") 從hash算法的原理和實際應(yīng)用等幾個角度,對hash算法進行一個講解
從hash算法的原理和實際應(yīng)用等幾個角度,對hash算法進行一個講解
提到hash,相信大多數(shù)同學(xué)都不會陌生,之前很火現(xiàn)在也依舊很火的技術(shù)區(qū)塊鏈背后的底層原理之一就是hash,下面就從hash算法的原理和實際應(yīng)用等幾個角度,對hash算法進行一個講解。
1、什么是Hash
Hash也稱散列、哈希,對應(yīng)的英文都是Hash。基本原理就是把任意長度的輸入,通過Hash算法變成固定長度的輸出。這個映射的規(guī)則就是對應(yīng)的Hash算法,而原始數(shù)據(jù)映射后的二進制串就是哈希值。活動開發(fā)中經(jīng)常使用的MD5和SHA都是歷史悠久的Hash算法。
echomd5("這是一個測試文案"); //輸出結(jié)果:2124968af757ed51e71e6abeac04f98d
在這個例子里,這是一個測試文案是原始值,2124968af757ed51e71e6abeac04f98d 就是經(jīng)過hash算法得到的Hash值。整個Hash算法的過程就是把原始任意長度的值空間,映射成固定長度的值空間的過程。
2、Hash的特點
一個優(yōu)秀的hash算法,需要什么樣的要求呢?
a)、從hash值不可以反向推導(dǎo)出原始的數(shù)據(jù)
這個從上面MD5的例子里可以明確看到,經(jīng)過映射后的數(shù)據(jù)和原始數(shù)據(jù)沒有對應(yīng)關(guān)系
b)、輸入數(shù)據(jù)的微小變化會得到完全不同的hash值,相同的數(shù)據(jù)會得到相同的值
echomd5("這是一個測試文案"); //輸出結(jié)果:2124968af757ed51e71e6abeac04f98d echomd5("這是二個測試文案"); //輸出結(jié)果:bcc2a4bb4373076d494b2223aef9f702
可以看到我們只改了一個文字,但是整個得到的hash值產(chǎn)生了非常大的變化。
c)、哈希算法的執(zhí)行效率要高效,長的文本也能快速地計算出哈希值
d)、hash算法的沖突概率要小
由于hash的原理是將輸入空間的值映射成hash空間內(nèi),而hash值的空間遠(yuǎn)小于輸入的空間。根據(jù)抽屜原理,一定會存在不同的輸入被映射成相同輸出的情況。那么作為一個好的hash算法,就需要這種沖突的概率盡可能小。
桌上有十個蘋果,要把這十個蘋果放到九個抽屜里,無論怎樣放,我們會發(fā)現(xiàn)至少會有一個抽屜里面放不少于兩個蘋果。這一現(xiàn)象就是我們所說的“抽屜原理”。抽屜原理的一般含義為:“如果每個抽屜代表一個集合,每一個蘋果就可以代表一個元素,假如有n+1個元素放到n個集合中去,其中必定有一個集合里至少有兩個元素。” 抽屜原理有時也被稱為鴿巢原理。它是組合數(shù)學(xué)中一個重要的原理
3、Hash碰撞的解決方案
前面提到了hash算法是一定會有沖突的,那么如果我們?nèi)绻龅搅薶ash沖突需要解決的時候應(yīng)該怎么處理呢?比較常用的算法是鏈地址法和開放地址法。
3.1 鏈地址法
鏈表地址法是使用一個鏈表數(shù)組,來存儲相應(yīng)數(shù)據(jù),當(dāng)hash遇到?jīng)_突的時候依次添加到鏈表的后面進行處理。
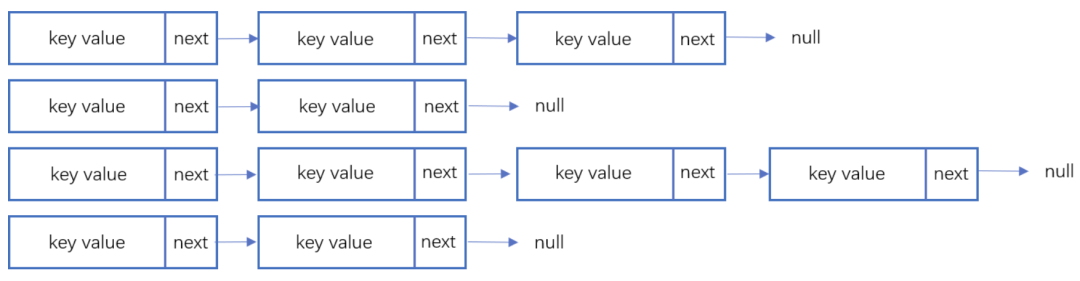
鏈地址法示意圖
鏈地址在處理的流程如下:
添加一個元素的時候,首先計算元素key的hash值,確定插入數(shù)組中的位置。如果當(dāng)前位置下沒有重復(fù)數(shù)據(jù),則直接添加到當(dāng)前位置。當(dāng)遇到?jīng)_突的時候,添加到同一個hash值的元素后面,行成一個鏈表。這個鏈表的特點是同一個鏈表上的Hash值相同。java的數(shù)據(jù)結(jié)構(gòu)HashMap使用的就是這種方法來處理沖突,JDK1.8中,針對鏈表上的數(shù)據(jù)超過8條的時候,使用了紅黑樹進行優(yōu)化。由于篇幅原因,這里不深入討論相關(guān)數(shù)據(jù)結(jié)構(gòu),有興趣的同學(xué)可以參考這篇文章:
《Java集合之一—HashMap》
3.2 開放地址法
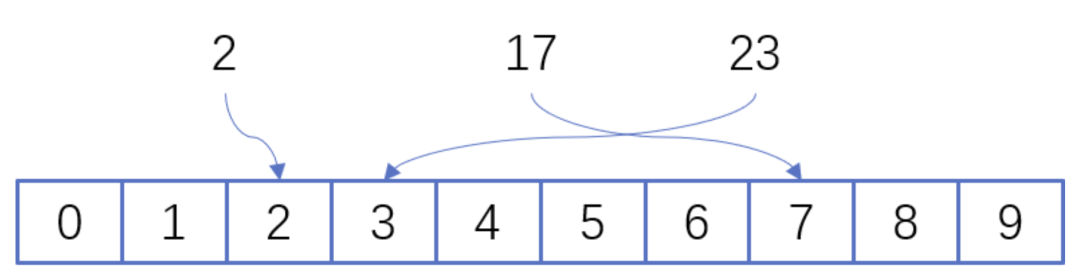
開放地址法是指大小為 M 的數(shù)組保存 N 個鍵值對,其中 M > N。我們需要依靠數(shù)組中的空位解決碰撞沖突。基于這種策略的所有方法被統(tǒng)稱為“開放地址”哈希表。線性探測法,就是比較常用的一種“開放地址”哈希表的一種實現(xiàn)方式。線性探測法的核心思想是當(dāng)沖突發(fā)生時,順序查看表中下一單元,直到找出一個空單元或查遍全表。簡單來說就是:一旦發(fā)生沖突,就去尋找下 一個空的散列表地址,只要散列表足夠大,空的散列地址總能找到。
線性探測法的數(shù)學(xué)描述是:h(k, i) = (h(k, 0) + i) mod m,i表示當(dāng)前進行的是第幾輪探查。i=1時,即是探查h(k, 0)的下一個;i=2,即是再下一個。這個方法是簡單地向下探查。mod m表示:到達了表的底下之后,回到頂端從頭開始。
對于開放尋址沖突解決方法,除了線性探測方法之外,還有另外兩種比較經(jīng)典的探測方法,二次探測(Quadratic probing)和雙重散列(Double hashing)。但是不管采用哪種探測方法,當(dāng)散列表中空閑位置不多的時候,散列沖突的概率就會大大提高。為了盡可能保證散列表的操作效率,一般情況下,我們會盡可能保證散列表中有一定比例的空閑槽位。我們用裝載因子(load factor)來表示空位的多少。
散列表的裝載因子=填入表中的元素個數(shù)/散列表的長度。裝載因子越大,說明沖突越多,性能越差。
3.3 兩種方案的demo示例
假設(shè)散列長為8,散列函數(shù)H(K)=K mod 7,給定的關(guān)鍵字序列為{32,14,23,2, 20}
當(dāng)使用鏈表法時,相應(yīng)的數(shù)據(jù)結(jié)構(gòu)如下圖所示:
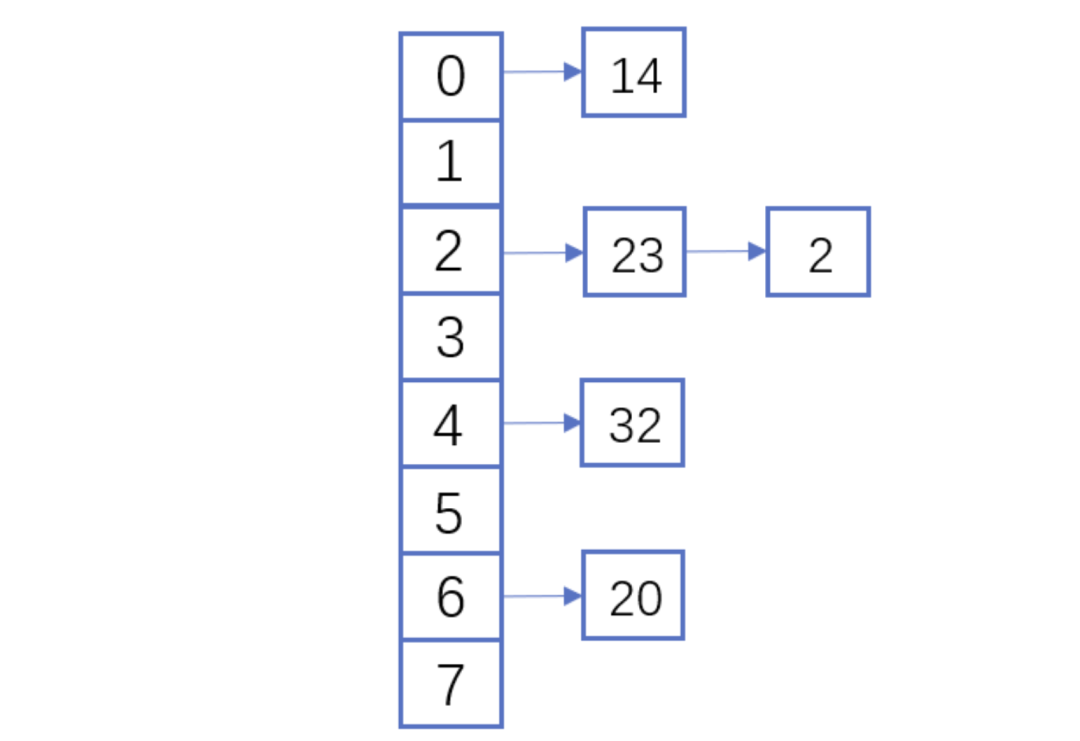
鏈表法demo
當(dāng)使用線性探測法時,相應(yīng)的數(shù)據(jù)結(jié)果如下圖所示:
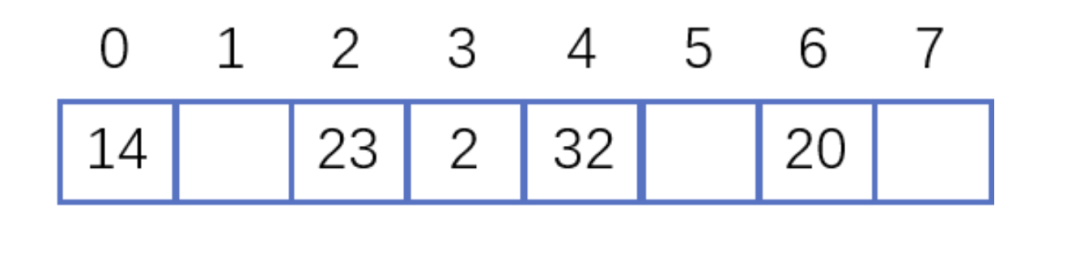
開放地址-線性探測法
這里的兩種算法的區(qū)別是2這個元素,在鏈表法中還是在節(jié)點2的位置上,但是在線性探測法遇到?jīng)_突時會將沖突數(shù)據(jù)放到下一個空的位置下面。
4、hash算法在日常活動中的應(yīng)用
在日常運營活動中,我們活動開發(fā)經(jīng)常遇到的應(yīng)用場景是信息加密、數(shù)據(jù)校驗、負(fù)載均衡。下面分別對這三種應(yīng)用場景進行講解。
4.1 信息加密
首先我們看一下信息加密的應(yīng)用。2011年CSDN脫庫事件,導(dǎo)致超過600W的用戶的密碼泄露,讓人失望的是,CSDN是明文存儲用戶的注冊郵箱和密碼的。作為用戶的非常隱私的信息,最簡單的保護措施就是對密碼進行hash加密。在客戶端對用戶輸入的密碼進行hash運算,然后在服務(wù)端的數(shù)據(jù)庫中保存用戶密碼的hash值。由于服務(wù)器端也沒有存儲密碼的明文,所以目前很多網(wǎng)站也就不再有找回密碼的功能了。
這里也友情提示一下大家:如果在使用中發(fā)現(xiàn)某網(wǎng)站還有提供找回密碼的功能,就要好好擔(dān)心下這個網(wǎng)站的安全性了。
看到這里有些同學(xué)會覺得那么我們是不是對用戶輸入的密碼進行一次MD5加密就可以了呢,這樣就算惡意用戶知道了hash值,也沒有辦法拿到用戶的真實密碼。假設(shè)用戶的密碼是123456789,經(jīng)過一次md5以后得到的值是:
25f9e794323b453885f5181f1b624d0b
那么是不是使用了這個加密后的字符串來存密碼就萬無一失了呢,理想總是很豐滿,而現(xiàn)實總是很骨感的。
大家可以看一下這個網(wǎng)站:
https://www.cmd5.com/
這里是該網(wǎng)站的相關(guān)介紹:
本站針對md5、sha1等全球通用公開的加密算法進行反向查詢,通過窮舉字符組合的方式,創(chuàng)建了明文密文對應(yīng)查詢數(shù)據(jù)庫,創(chuàng)建的記錄約90萬億條,占用硬盤超過500TB,查詢成功率95%以上,很多復(fù)雜密文只有本站才可查詢。已穩(wěn)定運行十余年,國內(nèi)外享有盛譽
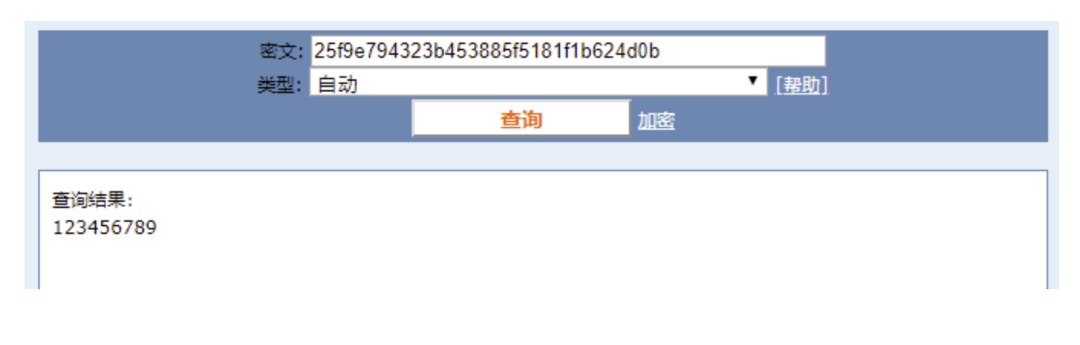
md5反查結(jié)果
那么一般針對這種問題,我們的解決之道就是引入salt(加鹽),即利用特殊字符(鹽)和用戶的輸入合在一起組成新的字符串進行加密。通過這樣的方式,增加了反向查詢的復(fù)雜度。但是這樣的方式也不是萬無一失,如果發(fā)生了鹽被泄露的問題,就需要所有用到的地方來重置密碼。
針對salt泄露的問題,其實還有一種解決辦法,即使用HMAC進行加密(Hash-based Message Authentication Code)。這種算法的核心思路是加密使用的key是從服務(wù)器端獲取的,每一個用戶的是不一樣的。如果發(fā)生了泄露,那么也就是這一個用戶的會被泄露,不會影響到全局。
這里也留給大家一個思考點,如果惡意用戶直接抓取了你的活動參與鏈接,也就是拿到了你計算后的hash值,那從技術(shù)的角度上說,我們還有沒有其他可以提升惡意用戶的違法成本呢?
4.2 數(shù)據(jù)校驗
-git commit id
使用過git的同學(xué)都應(yīng)該清楚,每次git提交后都有一個commit id,比如:
19d02d2cc358e59b3d04f82677dbf3808ae4fc40
就是一次git commit的結(jié)果,那么這個id是如何生成出來的呢?查閱了相關(guān)資料,使用如下代碼可以進行查看:
printf"commit%s"$(gitcat-filecommitHEAD|wc-c);gitcat-filecommitHEAD
git的commit id主要包括了以下幾部分內(nèi)容:Tree 哈希,parent哈希、作者信息和本次提交的備注。
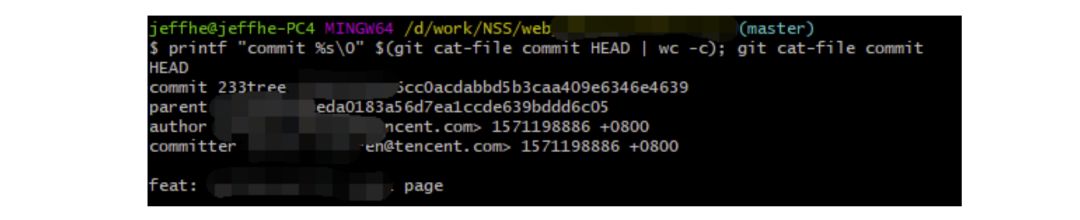
單次git commit相關(guān)信息
針對這些信息進行SHA-1 算法后得到值就是本次提交的commit id。簡單來講,就是對于單次提交的頭信息的一個校驗和。
Linux kernel開創(chuàng)者和Git的開發(fā)者——Linus說,Git使用了sha1并非是為了安全性,而是為了數(shù)據(jù)的完整性;它可以保證,在很多年后,你重新checkout某個commit時,一定是它多年前的當(dāng)時的狀態(tài),完全一摸一樣,完全值得信任。
但最新研究表明,理論上對其進行哈希碰撞(hash collision,不同的兩塊數(shù)據(jù)有相同的hash值)的攻擊可以在2^51(2的51次方)左右的次數(shù)內(nèi)實現(xiàn)。不過由于commit id 是針對單個倉庫里的,所以實際應(yīng)用中我們可以認(rèn)為如果兩個文件的SHA-1值是相同的,那么它們確是完全相同的內(nèi)容。
注:對于git里tree、parent等結(jié)構(gòu)感興趣的同學(xué),可以參考下這篇文章《Git 內(nèi)部原理 - Git 對象》,這里由于篇幅原因就不進行深入分析了。
版權(quán)校驗
在數(shù)據(jù)校驗方面的另一個應(yīng)用場景就是版權(quán)的保護或者違禁信息的打擊,比如某個小視頻,第一個用戶上傳的時候,我們認(rèn)為是版權(quán)所有者,計算一個hash值存下來。當(dāng)?shù)诙€用戶上傳的時候,同樣計算hash值,如果hash值一樣的話,就算同一個文件。這種方案其實也給用戶傳播違禁文件提高了一些門檻,不是簡單的換一個名字或者改一下后綴名就可以躲避掉打擊了。(當(dāng)然這種方式也是可以繞過的,圖片的你隨便改一下顏色,視頻去掉一幀就又是完全不同的hash值了。注意:我沒有教你變壞,我只是和你在討論這個技術(shù)。。。)另外我們在社區(qū)里,也會遇到玩家重復(fù)上傳同一張圖片或者視頻的情況,使用這種校驗的方式,可以有效減少cos服務(wù)的存儲空間。
大文件分塊校驗
使用過bt的同學(xué)都有經(jīng)驗,在p2p網(wǎng)絡(luò)中會把一個大文件拆分成很多小的數(shù)據(jù)各自傳輸。這樣的好處是如果某個小的數(shù)據(jù)塊在傳輸過程中損壞了,只要重新下載這個塊就好。為了確保每一個小的數(shù)據(jù)塊都是發(fā)布者自己傳輸?shù)模覀兛梢詫γ恳粋€小的數(shù)據(jù)塊都進行一個hash的計算,維護一個hash List,在收到所有數(shù)據(jù)以后,我們對于這個hash List里的每一塊進行遍歷比對。這里有一個優(yōu)化點是如果文件分塊特別多的時候,如果遍歷對比就會效率比較低。可以把所有分塊的hash值組合成一個大的字符串,對于這個字符串再做一次Hash運算,得到最終的hash(Root hash)。在實際的校驗中,我們只需要拿到了正確的Root hash,即可校驗Hash List,也就可以校驗每一個數(shù)據(jù)塊了。
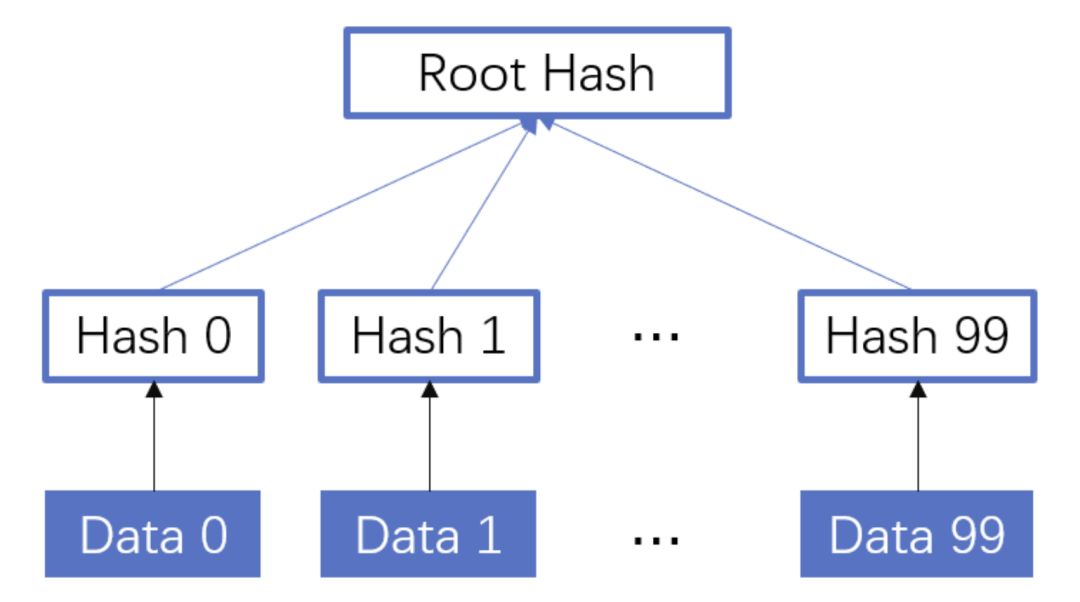
大文件分塊示意圖
4.3 負(fù)載均衡
活動開發(fā)同學(xué)在應(yīng)對高星級業(yè)務(wù)大用戶量參與時,都會使用分庫分表,針對用戶的openid進行hashtime33取模,就可以得到對應(yīng)的用戶分庫分表的節(jié)點了。
活動分庫分表示意圖
如上圖所示,這里其實是分了10張表,openid計算后的hash值取模10,得到對應(yīng)的分表,在進行后續(xù)處理就好。對于一般的活動或者系統(tǒng),我們一般設(shè)置10張表或者100張表就好。
下面我們來看一點復(fù)雜的問題,假設(shè)我們活動初始分表了10張,運營一段時間以后發(fā)現(xiàn)需要10張不夠,需要改到100張。這個時候我們?nèi)绻苯訑U容的話,那么所有的數(shù)據(jù)都需要重新計算Hash值,大量的數(shù)據(jù)都需要進行遷移。如果更新的是緩存的邏輯,則會導(dǎo)致大量緩存失效,發(fā)生雪崩效應(yīng),導(dǎo)致數(shù)據(jù)庫異常。造成這種問題的原因是hash算法本身的緣故,只要是取模算法進行處理,則無法避免這種情況。針對這種問題,我們就需要利用一致性hash進行相應(yīng)的處理了。
一致性hash的基本原理是將輸入的值hash后,對結(jié)果的hash值進行2^32取模,這里和普通的hash取模算法不一樣的點是在一致性hash算法里將取模的結(jié)果映射到一個環(huán)上。將緩存服務(wù)器與被緩存對象都映射到hash環(huán)上以后,從被緩存對象的位置出發(fā),沿順時針方向遇到的第一個服務(wù)器,就是當(dāng)前對象將要緩存于的服務(wù)器,由于被緩存對象與服務(wù)器hash后的值是固定的,所以,在服務(wù)器不變的情況下,一個openid必定會被緩存到固定的服務(wù)器上,那么,當(dāng)下次想要訪問這個用戶的數(shù)據(jù)時,只要再次使用相同的算法進行計算,即可算出這個用戶的數(shù)據(jù)被緩存在哪個服務(wù)器上,直接去對應(yīng)的服務(wù)器查找對應(yīng)的數(shù)據(jù)即可。這里的邏輯其實和直接取模的是一樣的。如下圖所示:
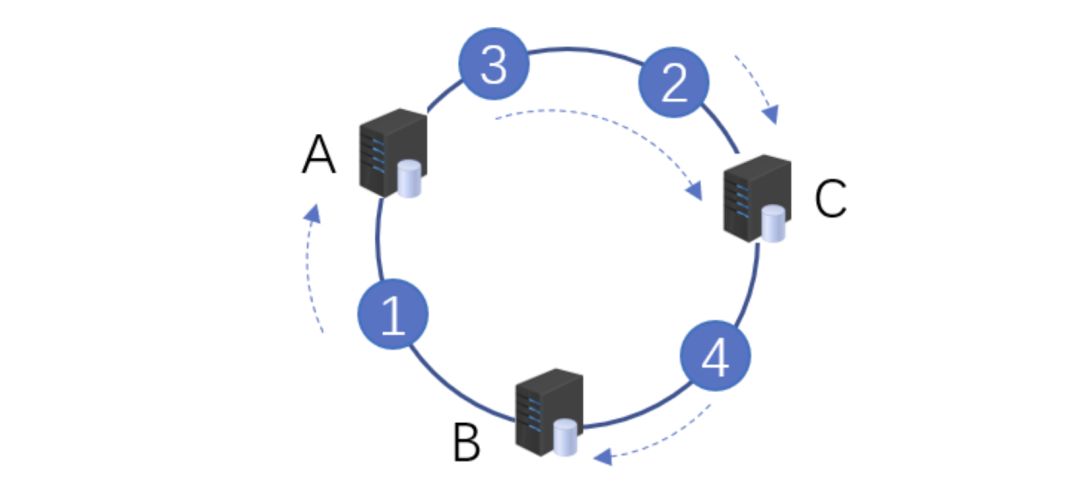
初始3臺機器的情況
初始情況如下:用戶1的數(shù)據(jù)在服務(wù)器A里,用戶2、3的數(shù)據(jù)存在服務(wù)器C里,用戶4的數(shù)據(jù)存儲在服務(wù)器B里
下面我們來看一下當(dāng)服務(wù)器數(shù)量發(fā)生變化的時候,相應(yīng)影響的數(shù)據(jù)情況:
服務(wù)器縮容
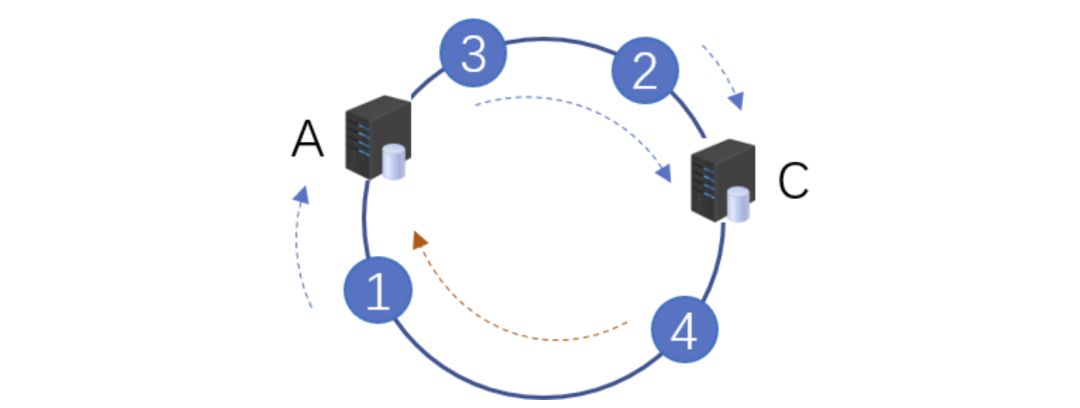
服務(wù)器縮容
服務(wù)器B發(fā)生了故障,進行剔除后,只有用戶4的數(shù)據(jù)發(fā)生了異常。這個時候我們需要繼續(xù)按照順時針的方案,把緩存的數(shù)據(jù)放在用戶A上面。
服務(wù)器擴容
同樣的,我們進行了服務(wù)器擴容以后,新增了一臺服務(wù)器D,位置落在用戶2和3之間。按照順時針原則,用戶2依然訪問的是服務(wù)器C的數(shù)據(jù),而用戶3順時針查詢后,發(fā)現(xiàn)最近的服務(wù)器是D,后續(xù)數(shù)據(jù)就會存儲到d上面。
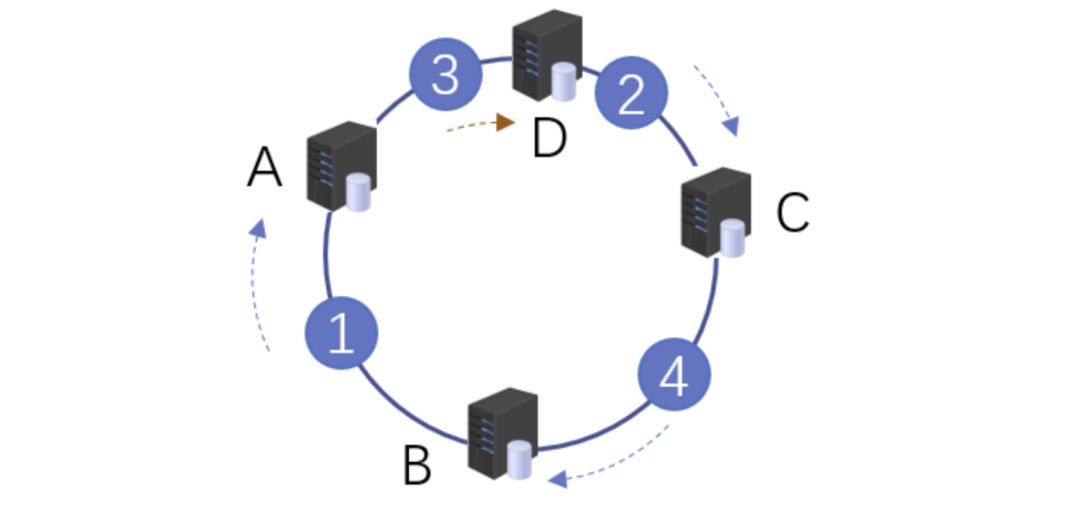
服務(wù)器擴容示意圖
虛擬節(jié)點
當(dāng)然這只是一種理想情況,實際使用中,由于服務(wù)器節(jié)點數(shù)量有限,有可能出現(xiàn)分布不均勻的情況。這個時候會出現(xiàn)大量數(shù)據(jù)都被映射到某一臺服務(wù)器的情況,如下圖左側(cè)所示。為了解決這個問題,我們采用了虛擬節(jié)點的方案。虛擬節(jié)點是實際節(jié)點(實際的物理服務(wù)器)在hash環(huán)上的復(fù)制品,一個實際節(jié)點可以對應(yīng)多個虛擬節(jié)點。虛擬節(jié)點越多,hash環(huán)上的節(jié)點就越多,數(shù)據(jù)被均勻分布的概率就越大。
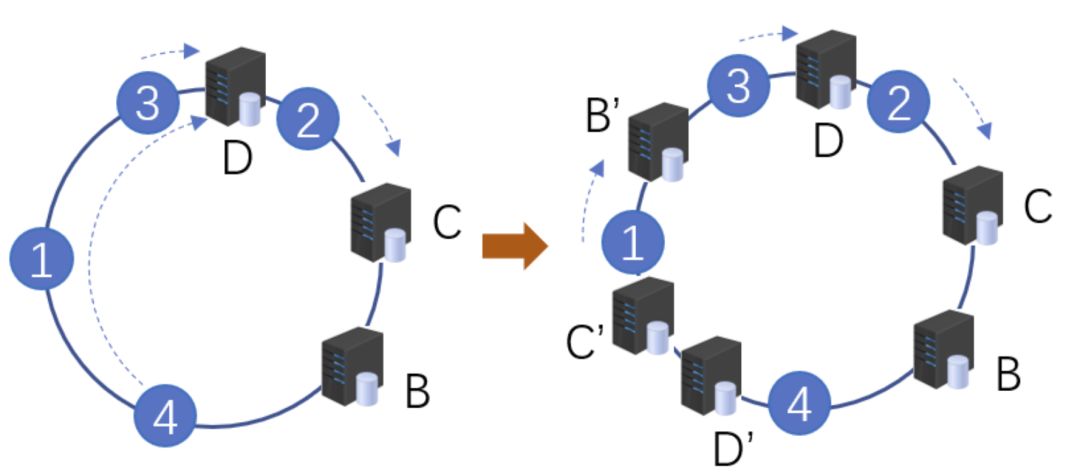
虛擬節(jié)點示意圖
如右圖所示,B、C、D 是原始節(jié)點復(fù)制出來的虛擬節(jié)點,原本都要訪問機器D的用戶1、4,分別被映射到了B,D。通過這樣的方式,起到了一個服務(wù)器均勻分布的作用。
5、幾種hash算法的擴展應(yīng)用
下面介紹幾種大家可能不經(jīng)常遇到的應(yīng)用,由于篇幅原因,不做深入介紹,只拋磚引玉。
5.1 SimHash
simHash是google用于海量文本去重的一種方法,它是一種局部敏感hash。那什么叫局部敏感呢,假定兩個字符串具有一定的相似性,在hash之后,仍然能保持這種相似性,就稱之為局部敏感hash。普通的hash是不具有這種屬性的。simhash被Google用來在海量文本中去重。
simHash算法的思路大致如下:
將Doc進行關(guān)鍵詞抽取(其中包括分詞和計算權(quán)重),抽取出n個(關(guān)鍵詞,權(quán)重)對, 即圖中的多個(feature, weight)。記為 feature_weight_pairs = [fw1, fw2 … fwn],其中 fwn = (feature_n,weight_n)。
對每個feature_weight_pairs中的feature進行hash。然后對hash_weight_pairs進行位的縱向累加,如果該位是1,則+weight,如果是0,則-weight,最后生成bits_count個數(shù)字,大于0標(biāo)記1,小于0標(biāo)記0
最后轉(zhuǎn)換成一個64位的字節(jié),判斷重復(fù)只需要判斷他們的特征字的距離是不是
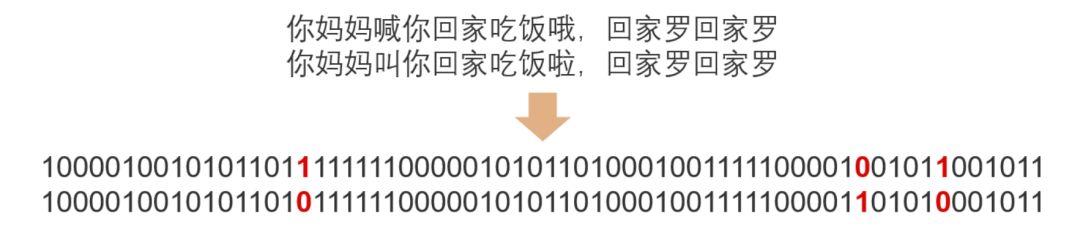
SimHash計算流程
如下圖所示,當(dāng)兩個文本只有一個字變化時,如果使用普通Hash則會導(dǎo)致兩次的結(jié)果發(fā)生較大改變,而SimHash的局部敏感特性,會導(dǎo)致只有部分?jǐn)?shù)據(jù)發(fā)生變化。
SimHash結(jié)果
5.2 GeoHash
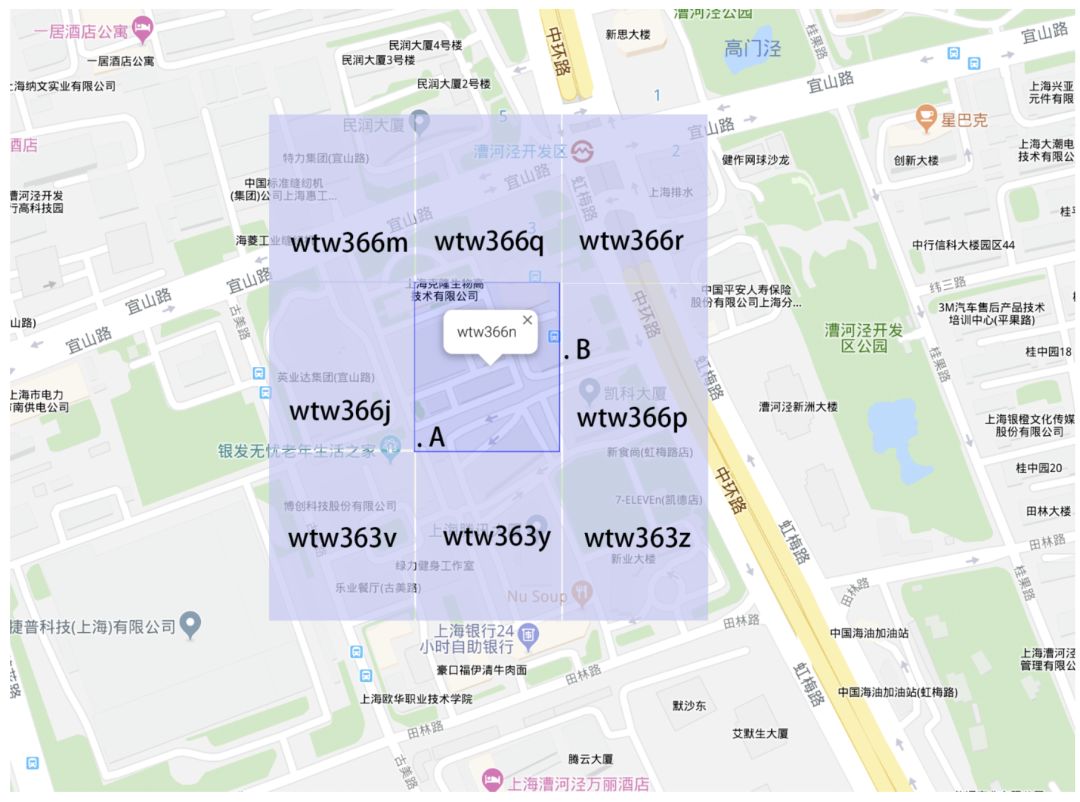
GeoHash將地球作為為一個二維平面進行遞歸分解。每個分解后的子塊在一定經(jīng)緯度范圍內(nèi)擁有相同的編碼。以下圖為例,這個矩形區(qū)域內(nèi)所有的點(經(jīng)緯度坐標(biāo))都共享相同的GeoHash字符串,這樣既可以保護隱私(只表示大概區(qū)域位置而不是具體的點),又比較容易做緩存。
GeoHash示意圖
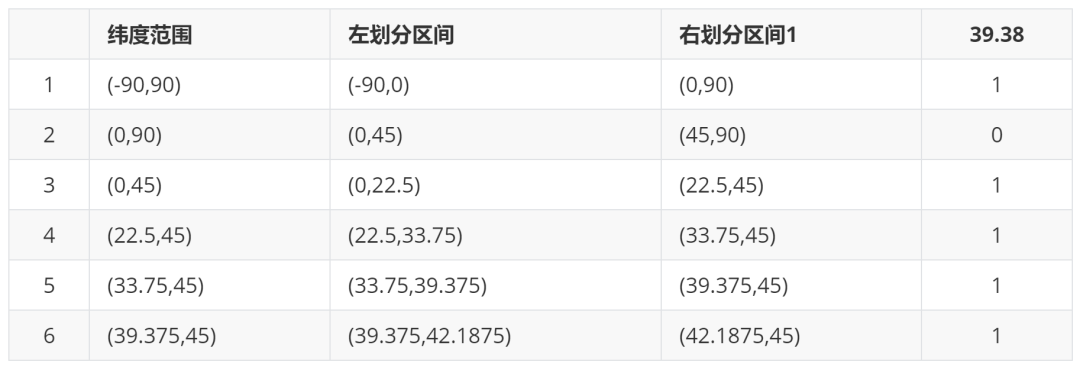
下面以一個例子來理解下這個算法,我們對緯度39.3817進行逼近編碼 :
地球緯度區(qū)間是[-90,90],對于這個區(qū)間進行二分劃分左區(qū)間[-90,0), 右區(qū)間[0,90]。39.3817屬于右區(qū)間,標(biāo)記為1
將右區(qū)間[0,90]繼續(xù)進行劃分,左區(qū)間[0,45) ,右區(qū)間[45,90]。39.3817屬于左區(qū)間,標(biāo)記為0
遞歸上面的過程,隨著每次迭代,區(qū)間[a,b]會不斷接近39.3817。遞歸的次數(shù)決定了生成的序列長度。
對于經(jīng)度做同樣的處理。得到的字符串,偶數(shù)位放經(jīng)度,奇數(shù)位放緯度,把2串編碼組合生成新串。對于新串轉(zhuǎn)成對應(yīng)10進制查出實際的base32編碼就是類似WX4ER的hash值。
整體遞歸過程如下表所示:
這里有一篇文章詳細(xì)介紹了GeoHash,有興趣的同學(xué)可以移步這里:
是什么能讓 APP 快速精準(zhǔn)定位到我們的位置?
5.3 布隆過濾器
布隆過濾器被廣泛用于黑名單過濾、垃圾郵件過濾、爬蟲判重系統(tǒng)以及緩存穿透問題。對于數(shù)量小,內(nèi)存足夠大的情況,我們可以直接用hashMap或者h(yuǎn)ashSet就可以滿足這個活動需求了。但是如果數(shù)據(jù)量非常大,比如5TB的硬盤上放滿了用戶的參與數(shù)據(jù),需要一個算法對這些數(shù)據(jù)進行去重,取得活動的去重參與用戶數(shù)。這種時候,布隆過濾器就是一種比較好的解決方案了。
布隆過濾器其實是基于bitmap的一種應(yīng)用,在1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數(shù),用于檢索一個元素是否在一個集合中。它的優(yōu)點是空間效率和查詢時間都遠(yuǎn)遠(yuǎn)超過一般的算法,缺點是有一定的誤識別率和刪除困難,主要用于大數(shù)據(jù)去重、垃圾郵件過濾和爬蟲url記錄中。核心思路是使用一個bit來存儲多個元素,通過這樣的方式來減少內(nèi)存的消耗。通過多個hash函數(shù),將每個數(shù)據(jù)都算出多個值,存放在bitmap中對應(yīng)的位置上。
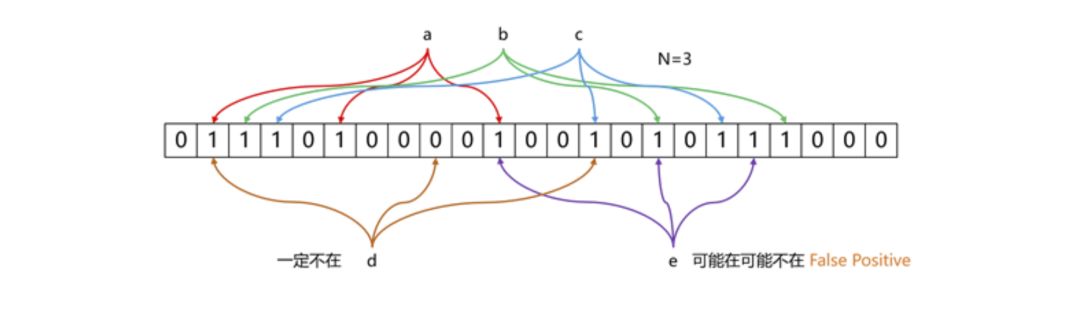
布隆過濾器的原理見下圖所示:
布隆過濾器原理示意
上圖所示的例子中,數(shù)據(jù)a、b、c經(jīng)過三次hash映射后,對應(yīng)的bit位都是1,表示這三個數(shù)據(jù)已經(jīng)存在了。而d這份數(shù)據(jù)經(jīng)過映射后有一個結(jié)果是0,則表明d這個數(shù)據(jù)一定沒有出現(xiàn)過。布隆過濾器存在假陽率(判定存在的元素可能不存在)的問題,但是沒有假陰率(判斷不存在的原因可能存在)的問題。即對于數(shù)據(jù)e,三次映射的結(jié)果都是1,但是這份數(shù)據(jù)也可能沒有出現(xiàn)過。
誤判率的數(shù)據(jù)公式如下所示:
其中,p是誤判率,n是容納的元素,m是需要的存儲空間。由公示可以看出,布隆過濾器的長度會直接影響誤報率,布隆過濾器越長其誤報率越小。哈希函數(shù)的個數(shù)也需要權(quán)衡,個數(shù)越多則布隆過濾器 bit 位置位 1 的速度越快,且布隆過濾器的效率越低;但是如果太少的話,則會導(dǎo)致誤報率升高。
6、總結(jié)
Hash算法作為一種活動開發(fā)經(jīng)常遇到的算法,我們在使用中不僅僅要知道這種算法背后真正的原理,才可以在使用上做到有的放矢。Hash的相關(guān)知識還有很多,有興趣的同學(xué)可以繼續(xù)深入研究。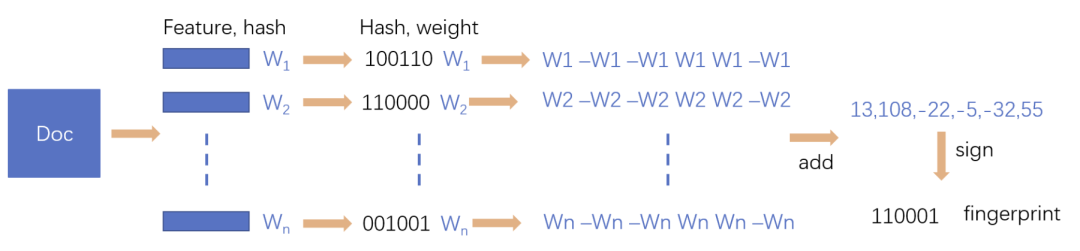
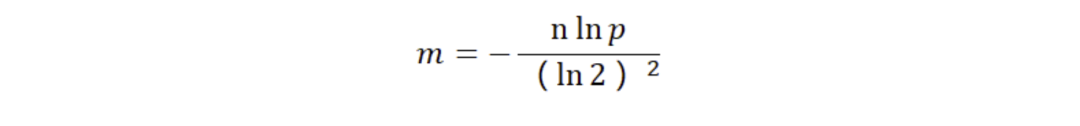
-
算法
+關(guān)注
關(guān)注
23文章
4619瀏覽量
93038 -
Hash
+關(guān)注
關(guān)注
0文章
32瀏覽量
13211
原文標(biāo)題:hash 算法原理及應(yīng)用漫談
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數(shù)據(jù)結(jié)構(gòu)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【RA-Eco-RA4E2-64PIN-V1.0開發(fā)板試用】RA4E2使用之SHA256加密解密
加密算法的選擇對于加密安全有多重要?
【「從算法到電路—數(shù)字芯片算法的電路實現(xiàn)」閱讀體驗】+閱讀第一章部分筆記
【「從算法到電路—數(shù)字芯片算法的電路實現(xiàn)」閱讀體驗】+內(nèi)容簡介
【「從算法到電路—數(shù)字芯片算法的電路實現(xiàn)」閱讀體驗】+介紹基礎(chǔ)硬件算法模塊
【「從算法到電路—數(shù)字芯片算法的電路實現(xiàn)」閱讀體驗】+一本介紹基礎(chǔ)硬件算法模塊實現(xiàn)的好書
Pure path studio內(nèi)能否自己創(chuàng)建一個component,來實現(xiàn)特定的算法,例如LMS算法?
名單公布!【書籍評測活動NO.46】從算法到電路 | 數(shù)字芯片算法的電路實現(xiàn)
FPGA-5G通信算法的基本套路
鴻蒙開發(fā):Universal Keystore Kit 密鑰管理服務(wù) HMAC ArkTS
鴻蒙開發(fā):Universal Keystore Kit 密鑰管理服務(wù) HMAC C、C++
機器學(xué)習(xí)算法原理詳解
STM32F439的HASH模塊DMA傳輸計算問題求解
全志R128 SDK HAL 模塊開發(fā)指南——Crypto Engine
AC電機控制算法是什么





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論