 情感語音合成技術難點突破與未來展望
情感語音合成技術難點突破與未來展望
語音技術的進步,讓機器合成的聲音不再頓挫、冰冷,在自然度和可懂度等方面取得了不錯的成績,但當前合成效果在合成音的表現力上,特別是語氣和情感方面,還存在不足。聲音如果缺少情感,何談表現力 ,又如何能提高用戶交互的意愿?本文由標貝科技聯合創始人兼CTO李秀林LiveVideoStack線上分享內容整理而成。
大家好,我是標貝科技的李秀林,非常高興能與大家分享情感語音合成的事情。
在語音交互中語音識別、語音合成、語音理解是必不可少的環節。語音識別,也就是識別用戶說的話。識別完成后,系統需要理解用戶語言背后的含義,我們稱之為語義理解。理解到用戶的訴求后,需要尋找答案并給出響應。通常情況下,我們會首先得到一份文本形式的答案,然后再將文本通過語音合成,模仿人說話的形式反饋給用戶,這也就形成一輪完整的語音交互。
語音交互過程涉及語音合成,即把文字變成聲音,聲音是文字內容的一個信息載體。語音交互是日常生活中最常見、最被人熟悉并樂于接受的展現形式,例如:人與人說話、看電視、聽收音機、與音響交互等等。體驗效果的好壞,會對用戶的感知造成很大影響。如果語音合成質量較好,說話效果更接近真人,且情感表達豐富,那么用戶的交互意愿自然也會更強,用戶會覺得這不是一個冷冰冰的機器,會有愿意與這類智能體進一步交互。 這段小視頻是疫情初期我們的合作伙伴利用語音合成技術生成的。從視頻中大家可以明顯感受到:我們可以從聲音當中獲取充分的信息,也就是信息的傳達作用是完全沒有問題的。但也同樣存在一個問題,即聲音相對來說比較平淡,聲音更多的是作為一個信息載體,而不是作為一個表達的載體。
接下來會和大家一同探討語音合成和情感語音合成的技術難點與實現,以及將來語音合成的發展和應用場景。 01 語音合成的發展
語音合成的歷史可以說是相當悠久。最初,實際上是通過類似于鋼琴一樣的設備來彈奏,能夠發出幾個聲音,大家就已經覺得非常厲害。隨著計算機技術的發展,從80年代到90年代再到現階段,技術的迭代更新也越來越快。
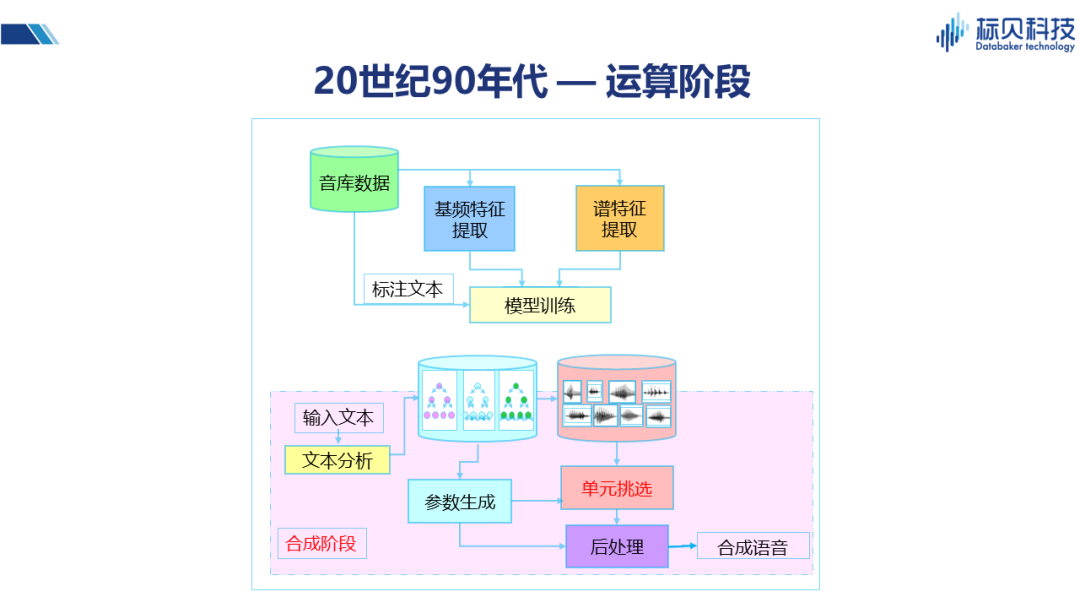
90年代,計算機已經可以支持幾百兆甚至上G的內存,硬盤也足以支持幾十G的內存,能夠實現存儲大量的數據并進行較為復雜的處理。上圖展示的系統框架就是在這一階段產生的,并且直到前幾年還有很多商務系統仍舊使用這套框架。 在框架中,訓練階段我們會針對音庫的數據以及對應的標注文本進行建模(包括基頻的提取、譜特征提取,以及時長提取等),訓練成時長模型、基頻模型、譜模型等。合成階段則存在拼接合成、參數合成兩種主流的方案。 拼接合成:用戶輸入的文本將通過文本分析,并結合訓練好的模型生成對應參數。該參數可以指導拼接系統進行單元挑選。所謂單元挑選,即從之前錄制好的音庫片段中挑選最合適的部分,將其拼接起來,使得整個聲音更加流暢,接近于真人。單元挑選的優點是音質還原度非常好,而缺點是其音級單元之間有時會產生一些跳躍和不連貫,通常表現為在聽感上會感覺有些地方不流暢、不舒服。 參數合成:即不使用原始的聲音片段,通過聲碼器對聲學參數進行轉換,生成聲音。這種方案由于其統計特性、以及聲碼器性能的影響,在音質方面會相對弱一些。
近些年,隨著神經網絡技術的發展,統計模型方面受到很大影響。之前許多基于高斯混合模型的統計,我們可以直接通過神經網絡模型來實現。當前階段我們將它命名為 — 自學習階段。 神經網絡具有很強的自我學習能力,有非常多的權重,可以通過數據,學習到許多連專家都難以總結出來的特點。因此,當前階段大家會更多的選擇使用神經網絡。 2016年,WaveNet的出現徹底改變了聲音生成的方式,它將逐幀生成,即以幀為單位的聲音生成變成了逐點生成波形。所帶來的好處是聲音還原度變得非常高,在一定程度上可以說是接近于原始聲音。盡管其仍存在計算量復雜的缺點,但此缺點在近兩年也已通過一系列的改造,例如并行的WaveNet等等,逐漸變得可以接受,同時優勢的體現也越來越充分。
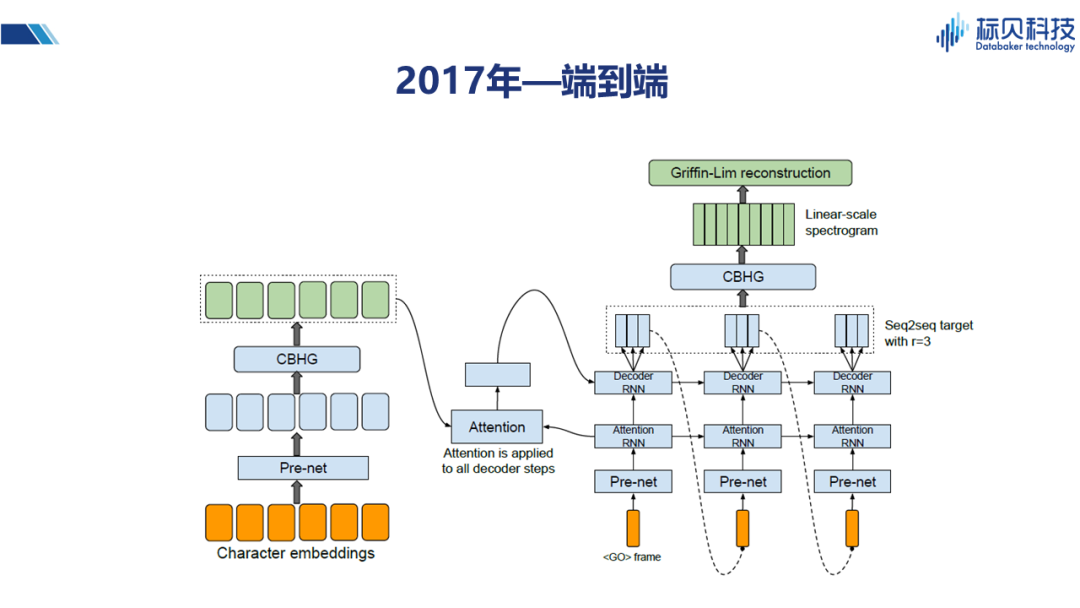
2017年,Tacotron以及后續Tacotron2等一系列的變體,為我們提供了一種端到端的語音合成方式。端到端雖然更多的是一個學術概念,但就整體系統來說是非常漂亮的。它利用核心的Attention機制,將輸入和輸出之間的關聯度,通過模型很好的表述出來。在此之前我們通常是先做一個時長模型,然后再做其它譜模型、基頻的模型,而通過端到端的模型,我們就可以跳過時長模型,直接針對整句話進行建模。Tacotron的出現,對于合成語音的韻律,節奏方面都有很大的提升(更接近真人)。
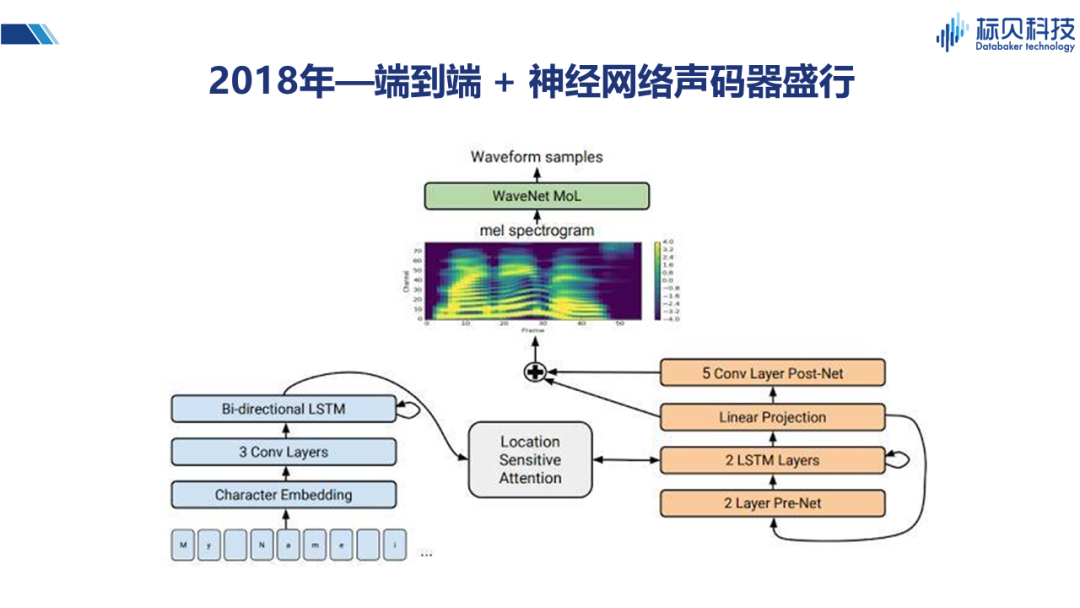
2018年,大家將兩種網絡結合在一起,即將端到端與神經網絡的聲碼器結合形成一個更逼真的語音合成系統。并且對Attention的結構也進行了一些改造,使得系統整體性能更優。所以在2018年以后,我們所見到的語音合成系統大多是基于Tacotron或Tacotron2實現。 02 情感合成 2.1 情感合成是什么?
以上簡單介紹了語音合成近些年的一些變化,那么為什么在經歷了這一系列變化后,大家覺得還是不夠?一般來說合成的數據我們都會考慮追求平穩,因此在情感和表達方面也就不會太豐富。但近些年大家對情感合成以及個性化合成的興趣與需求越來越高。 關于情感合成,我們可以想象一下,假如我們在和機器交流時能夠像和一個真正的人交談一樣,它可以用平淡的聲音、高興的聲音、悲傷的聲音,甚至不同的情感有不同的強度,比如說微微有點不高興、非常不高興、非常憤怒。那么可想而知這種場景會給我們的生活帶來多大改變。
情感合成作為一項技術,當然也離不開神經網絡的三要素:算法、算力和數據。而對于語音合成領域來說,算力實際上是不太重要的,我們可以通過一些GPU 的卡來解決算力的問題,因此需要我們重點關注的是算法和數據的問題。 情感合成的算法在最初使用HTS技術時,已經有很多學者進行過一些探索。但是由于模型的描述能力,以及模型本身自學習能力較弱,實用性會差一些。 2.2 情感標簽的使用
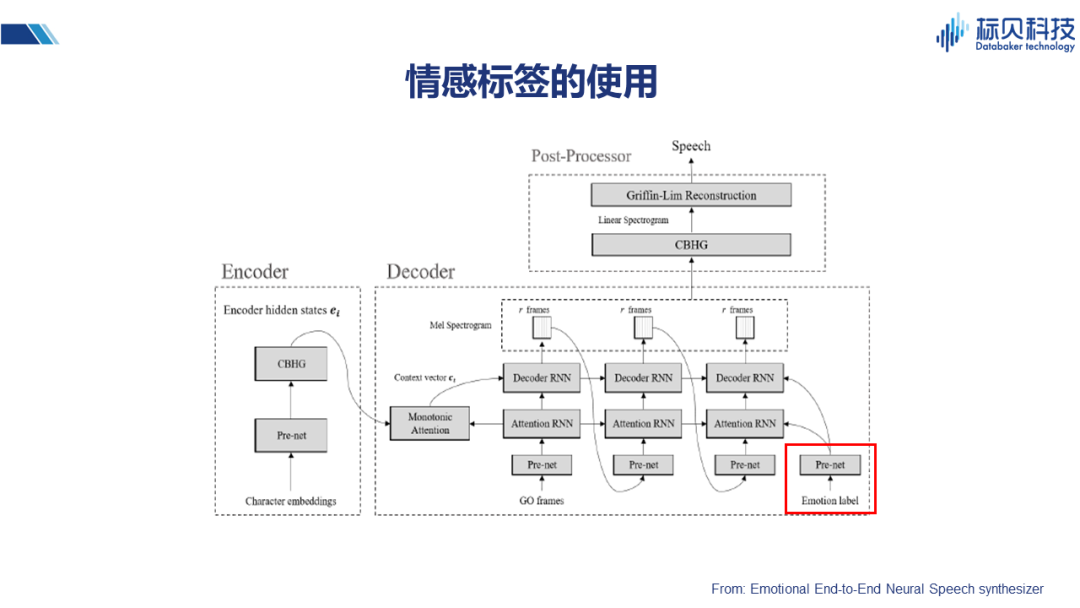
大家可以發現,在有了神經網絡之后,目前情感合成的方案基本上都是在一個很好的框架之上來進行一些不同的改造,下面簡單介紹幾種不同的解決方案。 在這篇端到端的情感合成的文章里,提到用情感做標簽(在原有網絡基礎上增加一個情感標簽),通過一個prenet 把這些信息引入到Attention的decoder中。這樣情感的信息自然會通過網絡得到一定的學習,在合成的時候,如果能賦予合適的情感標簽,也就能合成出有一定情感表達力的聲音。 2.3情感合成的實現 2.3.1 說話人嵌入的使用
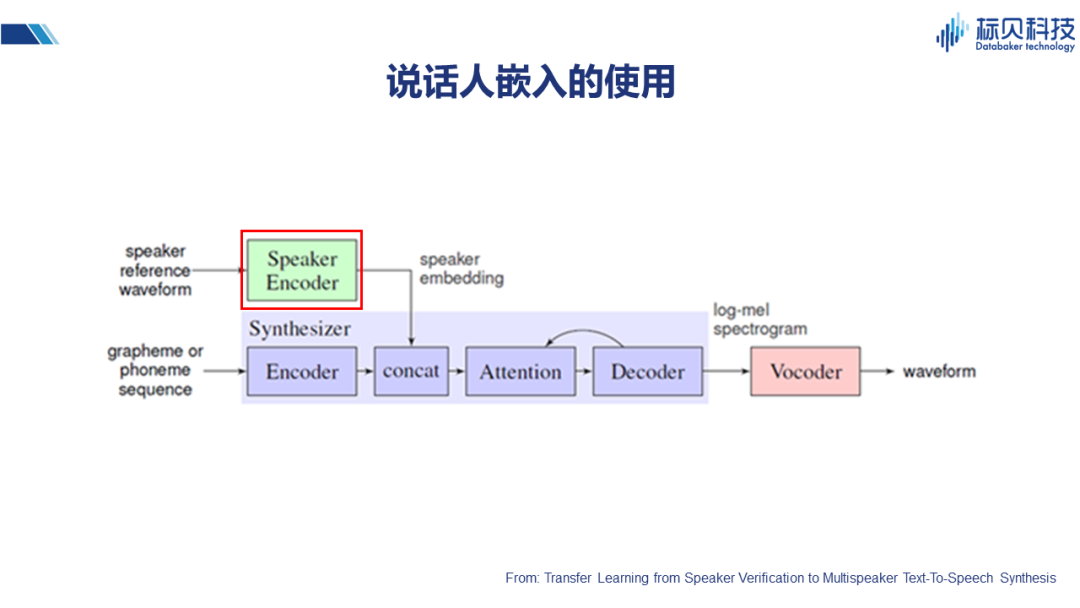
除情感標簽之外,比如說這篇文章,提到用說話人入嵌Encoder 的方式。也就是將說話人的聲音特征,通過編碼器得到speaker embedding,并將其結合到Attention的網絡中,實現不同說話人聲音合成的效果。 我們其實可以從另外一個角度考慮,情感是什么?或者不同的變化是什么?它可以是情感本身、不同說話人、以及語言風格等等。所以上述說話人嵌入的方式,其實對整個情感合成也會有一定的借鑒作用。 2.3.2 風格嵌入的使用
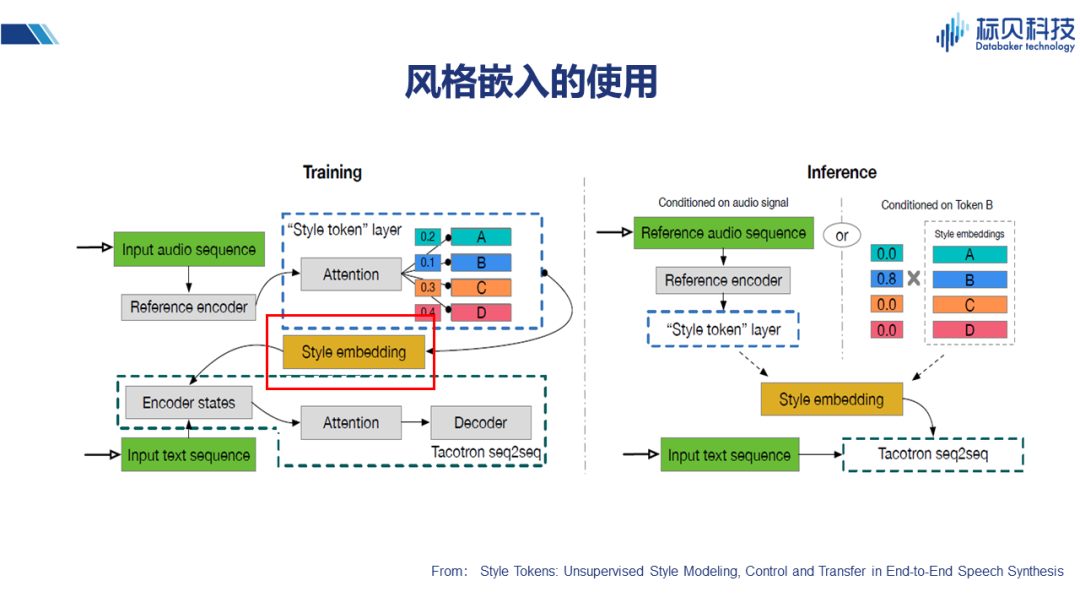
這篇文章介紹的是通過一個稍微復雜些的子網絡實現風格的嵌入,其整體核心框架也同樣是Tacotron系列。方法是在子網絡中構建一個風格的分類,在進行風格分類embedding之后,與之前文本的encoder 結果一同加入到網絡當中去。在推理的時候,通過風格的控制來改變整體合成的效果。 2.3.3 聲學特征&說話人嵌入的使用
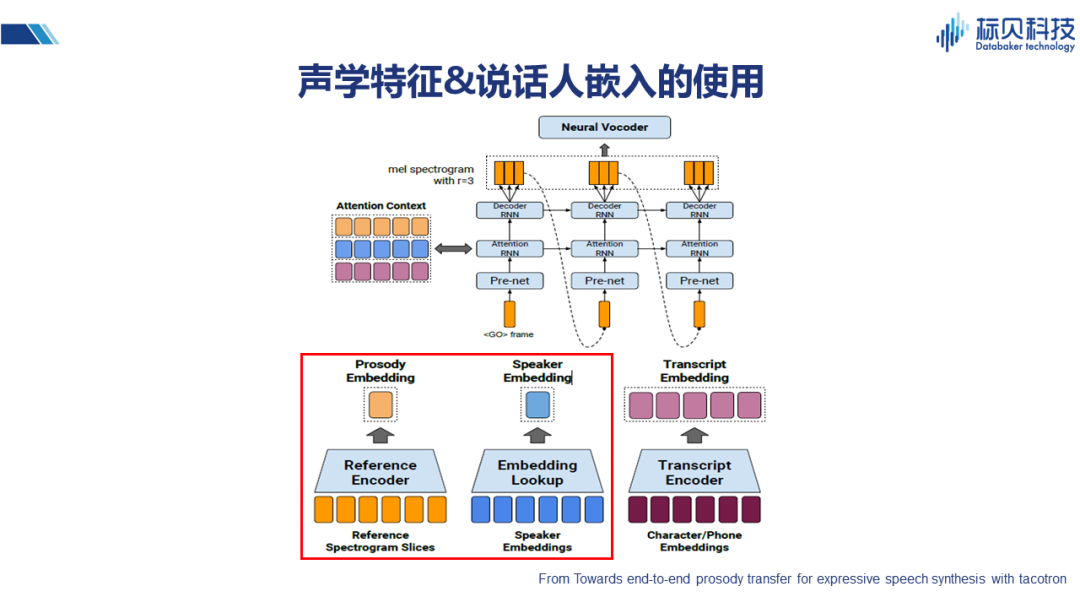
這篇文章也是類似的思路,除文本特征之外,再通過look up table 來做說話人的嵌入,通過譜的片段進行韻律的嵌入,最后將三種嵌入合成起來,作為影響整個系統的控制因素。 2.3.4 VAE的使用
除了上述提到的情感嵌入、說話人嵌入、風格嵌入之外,還有一種VAE的方法。它將譜的特征通過一個唯一的網絡 — 子網,在學習到特征之后,與文本特征一同輸入到Attention的網絡(在這里選擇的是Tacotron2的網絡)。 綜上可知我們的網絡主體基本上是一個Attention 機制的網絡(如Tacotron或Tacotron2),在這個主體之上,我們會加入一些特征,這個特征可以是各種各樣的標簽作為輸入。也就相當于把風格、情感等變量單一或者組合使用,引入到整個系統當中。 以上就是當前可以看到的文獻中出現的一些情感合成方案。 2.3.5 情感合成數據
數據是另外一個制約系統整體表現力的因素,在情感合成數據方面,我們面臨著很多的問題。 比如我們需要數據有情感表現力,所謂情感表現力是指在聽到一段聲音后,能夠明顯感知到說話人是高興的、生氣的、還是憂傷的,這也是我們現階段希望能夠解決的一個問題。還有就是情感控制,說話人情感表現的程度,有的比較輕微,有的是比較強烈,我們做數據的時候,應該選擇哪一種?前景網絡如果情感過于強烈,并且波動范圍很大的話,對于建模的要求就會非常高。那么我們就希望能夠在數據層面,對情感的控制有一個度量。 第三點,也就是數據的規模,我們知道對于神經網絡來說,數據規模越大,則整體效果越好,當然這是一個理想的情況。而現實是,我們在對情感表現力和情感控制方面要求比較嚴格時,往往只能采用同一個人的不同情感聲音數據,那么數據規模本身就會受到一定限制,因此數據規模也是制約情感合成技術發展的一個關鍵點。
接下來介紹下我們所做的一些工作,標貝科技專注于提供人工智能數據的服務,同時也提供高音質,多場景,多類別語音合成的整體解決方案。我們希望在做高質量語音合成數據的同時,能夠為中小型企業提供更多優質的解決方案,幫助解決他們的問題。 同樣,我們也希望能夠為整個語音行業提供一些基礎的數據支持。比如2017年,我們就將一個10000句話規模的高質量語音合成庫共享給了整個行業進行學術研究,希望能夠跟大家一起將語音技術做的越來越好。
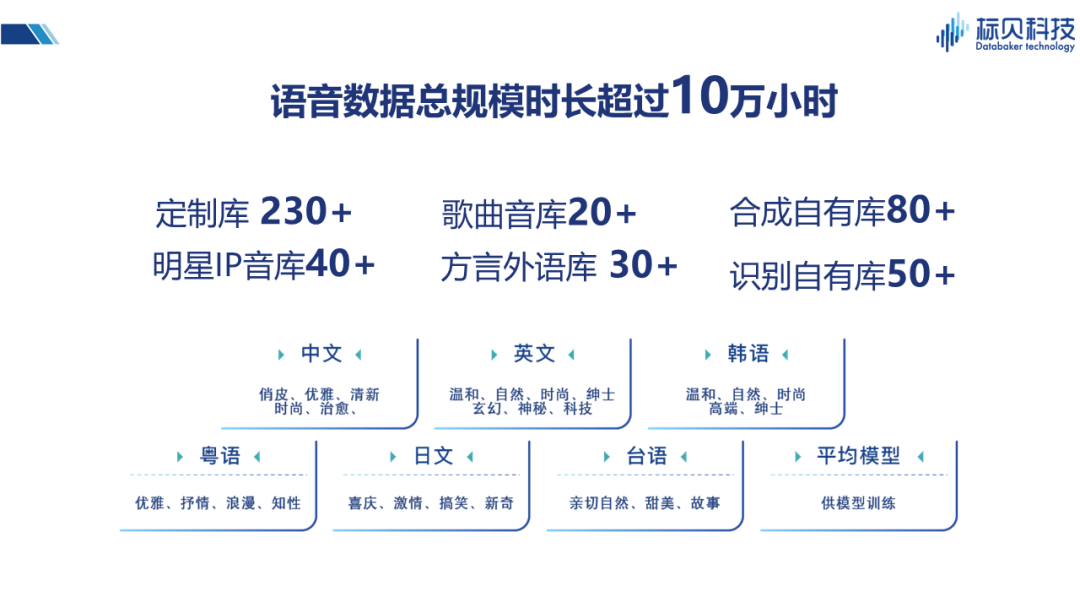
在數據方面,我們擁有包括識別自有庫,合成自有庫,歌曲音庫、明星IP音庫、以及方言音庫等在內的多種不同類型的語音數據庫,語音數據時長累計超過十萬小時,這些數據有很多也應用到了我們的情感合成實踐當中。 03 標貝科技情感合成實踐

在情感合成實踐當中,我們主要應用到了三類數據。 第一類是多人的數據庫,規模并不是特別大,在使用時大概是100人左右的規模。這100人里,每個人會說500句話,其中300句話是相同的,200句話是不同的。在不同人之間,實際上也會有一些共性的東西,有一些不同的東西。在發言人方面,覆蓋了從兒童、青年、老年等不同年齡段,這樣做的好處是它可以讓我們學習到不同年齡段人說話的特點。這些特點可能是受說話人自己的知識背景、生活環境影響,或者是生理因素(比如聲帶的發育階段,聲帶的老化情況等)影響而形成。 第二類數據,用到了一些中大規模的合成數據庫。這些數據庫有的是男生的、有的是女生的,數據規模比多人數據庫要大很多,基本上都是幾千句的,幾萬句的規模。 第三類數據庫是情感數據庫。情感數據庫中包含六種情感形式,悲傷、憤怒、驚訝、恐懼、喜悅和厭惡。除此之外,還包括同說話人的中性聲音,即不帶情感比較平穩的聲音。所以實際上這個情感數據庫,包括六種情感和一種中性的聲音,七種聲音都是同一個發音人。
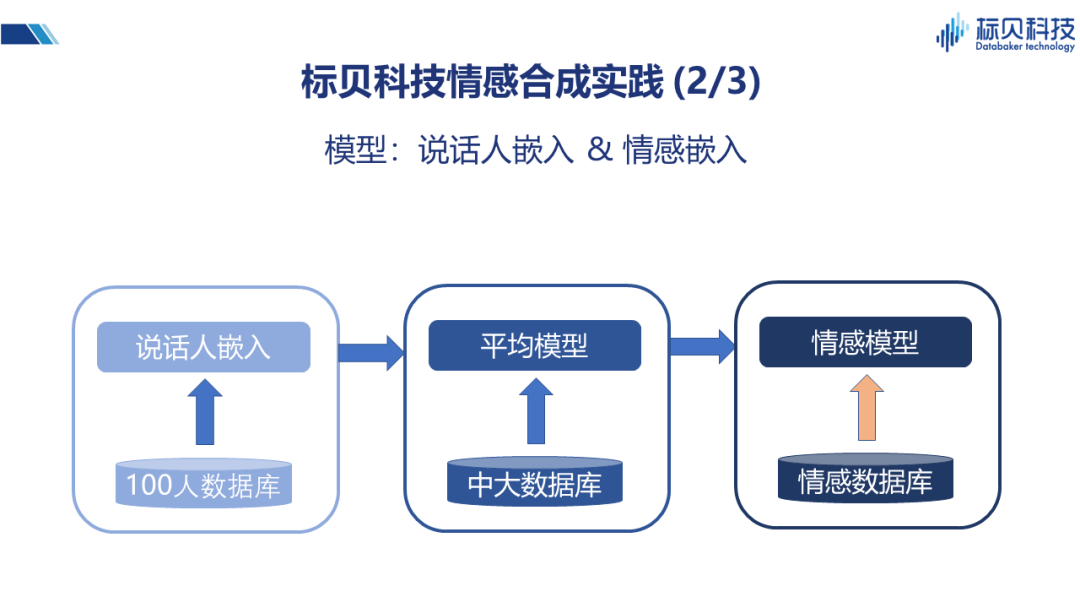
上述三類數據的用途各不相同:100人數據庫,主要用來做說話人嵌入的網絡。假如我們通過一個神經網絡來刻畫每個人,用向量表示的話應該是什么樣?在這里我們用了一個神經網絡來專門做說話人嵌入的向量訓練。 第二個階段,中大規模的數據庫做平均模型。我們將說話人的嵌入與數據結合起來,做了一個平均模型。因為輸入的文本和發音之間有一定的對應關系,所以平均模型相對來說比較穩定。 最后,我們就可以利用情感數據庫結合平均模型,實現情感語音合成的模型。

這是一個情感合成的樣音,不同的情感是存在明顯差別的,我們能從聲音里感受到情感的變化。這里我們并沒有采用WaveNet或者復雜度比較高的聲碼器,因為我們想做的是一個能夠在線上提供大規模并發服務的系統,所以選擇的是LPC Net,在音質方面還不是最好的。
隨著情感合成技術的發展,接下來還會有哪些應用場景?例如剛才聽到的語音故事,我們就可以將它應用到有聲讀物上。還有就是語音助手,近年來隨著NLP技術的發展,語音助手開始逐漸走進大家的生活中,幫助人們完成一些簡單的工作。虛擬形象近年來發展的也比較好,例如虛擬主持人、虛擬歌手、虛擬的形象,能夠具有一定的情感表現能力。 除此之外,抖音、快手等UGC創作平臺,其中不乏有意思的故事、視頻,但部分內容配音需要找一些專業的人員錄制,很多內容創作者并沒有這個條件。最近我們發現有許多創作者開始將語音合成(成本更低)結合到內容創作中,讓內容變得更加生動、有趣。 那么更進一步,例如游戲和影視動畫等領域,在具有一定情感表達能力后,對于一些非實時的產品,我們可以通過WaveNet的高質量生成器合成更高質量的語音內容,同樣具有一定潛力。 04 情感合成技術展望
但在進行這些場景的廣泛應用之前,我們還需要解決如下問題: 首先是NLP相關的問題,例如我們想要表達一個情感,需要知道這個情感是什么,不能用高興的聲音去說一件悲哀的事情,反之亦然。這就需要NLP有非常準確的情感分析與表達能力,不是60%、70%,我們希望至少是90%及以上,這樣用戶的接受度才會更好。 同樣,剛剛提到的有聲讀物。例如一本小說,小說里的角色眾多,如果每個人用不同的聲音去表現,每個人又都有其自己的感情,那這本小說就可以通過聽的方式表現的活靈活現,這也就要求NLP具有更高的角色分析能力。 還有涉及到語音合成的挑戰:不同說話人之間的情感遷移,例如對于沒有情感的聲音,可不可以通過一些類比或者遷移技術,把別人的情感和非情感的差異,在一個沒有情感數據的聲音上進行呈現;小數據量的個性化情感合成,我們前段時間推出了標貝留聲機的一個小數據的個性化合成,這里面并沒有涉及到情感。如果我們還是在這個數據規模下,每種情感加上一句話,是不是可以實現? 涉及到交互,如果想讓其更有深度,我們是不是能夠感知到與機器進行交互的人的情感。比如現在的一些心靈電臺等,有些人遇到挫折、困難的時候跟他聊聊天,講個故事安慰一下,我覺得對社會來說是一件非常有意義的事情。 另外就是聲音和形象的組合,例如我們現在看到的虛擬形象,在口型與聲音對應一致性上,已經有明顯的進步,甚至已經能夠完成一些虛擬動作的實現。如果能夠加上有情感的聲音以及有表現力的表情,就可以應用到影視、動畫等這些高難度的場景了。 所以,在情感合成方面,實際上我們只是進行了一些初步的探索,距離實現大范圍的快速、廣泛應用,仍需繼續努力。
-
語音識別
+關注
關注
38文章
1742瀏覽量
112692 -
語音合成
+關注
關注
2文章
90瀏覽量
16170
原文標題:情感語音合成技術難點突破與未來展望
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
移動機器人的技術突破和未來展望

全球人工智能認知與情感交織的2024年:益普索Ipsos報告揭示未來趨勢
中國AI芯片行業,自主突破與未來展望
WT3000T8-TTS語音合成芯片及應用場景介紹
融合通信技術的未來展望:更多可能,更多驚喜

深圳比創達電子EMC|EMC電磁兼容技術:原理、應用與未來展望.

玩轉語音合成芯片(TTS芯片),看這一篇就夠了






 工商網監
工商網監
評論