 詳解Redis主從復制和哨兵機制
詳解Redis主從復制和哨兵機制
1. Redis主從復制
1.1 Redis主從復制
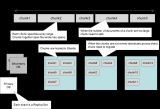
Redis主從復制主要有兩個角色,主機(master)對外提供讀寫功能,從機(slave)對外只提供讀功能,主機定期把數據同步到從機上保證數據一致性。
Redis主機數據同步到從機上有兩種方式,一種是全量同步,另一種是增量同步。
主從復制不會阻塞master,在數據同步時,master還可以繼續處理客戶端請求,因為redis會產生一個新的進程來解決同步問題。
一個redis也可以是從也可以是主(樹狀主從),可以減輕主機壓力。
1.2 Redis主從配置
只需要修改從服務器上的redis.conf文件:
# slaveof 《masterip》 《masterport》
# 表示當前【從服務器】對應的【主服務器】的IP是192.168.10.135,端口是6379。
slaveof 192.168.10.135 6379
啟動主服務器 redis-server redis.conf
進入從服務器文件夾,啟動從服務器
查看主服務器信息:redis-cli -p 6379 info Replication,可以看到有幾個從服務器
1.3 實現原理
redis的主從同步分為兩種,分為全量同步和增量同步。
只有從機第一次連接上主機是全量同步。
斷線重連很有可能觸發全量同步也有可能是增量同步(master判斷runid`是否一致)。
runid
每個redis服務器,不論主服務器還是從服務,都會有自己的運行id。PSYNC runid 這個命令,runid是指上一次復制主服務器的運行id,如果沒有保存這個id,PSYNC的命令會使用”PSYNC ? -1” 這種形式發送給Master,請求主服務器進行全量復制。
offset(復制偏移量)
主服務器和從服務器會分別維護一個復制偏移量,主服務器每次向從服務器傳播N個字節的數據時,就將自己的復制偏移量的值加上N,從服務器每次收到主服務器傳播來的N個字節的數據時,就將自己的復制偏移量值加上N。
復制積壓緩沖區
復制積壓緩沖區是由主服務器維護一個固定長度(fixed-size)先進先出(FIFO)隊列,默認大小是1MB。它主要的作用就是當主服務器進行命令傳播時,不僅將命令發送給所有從服務器,還會將命令入隊到復制積壓緩沖區。如果主服務器向從服務器傳播數據時發生斷線,主服務器會將復制積壓緩沖區偏移量的所有數據都發送給從服務器(發送的是斷線之后的的數據)。
PSYNC執行過程
1.Slave接受從客戶端發送過來的SLAVEOF命令。
當前服務器判斷自己是否保存Master runid是否是第一次復制。
如果是第一次復制那么當前服務器向Master發送PSYNC ? -1命令,主動請求Master進行全量同步。
如果已經父之過Master,那么當前從服務器向Master發送PSYNC runid offset命令。
Master接收到PSYNC 命令后首先判斷runid是否和本機的id一致,如果runid和本機id不一致則返回+FULLRESYNC runid offset命令執行全量同步操作,當前服務器會將runid保存起來,在下次發送PSUNC時使用。
如果判斷runid和本機id一致,Master則會再次判斷offset偏移量和本機的偏移量相差有沒有超過復制積壓緩沖區大小,如果沒有那么就給Slave發送CONTINUE,此時Slave只需要等待Master傳回失去連接期間丟失的命令;
全量同步
Redis的全量同步主要分為三個階段:
同步快照階段:Master創建并發送快照給Slave,Slave再入快照并解析。Master同時將此階段產生的新的命令寫入到積壓緩沖區中。
同步寫緩沖階段:Master向Slave同步存儲在緩沖區的寫操作命令。
同步增量階段:Master向SLave同步寫操作命令。
增量同步
Redis增量同步主要是指Slave完成初始化開始正常工作時,Master發生的寫操作同步到Slave的過程。
通常情況下,Master沒執行一個寫命令就會想Slave發送相同的寫命令,然后Slave接受并執行。
2. 哨兵(sentinel)機制
2.1 哨兵機制介紹
sentinel進程是用于監控Redis集群中Master主服務器工作的狀態。
在Master主服務器發生故障的時候,可以實現Master和Slave服務器的切換,保證系統的高可用。
2.2 為什么要有哨兵機制?
Redis主從復制的缺點:沒有辦法對master進行動態選舉,需要使用Sentinel機制完成動態選舉。
2.3 哨兵的作用
監控(Monitoring):sentinel會不斷檢查Master和Slave是否運行正常。
提醒(Notification):當被監控的某個Redis節點出現問題時, sentinel 可以通過 API向管理員或者其他應用程序發送通知。
自動故障轉移(Automatic failover):當Master不能正常操作時哨兵會開始一次故障轉移。 它會將失效的Master的其中一個Slave升級為新的Master,并讓其他Slave改為復制新的Master。 當客戶端試圖連接失效的Master時,集群會向客戶端顯示新的Master的地址。 Master和Slave切換后,Master的redis.conf、Slave的reids.conf和senisentinel的sentinel.conf配置文件的內容都會相應的改變,即,Master主服務器的redis.conf配置文件中會多一行slaveof的配置,sentinel.conf的監控目標會隨之調換。
2.4 故障判斷原理分析
每個sentinel進程每秒鐘一次的頻率向整個集群中Master、Slave以及其它Sentinel進程發送一個PING命令。
如果一個實例(instance)距離最后一次有效回復PING命令超過down-after-milliseconds選項所指定的值,這個實例會被sentinel進程標記為主觀下線(SDOWN)。
如果一個Master主服務器被標記為主觀下線(SDOWN),則正在監視這個Master主服務器的所有 Sentinel進程要以每秒一次的頻率確認Master主服務器的確進入了主觀下線狀態。
當有足夠數量的 Sentinel進程(大于等于配置文件指定的值)在指定的時間范圍內確認Master主服務器進入了主觀下線狀態(SDOWN), 則Master主服務器會被標記為客觀下線(ODOWN)。
在一般情況下, 每個 Sentinel進程會以每 10 秒一次的頻率向集群中的所有Master主服務器、Slave從服務器發送 INFO 命令。
當Master主服務器被 Sentinel進程標記為客觀下線(ODOWN)時,Sentinel進程向下線的 Master主服務器的所有 Slave從服務器發送 INFO 命令的頻率會從 10 秒一次改為每秒一次。
若沒有足夠數量的 Sentinel進程同意 Master主服務器下線, Master主服務器的客觀下線狀態就會被移除。若 Master主服務器重新向 Sentinel進程發送 PING 命令返回有效回復,Master主服務器的主觀下線狀態就會被移除。
-
服務器
+關注
關注
12文章
9205瀏覽量
85558 -
Redis
+關注
關注
0文章
376瀏覽量
10884
發布評論請先 登錄
相關推薦
華為云 Flexus 云服務器 X 實例:在 openEuler 系統下搭建 MySQL 主從復制
華為云Flexus X實例,Redis性能加速評測及對比
華為云 Flexus X 輕松實現 Redis 一主多從高效部署

Redis使用重要的兩個機制:Reids持久化和主從復制

Redis緩存與Memcached的比較
主從觸發器和邊沿觸發器的區別
Redis 開源協議調整,我們怎么辦?
Redis開源版與Redis企業版,怎么選用?

GaussDB(for Redis) 特性揭秘:多租戶管理

GaussDB(for Redis) 特性揭秘:大 key 治理

新版 Redis 不再“開源”,對使用者都有哪些影響?

MongoDB和Redis的技術特性






 工商網監
工商網監
評論