以保存3個版本。
在查詢某一行的數據時,HBase需要同時從兩個列族(文件)中進行查找,最終將結果合并后返回給客戶端。 由此可見如果列族太多,則會影響讀取的性能,在設計時就需要做一些權衡。
由此可見,HBase的使用方式與關系型數據庫是大不相同的,在使用 HBase 時需要拋棄許多關系型數據庫的思維及做法,比如強類型、二級索引、表連接、觸發器等等。
然而 HBase 的靈活性及高度可伸縮性卻是傳統 RDBMS 無法比擬的。
-
大數據
+關注
關注
64文章
8889瀏覽量
137442 -
Hbase
+關注
關注
0文章
27瀏覽量
11182
發布評論請先 登錄
相關推薦
TCSH shell 編程入門

【全新課程資料】正點原子《ESP32基礎及項目實戰入門》培訓課程資料上線!
新書推薦 | TSMaster開發從入門到精通

HBase集群數據在線遷移方案探索
芯海應用筆記:CPW3101入門指南
![[RK3588從<b class='flag-5'>入門</b>到精通]系列內容專欄目錄及<b class='flag-5'>介紹</b>](https://file1.elecfans.com/web2/M00/89/71/wKgZomSD4l6AF1pHAERebsBrF3M34.jpeg)
半導體封裝的可靠性測試及標準介紹





 工商網監
工商網監
評論