 CUDA 6中的統一內存模型
CUDA 6中的統一內存模型
CUDA介紹
CUDA(Compute Unified Device Architecture,統一計算設備架構)是由NVIDIA公司于 2006 年所推出的一種并行計算技術,是該公司對于GPGPU( General-purpose computing on graphics processing units, 圖形處理單元上的通用計算 )技術的正式命名。通過此技術,用戶可在GPU上進行通用計算,而開發人員可以使用C語言來為CUDA架構編寫程序 。相比CPU,擁有CUDA技術的GPU成本不高,但計算性能很突出。本文中提到的是2014年發布的CUDA6, CUDA6最重要的新特性就是支持統一內存模型(Unified Memory)。
注:文中經常出現“主機和設備”,本文的“主機”特指CPU、“設備”特指GPU。
CUDA 6中的統一內存模型
NVIDIA在CUDA 6中引入了統一內存模型 ( Unified Memory ),這是CUDA歷史上最重要的編程模型改進之一。在當今典型的PC或群集節點中,CPU和GPU的內存在物理上是獨立的,并通過PCI-Express總線相連。在CUDA6之前, 這是程序員最需要注意的地方。CPU和GPU之間共享的數據必須在兩個內存中都分配,并由程序直接地在兩個內存之間來回復制。這給CUDA編程帶來了很大難度。
統一內存模型創建了一個托管內存池(a pool of managed memory),該托管內存池由CPU和GPU共享,跨越了CPU與GPU之間的鴻溝。CPU和GPU都可以使用單指針訪問托管內存。關鍵是系統會自動地在主機和設備之間遷移在統一內存中分配的數據,從而使那些看起來像CPU內存中的代碼在CPU上運行,而另一些看起來像GPU內存中的代碼在GPU上運行。
在本文中,我將向您展示統一內存模型如何顯著簡化GPU加速型應用程序中的內存管理。下圖顯示了一個非常簡單的示例。兩種代碼都從磁盤加載文件,對其中的字節進行排序,然后在釋放內存之前使用CPU上已排序的數據。右側的代碼使用CUDA和統一內存模型在GPU上運行。和左邊代碼唯一的區別是,右邊代碼由GPU來啟動一個內核(并在啟動后進行同步),并使用新的API cudaMallocManaged() 在統一內存模型中為加載的文件分配空間。
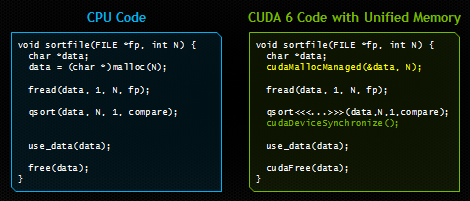
如果您曾經編程過CUDA C / C++,那么毫無疑問,右側的代碼會為您帶來震撼。請注意,我們只分配了一次內存,并且只有一個指針指向主機和設備上的可訪問數據。我們可以直接地將文件的內容讀取到已分配的內存,然后就可以將內存的指針傳遞給在設備上運行的CUDA內核。然后,在等待內核處理完成之后,我們可以再次從CPU訪問數據。CUDA運行時隱藏了所有復雜性,自動將數據遷移到訪問它的地方。
統一內存模型提供了什么
統一內存模型為程序員提供了兩大捷徑
簡化編程、簡化內存模型
統一內存模型通過使設備內存管理(device memory management)成為一項可選的優化,而不是一項硬性的要求,從而降低了CUDA平臺上并行編程的門檻。借助統一內存模型,程序員現在可以直接開發并行的CUDA內核,而不必擔心分配和復制設備內存的細節。這將降低在CUDA平臺上編程的學習成本,也使得將現有代碼移植到GPU的工作變得容易。但這些好處不僅有利于初學者。我在本文后面的示例中將展示統一內存模型如何使復雜的數據結構更易于與設備代碼一起使用,以及它與C++結合時的強大威力。
通過數據局部性原理提高性能
通過在CPU和GPU之間按需遷移數據,統一內存模型可以滿足GPU上本地數據的性能需求,同時還提供了易于使用的全局共享數據。這個功能的復雜細節被 CUDA驅動程序和運行時隱藏了,以確保應用程序代碼更易于編寫。遷移的關鍵是從每個處理器獲得全部帶寬。250 GB / s的GDDR5內存對于保證開普勒( Kepler )GPU的計算吞吐量至關重要。
值得注意的是, 一個經過精心調優的CUDA程序,即使用流(streams)和 cudaMemcpyAsync來有效地將執行命令與數據傳輸重疊的程序,會比僅使用統一內存模型的CUDA程序更好 。可以理解的是:CUDA運行時從來沒有像程序員那樣提供何處需要數據或何時需要數據的信息!CUDA程序員仍然可以顯式地訪問設備內存分配和異步內存拷貝,以優化數據管理和CPU-GPU并發機制 。首先,統一內存模型提高了生產力,它為并行計算提供了更順暢的入口,同時它又不影響高級用戶的任何CUDA功能。
統一內存模型 vs 統一虛擬尋址?
自CUDA4起,CUDA就支持統一虛擬尋址(UVA),并且盡管統一內存模型依賴于UVA,但它們并不是一回事。UVA為 系統中的所有內存提供了單個虛擬內存地址空間,無論指針位于系統中的何處,無論在設備內存(在相同或不同的GPU上)、主機內存、或片上共享存儲器。UVA也允許 cudaMemcpy在不指定輸入和輸出參數確切位置的情況下使用。UVA啟用“零復制(Zero-Copy)” 內存,“零復制”內存是固定的主機內存,可由設備上的代碼通過PCI-Express總線直接訪問,而無需使用 memcpy。零復制為統一內存模型提供了一些便利,但是卻沒有提高性能,因為它總是通過帶寬低而且延遲高的PCI-Express進行訪問。
UVA不會像統一內存模型一樣自動將數據從一個物理位置遷移到另一個物理位置。由于統一內存模型能夠在主機和設備內存之間的各級頁面自動地遷移數據,因此它需要進行大量的工程設計,因為它需要在CUDA運行時(runtime)、設備驅動程序、甚至OS內核中添加新功能。以下示例旨在讓您領會到這一點。示例:消除深層副本
統一內存模型的主要優勢在于,在訪問GPU內核中的結構化數據時,無需進行深度復制(deep copies),從而簡化了異構計算內存模型。如下圖所示,將包含指針的數據結構從CPU傳遞到GPU要求進行“深度復制”。
下面以struct dataElem為例。
struct dataElem {int prop1;int prop2;char *name;}
要在設備上使用此結構體,我們必須復制結構體本身及其數據成員,然后復制該結構體指向的所有數據,然后更新該結構體。副本中的所有指針。這導致下面的復雜代碼,這些代碼只是將數據元素傳遞給內核函數。
void launch(dataElem *elem) { dataElem *d_elem;char *d_name;
int namelen = strlen(elem-》name) + 1;
// Allocate storage for struct and name cudaMalloc(&d_elem, sizeof(dataElem)); cudaMalloc(&d_name, namelen);
// Copy up each piece separately, including new “name” pointer value cudaMemcpy(d_elem, elem, sizeof(dataElem), cudaMemcpyHostToDevice); cudaMemcpy(d_name, elem-》name, namelen, cudaMemcpyHostToDevice); cudaMemcpy(&(d_elem-》name), &d_name, sizeof(char*), cudaMemcpyHostToDevice);
// Finally we can launch our kernel, but CPU & GPU use different copies of “elem” Kernel《《《 。.. 》》》(d_elem);}
可以想象,在CPU和GPU代碼之間分享復雜的數據結構所需的額外主機端代碼對生產率有嚴重影響。統一內存模型中分配我們的“ dataElem”結構可消除所有多余的設置代碼,這些代碼與主機代碼被相同的指針操作,留給我們的就只有內核啟動了。這是一個很大的進步!
void launch(dataElem *elem) { kernel《《《 。.. 》》》(elem);}
但統一內存模型不僅大幅降低了代碼復雜性。還可以做一些以前無法想象的事情。讓我們看另一個例子。
Example: CPU/GPU Shared Linked Lists
鏈表是一種非常常見的數據結構,但是由于它們本質上是由指針組成的嵌套數據結構,因此在內存空間之間傳遞它們非常復雜。如果沒有統一內存模型,則無法在CPU和GPU之間分享鏈表。唯一的選擇是在零拷貝內存(被pin住的主機內存)中分配鏈表,這意味著GPU的訪問受限于PCI-express性能。通過在統一內存模型中分配鏈表數據,設備代碼可以正常使用GPU上的指針,從而發揮設備內存的全部性能。程序可以維護單鏈表,并且無論在主機或設備中都可以添加和刪除鏈表元素。
將具有復雜數據結構的代碼移植到GPU上曾經是一項艱巨的任務,但是統一內存模型使此操作變得非常容易。我希望統一內存模型能夠為CUDA程序員帶來巨大的生產力提升。
Unified Memory with C++
統一內存模型確實在C++數據結構中大放異彩。C++通過帶有拷貝構造函數(copy constructors)的類來簡化深度復制問題。拷貝構造函數是一個知道如何創建類所對應對象的函數,拷貝構造函數為對象的成員分配空間并從其他對象復制值過來。C++還允許 new和 delete這倆個內存管理運算符被重載。這意味著我們可以創建一個基類,我們將其稱為 Managed,它在重載的 new運算符內部使用 cudaMallocManaged(),如以下代碼所示。
class Managed {public:void *operator new(size_t len) {void *ptr; cudaMallocManaged(&ptr, len); cudaDeviceSynchronize();return ptr; }
void operator delete(void *ptr) { cudaDeviceSynchronize(); cudaFree(ptr); }};
然后,我們可以讓 String類繼承 Managed類,并實現一個拷貝構造函數,該拷貝構造函數為需要拷貝的字符串分配統一內存。
// Deriving from “Managed” allows pass-by-referenceclass String : public Managed { int length; char *data;
public:// Unified memory copy constructor allows pass-by-value String (const String &s) { length = s.length; cudaMallocManaged(&data, length); memcpy(data, s.data, length); }
// 。..};
同樣,我們使我們的 dataElem類也繼承 Managed。
// Note “managed” on this class, too.// C++ now handles our deep copiesclass dataElem : public Managed {public:int prop1;int prop2; String name;};
通過這些更改,C++的類將在統一內存中分配空間,并自動處理深度復制。我們可以像分配任何C++的對象那樣在統一內存中分配一個 dataElem。
dataElem *data = new dataElem;
請注意,您需要確保樹中的每個類都繼承自 Managed,否則您的內存映射中會有一個漏洞。實際上,任何你想在CPU和GPU之間分享的內容都應該繼承 Managed。如果你傾向于對所有程序都簡單地使用統一內存模型,你可以在全局重載 new和 delete, 但這只在這種情況下有作用——你的程序中沒有僅被CPU訪問的數據(即程序中的所有數據都被GPU訪問),因為只有CPU數據時沒有必要遷移數據。
現在,我們可以選擇將對象傳遞給內核函數了。如在C++中一樣,我們可以按值傳遞或按引用傳遞,如以下示例代碼所示。
// Pass-by-reference version__global__ void kernel_by_ref(dataElem &data) { 。.. }
// Pass-by-value version__global__ void kernel_by_val(dataElem data) { 。.. }
int main(void) { dataElem *data = new dataElem; 。..// pass data to kernel by reference kernel_by_ref《《《1,1》》》(*data);
// pass data to kernel by value -- this will create a copy kernel_by_val《《《1,1》》》(*data);}
多虧了統一內存模型,深度復制、按值傳遞和按引用傳遞都可以正常工作。統一內存模型為在GPU上運行C++代碼提供了巨大幫助。
這篇文章的例子可以在Github上找到。
統一內存模型的光明前景
CUDA 6中關于統一內存模型的最令人興奮的事情之一就是它僅僅是個開始。我們針對統一內存模型有一個包括性能提升與特性的長遠規劃。我們的第一個發行版旨在使CUDA編程更容易,尤其是對于初學者而言。從CUDA 6開始, cudaMemcpy()不再是必需的。通過使用 cudaMallocManaged(),您可以擁有一個指向數據的指針,并且可以在CPU和GPU之間共享復雜的C / C++數據結構。這使編寫CUDA程序變得容易得多,因為您可以直接編寫內核,而不是編寫大量數據管理代碼并且要維護在主機和設備之間所有重復的數據。您仍然可以自由使用 cudaMemcpy()(特別是 cudaMemcpyAsync())來提高性能,但現在這不是一項要求,而是一項優化。
CUDA的未來版本可能會通過添加數據預取和遷移提示來提高使用統一內存模型的應用程序的性能。我們還將增加對更多操作系統的支持。我們的下一代GPU架構將帶來許多硬件改進,以進一步提高性能和靈活性。
責任編輯:pj
-
數據
+關注
關注
8文章
7104瀏覽量
89297 -
內存
+關注
關注
8文章
3042瀏覽量
74180 -
編程
+關注
關注
88文章
3634瀏覽量
93861
發布評論請先 登錄
相關推薦
拋棄8GB內存,端側AI大模型加速內存升級

芯盾時代助力中建科技統一身份認證項目圓滿結項
芯盾時代繼續深化中建科技統一身份認證平臺建設
【「大模型啟示錄」閱讀體驗】對大模型更深入的認知
KerasHub統一、全面的預訓練模型庫
CNN, RNN, GNN和Transformer模型的統一表示和泛化誤差理論分析





 工商網監
工商網監
評論