 圖文詳解:深度學習的學習任務
圖文詳解:深度學習的學習任務
一、典型的學習任務包括:
分類(classification)
回歸(regression)
聚類(clustering)
排序(ranking)
密度估計(density estimation)
特征降維(dimensionality reduction)
… …
1.1分類(classification)
基于已知類別標簽的樣本構成的訓練集,學習預測模型;最終預測模型,對新的觀測樣本,預測相應的輸出;預測結果為事先指定的兩個或多個類別中的某一個,或預測結果來自數目有限的離散值之一。
兩類別 vs.多類別
類別數C=2, 兩類別分類(binary classification)
類別數C》2, 多類別分類(multiclass classification)

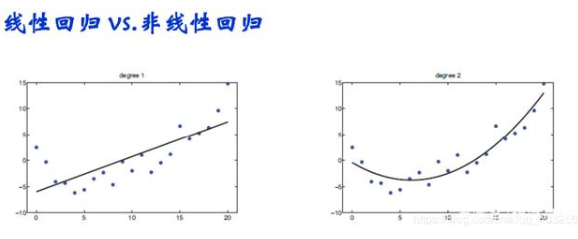
3.2回歸(regression)
回歸分析基于已知答案的樣本構成的訓練集,估計自變量與因變量之間關系的統計過程,進而基于該關系對新的觀測產生的輸出進行預測,預測輸出為連續的實數值
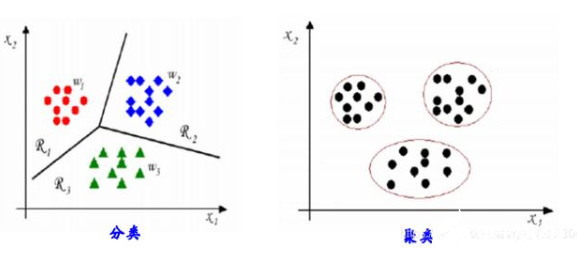
3.3 聚類(clustering)
對給定的數據集進行劃分,得到若干“簇”;使得“簇內”樣本之間較“簇間”樣本之間更為相似。通過聚類得到的可能各簇對應一些潛在的概念結構,聚類是自動為給定的樣本賦予標記的過程。
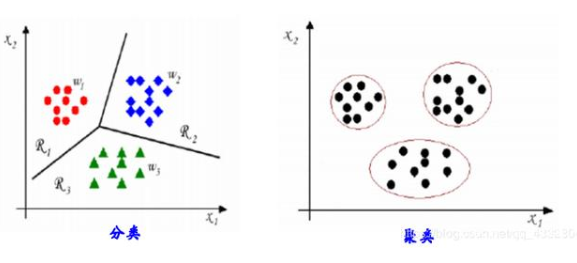
聚類舉例
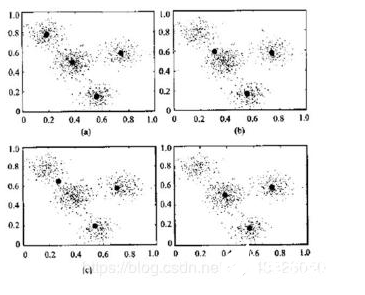
1.4特征降維
將初始的數據高維表示轉化為關于樣本的低維表示,借助由高維輸入空間向低維空間的映射,來簡化輸入。
– 特征提取,如PCA–高維數據的低維可視化
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
模型
+關注
關注
1文章
3279瀏覽量
48976 -
典型
+關注
關注
0文章
7瀏覽量
9089 -
深度學習
+關注
關注
73文章
5510瀏覽量
121347
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
設計的硬件加速器,它在深度學習中的應用日益廣泛。 1. NPU的基本概念 NPU是一種專門針對深度學習算法優化的處理器,它與傳統的CPU和GPU有所不同。NPU通常具有高度并行的處理能
AI大模型與深度學習的關系
AI大模型與深度學習之間存在著密不可分的關系,它們互為促進,相輔相成。以下是對兩者關系的介紹: 一、深度學習是AI大模型的基礎 技術支撐 :深度
深度學習算法在嵌入式平臺上的部署
隨著人工智能技術的飛速發展,深度學習算法在各個領域的應用日益廣泛。然而,將深度學習算法部署到資源受限的嵌入式平臺上,仍然是一個具有挑戰性的任務
深度學習中的時間序列分類方法
時間序列分類(Time Series Classification, TSC)是機器學習和深度學習領域的重要任務之一,廣泛應用于人體活動識別、系統監測、金融預測、醫療診斷等多個領域。隨
深度學習中的無監督學習方法綜述
深度學習作為機器學習領域的一個重要分支,近年來在多個領域取得了顯著的成果,特別是在圖像識別、語音識別、自然語言處理等領域。然而,深度學習模型
深度學習在視覺檢測中的應用
深度學習是機器學習領域中的一個重要分支,其核心在于通過構建具有多層次的神經網絡模型,使計算機能夠從大量數據中自動學習并提取特征,進而實現對復雜任務
深度學習與nlp的區別在哪
深度學習和自然語言處理(NLP)是計算機科學領域中兩個非常重要的研究方向。它們之間既有聯系,也有區別。本文將介紹深度學習與NLP的區別。 深度
深度學習中的模型權重
在深度學習這一充滿無限可能性的領域中,模型權重(Weights)作為其核心組成部分,扮演著至關重要的角色。它們不僅是模型學習的基石,更是模型智能的源泉。本文將從模型權重的定義、作用、優化、管理以及應用等多個方面,深入探討
深度學習模型訓練過程詳解
深度學習模型訓練是一個復雜且關鍵的過程,它涉及大量的數據、計算資源和精心設計的算法。訓練一個深度學習模型,本質上是通過優化算法調整模型參數,使模型能夠更好地擬合數據,提高預測或分類的準
深度學習與傳統機器學習的對比
在人工智能的浪潮中,機器學習和深度學習無疑是兩大核心驅動力。它們各自以其獨特的方式推動著技術的進步,為眾多領域帶來了革命性的變化。然而,盡管它們都屬于機器學習的范疇,但
深度解析深度學習下的語義SLAM
隨著深度學習技術的興起,計算機視覺的許多傳統領域都取得了突破性進展,例如目標的檢測、識別和分類等領域。近年來,研究人員開始在視覺SLAM算法中引入深度學習技術,使得
發表于 04-23 17:18
?1340次閱讀

為什么深度學習的效果更好?
導讀深度學習是機器學習的一個子集,已成為人工智能領域的一項變革性技術,在從計算機視覺、自然語言處理到自動駕駛汽車等廣泛的應用中取得了顯著的成功。深度

【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!
深度學習在科學計算中獲得了廣泛的普及,其算法被廣泛用于解決復雜問題的行業。所有深度學習算法都使用不同類型的神經網絡來執行特定任務。 什么是






 工商網監
工商網監
評論