") 實(shí)時(shí)數(shù)據(jù)體系建設(shè)的總體方案的三部分
實(shí)時(shí)數(shù)據(jù)體系建設(shè)的總體方案的三部分
隨著互聯(lián)網(wǎng)的發(fā)展進(jìn)入下半場(chǎng),數(shù)據(jù)的時(shí)效性對(duì)企業(yè)的精細(xì)化運(yùn)營(yíng)越來(lái)越重要, 商場(chǎng)如戰(zhàn)場(chǎng),在每天產(chǎn)生的海量數(shù)據(jù)中,如何能實(shí)時(shí)有效的挖掘出有價(jià)值的信息, 對(duì)企業(yè)的決策運(yùn)營(yíng)策略調(diào)整有很大幫助。
此外,隨著 5G 技術(shù)的成熟、廣泛應(yīng)用, 對(duì)于工業(yè)互聯(lián)網(wǎng)、物聯(lián)網(wǎng)等數(shù)據(jù)時(shí)效性要求非常高的行業(yè),企業(yè)就更需要一套完整成熟的實(shí)時(shí)數(shù)據(jù)體系來(lái)提高自身的行業(yè)競(jìng)爭(zhēng)力。
本文從上述現(xiàn)狀及實(shí)時(shí)數(shù)據(jù)需求出發(fā),結(jié)合工業(yè)界案例、筆者的實(shí)時(shí)數(shù)據(jù)開(kāi)發(fā)經(jīng)驗(yàn), 梳理總結(jié)了實(shí)時(shí)數(shù)據(jù)體系建設(shè)的總體方案,本文主要分為三個(gè)部分:
第一部分主要介紹了當(dāng)下在工業(yè)界比較火熱的實(shí)時(shí)計(jì)算引擎 Flink 在實(shí)時(shí)數(shù)據(jù)體系建設(shè)過(guò)程中主要的應(yīng)用場(chǎng)景及對(duì)應(yīng)解決方案;
第二部分從實(shí)時(shí)數(shù)據(jù)體系架構(gòu)、實(shí)時(shí)數(shù)據(jù)模型分層、實(shí)時(shí)數(shù)據(jù)體系建設(shè)方式、流批一體實(shí)時(shí)數(shù)據(jù)架構(gòu)發(fā)展等四個(gè)方面思考了實(shí)時(shí)數(shù)據(jù)體系的建設(shè)方案;
第三部分則以一個(gè)具體案例介紹如何使用 Flink SQL 完成實(shí)時(shí)數(shù)據(jù)統(tǒng)計(jì)類需求。
一、Flink 實(shí)時(shí)應(yīng)用場(chǎng)景
目前看來(lái),F(xiàn)link 在實(shí)時(shí)計(jì)算領(lǐng)域內(nèi)的主要應(yīng)用場(chǎng)景主要可分為四類場(chǎng)景, 分別是實(shí)時(shí)數(shù)據(jù)同步、流式 ETL、實(shí)時(shí)數(shù)據(jù)分析和復(fù)雜事件處理,具體的業(yè)務(wù)場(chǎng)景和對(duì)應(yīng)的解決方案可詳細(xì)研究下圖, 文字層面不再詳述。
二、實(shí)時(shí)數(shù)據(jù)體系架構(gòu)
實(shí)時(shí)數(shù)據(jù)體系大致分為三類場(chǎng)景:流量類、業(yè)務(wù)類和特征類,這三種場(chǎng)景各有不同。
在數(shù)據(jù)模型上,流量類是扁平化的寬表,業(yè)務(wù)數(shù)倉(cāng)更多是基于范式的建模,特征數(shù)據(jù)是 KV 存儲(chǔ);
從數(shù)據(jù)來(lái)源區(qū)分,流量數(shù)倉(cāng)的數(shù)據(jù)來(lái)源一般是日志數(shù)據(jù),業(yè)務(wù)數(shù)倉(cāng)的數(shù)據(jù)來(lái)源是業(yè)務(wù) binlog 數(shù)據(jù),特征數(shù)倉(cāng)的數(shù)據(jù)來(lái)源則多種多樣;
從數(shù)據(jù)量而言,流量和特征數(shù)倉(cāng)都是海量數(shù)據(jù),每天十億級(jí)以上,而業(yè)務(wù)數(shù)倉(cāng)的數(shù)據(jù)量一般每天百萬(wàn)到千萬(wàn)級(jí);
從數(shù)據(jù)更新頻率而言,流量數(shù)據(jù)極少更新,則業(yè)務(wù)和特征數(shù)據(jù)更新較多,流量數(shù)據(jù)一般關(guān)注時(shí)序和趨勢(shì),業(yè)務(wù)數(shù)據(jù)和特征數(shù)據(jù)關(guān)注狀態(tài)變更;
在數(shù)據(jù)準(zhǔn)確性上,流量數(shù)據(jù)要求較低,而業(yè)務(wù)數(shù)據(jù)和特征數(shù)據(jù)要求較高。
1、實(shí)時(shí)數(shù)據(jù)體系整體架構(gòu)
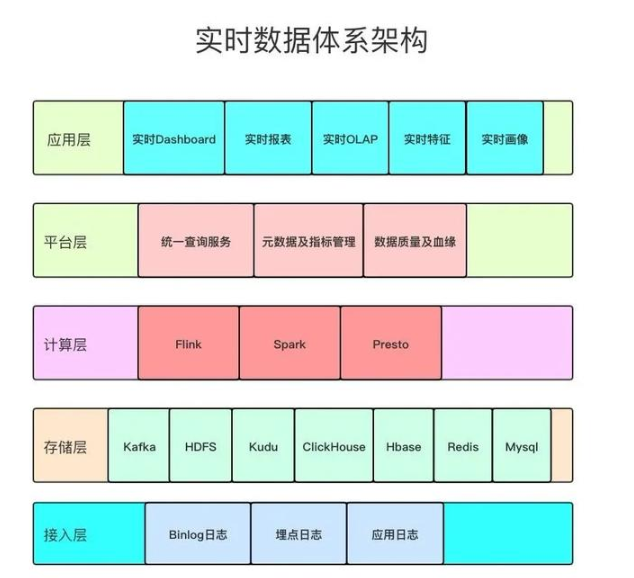
整個(gè)實(shí)時(shí)數(shù)據(jù)體系架構(gòu)分為五層,分別是接入層,存儲(chǔ)層,計(jì)算層、平臺(tái)層和應(yīng)用層,上圖只是整體架構(gòu)的概要圖,每一層具體要做的事情,接下來(lái)通過(guò)文字來(lái)詳述。
1)接入層:該層利用各種數(shù)據(jù)接入工具收集各個(gè)系統(tǒng)的數(shù)據(jù),包括 binlog 日志、埋點(diǎn)日志、以及后端服務(wù)日志,數(shù)據(jù)會(huì)被收集到 Kafka 中;這些數(shù)據(jù)不只是參與實(shí)時(shí)計(jì)算,也會(huì)參與離線計(jì)算,保證實(shí)時(shí)和離線的原始數(shù)據(jù)是統(tǒng)一的;
2)存儲(chǔ)層:該層對(duì)原始數(shù)據(jù)、清洗關(guān)聯(lián)后的明細(xì)數(shù)據(jù)進(jìn)行存儲(chǔ),基于統(tǒng)一的實(shí)時(shí)數(shù)據(jù)模型分層理念,將不同應(yīng)用場(chǎng)景的數(shù)據(jù)分別存儲(chǔ)在 Kafka、HDFS、Kudu、 Clickhouse、Hbase、Redis、Mysql 等存儲(chǔ)引擎中,各種存儲(chǔ)引擎存放的具體的數(shù)據(jù)類型在實(shí)時(shí)數(shù)據(jù)模型分層部分會(huì)詳細(xì)介紹;
3)計(jì)算層:計(jì)算層主要使用 Flink、Spark、Presto 以及 ClickHouse 自帶的計(jì)算能力等四種計(jì)算引擎,F(xiàn)link 計(jì)算引擎主要用于實(shí)時(shí)數(shù)據(jù)同步、 流式 ETL、關(guān)鍵系統(tǒng)秒級(jí)實(shí)時(shí)指標(biāo)計(jì)算場(chǎng)景,Spark SQL 主要用于復(fù)雜多維分析的準(zhǔn)實(shí)時(shí)指標(biāo)計(jì)算需求場(chǎng)景,Presto 和 ClickHouse 主要滿足多維自助分析、對(duì)查詢響應(yīng)時(shí)間要求不太高的場(chǎng)景;
4)平臺(tái)層:在平臺(tái)層主要做三個(gè)方面的工作,分別是對(duì)外提供統(tǒng)一查詢服務(wù)、元數(shù)據(jù)及指標(biāo)管理、數(shù)據(jù)質(zhì)量及血緣;
5)應(yīng)用層:以統(tǒng)一查詢服務(wù)對(duì)各個(gè)業(yè)務(wù)線數(shù)據(jù)場(chǎng)景進(jìn)行支持,業(yè)務(wù)主要包括實(shí)時(shí)大屏、實(shí)時(shí)數(shù)據(jù)產(chǎn)品、實(shí)時(shí) OLAP、實(shí)時(shí)特征等。
其中,平臺(tái)層詳細(xì)工作如下:
統(tǒng)一查詢服務(wù)支持從底層明細(xì)數(shù)據(jù)到聚合層數(shù)據(jù)的查詢,支持以SQL化方式查詢Redis、Hbase等KV存儲(chǔ)中的數(shù)據(jù);
元數(shù)據(jù)及指標(biāo)管理:主要對(duì)實(shí)時(shí)的Kafka表、Kudu表、Clickhouse表、Hive表等進(jìn)行統(tǒng)一管理,以數(shù)倉(cāng)模型中表的命名方式規(guī)范表的命名,明確每張表的字段含義、使用方,指標(biāo)管理則是盡量通過(guò)指標(biāo)管理系統(tǒng)將所有的實(shí)時(shí)指標(biāo)統(tǒng)一管理起來(lái),明確計(jì)算口徑,提供給不同的業(yè)務(wù)方使用;
數(shù)據(jù)質(zhì)量及血緣分析:數(shù)據(jù)質(zhì)量分為平臺(tái)監(jiān)控和數(shù)據(jù)監(jiān)控兩個(gè)部分,血緣分析則主要是對(duì)實(shí)時(shí)數(shù)據(jù)依賴關(guān)系、實(shí)時(shí)任務(wù)的依賴關(guān)系進(jìn)行分析。
平臺(tái)監(jiān)控部分一是對(duì)任務(wù)運(yùn)行狀態(tài)進(jìn)行監(jiān)控,對(duì)異常的任務(wù)進(jìn)行報(bào)警并根據(jù)設(shè)定的參數(shù)對(duì)任務(wù)進(jìn)行自動(dòng)拉起與恢復(fù),二是針對(duì) Flink 任務(wù)要對(duì) Kafka 消費(fèi)處理延遲進(jìn)行監(jiān)控并實(shí)時(shí)報(bào)警。
數(shù)據(jù)監(jiān)控則分為兩個(gè)部分:
首先流式 ETL 是整個(gè)實(shí)時(shí)數(shù)據(jù)流轉(zhuǎn)過(guò)程中重要的一環(huán),ETL 的過(guò)程中會(huì)關(guān)聯(lián)各種維表,實(shí)時(shí)關(guān)聯(lián)時(shí),定時(shí)對(duì)沒(méi)有關(guān)聯(lián)上的記錄上報(bào)異常日志到監(jiān)控平臺(tái),當(dāng)數(shù)量達(dá)到一定閾值時(shí)觸發(fā)報(bào)警;
其次,部分關(guān)鍵實(shí)時(shí)指標(biāo)采用了 lambda 架構(gòu),因此需要對(duì)歷史的實(shí)時(shí)指標(biāo)與離線 hive 計(jì)算的數(shù)據(jù)定時(shí)做對(duì)比,提供實(shí)時(shí)數(shù)據(jù)的數(shù)據(jù)質(zhì)量監(jiān)控,對(duì)超過(guò)閾值的指標(biāo)數(shù)據(jù)進(jìn)行報(bào)警。
為了配合數(shù)據(jù)監(jiān)控,需要做實(shí)時(shí)數(shù)據(jù)血緣,主要是梳理實(shí)時(shí)數(shù)據(jù)體系中數(shù)據(jù)依賴關(guān)系,以及實(shí)時(shí)任務(wù)的依賴關(guān)系,從底層ODS 到 DW 再到 DM,以及 DM 層被哪些模型用到, 將整個(gè)鏈條串聯(lián)起來(lái),這樣做在數(shù)據(jù)/任務(wù)主動(dòng)調(diào)整時(shí)可以通知關(guān)聯(lián)的下游,指標(biāo)異常時(shí)借助血緣定位問(wèn)題,同時(shí)基于血緣關(guān)系的分析,我們也能評(píng)估數(shù)據(jù)的應(yīng)用價(jià)值,核算數(shù)據(jù)的計(jì)算成本。
2、實(shí)時(shí)數(shù)據(jù)模型分層
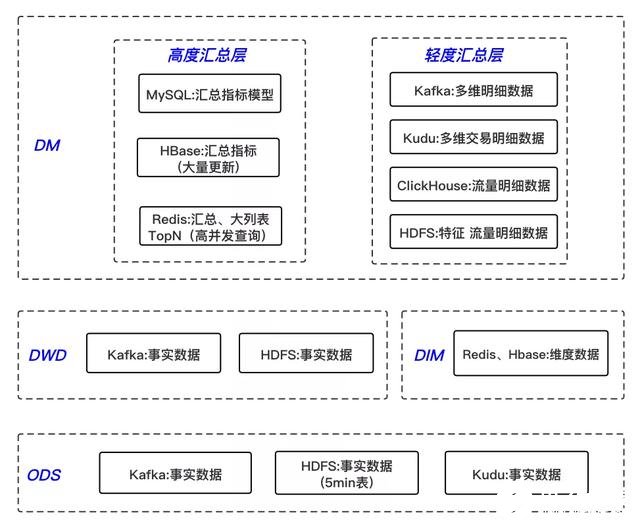
離線數(shù)倉(cāng)考慮到效率問(wèn)題,一般會(huì)采取空間換時(shí)間的方式,層級(jí)劃分會(huì)比較多;實(shí)時(shí)數(shù)倉(cāng)考慮到實(shí)時(shí)性問(wèn)題,分層則越少越好,另外也減少了中間流程出錯(cuò)的可能性,因此將其分為四層。
1)ODS 層
操作數(shù)據(jù)層,保存原始數(shù)據(jù),對(duì)非結(jié)構(gòu)化的數(shù)據(jù)進(jìn)行結(jié)構(gòu)化處理,輕度清洗,幾乎不刪除原始數(shù)據(jù)。
該層的數(shù)據(jù)主要來(lái)自業(yè)務(wù)數(shù)據(jù)庫(kù)的 binlog 日志、埋點(diǎn)日志和應(yīng)用程序日志。
對(duì)于 binlog 日志通過(guò) canal 監(jiān)聽(tīng),寫到消息隊(duì)列 Kafka 中,對(duì)應(yīng)于埋點(diǎn)和應(yīng)用程序日志,則通過(guò) Filebeat 采集 nginx 和 tomcat 日志,上報(bào)到Kafka 中。
除了存儲(chǔ)在 Kafka 中,同時(shí)也會(huì)對(duì)業(yè)務(wù)數(shù)據(jù)庫(kù)的 binlog 日志通過(guò) Flink 寫入 HDFS、Kudu 等存儲(chǔ)引擎,落地到 5min Hive 表,供查詢明細(xì)數(shù)據(jù),同時(shí)也提供給離線數(shù)倉(cāng),做為其原始數(shù)據(jù);另外,對(duì)于埋點(diǎn)日志數(shù)據(jù),由于 ODS 層是非結(jié)構(gòu)化的,則沒(méi)有必要落地。
2)DWD 層
實(shí)時(shí)明細(xì)數(shù)據(jù)層,以業(yè)務(wù)過(guò)程作為建模驅(qū)動(dòng),基于每個(gè)具體的業(yè)務(wù)過(guò)程特點(diǎn),構(gòu)建最細(xì)粒度的明細(xì)層事實(shí)表;可以結(jié)合企業(yè)的數(shù)據(jù)使用特點(diǎn),將明細(xì)事實(shí)表的某些重要維度屬性字段做適當(dāng)冗余,也即寬表化處理。
該層的數(shù)據(jù)來(lái)源于 ODS 層,通過(guò)簡(jiǎn)單的 Streaming ETL 后得到,對(duì)于 binlog 日志的處理主要進(jìn)行簡(jiǎn)單的數(shù)據(jù)清洗、處理數(shù)據(jù)漂移,以及可能對(duì)多個(gè) ODS 層的表進(jìn)行 Streaming Join,對(duì)流量日志主要是做一些通用ETL 處理,將非結(jié)構(gòu)化的數(shù)據(jù)結(jié)構(gòu)化,關(guān)聯(lián)通用的維度字段。
該層的數(shù)據(jù)存儲(chǔ)在消息隊(duì)列 Kafka 中,同時(shí)也會(huì)用 Flink 實(shí)時(shí)寫入 Hive 5min 表,供查詢明細(xì)數(shù)據(jù),同時(shí)要提供給離線數(shù)倉(cāng),做為其原始數(shù)據(jù)。
3)DIM 層
公共維度層,基于維度建模理念思想,建立整個(gè)業(yè)務(wù)過(guò)程的一致性維度,降低數(shù)據(jù)計(jì)算口徑和算法不統(tǒng)一風(fēng)險(xiǎn)。
DIM 層數(shù)據(jù)來(lái)源于兩部分:一部分是Flink程序?qū)崟r(shí)處理ODS層數(shù)據(jù)得到,另外一部分是通過(guò)離線任務(wù)出倉(cāng)得到。
DIM 層維度數(shù)據(jù)主要使用 MySQL、Hbase、Redis 三種存儲(chǔ)引擎,對(duì)于維表數(shù)據(jù)比較少的情況可以使用 MySQL,對(duì)于單條數(shù)據(jù)大小比較小,查詢 QPS 比較高的情況,可以使用 Redis 存儲(chǔ),降低機(jī)器內(nèi)存資源占用,對(duì)于數(shù)據(jù)量比較大,對(duì)維表數(shù)據(jù)變化不是特別敏感的場(chǎng)景,可以使用HBase 存儲(chǔ)。
4)DM 層
①數(shù)據(jù)集市層
以數(shù)據(jù)域+業(yè)務(wù)域的理念建設(shè)公共匯總層,對(duì)于DM層比較復(fù)雜,需要綜合考慮對(duì)于數(shù)據(jù)落地的要求以及具體的查詢引擎來(lái)選擇不同的存儲(chǔ)方式,分為輕度匯總層和高度匯總層,同時(shí)產(chǎn)出,高度匯總層數(shù)據(jù)用于前端比較簡(jiǎn)單的KV查詢, 提升查詢性能,比如實(shí)時(shí)大屏,實(shí)時(shí)報(bào)表等,數(shù)據(jù)的時(shí)效性要求為秒級(jí),輕度匯總層Kafka中寬表實(shí)時(shí)寫入OLAP存儲(chǔ)引擎,用于前端產(chǎn)品復(fù)雜的OLAP查詢場(chǎng)景,滿足自助分析和產(chǎn)出復(fù)雜報(bào)表的需求,對(duì)數(shù)據(jù)的時(shí)效性要求可容忍到分鐘級(jí);
②輕度匯總層
輕度匯總層由明細(xì)層通過(guò)Streaming ETL得到,主要以寬表的形式存在,業(yè)務(wù)明細(xì)匯總是由業(yè)務(wù)事實(shí)明細(xì)表和維度表join得到,流量明細(xì)匯總是由流量日志按業(yè)務(wù)線拆分和維度表join得到。
輕度匯總層數(shù)據(jù)存儲(chǔ)比較多樣化,首先利用Flink實(shí)時(shí)消費(fèi)DWD層Kafka中明細(xì)數(shù)據(jù)join業(yè)務(wù)過(guò)程需要的維表,實(shí)時(shí)打?qū)捄髮懭朐搶拥腒afka中,以Json或PB格式存儲(chǔ)。
同時(shí)對(duì)多維業(yè)務(wù)明細(xì)匯總數(shù)據(jù)通過(guò)Flink實(shí)時(shí)寫入Kudu,用于查詢明細(xì)數(shù)據(jù)和更復(fù)雜的多維數(shù)據(jù)分析需求,對(duì)于流量數(shù)據(jù)通過(guò)Flink分別寫入HDFS和ClickHouse用于復(fù)雜的多維數(shù)據(jù)分析, 實(shí)時(shí)特征數(shù)據(jù)則通過(guò)Flink join維表后實(shí)時(shí)寫入HDFS,用于下游的離線ETL消費(fèi)。
對(duì)于落地Kudu和HDFS的寬表數(shù)據(jù),可用Spark SQL做分鐘級(jí)的預(yù)計(jì)算,滿足業(yè)務(wù)方復(fù)雜數(shù)據(jù)分析需求,提供分鐘級(jí)延遲的數(shù)據(jù),從而加速離線ETL過(guò)程的延遲, 另外隨著Flink SQL與Hive生態(tài)集成的不斷完善,可嘗試用Flink SQL做離線ETL和OLAP計(jì)算任務(wù)(Flink流計(jì)算基于內(nèi)存計(jì)算的特性,和presto非常類似,這使其也可以成為一個(gè)OLAP計(jì)算引擎),用一套計(jì)算引擎解決實(shí)時(shí)離線需求,從而實(shí)現(xiàn)批流統(tǒng)一。
對(duì)于Kudu中的業(yè)務(wù)明細(xì)數(shù)據(jù)、ClickHouse中的流量明細(xì)數(shù)據(jù),也可以滿足業(yè)務(wù)方的個(gè)性化數(shù)據(jù)分析需求,利用強(qiáng)大的OLAP計(jì)算引擎,實(shí)時(shí)查詢明細(xì)數(shù)據(jù),在10s量級(jí)的響應(yīng)時(shí)間內(nèi)給出結(jié)果,這類需求也即是實(shí)時(shí)OLAP需求,靈活性比較高。
③高度匯總層
高度匯總層由明細(xì)數(shù)據(jù)層或輕度匯總層通過(guò)聚合計(jì)算后寫入到存儲(chǔ)引擎中,產(chǎn)出一部分實(shí)時(shí)數(shù)據(jù)指標(biāo)需求,靈活性比較差。
計(jì)算引擎使用Flink Datastream API和Flink SQL,指標(biāo)存儲(chǔ)引擎根據(jù)不同的需求,對(duì)于常見(jiàn)的簡(jiǎn)單指標(biāo)匯總模型可直接放在MySQL里面,維度比較多的、寫入更新比較大的模型會(huì)放在HBase里面, 還有一種是需要做排序、對(duì)查詢QPS、響應(yīng)時(shí)間要求非常高、且不需要持久化存儲(chǔ)如大促活動(dòng)期間在線TopN商品等直接存儲(chǔ)在Redis里面。
在秒級(jí)指標(biāo)需求中,需要混用Lambda和Kappa架構(gòu),大部分實(shí)時(shí)指標(biāo)使用Kappa架構(gòu)完成計(jì)算,少量關(guān)鍵指標(biāo)(如金額相關(guān))使用Lambda架構(gòu)用批處理重新處理計(jì)算,增加一次校對(duì)過(guò)程。
總體來(lái)說(shuō) DM 層對(duì)外提供三種時(shí)效性的數(shù)據(jù):
首先是 Flink 等實(shí)時(shí)計(jì)算引擎預(yù)計(jì)算好的秒級(jí)實(shí)時(shí)指標(biāo),這種需求對(duì)數(shù)據(jù)的時(shí)效性要求非常高,用于實(shí)時(shí)大屏、計(jì)算維度不復(fù)雜的實(shí)時(shí)報(bào)表需求。
其次是 Spark SQL 預(yù)計(jì)算的延遲在分鐘級(jí)的準(zhǔn)實(shí)時(shí)指標(biāo), 該類指標(biāo)滿足一些比較復(fù)雜但對(duì)數(shù)據(jù)時(shí)效性要求不太高的數(shù)據(jù)分析場(chǎng)景,可能會(huì)涉及到多個(gè)事實(shí)表的join,如銷售歸因等需求。
最后一種則是不需要預(yù)計(jì)算,ad-hoc查詢的復(fù)雜多維數(shù)據(jù)分析場(chǎng)景,此類需求比較個(gè)性化,靈活性比較高,如果 OLAP 計(jì)算引擎性能足夠強(qiáng)大,也可完全滿足秒級(jí)計(jì)算需求的場(chǎng)景; 對(duì)外提供的秒級(jí)實(shí)時(shí)數(shù)據(jù)和另外兩種準(zhǔn)實(shí)時(shí)數(shù)據(jù)的比例大致為 3:7,絕大多數(shù)的業(yè)務(wù)需求都優(yōu)先考慮準(zhǔn)實(shí)時(shí)計(jì)算或 ad-hoc 方式,可以降低資源使用、提升數(shù)據(jù)準(zhǔn)確性,以更靈活的方式滿足復(fù)雜的業(yè)務(wù)場(chǎng)景。
3、實(shí)時(shí)數(shù)據(jù)體系建設(shè)方式
整個(gè)實(shí)時(shí)數(shù)據(jù)體系分為兩種建設(shè)方式,即實(shí)時(shí)和準(zhǔn)實(shí)時(shí)(它們的實(shí)現(xiàn)方式分別是基于流計(jì)算引擎和 ETL、OLAP 引擎,數(shù)據(jù)時(shí)效性則分別是秒級(jí)和分鐘級(jí)。
1)在調(diào)度開(kāi)銷方面,準(zhǔn)實(shí)時(shí)數(shù)據(jù)是批處理過(guò)程,因此仍然需要調(diào)度系統(tǒng)支持,調(diào)度頻率較高,而實(shí)時(shí)數(shù)據(jù)卻沒(méi)有調(diào)度開(kāi)銷。
2)在業(yè)務(wù)靈活性方面,因?yàn)闇?zhǔn)實(shí)時(shí)數(shù)據(jù)是基于 ETL 或 OLAP 引擎實(shí)現(xiàn),靈活性優(yōu)于基于流計(jì)算的方式。
3)在對(duì)數(shù)據(jù)晚到的容忍度方面,因?yàn)闇?zhǔn)實(shí)時(shí)數(shù)據(jù)可以基于一個(gè)周期內(nèi)的數(shù)據(jù)進(jìn)行全量計(jì)算,因此對(duì)于數(shù)據(jù)晚到的容忍度也是比較高的,而實(shí)時(shí)數(shù)據(jù)使用的是增量計(jì)算,對(duì)于數(shù)據(jù)晚到的容忍度更低一些。
4)在適用場(chǎng)景方面,準(zhǔn)實(shí)時(shí)數(shù)據(jù)主要用于有實(shí)時(shí)性要求但不太高、涉及多表關(guān)聯(lián)和業(yè)務(wù)變更頻繁的場(chǎng)景,如交易類型的實(shí)時(shí)分析,實(shí)時(shí)數(shù)據(jù)則更適用于實(shí)時(shí)性要求高、數(shù)據(jù)量大的場(chǎng)景,如實(shí)時(shí)特征、流量類型實(shí)時(shí)分析等場(chǎng)景。
4、流批一體實(shí)時(shí)數(shù)據(jù)架構(gòu)發(fā)展
從1990年 Inmon 提出數(shù)據(jù)倉(cāng)庫(kù)概念到今天,大數(shù)據(jù)架構(gòu)經(jīng)歷了從最初的離線大數(shù)據(jù)架構(gòu)、Lambda 架構(gòu)、Kappa 架構(gòu)以及 Flink 的火熱帶出的流批一體架構(gòu),數(shù)據(jù)架構(gòu)技術(shù)不斷演進(jìn),本質(zhì)是在往流批一體的方向發(fā)展,讓用戶能以最自然、最小的成本完成實(shí)時(shí)計(jì)算。
1)離線大數(shù)據(jù)架構(gòu):數(shù)據(jù)源通過(guò)離線的方式導(dǎo)入到離線數(shù)倉(cāng)中,下游應(yīng)用根據(jù)業(yè)務(wù)需求選擇直接讀取 DM 或加一層數(shù)據(jù)服務(wù),比如 MySQL 或 Redis,數(shù)據(jù)存儲(chǔ)引擎是 HDFS/Hive,ETL 工具可以是 MapReduce 腳本或 HiveSQL。數(shù)據(jù)倉(cāng)庫(kù)從模型層面分為操作數(shù)據(jù)層 ODS、數(shù)據(jù)倉(cāng)庫(kù)明細(xì)層 DWD、數(shù)據(jù)集市層 DM。
2)Lambda 架構(gòu):隨著大數(shù)據(jù)應(yīng)用的發(fā)展,人們逐漸對(duì)系統(tǒng)的實(shí)時(shí)性提出了要求,為了計(jì)算一些實(shí)時(shí)指標(biāo),就在原來(lái)離線數(shù)倉(cāng)的基礎(chǔ)上增加了一個(gè)實(shí)時(shí)計(jì)算的鏈路,并對(duì)數(shù)據(jù)源做流式改造(即把數(shù)據(jù)發(fā)送到消息隊(duì)列),實(shí)時(shí)計(jì)算去訂閱消息隊(duì)列,直接完成指標(biāo)增量的計(jì)算,推送到下游的數(shù)據(jù)服務(wù)中去,由數(shù)據(jù)服務(wù)層完成離線&實(shí)時(shí)結(jié)果的合并。
3)Kappa 架構(gòu):Lambda 架構(gòu)雖然滿足了實(shí)時(shí)的需求,但帶來(lái)了更多的開(kāi)發(fā)與運(yùn)維工作,其架構(gòu)背景是流處理引擎還不完善,流處理的結(jié)果只作為臨時(shí)的、近似的值提供參考。后來(lái)隨著 Flink 等流處理引擎的出現(xiàn),流處理技術(shù)成熟起來(lái),這時(shí)為了解決兩套代碼的問(wèn)題,LickedIn 的 Jay Kreps 提出了 Kappa 架構(gòu)。
4)流批一體架構(gòu):流批一體架構(gòu)比較完美的實(shí)現(xiàn)方式是采用流計(jì)算 + 交互式分析雙引擎架構(gòu),在這個(gè)架構(gòu)中,流計(jì)算負(fù)責(zé)的是基礎(chǔ)數(shù)據(jù),而交互式分析引擎是中心,流計(jì)算引擎對(duì)數(shù)據(jù)進(jìn)行實(shí)時(shí) ETL 工作,與離線相比,降低了 ETL 過(guò)程的 latency,交互式分析引擎則自帶存儲(chǔ),通過(guò)計(jì)算存儲(chǔ)的協(xié)同優(yōu)化, 實(shí)現(xiàn)高寫入 TPS、高查詢 QPS 和低查詢 latency ,從而做到全鏈路的實(shí)時(shí)化和 SQL 化,這樣就可以用批的方式實(shí)現(xiàn)實(shí)時(shí)分析和按需分析,并能快速的響應(yīng)業(yè)務(wù)的變化,兩者配合,實(shí)現(xiàn) 1 + 1 > 2 的效果;該架構(gòu)對(duì)交互式分析引擎的要求非常高,也許是未來(lái)大數(shù)據(jù)庫(kù)技術(shù)發(fā)展的一個(gè)重點(diǎn)和方向。
為了應(yīng)對(duì)業(yè)務(wù)方更復(fù)雜的多維實(shí)時(shí)數(shù)據(jù)分析需求,筆者目前在數(shù)據(jù)開(kāi)發(fā)中引入 Kudu這個(gè) OLAP 存儲(chǔ)引擎,對(duì)訂單等業(yè)務(wù)數(shù)據(jù)使用 Presto + Kudu 的計(jì)算方案也是在探索流批一體架構(gòu)在實(shí)時(shí)數(shù)據(jù)分析領(lǐng)域的可行性。此外,目前比較熱的數(shù)據(jù)湖技術(shù),如 Delta lake、Hudi 等支持在 HDFS 上進(jìn)行 upsert 更新,隨著其流式寫入、SQL 引擎支持的成熟,未來(lái)可以用一套存儲(chǔ)引擎解決實(shí)時(shí)、離線數(shù)據(jù)需求,從而減少多引擎運(yùn)維開(kāi)發(fā)成本。
三、Flink SQL 實(shí)時(shí)計(jì)算 UV 指標(biāo)
上一部分從宏觀層面介紹了如何建設(shè)實(shí)時(shí)數(shù)據(jù)體系,非常不接地氣,可能大家需要的只是一個(gè)具體的 case 來(lái)了解一下該怎么做,那么接下來(lái)用一個(gè)接地氣的案例來(lái)介紹如何實(shí)時(shí)計(jì)算 UV 數(shù)據(jù)。
大家都知道,在 ToC 的互聯(lián)網(wǎng)公司,UV 是一個(gè)很重要的指標(biāo),對(duì)于老板、商務(wù)、運(yùn)營(yíng)的及時(shí)決策會(huì)產(chǎn)生很大的影響,筆者在電商公司,目前主要的工作就是計(jì)算 UV、銷售等各類實(shí)時(shí)數(shù)據(jù),體驗(yàn)就特別深刻, 因此就用一個(gè)簡(jiǎn)單demo 演示如何用 Flink SQL 消費(fèi) Kafka 中的 PV 數(shù)據(jù),實(shí)時(shí)計(jì)算出 UV 指標(biāo)后寫入 Hbase。
1、Kafka 源數(shù)據(jù)解析
PV 數(shù)據(jù)來(lái)源于埋點(diǎn)數(shù)據(jù)經(jīng) FileBeat 上報(bào)清洗后,以 ProtoBuffer 格式寫入下游 Kafka,消費(fèi)時(shí)第一步要先反序列化 PB 格式的數(shù)據(jù)為 Flink 能識(shí)別的 Row 類型,因此也就需要自定義實(shí)現(xiàn) DeserializationSchema 接口,具體如下代碼, 這里只抽取計(jì)算用到的 PV 的 mid、事件時(shí)間 time_local,并從其解析得到 log_date 字段:
publicclassPageViewDeserializationSchemaimplementsDeserializationSchema{
publicstaticfinalLoggerLOG=LoggerFactory.getLogger(PageViewDeserializationSchema.class);
protectedSimpleDateFormatdayFormatter;
privatefinalRowTypeInforowTypeInfo;
publicPageViewDeserializationSchema(RowTypeInforowTypeInfo){
dayFormatter=newSimpleDateFormat("yyyyMMdd",Locale.UK);
this.rowTypeInfo=rowTypeInfo;
}
@Override
publicRowdeserialize(byte[]message)throwsIOException{
Rowrow=newRow(rowTypeInfo.getArity());
MobilePagemobilePage=null;
try{
mobilePage=MobilePage.parseFrom(message);
Stringmid=mobilePage.getMid();
row.setField(0,mid);
LongtimeLocal=mobilePage.getTimeLocal();
StringlogDate=dayFormatter.format(timeLocal);
row.setField(1,logDate);
row.setField(2,timeLocal);
}catch(Exceptione){
StringmobilePageError=(mobilePage!=null)?mobilePage.toString():"";
LOG.error("errorparsebytespayloadis{},pageviewerroris{}",message.toString(),mobilePageError,e);
}
returnnull;
}
2、編寫 Flink Job 主程序
將 PV 數(shù)據(jù)解析為 Flink 的 Row 類型后,接下來(lái)就很簡(jiǎn)單了,編寫主函數(shù),寫 SQL 就能統(tǒng)計(jì) UV 指標(biāo)了,代碼如下:
publicclassRealtimeUV{
publicstaticvoidmain(String[]args)throwsException{
//step1從properties配置文件中解析出需要的Kakfa、Hbase配置信息、checkpoint參數(shù)信息
Mapconfig=PropertiesUtil.loadConfFromFile(args[0]);
Stringtopic=config.get("source.kafka.topic");
StringgroupId=config.get("source.group.id");
StringsourceBootStrapServers=config.get("source.bootstrap.servers");
StringhbaseTable=config.get("hbase.table.name");
StringhbaseZkQuorum=config.get("hbase.zk.quorum");
StringhbaseZkParent=config.get("hbase.zk.parent");
intcheckPointPeriod=Integer.parseInt(config.get("checkpoint.period"));
intcheckPointTimeout=Integer.parseInt(config.get("checkpoint.timeout"));
StreamExecutionEnvironmentsEnv=StreamExecutionEnvironment.getExecutionEnvironment();
//step2設(shè)置Checkpoint相關(guān)參數(shù),用于Failover容錯(cuò)
sEnv.getConfig().registerTypeWithKryoSerializer(MobilePage.class,
ProtobufSerializer.class);
sEnv.getCheckpointConfig().setFailOnCheckpointingErrors(false);
sEnv.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
sEnv.enableCheckpointing(checkPointPeriod,CheckpointingMode.EXACTLY_ONCE);
sEnv.getCheckpointConfig().setCheckpointTimeout(checkPointTimeout);
sEnv.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//step3使用Blinkplanner、創(chuàng)建TableEnvironment,并且設(shè)置狀態(tài)過(guò)期時(shí)間,避免JobOOM
EnvironmentSettingsenvironmentSettings=EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironmenttEnv=StreamTableEnvironment.create(sEnv,environmentSettings);
tEnv.getConfig().setIdleStateRetentionTime(Time.days(1),Time.days(2));
PropertiessourceProperties=newProperties();
sourceProperties.setProperty("bootstrap.servers",sourceBootStrapServers);
sourceProperties.setProperty("auto.commit.interval.ms","3000");
sourceProperties.setProperty("group.id",groupId);
//step4初始化KafkaTableSource的Schema信息,筆者這里使用registerTableSource的方式將源表注冊(cè)到Flink中,而沒(méi)有用registerDataStream方式,也是因?yàn)橄胧煜ひ幌氯绾巫?cè)KafkaTableSource到Flink中
TableSchemaschema=TableSchemaUtil.getAppPageViewTableSchema();
OptionalproctimeAttribute=Optional.empty();
ListrowtimeAttributeDescriptors=Collections.emptyList();
MapfieldMapping=newHashMap<>();
ListcolumnNames=newArrayList<>();
RowTypeInforowTypeInfo=newRowTypeInfo(schema.getFieldTypes(),schema.getFieldNames());
columnNames.addAll(Arrays.asList(schema.getFieldNames()));
columnNames.forEach(name->fieldMapping.put(name,name));
PageViewDeserializationSchemadeserializationSchema=new
PageViewDeserializationSchema(
rowTypeInfo);
MapspecificOffsets=newHashMap<>();
Kafka011TableSourcekafkaTableSource=newKafka011TableSource(
schema,
proctimeAttribute,
rowtimeAttributeDescriptors,
Optional.of(fieldMapping),
topic,
sourceProperties,
deserializationSchema,
StartupMode.EARLIEST,
specificOffsets);
tEnv.registerTableSource("pageview",kafkaTableSource);
//step5初始化HbaseTableSchema、寫入?yún)?shù),并將其注冊(cè)到Flink中
HBaseTableSchemahBaseTableSchema=newHBaseTableSchema();
hBaseTableSchema.setRowKey("log_date",String.class);
hBaseTableSchema.addColumn("f","UV",Long.class);
HBaseOptionshBaseOptions=HBaseOptions.builder()
.setTableName(hbaseTable)
.setZkQuorum(hbaseZkQuorum)
.setZkNodeParent(hbaseZkParent)
.build();
HBaseWriteOptionshBaseWriteOptions=HBaseWriteOptions.builder()
.setBufferFlushMaxRows(1000)
.setBufferFlushIntervalMillis(1000)
.build();
HBaseUpsertTableSinkhBaseSink=newHBaseUpsertTableSink(hBaseTableSchema,hBaseOptions,hBaseWriteOptions);
tEnv.registerTableSink("uv_index",hBaseSink);
//step6實(shí)時(shí)計(jì)算當(dāng)天UV指標(biāo)sql,這里使用最簡(jiǎn)單的groupbyagg,沒(méi)有使用minibatch或窗口,在大數(shù)據(jù)量?jī)?yōu)化時(shí)最好使用后兩種方式
StringuvQuery="insertintouv_index"
+"selectlog_date, "
+"ROW(count(distinctmid)asUV) "
+"frompageview "
+"groupbylog_date";
tEnv.sqlUpdate(uvQuery);
//step7執(zhí)行Job
sEnv.execute("UVJob");
}
}
以上就是一個(gè)簡(jiǎn)單的使用 Flink SQL 統(tǒng)計(jì) UV 的 case, 代碼非常簡(jiǎn)單,只需要理清楚如何解析 Kafka 中數(shù)據(jù),如何初始化 Table Schema,以及如何將表注冊(cè)到 Flink中,即可使用 Flink SQL 完成各種復(fù)雜的實(shí)時(shí)數(shù)據(jù)統(tǒng)計(jì)類的業(yè)務(wù)需求,學(xué)習(xí)成本比API 的方式低很多。
說(shuō)明一下,筆者這個(gè) demo 是基于目前業(yè)務(wù)場(chǎng)景而開(kāi)發(fā)的,在生產(chǎn)環(huán)境中可以真實(shí)運(yùn)行起來(lái),可能不能拆箱即用,你需要結(jié)合自己的業(yè)務(wù)場(chǎng)景自定義相應(yīng)的 kafka 數(shù)據(jù)解析類。
-
互聯(lián)網(wǎng)
+關(guān)注
關(guān)注
54文章
11154瀏覽量
103301 -
5G
+關(guān)注
關(guān)注
1354文章
48454瀏覽量
564219 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8889瀏覽量
137438
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
實(shí)時(shí)數(shù)據(jù)求差分
單電壓基準(zhǔn)與雙電壓基準(zhǔn)的對(duì)決-第三部分
基于多DSP互聯(lián)技術(shù)的頻譜監(jiān)測(cè)分析儀總體方案
在STM32中執(zhí)行中斷主要分三部分
在STM32中執(zhí)行中斷主要分三部分
TD-LTE規(guī)模試驗(yàn)網(wǎng)總體方案介紹
開(kāi)關(guān)電源設(shè)計(jì)(第3版)第三部分
2012年P(guān)SoC數(shù)模混合設(shè)計(jì)培訓(xùn)_第三部分
移動(dòng)通信行業(yè)的生態(tài)系統(tǒng)大致可以分成三部分
三部門印發(fā)國(guó)家車聯(lián)網(wǎng)產(chǎn)業(yè)標(biāo)準(zhǔn)體系建設(shè)指南

用于激活設(shè)備的可編程定時(shí)器-第三部分

硬件即代碼第三部分:空間與時(shí)間
SensorTile.box第三部分:編程模式(Pro mode)介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論