 數據湖是什么,它的快速搭建方法介紹
數據湖是什么,它的快速搭建方法介紹
(文章來源:ITPUB)
數據湖概念最早是在2011年提出,到現在也就9年左右的時間,算是一個較新的概念。雖然各方理解上有些差異,也存在一些爭議,但概念不重要,關鍵是否能真正幫助企業解決在業務快速發展過程中不斷遭遇的新問題。對于希望從數據資產中獲取更多經濟價值的企業而言,數據湖可能是一個可行的選擇。但對不少國內企業來說,數據湖顯然還是一個未知的領域。
數據顯示,全球數據湖市場在2019年的規模為37.4億美元,預計到2025年將達到176億美元,預計2020 - 2025年期間的復合年增長率為29.9%。在國外,尤其是北美,數據湖應用已經比較成熟,但在國內,還屬于初期階段。因此,第一次搭建數據湖,從哪里開始?如何成功搭建數據湖?對一些企業而言可能很難獲知,無論從時間還是投入上來說,試錯的成本都很高,那么,企業應該怎么做才能最大程度的降低風險并確保獲得回報?而這將是本文要探討的。
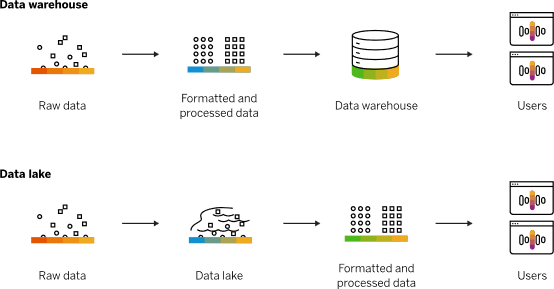
什么是數據湖,簡單的說,數據湖更像是數據倉庫的進化,比傳統數據倉庫涉及面更廣。但這并不是說數據湖能直接代替數據倉庫,兩者可以互補,大量案例顯示,數據倉庫作為數據湖的一類“數據應用”存在,協同工作。
眾所周知,傳統數據倉庫都是由數據庫發展而來,因此,無論是傳統的還是新型數據倉庫(分布式、云原生數倉),主要應用于結構化數據。而數據湖是多結構數據的存儲庫,無論是結構化、非結構化或半結構化數據,都能以其原始格式存儲,不需要進行初始轉換過程,因此,更加靈活,并且存儲與計算是分離的,數據存儲在便宜的對象存儲中,如Hadoop或Amazon S3,能更好的優化成本,而各種工具和服務(如Apache Presto、Elasticsearch和Amazon Athena)可以用來查詢這些數據。
數據湖的產生,源于大數據時代企業面臨的一系列挑戰,例如:數據孤島,分析各種數據集的難度,數據管理,數據安全等。而云計算、人工智能則是推動數據湖發展的重要因素,云計算提供了快速查詢、海量存儲的能力,而機器學習需要原始數據做分析,而用到的數據,也不止于結構化數據,用戶的評論、圖像這些非結構化數據,也都可以應用到機器學習中。目前,數據湖最為人所知的應用,當屬亞馬遜Galaxy(內部代號),如今已經成為了亞馬遜核心競爭力之一。
Galaxy數據湖建于2019年,構建的原因是亞馬遜運營團隊需要做大量的數據分析,但基于傳統的數據倉庫無法滿足擴展的需要,并且維護的復雜度和成本都很高。基于自身強大的技術能力,亞馬遜Galaxy實施了基于Amazon S3的數據湖方案,使用Amazon Redshift,Redshift Spectrum,和Amazon EMR運行分析的操作。下圖展示了Galaxy使用的一些AWS服務:Galaxy的部署,讓數據存儲量從50PB提升至100PB,在減少成本的同時加快了從數據中挖掘有用信息的速度。
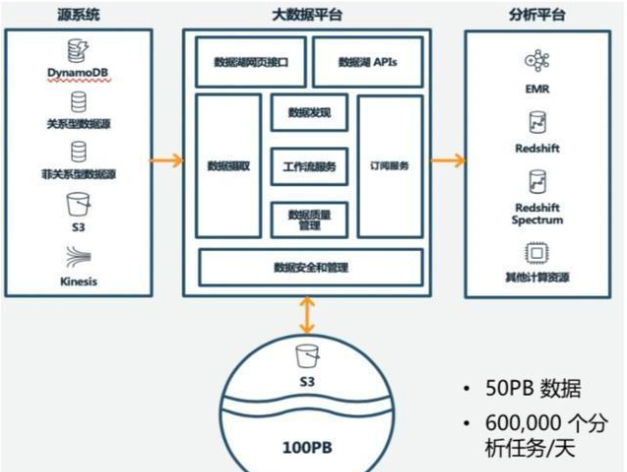
目前,每天在Galaxy上執行的分析任務高達60萬個,涉及各個方面,如為用戶推薦、運營信息、庫存信息、購買信息、物價信息等。再來看一個國內的應用,出海電商新秀Club Factory。Club Factory 是2016年由嘉云數據在杭州成立, 定位于創新型出口電商、輕自營跨境電商平臺。或許國內很多人都沒聽說過這家公司,但這家公司很厲害,手握的全球用戶已經超過1億,其APP在超過10個國家APP購物榜單排名前5,14個國家排名前10。
在數據湖的構建上,Club Factory采用了基于AWS數據湖的解決方案,通過使用數據湖來實現基于用戶在平臺上的所有行為做實時自動推薦,BI報表(內部運營、分析),供應鏈管理創新。據公開資料顯示,其數據湖平臺日均處理15億條行為數據分析,支撐80多位數據工程師的分析和算法需求,支撐180個活躍的數據分析調度任務,每日同步4000多個業務數據到數據倉庫,支撐的數據總量達到約600TB。
如何快速搭建數據湖?搭建數據湖無非2種選擇,一種是基于開源解決方案,一種是基于商業解決方案。開源解決方案的優勢是沒有授權成本,但有個前提,即你所在的企業得有一個能夠駕馭開源技術的團隊,有能力自己解決問題。因為,開源解決方案通常都比較零散,不成系統。對于初次搭建數據湖的企業而言,復雜性很高,成功搭建難度大。基于商業的解決方案則相反,對于較小或剛開始使用數據湖的公司來說,基于公有云的數據湖解決方案實現數據湖的快速構建是可行的選擇。
不僅搭建和管理維護的復雜性降低,并且成本可監控。其次,基于云的數據湖解決方案技術成熟度更高。能得到更為成熟的技術環境支持,包括工具的多樣性。最后,可擴展性和安全也是重要原因之一。目前,數據湖已經在公有云上得到了完美的實現和應用,例如:可以基于Amazon S3、AWS Glue等多個基本云服務快速構建出一套數據湖服務 。近期,AWS宣布,AWS Glue、Amazon Athena在由西云數據運營的AWS中國(寧夏)區域正式上線。
AWS Glue是一種全托管的數據提取、轉換和加載 (ETL) 服務及元數據目錄。它的價值在于,能讓準備數據更容易加載數據到數據庫、數據倉庫和數據湖,用于數據分析。Amazon Athena則是一種交互式查詢服務,使用標準的SQL,可以直接對Amazon S3上的數據做交互查詢。而這兩種服務都是無服務器服務,意味著不需要管理基礎設施,只需要為運行的查詢付費。
官方已經給出了如何使用 AWS Glue 和 Amazon S3 構建數據湖基礎和如何使用Amazon Athena 分析數據的具體教程,本文就不再贅述。當然,如果你覺得這種方式還有些復雜,那么接下來的一項服務,可以重點關注。去年,AWS發布了一項名為AWS Lake Formation的新服務,進一步降低了數據湖搭建的門檻,該服務簡化了數據湖的創建過程,并在幾天(而不是幾個月)內構建一個安全的數據湖。
不過,該服務目前還未在中國正式推出。當然,你也可以視自身情況自行選擇其他供應商,本文推薦基于AWS數據湖解決方案來實現快速搭建數據湖,是因為,到目前為止,AWS數據湖/數據分析解決方案是最完整,提供服務最豐富的,也是成功案例最多的。
(責任編輯:fqj)
-
數據
+關注
關注
8文章
7128瀏覽量
89365 -
云計算
+關注
關注
39文章
7852瀏覽量
137684
發布評論請先 登錄
相關推薦
電腦搭建虛擬云,電腦搭建虛擬云電腦的具體方法

蘋果電腦搭建私有云,蘋果電腦搭建私有云的詳細操作步驟
搭建家庭云平臺電腦,搭建家庭云平臺電腦的操作方法
舊電腦搭建私有云群暉,怎么用群暉搭建舊電腦私有云

云電腦需要怎么去搭建,云電腦需要怎么快速去搭建
電腦怎么搭建云存儲,電腦怎么搭建云存儲的教程,個人云電腦是什么以及怎么連接
TI RF Transceiver EVM自動化環境搭建方法

滴水湖中國RISC-V產業論壇:去年推介10款芯片9款量產
pytorch環境搭建詳細步驟
什么是數據湖?數據湖和數據倉庫有什么區別?

巡湖護河聯合執法 解決通信是關鍵

華為推出全新數據湖解決方案及全閃存新品
揭秘湖倉一體:大數據演進的未來趨勢與影響






 工商網監
工商網監
評論