") 賦予機器自主設(shè)計模型“能力”,一文概覽結(jié)構(gòu)搜索的起源
賦予機器自主設(shè)計模型“能力”,一文概覽結(jié)構(gòu)搜索的起源
伴隨著人工智能技術(shù)的飛速發(fā)展,語音識別、機器翻譯等各項科技名詞已不是傳統(tǒng)意義上被企業(yè)家束之高閣的前景應(yīng)用,更不是研究人員諱莫如深的復(fù)雜概念,它們已經(jīng)伴隨著大數(shù)據(jù)時代的來臨走入了尋常人的身邊。如今的生活中我們無處不在享受著人工智能技術(shù)帶給我們的便利,從前在科幻電影《星際迷航》中使用的通用翻譯器,已然成為了現(xiàn)在人們出行途中能夠使用的小型翻譯機。而撥開這些實際應(yīng)用的面紗,它們背后所使用的技術(shù)往往是這些年來備受關(guān)注的神經(jīng)網(wǎng)絡(luò)模型。
通俗來講,它是一種對外部輸入信息進行學(xué)習(xí)的數(shù)學(xué)模型或計算模型。它能夠通過對自身內(nèi)部結(jié)構(gòu)的調(diào)整來擬合輸入數(shù)據(jù),憑借著算法廣泛的通用性,其在語音、圖像、自然語言處理等眾多領(lǐng)域得到了廣泛的應(yīng)用。
電影《星際迷航》里科克船長和老骨頭所使用的實時翻譯設(shè)備
而對于目前的基于神經(jīng)網(wǎng)絡(luò)技術(shù)的各項任務(wù)而言,主要的過程依舊是由研究人員手動地探索新的網(wǎng)絡(luò)結(jié)構(gòu),比如我們常見的循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent neural network; RNN)、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network; CNN)等。但這樣做實際上是一個非常系統(tǒng)工程的方式,我們把研究人員束縛在崗位上不斷地去“設(shè)計”所謂的更好的結(jié)構(gòu),而模型的好與壞則往往取決于人對任務(wù)的理解以及模型設(shè)計上的想象力,整個過程需要研究人員對相關(guān)領(lǐng)域有著充分的認知,間接提高了從業(yè)人員的入門門檻,與此同時通過人工不斷地對模型結(jié)構(gòu)進行改良也非常耗費時間。
隨著近年來計算機設(shè)備的算力以及存儲能力逐年遞增,人們逐漸開始去思考是否我們可以讓計算機像學(xué)網(wǎng)絡(luò)參數(shù)一樣學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)模型的結(jié)構(gòu)?希望能通過這種方式將研究人員從模型結(jié)構(gòu)設(shè)計者的位置上“解救”出來,于是就有了這樣一個機器學(xué)習(xí)領(lǐng)域的研究分支——網(wǎng)絡(luò)結(jié)構(gòu)搜索(Neural Architecture Search; NAS)。
實際上目前神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索技術(shù)已經(jīng)在各個領(lǐng)域中嶄露頭角,如谷歌團隊在Searching for Activation Functions【1】論文中通過對激活函數(shù)空間進行搜索發(fā)現(xiàn)了Swish函數(shù),相對諸如Relu等傳統(tǒng)人工設(shè)計的激活函數(shù)具有更快的收斂速度。而微軟團隊在WMT19機器翻譯評測任務(wù)中同樣也采用了其團隊提出的NAO【2】方法來自動地對神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)進行優(yōu)化,在英語-芬蘭語以及芬蘭語-英語的任務(wù)上均取得了不俗的成績。
可以看到網(wǎng)絡(luò)結(jié)構(gòu)搜索技術(shù)的使用已經(jīng)為各項任務(wù)中模型結(jié)構(gòu)的設(shè)計起到非常好的助力,那么其背后究竟使用了怎樣的技術(shù)?如何能夠讓神經(jīng)網(wǎng)絡(luò)自動地對自身結(jié)構(gòu)進行改良?雖然目前網(wǎng)絡(luò)結(jié)構(gòu)的搜索技術(shù)依舊方興未艾,但已然存在很多來自工業(yè)界以及學(xué)術(shù)界的團隊在不斷努力探索更好的方法。
可以預(yù)計在不遠的將來,隨著科研人員的努力以及計算資源的進一步提升,網(wǎng)絡(luò)結(jié)構(gòu)搜索的技術(shù)將大幅降低模型結(jié)構(gòu)的更迭所需要的時間周期,同時能夠讓研究人員有更多地精力去探索有趣的應(yīng)用或討論神經(jīng)網(wǎng)絡(luò)背后的可解釋性。當然在這個過程中,我們需要審視這門技術(shù)的發(fā)展歷史,同時對未來的發(fā)展趨勢進行展望。

微軟團隊在WMT19機器翻譯評測任務(wù)中英語-芬蘭語任務(wù)的提交信息
從“人工”到“自動”的突圍
人類對于自動化的追求從未停止,這一點從三次工業(yè)革命的目標即可看到端倪,它們無一不在為了將人們從繁復(fù)的工作中解放出來不懈努力。而對于機器學(xué)習(xí)任務(wù)而言,人們也依舊在不斷地探索,希望能夠讓機器在無需人類過多干預(yù)的情況下,真正地替代人去完成更多的工作,而在這個過程中研究人員始終在不斷嘗試,努力做好這次從“人工”到“自動”的突圍。
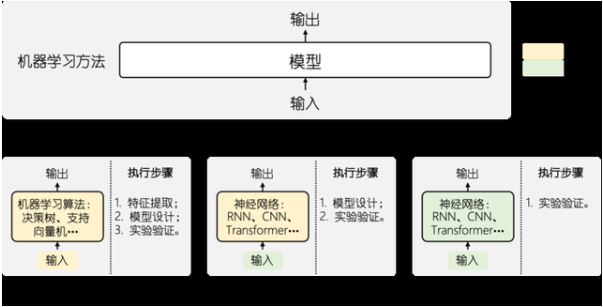
機器學(xué)習(xí)方法的演化與變遷
傳統(tǒng)機器學(xué)習(xí)
如果我們將機器學(xué)習(xí)所處理的任務(wù)建模為一種從輸入到輸出的映射學(xué)習(xí),那么在初代的機器學(xué)習(xí)算法中,我們不僅需要設(shè)計一種適用于當前任務(wù)的方法(如廣泛使用的決策樹、支持向量機等),同時還要為其提供人工設(shè)計的特征集合,在完成這些工作之后,才能使用數(shù)據(jù)對模型中的參數(shù)進行調(diào)優(yōu)。
以情感分析為例,我們可以向模型中輸入詞性、詞頻及其情感屬性等信息,然后通過支持向量機的模型來對情感分析任務(wù)進行建模,其中詞性、詞頻以及情感屬性即為我們從句子中提取出的人工設(shè)計的模型特征,支持向量機則是我們選擇來解決當前問題的機器學(xué)習(xí)算法。
我們可以看到,不管是輸入的特征還是模型自身,均為研究人員歸納總結(jié)而得,這個過程就很容易造成對有效特征的忽視以及模型設(shè)計上的不合理,因此基于這種傳統(tǒng)機器學(xué)習(xí)算法的情感分析任務(wù)在IMDB Movie Reviews【3】集合上的準確率一般很難超過92%(如斯坦福大學(xué)的工作Baselines and Bigrams: Simple, Good Sentiment and Topic Classification【4】,通過使用樸素貝葉斯的方法在IMDB Movie Reviews數(shù)據(jù)集上也僅達到了91.22%的準確率)。可以看到在機器學(xué)習(xí)技術(shù)的初期,整個系統(tǒng)尚且處于對“人工”高度依賴的時代。
隨著深度學(xué)習(xí)技術(shù)的廣泛普及,人們開始嘗試將提取特征的過程交由模型來自動完成,通過數(shù)據(jù)驅(qū)動的方式減少傳統(tǒng)方法中特征遺漏的問題。比如說對于圖像處理任務(wù)而言,我們無需根據(jù)人工經(jīng)驗對圖像中的局部特征進行設(shè)計,只需要直接將畫面完整地送入模型中進行訓(xùn)練即可。
下圖中為人臉識別任務(wù)中不同層的神經(jīng)網(wǎng)絡(luò)對圖像信息的抽取,我們可以看到在學(xué)習(xí)過程中底層網(wǎng)絡(luò)主要是對圖像中局部紋理進行捕捉,而隨著層數(shù)的遞增,模型開始根據(jù)下層中收集到的紋理信息對人臉中的局部結(jié)構(gòu)(如眼睛、耳朵等)進行建模,而頂層將綜合上述局部特征對人臉在圖像中的位置進行確定,最終達成人臉識別的目的。
人臉識別任務(wù)中不同層對圖像信息的提取差異
此外,對于前文提到的情感分析任務(wù)而言,同樣是可以使用深度學(xué)習(xí)的方式對語言進行建模。相對基于傳統(tǒng)機器學(xué)習(xí)算法的模型而言,深度學(xué)習(xí)的方式直接接收文本的輸入,將詞匯以高維向量的方式建模為詞嵌入(word embedding)。這種方法利用高維空間對詞匯中語義信息進行捕獲,從而為下一步的情感分析提供了非常充足的信息。
基于深度學(xué)習(xí)的情感分析模型在IMDB Movie Reviews數(shù)據(jù)集上遠遠超越了傳統(tǒng)的機器學(xué)習(xí)方法,在卡內(nèi)基梅隆大學(xué)與谷歌團隊在NIPS 2019上合作發(fā)表的論文XLNet: Generalized Autoregressive Pretraining for Language Understanding【5】中,準確率達到了96.8%。
從上述例子中可以看到,深度學(xué)習(xí)技術(shù)在如今的機器學(xué)習(xí)領(lǐng)域已然達成諸多優(yōu)異成績,其中非常重要的一個貢獻在于通過使用自動提取的方式對初始輸入信息中的有效資訊進行捕獲,大幅度降低了手動設(shè)計特征所帶來的信息折損,為下游任務(wù)提供了更堅實的基礎(chǔ)。
深度學(xué)習(xí)&網(wǎng)絡(luò)結(jié)構(gòu)搜索
深度學(xué)習(xí)技術(shù)的到來使得原本由人工進行的特征提取過程交由機器自動完成,允許模型根據(jù)自身需求從原始數(shù)據(jù)中進行特征的捕獲,通過這種數(shù)據(jù)驅(qū)動的方式有效降低了人工抽取所帶來的信息丟失風(fēng)險。但當我們回顧整個深度學(xué)習(xí)系統(tǒng),實際上其依舊并非我們期望的完全自動化的過程,在模型結(jié)構(gòu)的設(shè)計上仍然非常依賴行業(yè)專家面向任務(wù)對模型結(jié)構(gòu)進行設(shè)計。
以機器翻譯任務(wù)為例,研究人員在模型結(jié)構(gòu)上的探索腳步從未停止,從最初基于RNN【6】對文本序列進行表示發(fā)展到之后注意力機制【7】的引入,乃至更近一段時間的基于CNN【8】的翻譯系統(tǒng)以及目前備受關(guān)注的Transformer【9】系統(tǒng),科研人員始終在不斷地針對任務(wù)進行模型結(jié)構(gòu)的設(shè)計與改良。但有了深度學(xué)習(xí)初期的發(fā)展,研究人員也期望著有朝一日能夠讓模型結(jié)構(gòu)設(shè)計的過程同樣不再過分依賴人工設(shè)計,能夠采用同特征選擇類似的方式自動進行學(xué)習(xí),因此在深度學(xué)習(xí)方法的基礎(chǔ)上,人們開始嘗試網(wǎng)絡(luò)結(jié)構(gòu)搜索的方式來自動得到模型結(jié)構(gòu)。
實際上網(wǎng)絡(luò)結(jié)構(gòu)搜索的任務(wù)并非起源于近些年,早在上世紀80年代,斯坦福大學(xué)的Miller, Geoffrey F.等人在Designing Neural Networks using Genetic Algorithms【10】論文中就提出使用進化算法對神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)進行學(xué)習(xí)的方式,在此之后也有很多研究人員沿著該思路進行了相關(guān)的探索(如Representation and evolution of neural networks【11】一文對進化算法的編碼格式進行改良,J. R. Koza等人在Genetic generation of both the weights and architecture for a neural network【12】中提出要同時對網(wǎng)絡(luò)中的結(jié)構(gòu)和參數(shù)進行學(xué)習(xí)等)。
但受限于當時計算資源,針對神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)搜索的應(yīng)用場景較少,因此這方面的工作并沒有受到很多研究者的關(guān)注。而隨著近些年來神經(jīng)網(wǎng)絡(luò)以及深度學(xué)習(xí)的技術(shù)的廣泛應(yīng)用,對于網(wǎng)絡(luò)結(jié)構(gòu)自學(xué)習(xí)的需求也越來越大,與此同時發(fā)展迅猛的半導(dǎo)體技術(shù)也使得設(shè)備的算力、存儲能力大大提升,為網(wǎng)絡(luò)結(jié)構(gòu)搜索任務(wù)提供了必要的支持。
縱觀整個機器學(xué)習(xí)算法的發(fā)展過程,網(wǎng)絡(luò)結(jié)構(gòu)搜索任務(wù)的出現(xiàn)可以看作是歷史的必然。無論是數(shù)據(jù)資源的累積還是計算能力的提升,無一不在催生著數(shù)據(jù)驅(qū)動下的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計。雖然目前的網(wǎng)絡(luò)結(jié)構(gòu)搜索技術(shù)尚且處于比較初級的階段,其高資源消耗、模型結(jié)構(gòu)不穩(wěn)定等問題始終困擾著研究人員,但是其發(fā)展勢頭迅猛,在圖像、自然語言處理等領(lǐng)域均開始嶄露頭角。
可以預(yù)見的是,深度學(xué)習(xí)&網(wǎng)絡(luò)結(jié)構(gòu)搜索的組合將是把研究人員從模型工程的泥淖中救起的稻草,我們也相信網(wǎng)絡(luò)結(jié)構(gòu)搜索技術(shù)會終將為機器學(xué)習(xí)完成這場從“人工”到“自動”的終局突圍。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100792 -
機器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14886 -
自然語言處理
+關(guān)注
關(guān)注
1文章
618瀏覽量
13561
發(fā)布評論請先 登錄
相關(guān)推薦
【「具身智能機器人系統(tǒng)」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統(tǒng)」閱讀體驗】1.初步理解具身智能
【「具身智能機器人系統(tǒng)」閱讀體驗】1.全書概覽與第一章學(xué)習(xí)
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
【書籍評測活動NO.51】具身智能機器人系統(tǒng) | 了解AI的下一個浪潮!
【「時間序列與機器學(xué)習(xí)」閱讀體驗】全書概覽與時間序列概述
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)篇
【《大語言模型應(yīng)用指南》閱讀體驗】+ 俯瞰全書
多層感知機模型結(jié)構(gòu)
Al大模型機器人
智能制造能力成熟度模型是什么?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論