") 機器學習在現(xiàn)實世界中的真相
機器學習在現(xiàn)實世界中的真相
導讀
當你在現(xiàn)實世界中工作時,有幾個事實是你必須面對的,這也是本文的主要內(nèi)容。
上個月,我在一個親密的朋友聚會上做了一個非正式的演講,我把這個題目記下來。這篇文章主要是寫給那些使用機器學習來構(gòu)造東西的人,而不是那些研究機器學習的人,盡管后一組人會很好地傾聽這些真理并反省他們的工作。
0. 你不是一個科學家
是的,雖然你們的 title 是“科學家”,包括你們所有擁有博士學位的人,以及涉足這個行業(yè)的學者。但是,機器學習(以及其他人工智能應(yīng)用領(lǐng)域,如 NLP、視覺、語音……)是一門工程研究學科(與科學研究相對)。
你會問,科學研究和工程研究有什么區(qū)別?George A. Hazelrigg 在他的“HONING YOUR PROPOSAL WRITING SKILLS”中寫道:
一些科學家會學習如何制定研究計劃。很少有工程師是博士級別的工程師。讓我們先試著理解科學研究和工程研究之間的區(qū)別。對我來說,區(qū)別很明顯。科學家力圖了解大自然的本質(zhì),以了解其根本的本質(zhì)。為了做到這一點,科學家通常剝離無關(guān)的影響,深入到一個非常狹窄的自然元素。這就是我們所說的自然法則:能量和質(zhì)量是一樣的,每一個作用力都有一個大小相等、方向相反的反作用力,依此類推。有許多自然法則,它們隨時隨地都適用。工程師遵循自然法則。他們別無選擇。他們的目標是設(shè)計出在自然允許的范圍內(nèi)工作的東西。要做到這一點,他們必須能夠預測系統(tǒng)的行為。所以工程師們面臨的一個大問題是,我們?nèi)绾卫斫夂皖A測一個系統(tǒng)的行為,在這個系統(tǒng)中,所有的自然法則在任何時候都適用于任何地方。這是一個整合的問題,它就像找到一開始的規(guī)律一樣困難。每時每刻把所有的自然規(guī)律都考慮進去是不可能的。因此,工程師必須找到方法來確定哪些定律是重要的,哪些可以忽略,以及如何近似那些在時間和空間上都很重要的定律。工程師不僅僅是預測未來。他們做出的決定部分是基于他們的預測,因為他們知道自己的預測不可能既準確又確定。理解和應(yīng)用數(shù)學也很重要。這包括概率論、決策理論、博弈論、最優(yōu)化、控制理論和其他數(shù)學在工程決策環(huán)境中的應(yīng)用。這也是一個合理的工程研究領(lǐng)域。
作為 ML 的研究人員和實踐者,你必須考慮你擁有的數(shù)據(jù)的正確模型,而不是你擁有的模型的正確數(shù)據(jù)集(就像許多研究論文一樣)。如果你曾經(jīng)問過“這個模型的正確數(shù)據(jù)集是什么”,那么你并不是在現(xiàn)實世界中。到底什么是真實的世界?在現(xiàn)實世界中,你對要處理的數(shù)據(jù)是沒有選擇的。在這里,數(shù)據(jù)定義了問題,而不是相反。有時,在現(xiàn)實世界中,ML 實踐者創(chuàng)建了一個自己的世界作為他們的建模游樂場,從而假裝他們是“科學家”,例如“發(fā)明”一種用于做 NLP 的語言,或者通過簡化假設(shè)來創(chuàng)建封閉的環(huán)境來強化學習。這些研究得出了有趣的結(jié)果,但它們的范圍僅限于它們所來自的世界,即使研究人員喜歡在論文中把它們當作適用于現(xiàn)實世界的東西來兜售。在現(xiàn)實世界中,輸入的分布更有可能發(fā)生變化,長尾的“curve balls”不知從何而來,你并不總是有答案。
當你在現(xiàn)實世界中工作時,有幾個事實是你必須面對的,這也是本文的主要內(nèi)容。但這個開場白是必不可少的。如果你在現(xiàn)實世界中做 ML 研究,你是工程師而不是科學家。
1. 需要可以工作
雖然這聽起來很簡單,但我很驚訝有多少人,不管是新手還是有經(jīng)驗的人,都被一些聽起來很花哨的名字吸引住了,或者因為一些東西來自 DeepMind、OpenAI、斯坦福大學、麻省理工學院等等。如果你的模型確實只能夠在它們的環(huán)境和資源約束下處理他們的數(shù)據(jù)集和,那么現(xiàn)實世界將無情地拒絕它。arXiv 上的許多結(jié)果只能在少數(shù)數(shù)據(jù)集上工作,或者只能在只有谷歌基礎(chǔ)設(shè)施支持的百兆級 gpu 上工作。幫社區(qū)一個忙,不要再發(fā)布那些一般性的結(jié)果了。它必須能工作。這也是為什么我們今天不考慮在沒有卷積神經(jīng)網(wǎng)絡(luò)的計算機視覺中做任何事情,或者為什么我們很容易在序列模型中使用注意力的原因。它必須要能工作。
推測:這么多人,特別是 ML 的新手,被花哨的模型名稱沖昏了頭腦,迫不及待地想要嘗試它們,或者寫關(guān)于它們的博客帖子,等等。我覺得這就像一個初學寫作的人。他們認為使用華麗的詞語會使他們的寫作更好,但經(jīng)驗會告訴他們其他的。
2. 無論你如何努力,無論你的優(yōu)先級是什么,你都不能提高光速
緩存層次結(jié)構(gòu)已經(jīng)是固定的,你必須在這個前提下工作,網(wǎng)絡(luò)開銷會讓分布式訓練變慢,在向量中只能塞入那么多內(nèi)容,等等。
3. 只要有足夠的推力,豬就能飛得很高,然而,這并不一定是一個好主意
一個研究生或大型的超參數(shù)掃描器可以在一個巨大的數(shù)據(jù)中心中可以找到一組超參數(shù),可以讓非常復雜的模型工作得很好,甚至產(chǎn)生優(yōu)秀的結(jié)果。但沒有人在現(xiàn)實世界中調(diào)試那么大的模型。我在幫助公司管理他們的 ML 團隊時發(fā)現(xiàn)了一個秘密 — 大多數(shù)人不知道/不關(guān)心超參數(shù)調(diào)優(yōu)。
4. 生活中的一些事情,除非親身經(jīng)歷過,否則永遠不會被完全欣賞或理解
對于既不構(gòu)建生產(chǎn) ML 模型也不維護它們的人來說,機器學習中的某些東西是永遠無法完全理解的。再多的課件,再多的 mooc,再多的 Kaggling,都無法讓你為此做好準備。沒有什么可以替代部署模型、觀察用戶與模型的交互、處理代碼/模型分解等等。
5. 總是有可能將多個獨立的問題聚合成一個復雜的相互依賴的解決方案,在大多數(shù)情況下,這是一個壞主意
端到端學習在理論上聽起來是一個好主意,但是對于大多數(shù)部署場景,分段優(yōu)化的管道架構(gòu)將繼續(xù)存在。這并不意味著我們將完全沒有端到端系統(tǒng)(語音識別和機器翻譯有很好的端到端生產(chǎn)價值解決方案),但在大多數(shù)情況下,具有可觀察的調(diào)試路徑將勝過其他選擇。
6. 把一個問題轉(zhuǎn)移到別處,甚至是忽略它,都比解決它要容易得多
例如,在語音方面,聲學建模是困難的,但是你可以讓網(wǎng)絡(luò)在解決不同問題(例如語音識別)的方法中找出這些細節(jié)。在 NLP 中,很難進行正確的解析。但值得慶幸的是,對于 99%的現(xiàn)實任務(wù),我們可以不進行解析。
推論:除非迫不得已,否則不要解決問題。
7. 你總是要在一些事情上做權(quán)衡
速度 vs 內(nèi)存,電池壽命 vs 準確性,公平性 vs 準確性,易于實現(xiàn) vs 可維護性,……
8. 一切都比你想象的復雜
與購物時的價格沖擊類似,工作中也有“努力沖擊”。大多數(shù)經(jīng)驗豐富的研究人員和工程師都經(jīng)歷過“努力沖擊”,要么是因為他們低估了處理大型數(shù)據(jù)集的工程問題,要么是因為他們低估了正在與之搏斗的領(lǐng)域的復雜性,要么是因為他們低估了對手。大多數(shù)論文讓讀者讀起來覺得事情很簡單,而忽略了這背后是經(jīng)過了幾百萬次失敗才有的成功。因此,論文不是研究,而是做研究的結(jié)果。因為這個原因,你永遠可能通過閱讀論文來體驗做研究的過程。
9. 你永遠都會是準備不足
這可以和第 8 點結(jié)合起來,事實上任何遠程調(diào)用的成功的模型如果沒有適當?shù)挠媱潱伎赡苡捎谧陨淼某晒Χ罎ⅰ?/p>
10. 一個尺碼不可能適合所有人,你的模型會一直犯令人尷尬的錯誤,盡管你的出發(fā)點是好的
角落案例和長尾失敗模式將困擾你。值得慶幸的是,對于許多非關(guān)鍵的 ML 部署來說,這并不是什么大問題。最壞的情況下,它會成為一條搞笑的推文。但是,如果你在醫(yī)療保健或其他高風險情況下工作,ML 部署將因此成為一場噩夢。
11. 每一個舊的想法都會以不同的名字和不同的形式被再次提出,不管它是否有效
Schimdhuber 可能提出了一個更大的觀點。沒有人聽他的,像他一樣,我們把舊酒重新裝進新瓶子,被迫重復錯誤的歷史。
12. 達到完美不是因為沒有什么可以補充的,而是因為沒有什么可以去掉的
生活中的每件事都是如此,現(xiàn)實世界中的機器學習也是如此。唉,我們的會議回顧了他們對“新穎性”的嗜好,產(chǎn)生了不想要的 arxi -spam,其中包含了大量本來就不需要存在的垃圾。除非做“科學”能夠鼓勵宣傳什么是有效的,而不是什么是新的,否則我不認為這種情況會改變。
-
機器學習
+關(guān)注
關(guān)注
66文章
8421瀏覽量
132703
發(fā)布評論請先 登錄
相關(guān)推薦
【「具身智能機器人系統(tǒng)」閱讀體驗】+數(shù)據(jù)在具身人工智能中的價值
zeta在機器學習中的應(yīng)用 zeta的優(yōu)缺點分析
cmp在機器學習中的作用 如何使用cmp進行數(shù)據(jù)對比
什么是機器學習?通過機器學習方法能解決哪些問題?

eda在機器學習中的應(yīng)用
魯棒性在機器學習中的重要性
具身智能與機器學習的關(guān)系
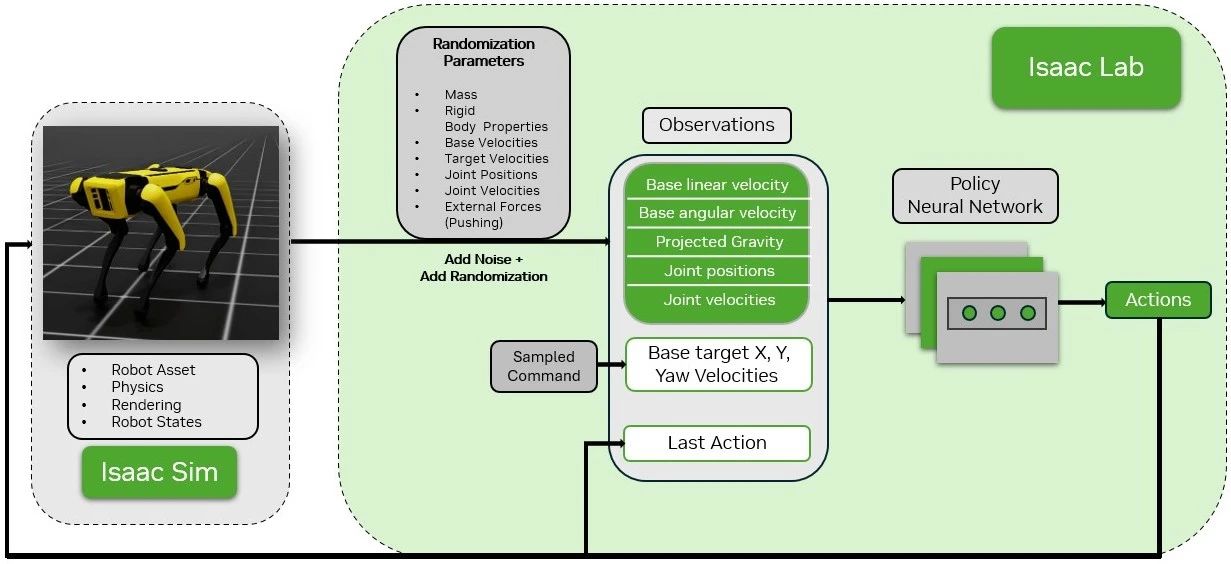
在NVIDIA Isaac Lab中訓練四足機器人運動





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論