 SVM與神經網絡結合會發生什么?
SVM與神經網絡結合會發生什么?
SVM 是機器學習領域的經典算法之一。如果將 SVM推廣到神經網絡,會發生什么呢?
支持向量機(Support Vector Machine,SVM)是大多數 AI 從業者比較熟悉的概念。它是一種在分類與回歸分析中分析數據的監督式學習模型與相關的學習算法。給定一組訓練實例,每個訓練實例被標記為屬于兩個類別中的一個或另一個,SVM 訓練算法創建一個將新的實例分配給兩個類別之一的模型,使其成為非概率二元線性分類器。SVM 模型將實例表示為空間中的點,這樣映射就使得單獨類別的實例被盡可能寬的明顯的間隔分開。然后,將新的實例映射到同一空間,并基于它們落在間隔的哪一側來預測所屬類別。 除了進行線性分類之外,SVM 還可以使用所謂的核技巧有效地進行非線性分類,將其輸入隱式映射到高維特征空間中。 本文將介紹一篇來自蒙特利爾大學的論文《SVM、Wasserstein 距離、梯度懲罰 GAN 之間的聯系》。在這篇論文中,研究者闡述了如何從同一框架中得到 SVM 和梯度懲罰 GAN。 據論文一作介紹,這項研究的靈感來自她的博士資格考試。在準備過程中,她學習了 SVM,并思考了這個問題:「如果將 SVM 推廣到神經網絡會發生什么?」順著這個思路,研究者發現了 SVM、GAN、Wasserstein 距離之間的關系。

該研究將最大間隔分類器(MMC)的概念擴展到任意范數和非線性函數。支持向量機是 MMC 的一個特例。研究者發現,MMC 可以形式化為積分概率度量(Integral Probability Metrics,IPM)或具備某種形式梯度范數懲罰的分類器。這表明它與梯度懲罰 GAN 有直接關聯。 該研究表明,Wasserstein GAN、標準 GAN、最小二乘 GAN 和具備梯度懲罰的 Hinge GAN 中的判別器都是 MMC,并解釋了 GAN 中最大化間隔的作用。研究者假設 L^∞ 范數懲罰和 Hinge 損失生成的 GAN 優于 L^2 范數懲罰生成的 GAN,并通過實驗進行了驗證。此外,該研究還導出了 Relativistic paired (Rp) 和 average (Ra) GAN 的間隔。 這篇論文共包含幾部分:在第二章中,研究者回顧了 SVM 和 GAN;第三章,研究者概述了最大間隔分類器(MMC)的概念;第四章,研究者用梯度懲罰解釋了 MMC 和 GAN 之間的聯系。其中 4.1 提到了強制 1-Lipschitz 等價于假設一個有界梯度,這意味著 Wasserstein 距離可以用 MMC 公式來近似估算;4.2 描述了在 GAN 中使用 MMC 的好處;4.3 假定 L1 范數間隔能夠導致更具魯棒性的分類器;4.4 推導了 Relativistic paired GAN 和 Relativistic average GAN 的間隔。最后,第五章提供了實驗結果以支持文章假設。 SVM 是 MMC 的一個特例。MMC 是使間隔最大化的分類器 f(間隔指的是決策邊界與數據點之間的距離)。決策邊界是指我們無法分辨出樣本類別的區域(所有 x 使得 f(x)=0)。 Soft-SVM 是一種特殊情況,它可以使最小 L2 范數間隔最大化。下圖展示了實際使用中的 Soft-SVM:
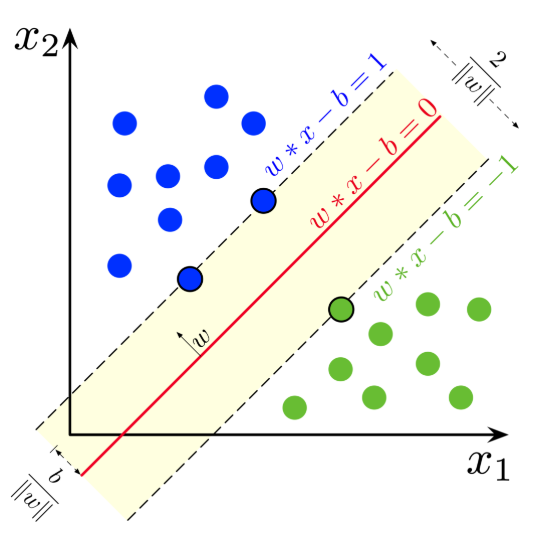
在解釋這一結果之前,我們需要了解一個關鍵要素。關于「間隔」有多種定義: (1)樣本與邊界之間的最小距離; (2)距邊界最近的點與邊界之間的最小距離。 定義(2)更為常用。但是如果使用此定義,那么 SVM 文獻中所謂的「函數間隔(functional margin)」和「幾何間隔(geometric margin)」就都不能被視為間隔。這可能會讓人十分困惑。 理解這種差異更好的一種方式是:
將(1)視為「樣本的間隔」;
將(2)視為「數據集的間隔」。
但是,為了消除這兩種情況的歧義,本文將前者稱為「間隔(margin)」,將后者稱為「最小間隔(minimum margin)」。 Hard-SVM(原始形式)解決了最大化最小間隔的問題。Soft-SVM 解決了另一個更簡單的問題——最大化期望 soft-margin(最小化期望 Hinge 損失)。這個問題很容易解決,hinge 損失確保遠離邊界的樣本不會對假重復 Hard-SVM 效果的嘗試產生任何影響。 從這個角度看,最大化期望間隔(而不是最大化最小間隔)仍會導致最大間隔分類器,但是分類器可能會受到遠離邊界的點的影響(如果不使用 Hinge 損失的話)。因此,最大化期望間隔意味著最大化任何樣本(即數據點)與決策邊界之間的平均距離。這些方法就是最大間隔分類器(MMC)的示例。 為了盡可能地通用化,該研究設計了一個框架來導出 MMC 的損失函數。研究者觀察到,該框架可以導出帶有梯度懲罰的基于間隔的目標函數(目標函數 F 的形式為 F(yf(x)))。這就意味著標準 GAN、最小二乘 GAN、WGAN 或 HingeGAN-GP 都是 MMC。所有這些方法(和 WGAN-GP 一樣使用 L2 梯度規范懲罰時)都能最大化期望 L2 范數間隔。 研究者還展示了,使用 Lipschitz-1 判別器的大多數 GAN(譜歸一化 HingeGAN、WGAN、WGAN-GP 等)都可被表示為 MMC,因為假定 1-Lipschitz 等效于假定有界梯度(因此可作為一種梯度懲罰形式)。 重要的是,這意味著我們可以將最成功的 GAN(BigGAN、StyleGAN)看作 MMC。假定 Lipschitz-1 判別器一直被看作實現優秀 GAN 的關鍵因素,但它可能需要一個能夠最大化間隔的判別器和相對判別器(Relativistic Discriminator)。該研究基于 MMC 判別器給偽生成樣本帶來更多梯度信號的事實,闡述了其優點。 在這一點上,讀者可能有疑問:「是不是某些間距比其它間距更好?是的話,我們能做出更好的 GAN 嗎?」 這兩個問題的答案都是肯定的。最小化 L1 范數的損失函數比最小化 L2 范數的損失函數對異常值更具魯棒性。基于這一事實,研究者提出質疑:L1 范數間隔會帶來魯棒性更強的分類器,生成的 GAN 也可能比 L2 范數間隔更佳。 重要的是,L1 范數間隔會造成 L∞ 梯度范數懲罰,L2 范數間隔會造成 L2 梯度范數懲罰。該研究進行了一些實驗,表明 L∞ 梯度范數懲罰(因使用 L1 間隔產生)得到的 GAN 性能更優。 此外,實驗表明, HingeGAN-GP 通常優于 WGAN-GP(這是說得通的,因為 hinge 損失對遠離邊界的異常值具有魯棒性),并且僅懲罰大于 1 的梯度范數效果更好(而不是像 WGAN-GP 一樣,使所有的梯度范數逼近 1)。因此,盡管這是一項理論研究,但研究者發現了一些對改進 GAN 非常有用的想法。 使用該框架,研究者能夠為 Relativistic paired (Rp) GAN 和 Relativistic average (Ra) GAN 定義決策邊界和間隔。人們常常想知道為什么 RpGAN 的性能不如 RaGAN,在這篇文章中,研究者對此進行了闡述。 使用 L1 范數間隔的想法只是冰山一角,該框架還能通過更具魯棒性的間隔,設計出更優秀的 GAN(從而提供更好的梯度懲罰或「光譜」歸一化技術)。最后,對于為什么梯度懲罰或 1-Lipschitz 對不估計 Wasserstein 距離的 GAN 有效,該研究也提供了明確的理論依據,更多細節可參考原論文。
-
神經網絡
+關注
關注
42文章
4773瀏覽量
100872 -
SVM
+關注
關注
0文章
154瀏覽量
32493
原文標題:當支持向量機遇上神經網絡:這項研究揭示了SVM、GAN、Wasserstein距離之間的關系
文章出處:【微信號:cas-ciomp,微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡教程(李亞非)
非局部神經網絡,打造未來神經網絡基本組件
卷積神經網絡如何使用
【案例分享】ART神經網絡與SOM神經網絡
如何設計BP神經網絡圖像壓縮算法?
如何構建神經網絡?
基于BP神經網絡的PID控制
什么是模糊神經網絡_模糊神經網絡原理詳解





 工商網監
工商網監
評論