 什么是互相關函數?什么是相關系數?
什么是互相關函數?什么是相關系數?
[導讀] 在工程應用時,有時候需要計算兩個信號序列的相似度,實際信號由于在采集過程中會混入干擾,如果簡單的依次比較各樣本是否相等或者差值,則很難判定兩個信號序列的相似程度。本文來聊聊我的一些思路。
什么是互相關函數?
在統計學中,相關是描述兩個隨機變量序列或二元數據之間的統計關系,無論是否具有因果關系。廣義上講,相關性是統計上的關聯程度,它通常指的是兩個變量的線性相關的程度。比如商品的價格和消費者購買愿意數量之間的關系,也即所謂的需求曲線。
相關性是有用的,因為它們可以描述一種可在實踐中加以利用的預測作用。例如,根據電力需求和天氣之間的相關性,電力公司可能會在天氣涼快時候生產更少的電力。在這個例子中,有一定的因果關系存在,因為極端天氣導致人們使用更多的電力用于取暖或制冷。然而,一般而言,相關性的存在并不足以推斷出因果關系的存在,也就是說相關性并不意味著因果關系。
連續信號里,為函數及的互相關函數定義為:
離散信號,假設兩個信號序列x(n)及y(n),每個序列的能量都是有限能量序列,則x(n)及y(n)的互相關序列為:
那么互相關函數就是描述在連續信號或離散序列的相關程度的一種統計度量。
什么是相關系數?
最熟悉的度量兩個量之間的相關性的方法是皮爾遜乘積矩相關系數(PPMCC),也稱為“皮爾遜相關系數”,通常簡稱為“相關系數”。在數學上,它被定義為對原始數據的最小二乘擬合的質量(擬合程度或效果)。它是由數據集兩個變量的協方差的比率,歸一化到他們的方差的平方根得到的。數學上,兩個變量的協方差除以標準差的乘積。
皮爾遜積矩相關系數試圖通過兩個隨機序列的數據集建立一條最佳擬合曲線,實質上是通過列出期望和由此產生的皮爾遜相關系數表明實際數據集離預期值有多遠。根據皮爾遜相關系數的符號,如果數據集的變量之間存在某種關系,可以得到負相關或正相關。其定義公式如下:
上述公式展開為:
在根據期望計算公式展開,就得到:
如果考察延遲d處的互相關,則上述公式就變為:
為了方便理解,本文就不考察延遲節拍了。
相關系數有啥用?
皮爾遜相關系數的絕對值不大于1是Cauchy–Schwarz不等式的推論(有興趣的可以去找書看看)。因此,相關系數的值在[-1,1]之間。在理想的增加線性相關關系情況下,相關系數為+1;在理想的減少(反相關)線性關系情況下,相關系數為-1;在所有其他取值情況下,表示變量之間的線性相關程度。當它接近零時,更接近于不相關。系數越接近-1或1,變量之間的相關性越強。
故,相關系數其值范圍分布在區間[-1,1]:
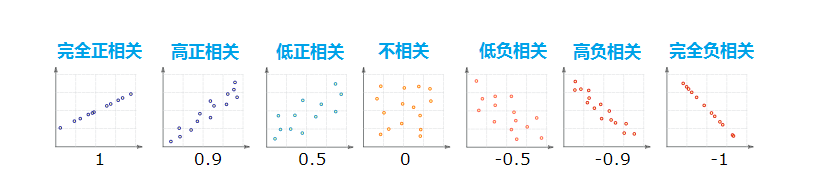
1表示完全正相關
0表示不相關
-1表示完全負相關
為了方便理解,假定兩個隨機序列按照下面各類情況分布,下面的數字為相關系數:
程序如何實現呢?
上述公式在實際編程時,當然可以直接按照公式編制代碼,如果仔細觀察會發現該公式可以進一步簡化,過程省略:
由這個公式就很容易編程了,干貨在這里,可以拿去稍加改造即可使用:
#include
運行結果為:
pxyofs1ands2:0.997435 pxyofs1ands1:1.000000 pxyofs1ands1:-1.000000
將這三個信號繪制成波形來看看:
由圖看出:
S1與S2非常相似,其相關系數為0.997435,高度相似
S1與-S1則剛好相位相反,理想反相關,其相關系數為-1
S1與S1則理所當然是一樣的,其相關系數為1
再來一組信號對比一下:
其波形數據為:
doubles1[30]={ 0.309016989,0.587785244,0.809016985,0.95105651,1, 0.951056526,0.809017016,0.587785287,0.30901704,5.35898E-08, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0 }; doubles6[30]={ 0,0,0.187381311,0.368124547,0.535826787, 0.684547097,0.809016985,0.904827044,0.968583156,0.998026727, 0.992114705,0.951056526,0,0,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0 }; doubles7[30]={ 0.187381311,0.368124547,0.535826787,0.684547097,0.809016985, 0.904827044,0.968583156,0.998026727,0.992114705,0.951056526, 0.876306697,0.770513267,0.637424022,0.481753714,0, 0,0,0,0,0, 0,0,0,0,0, 0,0,0,0,0 };
利用上述代碼計算S1與S6,S1與S7的相關系數:
pxyofs1ands6:0.402428 pxyofs1ands7:0.612618
可見,S6、S7與S1的相關系數越來越大,從波形上看相似度也越來越大。
總結一下
通過相關系數可以比較完美的判斷兩個信號序列,或者兩個隨機變量之間的相似度。相關系數以及互相關函數應用很廣,本文僅僅描述了一個工程上應用較多的實際栗子。事實上,該數學特性有著廣泛的應用,有興趣的可以深度學習探討一下。
-
函數
+關注
關注
3文章
4344瀏覽量
62809 -
數據集
+關注
關注
4文章
1208瀏覽量
24749
原文標題:數學之美:判定兩個隨機信號序列的相似度
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么叫系統的頻率響應函數?它和傳遞函數有何關系
噪聲系數和噪聲溫度的關系
直流電源電路穩壓系數相關介紹
過電流保護的靈敏系數與返回系數的關系
壓敏電阻壓力與電阻函數關系
紋波系數,輸出電壓與輸入頻率的關系
基于LIBS的土壤中銅元素和鉛元素定量分析

相關器抑制干擾信號的原理是什么
天線系數與天線增益的關系
esp32獲取時間戳的相關函數是哪個?
耦合元件的互感系數與什么有關系
函數信號發生器的功能及相關使用領域
PPTC的相關參數介紹





 工商網監
工商網監
評論