") Linux 自旋鎖spinlock
Linux 自旋鎖spinlock
背景
由于在多處理器環(huán)境中某些資源的有限性,有時(shí)需要互斥訪問(mutual exclusion),這時(shí)候就需要引入鎖的概念,只有獲取了鎖的任務(wù)才能夠?qū)Y源進(jìn)行訪問,由于多線程的核心是CPU的時(shí)間分片,所以同一時(shí)刻只能有一個(gè)任務(wù)獲取到鎖。
內(nèi)核當(dāng)發(fā)生訪問資源沖突的時(shí)候,通常有兩種處理方式:
一個(gè)是原地等待
一個(gè)是掛起當(dāng)前進(jìn)程,調(diào)度其他進(jìn)程執(zhí)行(睡眠)
自旋鎖
Spinlock 是內(nèi)核中提供的一種比較常見的鎖機(jī)制,自旋鎖是“原地等待”的方式解決資源沖突的。即,一個(gè)線程獲取了一個(gè)自旋鎖后,另外一個(gè)線程期望獲取該自旋鎖,獲取不到,只能夠原地“打轉(zhuǎn)”(忙等待)。
由于自旋鎖的這個(gè)忙等待的特性,注定了它使用場景上的限制 —— 自旋鎖不應(yīng)該被長時(shí)間的持有(消耗 CPU 資源)。
自旋鎖的優(yōu)點(diǎn)
自旋鎖不會(huì)使線程狀態(tài)發(fā)生切換,一直處于用戶態(tài),即線程一直都是active的;不會(huì)使線程進(jìn)入阻塞狀態(tài),減少了不必要的上下文切換,執(zhí)行速度快。
非自旋鎖在獲取不到鎖的時(shí)候會(huì)進(jìn)入阻塞狀態(tài),從而進(jìn)入內(nèi)核態(tài),當(dāng)獲取到鎖的時(shí)候需要從內(nèi)核態(tài)恢復(fù),需要線程上下文切換。(線程被阻塞后便進(jìn)入內(nèi)核(Linux)調(diào)度狀態(tài),這個(gè)會(huì)導(dǎo)致系統(tǒng)在用戶態(tài)與內(nèi)核態(tài)之間來回切換,嚴(yán)重影響鎖的性能)。
自旋鎖的使用
在linux kernel的實(shí)現(xiàn)中,經(jīng)常會(huì)遇到這樣的場景:共享數(shù)據(jù)被中斷上下文和進(jìn)程上下文訪問,該如何保護(hù)呢?
如果只有進(jìn)程上下文的訪問,那么可以考慮使用semaphore或者mutex的鎖機(jī)制,但是現(xiàn)在中斷上下文也摻和進(jìn)來,那些可以導(dǎo)致睡眠的lock就不能使用了,這時(shí)候,可以考慮使用spin lock。
在中斷上下文,是不允許睡眠的,所以,這里需要的是一個(gè)不會(huì)導(dǎo)致睡眠的鎖——spinlock。
換言之,中斷上下文要用鎖,首選 spinlock。
使用自旋鎖,有兩種方式定義一個(gè)鎖:
動(dòng)態(tài)的:
spinlock_t lock;spin_lock_init (&lock);
靜態(tài)的:
DEFINE_SPINLOCK(lock);
使用步驟
spinlock的使用很簡單:
我們要訪問臨界資源需要首先申請自旋鎖;
獲取不到鎖就自旋,如果能獲得鎖就進(jìn)入臨界區(qū);
當(dāng)自旋鎖釋放后,自旋在這個(gè)鎖的任務(wù)即可獲得鎖并進(jìn)入臨界區(qū),退出臨界區(qū)的任務(wù)必須釋放自旋鎖。
使用實(shí)例
static spinlock_t lock;static int flage = 1;spin_lock_init(&lock);static int hello_open (struct inode *inode, struct file *filep){ spin_lock(&lock); if(flage !=1) { spin_unlock(&lock); return -EBUSY; } flage =0; spin_unlock(&lock); return 0;}static int hello_release (struct inode *inode, struct file *filep){ flage = 1; return 0;}
補(bǔ)充
中斷上下文不能睡眠的原因是:
中斷處理的時(shí)候,不應(yīng)該發(fā)生進(jìn)程切換,因?yàn)樵谥袛郼ontext中,唯一能打斷當(dāng)前中斷handler的只有更高優(yōu)先級的中斷,它不會(huì)被進(jìn)程打斷,如果在 中斷context中休眠,則沒有辦法喚醒它,因?yàn)樗械膚ake_up_xxx都是針對某個(gè)進(jìn)程而言的,而在中斷context中,沒有進(jìn)程的概念,沒 有一個(gè)task_struct(這點(diǎn)對于softirq和tasklet一樣),因此真的休眠了,比如調(diào)用了會(huì)導(dǎo)致block的例程,內(nèi)核幾乎肯定會(huì)死。
schedule()在切換進(jìn)程時(shí),保存當(dāng)前的進(jìn)程上下文(CPU寄存器的值、進(jìn)程的狀態(tài)以及堆棧中的內(nèi)容),以便以后恢復(fù)此進(jìn)程運(yùn)行。中斷發(fā)生后,內(nèi)核會(huì)先保存當(dāng)前被中斷的進(jìn)程上下文(在調(diào)用中斷處理程序后恢復(fù));
但在中斷處理程序里,CPU寄存器的值肯定已經(jīng)變化了吧(最重要的程序計(jì)數(shù)器PC、堆棧SP等),如果此時(shí)因?yàn)樗呋蜃枞僮髡{(diào)用了schedule(),則保存的進(jìn)程上下文就不是當(dāng)前的進(jìn)程context了。所以不可以在中斷處理程序中調(diào)用schedule()。
內(nèi)核中schedule()函數(shù)本身在進(jìn)來的時(shí)候判斷是否處于中斷上下文:
if(unlikely(in_interrupt())) BUG();
因此,強(qiáng)行調(diào)用schedule()的結(jié)果就是內(nèi)核BUG。
中斷handler會(huì)使用被中斷的進(jìn)程內(nèi)核堆棧,但不會(huì)對它有任何影響,因?yàn)閔andler使用完后會(huì)完全清除它使用的那部分堆棧,恢復(fù)被中斷前的原貌。
處于中斷context時(shí)候,內(nèi)核是不可搶占的。因此,如果休眠,則內(nèi)核一定掛起。
自旋鎖的死鎖
自旋鎖不可遞歸,自己等待自己已經(jīng)獲取的鎖,會(huì)導(dǎo)致死鎖。
自旋鎖可以在中斷上下文中使用,但是試想一個(gè)場景:一個(gè)線程獲取了一個(gè)鎖,但是被中斷處理程序打斷,中斷處理程序也獲取了這個(gè)鎖(但是之前已經(jīng)被鎖住了,無法獲取到,只能自旋),中斷無法退出,導(dǎo)致線程中后面釋放鎖的代碼無法被執(zhí)行,導(dǎo)致死鎖。(如果確認(rèn)中斷中不會(huì)訪問和線程中同一個(gè)鎖,其實(shí)無所謂)。
一、考慮下面的場景(內(nèi)核搶占場景):
(1)進(jìn)程A在某個(gè)系統(tǒng)調(diào)用過程中訪問了共享資源 R
(2)進(jìn)程B在某個(gè)系統(tǒng)調(diào)用過程中也訪問了共享資源 R
會(huì)不會(huì)造成沖突呢?
假設(shè)在A訪問共享資源R的過程中發(fā)生了中斷,中斷喚醒了沉睡中的,優(yōu)先級更高的B,在中斷返回現(xiàn)場的時(shí)候,發(fā)生進(jìn)程切換,B啟動(dòng)執(zhí)行,并通過系統(tǒng)調(diào)用訪問了R,如果沒有鎖保護(hù),則會(huì)出現(xiàn)兩個(gè)thread進(jìn)入臨界區(qū),導(dǎo)致程序執(zhí)行不正確。OK,我們加上spin lock看看如何:A在進(jìn)入臨界區(qū)之前獲取了spin lock,同樣的,在A訪問共享資源R的過程中發(fā)生了中斷,中斷喚醒了沉睡中的,優(yōu)先級更高的B,B在訪問臨界區(qū)之前仍然會(huì)試圖獲取spin lock,這時(shí)候由于A進(jìn)程持有spin lock而導(dǎo)致B進(jìn)程進(jìn)入了永久的spin……怎么破?linux的kernel很簡單,在A進(jìn)程獲取spin lock的時(shí)候,禁止本CPU上的搶占(上面的永久spin的場合僅僅在本CPU的進(jìn)程搶占本CPU的當(dāng)前進(jìn)程這樣的場景中發(fā)生)。如果A和B運(yùn)行在不同的CPU上,那么情況會(huì)簡單一些:A進(jìn)程雖然持有spin lock而導(dǎo)致B進(jìn)程進(jìn)入spin狀態(tài),不過由于運(yùn)行在不同的CPU上,A進(jìn)程會(huì)持續(xù)執(zhí)行并會(huì)很快釋放spin lock,解除B進(jìn)程的spin狀態(tài)。
二、再考慮下面的場景(中斷上下文場景):
運(yùn)行在CPU0上的進(jìn)程A在某個(gè)系統(tǒng)調(diào)用過程中訪問了共享資源 R
運(yùn)行在CPU1上的進(jìn)程B在某個(gè)系統(tǒng)調(diào)用過程中也訪問了共享資源 R
外設(shè)P的中斷handler中也會(huì)訪問共享資源 R
在這樣的場景下,使用spin lock可以保護(hù)訪問共享資源R的臨界區(qū)嗎?
我們假設(shè)CPU0上的進(jìn)程A持有spin lock進(jìn)入臨界區(qū),這時(shí)候,外設(shè)P發(fā)生了中斷事件,并且調(diào)度到了CPU1上執(zhí)行,看起來沒有什么問題,執(zhí)行在CPU1上的handler會(huì)稍微等待一會(huì)CPU0上的進(jìn)程A,等它立刻臨界區(qū)就會(huì)釋放spin lock的,但是,如果外設(shè)P的中斷事件被調(diào)度到了CPU0上執(zhí)行會(huì)怎么樣?CPU0上的進(jìn)程A在持有spin lock的狀態(tài)下被中斷上下文搶占,而搶占它的CPU0上的handler在進(jìn)入臨界區(qū)之前仍然會(huì)試圖獲取spin lock,悲劇發(fā)生了,CPU0上的P外設(shè)的中斷handler永遠(yuǎn)的進(jìn)入spin狀態(tài),這時(shí)候,CPU1上的進(jìn)程B也不可避免在試圖持有spin lock的時(shí)候失敗而導(dǎo)致進(jìn)入spin狀態(tài)。為了解決這樣的問題,linux kernel采用了這樣的辦法:如果涉及到中斷上下文的訪問,spin lock需要和禁止本 CPU 上的中斷聯(lián)合使用。
三、再考慮下面的場景(底半部場景)
linux kernel中提供了豐富的bottom half的機(jī)制,雖然同屬中斷上下文,不過還是稍有不同。我們可以把上面的場景簡單修改一下:外設(shè)P不是中斷handler中訪問共享資源R,而是在的bottom half中訪問。使用spin lock+禁止本地中斷當(dāng)然是可以達(dá)到保護(hù)共享資源的效果,但是使用牛刀來殺雞似乎有點(diǎn)小題大做,這時(shí)候disable bottom half就可以了。
四、中斷上下文之間的競爭
同一種中斷handler之間在uni core和multi core上都不會(huì)并行執(zhí)行,這是linux kernel的特性。如果不同中斷handler需要使用spin lock保護(hù)共享資源,對于新的內(nèi)核(不區(qū)分fast handler和slow handler),所有handler都是關(guān)閉中斷的,因此使用spin lock不需要關(guān)閉中斷的配合。bottom half又分成softirq和tasklet,同一種softirq會(huì)在不同的CPU上并發(fā)執(zhí)行,因此如果某個(gè)驅(qū)動(dòng)中的softirq的handler中會(huì)訪問某個(gè)全局變量,對該全局變量是需要使用spin lock保護(hù)的,不用配合disable CPU中斷或者bottom half。tasklet更簡單,因?yàn)橥环Ntasklet不會(huì)多個(gè)CPU上并發(fā)。
自旋鎖的實(shí)現(xiàn)原理
數(shù)據(jù)結(jié)構(gòu)
首先定義一個(gè) spinlock_t 的數(shù)據(jù)類型,其本質(zhì)上是一個(gè)整數(shù)值(對該數(shù)值的操作需要保證原子性),該數(shù)值表示spin lock是否可用。初始化的時(shí)候被設(shè)定為1。當(dāng)thread想要持有鎖的時(shí)候調(diào)用spin_lock函數(shù),該函數(shù)將spin lock那個(gè)整數(shù)值減去1,然后進(jìn)行判斷,如果等于0,表示可以獲取spin lock,如果是負(fù)數(shù),則說明其他thread的持有該鎖,本thread需要spin。
內(nèi)核中的spinlock_t的數(shù)據(jù)類型定義如下:
typedef struct spinlock { struct raw_spinlock rlock; } spinlock_t;typedef struct raw_spinlock { arch_spinlock_t raw_lock;} raw_spinlock_t;
通用(適用于各種arch)的spin lock使用spinlock_t這樣的type name,各種arch定義自己的struct raw_spinlock。聽起來不錯(cuò)的主意和命名方式,直到linux realtime tree(PREEMPT_RT)提出對spinlock的挑戰(zhàn)。
spin lock的命名規(guī)范定義如下:
spinlock,在rt linux(配置了PREEMPT_RT)的時(shí)候可能會(huì)被搶占(實(shí)際底層可能是使用支持PI(優(yōu)先級翻轉(zhuǎn))的mutext)。
raw_spinlock,即便是配置了PREEMPT_RT也要頑強(qiáng)的spin
arch_spinlock,spin lock是和architecture相關(guān)的,
ARM 結(jié)構(gòu)體系 arch_spin_lock 接口實(shí)現(xiàn)
加鎖
同樣的,這里也只是選擇一個(gè)典型的API來分析,其他的大家可以自行學(xué)習(xí)。我們選擇的是 arch_spin_lock,其ARM32的代碼如下:
static inline void arch_spin_lock(arch_spinlock_t *lock){ unsigned long tmp; u32 newval; arch_spinlock_t lockval; prefetchw(&lock-》slock);---------(0) __asm__ __volatile__(“1: ldrex %0, [%3]\n”---------(1)“ add %1, %0, %4\n” ----------(2)“ strex %2, %1,[%3]\n”---------(3)“ teq %2, #0\n”-------------(4)“ bne 1b” : “=&r” (lockval), “=&r” (newval), “=&r” (tmp) : “r” (&lock-》slock), “I” (1 《《 TICKET_SHIFT) : “cc”); while (lockval.tickets.next != lockval.tickets.owner) {----(5) wfe();------------(6) lockval.tickets.owner = ACCESS_ONCE(lock-》tickets.owner);----(7) } smp_mb();-----------(8)}
(0)和preloading cache相關(guān)的操作,主要是為了性能考慮(1)lockval = lock-》slock (如果lock-》slock沒有被其他處理器獨(dú)占,則標(biāo)記當(dāng)前執(zhí)行處理器對lock-》slock地址的獨(dú)占訪問;否則不影響)(2)newval = lockval + (1 《《 TICKET_SHIFT)(3)strex tmp, newval, [&lock-》slock] (如果當(dāng)前執(zhí)行處理器沒有獨(dú)占lock-》slock地址的訪問,不進(jìn)行存儲(chǔ),返回1給temp;如果當(dāng)前處理器已經(jīng)獨(dú)占lock-》slock內(nèi)存訪問,則對內(nèi)存進(jìn)行寫,返回0給temp,清除獨(dú)占標(biāo)記) lock-》tickets.next = lock-》tickets.next + 1(4)檢查是否寫入成功 lockval.tickets.next(5)初始化時(shí)lock-》tickets.owner、lock-》tickets.next都為0,假設(shè)第一次執(zhí)行arch_spin_lock,lockval = *lock,lock-》tickets.next++,lockval.tickets.next 等于 lockval.tickets.owner,獲取到自旋鎖;自旋鎖未釋放,第二次執(zhí)行的時(shí)候,lock-》tickets.owner = 0, lock-》tickets.next = 1,拷貝到lockval后,lockval.tickets.next != lockval.tickets.owner,會(huì)執(zhí)行wfe等待被自旋鎖釋放被喚醒,自旋鎖釋放時(shí)會(huì)執(zhí)行 lock-》tickets.owner++,lockval.tickets.owner重新賦值(6)暫時(shí)中斷掛起執(zhí)行。如果當(dāng)前spin lock的狀態(tài)是locked,那么調(diào)用wfe進(jìn)入等待狀態(tài)。更具體的細(xì)節(jié)請參考ARM WFI和WFE指令中的描述。(7)其他的CPU喚醒了本cpu的執(zhí)行,說明owner發(fā)生了變化,該新的own賦給lockval,然后繼續(xù)判斷spin lock的狀態(tài),也就是回到step 5。(8)memory barrier的操作,具體可以參考memory barrier中的描述。
釋放鎖
static inline void arch_spin_unlock(arch_spinlock_t *lock){ smp_mb(); lock-》tickets.owner++; ---------------------- (0) dsb_sev(); ---------------------------------- (1)}
(0)lock-》tickets.owner增加1,下一個(gè)被喚醒的處理器會(huì)檢查該值是否與自己的lockval.tickets.next相等,lock-》tickets.owner代表可以獲取的自旋鎖的處理器,lock-》tickets.next你一個(gè)可以獲取的自旋鎖的owner;處理器獲取自旋鎖時(shí),會(huì)先讀取lock-》tickets.next用于與lock-》tickets.owner比較并且對lock-》tickets.next加1,下一個(gè)處理器獲取到的lock-》tickets.next就與當(dāng)前處理器不一致了,兩個(gè)處理器都與lock-》tickets.owner比較,肯定只有一個(gè)處理器會(huì)相等,自旋鎖釋放時(shí)時(shí)對lock-》tickets.owner加1計(jì)算,因此,先申請自旋鎖多處理器lock-》tickets.next值更新,自然先獲取到自旋鎖
(1)執(zhí)行sev指令,喚醒wfe等待的處理器
自旋鎖導(dǎo)致死鎖實(shí)例
死鎖的2種情況
1)擁有自旋鎖的進(jìn)程A在內(nèi)核態(tài)阻塞了,內(nèi)核調(diào)度B進(jìn)程,碰巧B進(jìn)程也要獲得自旋鎖,此時(shí)B只能自旋轉(zhuǎn)。而此時(shí)搶占已經(jīng)關(guān)閉,不會(huì)調(diào)度A進(jìn)程了,B永遠(yuǎn)自旋,產(chǎn)生死鎖。
2)進(jìn)程A擁有自旋鎖,中斷到來,CPU執(zhí)行中斷函數(shù),中斷處理函數(shù),中斷處理函數(shù)需要獲得自旋鎖,訪問共享資源,此時(shí)無法獲得鎖,只能自旋,產(chǎn)生死鎖。
如何避免死鎖
如果中斷處理函數(shù)中也要獲得自旋鎖,那么驅(qū)動(dòng)程序需要在擁有自旋鎖時(shí)禁止中斷;
自旋鎖必須在可能的最短時(shí)間內(nèi)擁有;
避免某個(gè)獲得鎖的函數(shù)調(diào)用其他同樣試圖獲取這個(gè)鎖的函數(shù),否則代碼就會(huì)死鎖;不論是信號量還是自旋鎖,都不允許鎖擁有者第二次獲得這個(gè)鎖,如果試圖這么做,系統(tǒng)將掛起;
鎖的順序規(guī)則 按同樣的順序獲得鎖; 如果必須獲得一個(gè)局部鎖和一個(gè)屬于內(nèi)核更中心位置的鎖,則應(yīng)該首先獲取自己的局部鎖 ; 如果我們擁有信號量和自旋鎖的組合,則必須首先獲得信號量;在擁有自旋鎖時(shí)調(diào)用down(可導(dǎo)致休眠)是個(gè)嚴(yán)重的錯(cuò)誤的。
死鎖舉例
因?yàn)樽孕i持有時(shí)間非常短,沒有直觀的現(xiàn)象,下面舉一個(gè)會(huì)導(dǎo)致死鎖的實(shí)例。
運(yùn)行條件
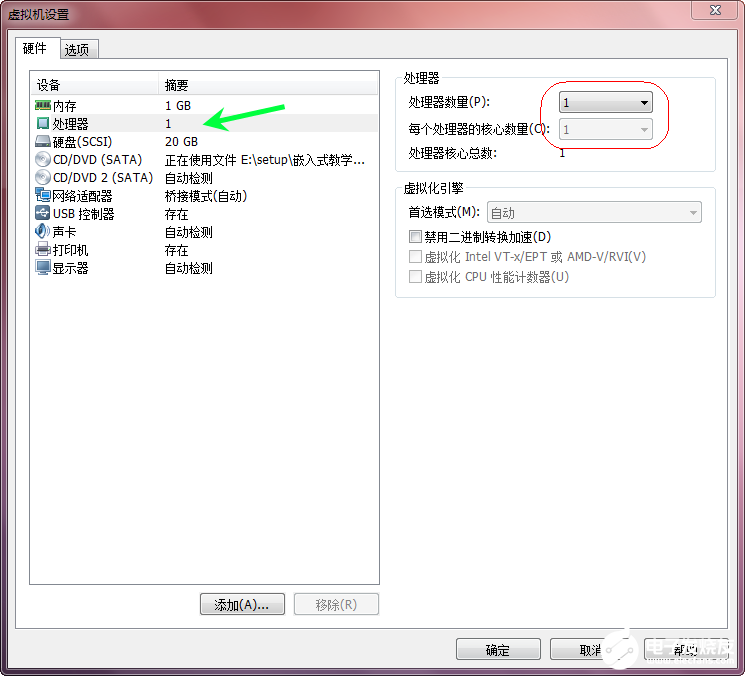
虛擬機(jī):vmware
OS :Ubuntu 14
配置 :將虛擬機(jī)的處理個(gè)數(shù)設(shè)置為1,否則不會(huì)死鎖
原理
針對單CPU,擁有自旋鎖的任務(wù)不應(yīng)該調(diào)度會(huì)引起休眠的函數(shù),否則會(huì)導(dǎo)致死鎖。
步驟:
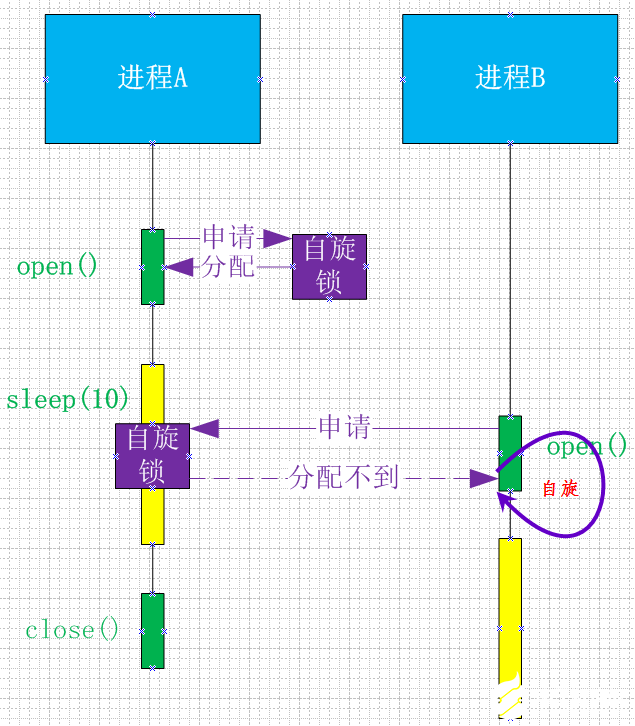
進(jìn)程A在open()字符設(shè)備后,對應(yīng)的內(nèi)核函數(shù)會(huì)申請自旋鎖,此時(shí)自旋鎖空閑,申請到自旋鎖,進(jìn)程A隨即進(jìn)入執(zhí)行sleep()函數(shù)進(jìn)入休眠;
在進(jìn)程A 處于sleep期間,自旋鎖一直屬于進(jìn)程A所有;
運(yùn)行進(jìn)程B,進(jìn)程B執(zhí)行open函數(shù),對應(yīng)的內(nèi)核函數(shù)也會(huì)申請自旋鎖,此時(shí)自旋鎖歸進(jìn)程A所有,所以進(jìn)程B進(jìn)入自旋狀態(tài);
因?yàn)榇藭r(shí)搶占已經(jīng)關(guān)閉,系統(tǒng)死鎖。
驅(qū)動(dòng)代碼如下:
#include 《linux/init.h》#include 《linux/module.h》#include 《linux/kdev_t.h》#include 《linux/fs.h》#include 《linux/cdev.h》#include 《linux/device.h》#include 《linux/spinlock.h》static int major = 250;static int minor = 0;static dev_t devno;static struct cdev cdev;static struct class *cls;static struct device *test_device;static spinlock_t lock;static int flage = 1;#define DEAD 1static int hello_open (struct inode *inode, struct file *filep){ spin_lock(&lock); if(flage !=1) { spin_unlock(&lock); return -EBUSY; } flage =0; #if DEAD #elif spin_unlock(&lock); #endif return 0;}static int hello_release (struct inode *inode, struct file *filep){ flage = 1; #if DEAD spin_unlock(&lock); #endif return 0;}static struct file_operations hello_ops ={ .open = hello_open, .release = hello_release,};static int hello_init(void){ int result; int error; printk(“hello_init \n”); result = register_chrdev( major, “hello”, &hello_ops); if(result 《 0) { printk(“register_chrdev fail \n”); return result; } devno = MKDEV(major,minor); cls = class_create(THIS_MODULE,“helloclass”); if(IS_ERR(cls)) { unregister_chrdev(major,“hello”); return result; } test_device = device_create(cls,NULL,devno,NULL,“test”); if(IS_ERR(test_device )) { class_destroy(cls); unregister_chrdev(major,“hello”); return result; } spin_lock_init(&lock); return 0;}static void hello_exit(void){ printk(“hello_exit \n”); device_destroy(cls,devno); class_destroy(cls); unregister_chrdev(major,“hello”); return;}module_init(hello_init);module_exit(hello_exit);MODULE_LICENSE(“GPL”);
測試程序如下:
#include 《stdio.h》#include 《sys/types.h》#include 《sys/stat.h》#include 《fcntl.h》main(){ int fd; fd = open(“/dev/test”,O_RDWR); if(fd《0) { perror(“open fail \n”); return; } sleep(20); close(fd); printf(“open ok \n ”);}
測試步驟:
編譯加載內(nèi)核
makeinsmod hello.ko
運(yùn)行進(jìn)程A
gcc test.c -o a./a
打開一個(gè)新的終端,運(yùn)行進(jìn)程B
gcc test.c -o b./b
注意,一定要在進(jìn)程A沒有退出的時(shí)候運(yùn)行進(jìn)程B。
-
Linux
+關(guān)注
關(guān)注
87文章
11304瀏覽量
209524 -
鎖存
+關(guān)注
關(guān)注
0文章
21瀏覽量
20639
發(fā)布評論請先 登錄
相關(guān)推薦
自旋憶阻器:最像大腦的存儲(chǔ)器
自旋極化:開創(chuàng)半導(dǎo)體器件設(shè)計(jì)的新路徑
TDK成功研發(fā)出用于神經(jīng)形態(tài)設(shè)備的自旋憶阻器
d鎖存器解決了sr鎖存器的什么問題
rs鎖存器和sr鎖存器有什么區(qū)別嗎
互斥鎖和自旋鎖的實(shí)現(xiàn)原理
使用http client時(shí)出現(xiàn)了assert failed: spinlock_release spinlock.h:140 (core_id == lock->owner)怎么解決?
freertos里是否有spinlock或者類似的接口?
全志R128 SDK HAL 模塊開發(fā)指南——HW Spinlock
MM32自旋系列電機(jī)專用 24V電機(jī)驅(qū)動(dòng)DK板功能介紹
通過TriVista高分辨率光譜測量系統(tǒng)測量量子材料的精細(xì)結(jié)構(gòu)和自旋相互作用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論