 百度自研AI芯片昆侖解讀 與國產處理器飛騰良好適配
百度自研AI芯片昆侖解讀 與國產處理器飛騰良好適配
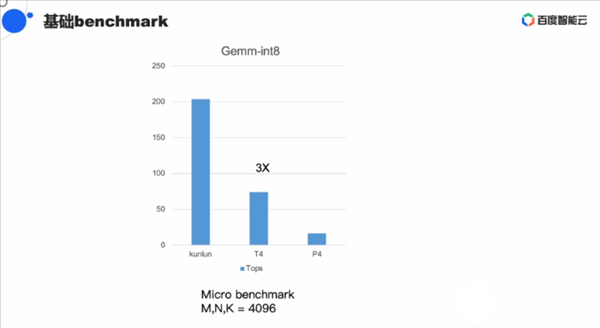
4月2日下午,百度智能芯片總經理歐陽劍在一場公開課中首次對昆侖芯片進行了詳細分享,并公開了昆侖K200與英特爾T4 GPU的多項對比數據,其中最有優勢的一項數據是Gemm-Int8 的Benchmark是T4性能的3倍。歐陽劍還通過視頻展示了昆侖芯片的殺手锏,與國產處理器飛騰的良好適配。
2018年的百度AI開發者大會上,百度創始人、董事長兼CEO李彥宏宣布推出自研AI芯片昆侖。百度研發AI芯片的積累得益于其用FPGA做AI加速的積累,也得益于其在軟件定義加速器和XPU架構的多年積累。
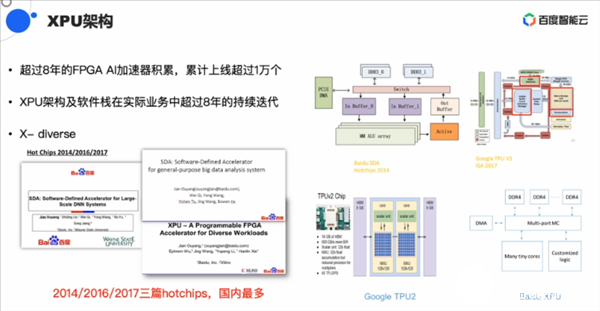
百度最早在2010年開始用FPGA做AI架構的研發,2011年開展小規模部署上線,2017年部署超過了10000片FPGA,2018年發布自主研發AI芯片,2019年下半年流片成功,2020年開始量產。
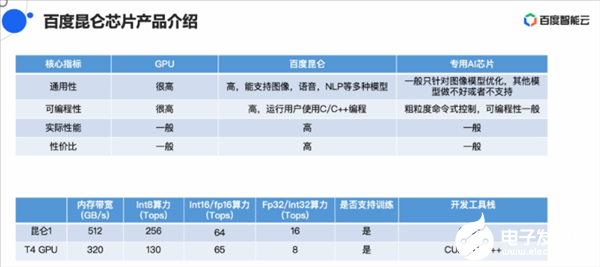
昆侖芯片的定位是通用AI芯片,目標是提供高性能、低成本、高靈活性的AI芯片。歐陽劍在分享中說:“相比GPU,昆侖芯片的通用性和可編程性都做的不錯,并且我們還在努力把編程性做的更好。”
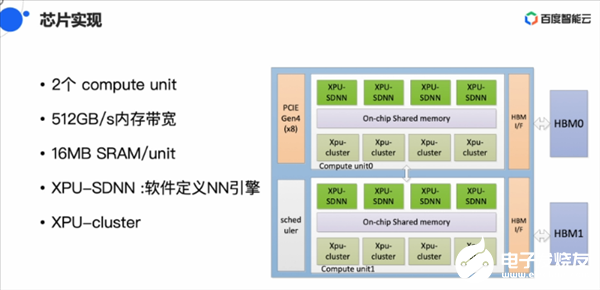
昆侖發布之后,其相關消息陸續公布。架構方面,昆侖有2個計算單元,512GB/S的內存帶寬,16MB SRAM/unit。歐陽劍介紹,16MB的SRAM對AI推理很有幫助,XPU架構上的XPU-SDNN是為Tensor等而設計,XPU-Cluster則能夠滿足通用處理的需求。
昆侖第一代芯片并沒有采用NVLink,而是通過PCIE 4.0接口進行互聯。在三星14nm的制造工藝和2.5D封裝的支持下,昆侖芯片峰值性能可以達到260TOPS,功耗為150W。
在靈活性和易用性方面,昆侖面向開發者提供類似英偉達CUDA的軟件棧,可以通過C/C++語言進行編程,降低開發者的開發難度。

目前,基于第一代昆侖芯片,百度推出了兩款AI加速卡,K100和K200,前者算力和功耗都是后者的兩倍。
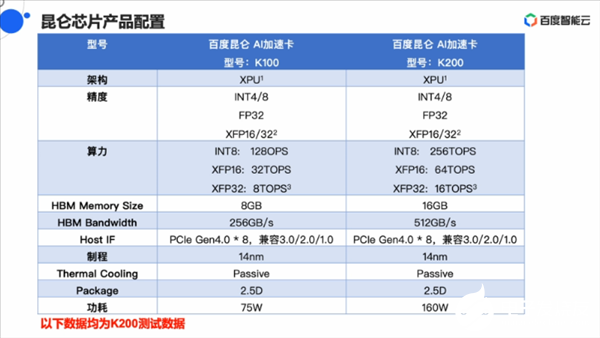
在今天的分享中,歐陽劍給出了一系列K200對比英偉達T4的數據,其中在Gemm-Int8數據類型,4K X 4K的矩陣下,昆侖K200的Benchmark分出超過2000,是英偉達T4的3倍多。
在語音常用的Bert/Ernie測試模型下,昆侖也有明顯性能優勢。

在線上性能數據的表現上,昆侖的表現相比英偉達T4更加穩定,且延遲也有優勢。

在圖像分割YOLOV3算法中,昆侖雖然有優勢,但優勢已經不那么明顯。不過歐陽劍表示百度仍然在通過持續的優化提高昆侖的性能。

他同時表示,昆侖已經在百度內部規模應用。至于對外提供AI算力,去年12月13日百度通過定向邀請的方式通過百度云提供昆侖的算力。在與歐陽劍的直播互動中,雷鋒網(公眾號:雷鋒網)了解到通過百度云提供昆侖AI算力目前仍然是定向邀請的方式,且主要是私有部署的方式。百度會通過定向邀請的客戶的反饋消息,再通過百度云大規模向外提供昆侖的算力,但他沒有給出具體的時間線。
除了通過百度云提供昆侖的算力,歐陽劍也展示了昆侖加速卡在工業智能設備中的應用。歐陽劍演示的是用CPU和昆侖加速卡去進行產品缺陷檢測,昆侖可以大幅提升速度,但并沒有給出具體的對比數據。
另外一個展示則是昆侖的殺手锏,那就是和國產處理器平臺飛騰的適配。在2019飛騰生態伙伴大會上,歐陽劍就透露昆侖AI芯片正在適配國產飛騰服務器,做性能調優工作。在今天的線上分享中,歐陽劍展示了采用昆侖加速卡帶來的圖像分割速度的顯著加速。
飛騰CPU處理器采用的是Armv8指令級,主要用在數據中心和云計算中心,作為國產芯的代表,昆侖選擇與飛騰進行很好地適配顯然是看中了國產自研芯片的大市場。
通過飛騰CPU+昆侖AI加速器的方式,雙方可以更好的實現國產芯片在服務器市場的國產化,也可以視為昆侖AI芯片和加速卡未來增長的一個重要動力和殺手锏。
責任編輯:wv
-
處理器
+關注
關注
68文章
19295瀏覽量
230001 -
百度
+關注
關注
9文章
2270瀏覽量
90432 -
AI芯片
+關注
關注
17文章
1887瀏覽量
35055
發布評論請先 登錄
相關推薦

百度小度將發布AI智能眼鏡
百度百舸AI計算平臺4.0震撼發布
國產DSP,自研指令集內核C2000,F28335、F280049、F28377
百度搜索AI生成內容占比達11%
2024百度移動生態萬象大會:百度新搜索11%內容已AI生成
日產汽車將搭載百度AI解決方案
百度搜索重磅推出AI圖片助手
百度將為蘋果新品提供AI功能
【有獎】 百度智能云度目推出首款多模態 AI 模組,應用場景有獎征集!
百度搜索推出AI拜年新能力






 工商網監
工商網監
評論