") 用視覺替代激光雷達,可能嗎?特斯拉為何不用激光雷達?
用視覺替代激光雷達,可能嗎?特斯拉為何不用激光雷達?
在自動駕駛的感知領(lǐng)域,行業(yè)內(nèi)分成了立場鮮明的兩派——視覺派和激光雷達派。特斯拉是視覺派最堅定的守護者,甚至不惜用一切最惡毒的形容詞將激光雷達貶到一無是處。但按照埃隆·馬斯克一貫的作風,在“詛咒”某些事情的背后,他一定也在“敬畏”某些事情。
當一個系統(tǒng)想要變得可靠,一個關(guān)鍵原則是把這個系統(tǒng)做“冗余”。因此,汽車行業(yè)里的多數(shù)人,都在為這個極度需要可靠的物件做加法。
但特斯拉恰恰相反,它不斷地在為汽車做減法:大幅降低車輛線束長度、大幅減少車身零部件數(shù)量、大幅壓縮生產(chǎn)制造工序。所有這一切都是從技術(shù)快速落地的商業(yè)化考慮——足夠便宜,用戶才能接受。
如果秉持同樣的出發(fā)點,就不難理解埃隆·馬斯克多次在公開場合對激光雷達無下限的貶低:
2015年10月——激光雷達毫無意義,對于自動駕駛汽車來說沒有必要。
2017年4月——激光雷達很差勁,他們會拋棄激光雷達,記住我的話,這是我的預測。
2018年2月——激光雷達昂貴、丑陋、沒有必要。
2019年4月——激光雷達就像人身上長了一堆闌尾,闌尾本身的存在基本是無意義的,如果長了一堆的話,那就太可笑了。任何依賴激光雷達的公司都可能無疾而終。
當然,從事實的結(jié)果來講,馬斯克有足夠的資本藐視激光雷達,因為依靠視覺方案的特斯拉是目前公認這個星球上將量產(chǎn)輔助駕駛做到最好的公司。
但是,埃隆·馬斯克真的就將激光雷達踩在腳底了嗎?恰恰相反,他清楚地認識到視覺與激光雷達的優(yōu)劣勢,同時不斷推動讓視覺方案做到本只能由激光雷達做到的事情。
特斯拉為何不用激光雷達?
理論上說,視覺與激光雷達是完美的互補體。
視覺方案中的圖像傳感器能以高幀率、高分辨率獲取周圍復雜的環(huán)境信息,且價格便宜。但圖像傳感器是一種被動式傳感器,其本身并不發(fā)光,成像質(zhì)量受到環(huán)境亮度影響較大,在惡劣環(huán)境下完成感知任務(wù)的難度會大幅提升。
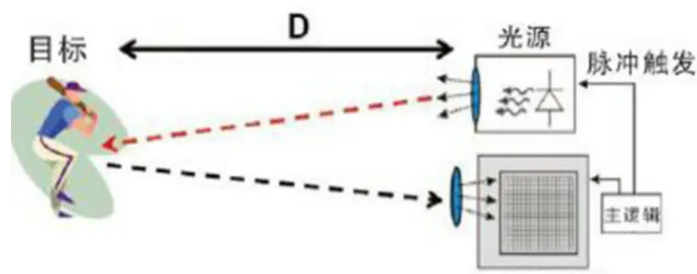
激光雷達是一種主動式傳感器,通過發(fā)射脈沖激光并探測目標的散射光特性獲取目標的深度信息,具有精度高、范圍大、抗干擾能力強的特性。但是,激光雷達獲取的數(shù)據(jù)稀疏無序、難以直接利用,且激光單色的特性讓其無法獲取顏色和紋理信息。
所以,基于可靠性的考慮,行業(yè)中多數(shù)人在研究的是如何將視覺與激光雷達所獲得的信息進行融合,實現(xiàn)更加精確的環(huán)境感知。
但在馬斯克看來,無論是汽車還是道路,都是人類為人類設(shè)計的。既然人類可以通過視覺收集信息+大腦處理信息的方式進行安全駕駛,那就意味著自動駕駛也可以通過同樣的方式實現(xiàn)。如果強行加入一個激光雷達作為“超人感官”,就好比人在行走時拿著一根拐杖。
顯然,拐杖不是創(chuàng)新,而是限制創(chuàng)新。
另一方面,激光雷達的高成本,以及因為加入激光雷達后造成電氣系統(tǒng)的復雜,不符合特斯拉一貫做減法的造車理念。
視覺的瓶頸在算法,激光雷達的瓶頸在原理。顯然,視覺具有更大的開發(fā)潛力,也擁有理論上更高的上限。做對的事情,不做容易的事情,也是一直以來馬斯克的作風。
至于在公開場合頻繁唱衰激光雷達,就權(quán)當是特斯拉及埃隆·馬斯克出色公關(guān)水平的一種體現(xiàn)。
特斯拉如何克服視覺劣勢?
從2D平面圖像推斷精確的3D立體實景,實際上是非常困難的。
以下圖中這輛MPV為例,如果只看左側(cè)的2D圖像,似乎用視覺和激光雷達標注的形狀都是準確的,但是如果放在3D的場景中,就會發(fā)現(xiàn)使用視覺方案標注的形狀不僅偏長、偏窄,而且缺少了汽車的側(cè)面。
因為在2D圖像中,很容易找到車輛的左前角和右后角,但是左后角卻沒有明顯的特征,由于車輛尾部的傾斜、向上收窄,就會造成對整體寬度的低估。同時,依靠發(fā)動機艙蓋超出車頂?shù)牟糠止浪丬囬L,也會導致在縱深方向上的高估。
而這還僅僅是一個在高亮度環(huán)境下相對規(guī)則的物體,如果環(huán)境變暗,或是加入更多的遮蔽物、障礙物,情況會變得更加極端。比如在黑暗樹蔭中的二輪車,純視覺方案很難分辨。
因此,從根本算法上解決視覺信息的準確處理,就是特斯拉自動駕駛體系的絕對核心技術(shù)。
實現(xiàn)自動駕駛功能,更多的是技巧、記憶和經(jīng)驗,而不只是推理和計算,深度學習的算法就是為了提高自動駕駛的成熟程度。特斯拉完善視覺算法的一大優(yōu)勢,就是通過海量的車主駕駛數(shù)據(jù),進行神經(jīng)網(wǎng)絡(luò)訓練,從而不斷覆蓋更多的工況與場景,達到視覺算法無限接近人類判斷的目的。
這一方面取決于特斯拉自動駕駛硬件的高算力,另一方面是特斯拉在“模式識別模型”領(lǐng)域的絕對領(lǐng)先——超大的數(shù)據(jù)規(guī)模、多樣化的數(shù)據(jù)覆蓋度、真實的數(shù)據(jù)場景。歸根到底,全世界超過百萬輛的特斯拉車主,都是特斯拉自動駕駛算法訓練的眾測者。
這里不得不提的就是特斯拉獨有的“影子模式”,這是特斯拉在不影響算法訓練的速度與準確性的基礎(chǔ)上,大幅降低因數(shù)據(jù)量過大造成訓練成本提升的關(guān)鍵。
藏在駕駛員背后的“影子”,始終在觀察外部環(huán)境與駕駛員的動作。如果在某個特定場景中駕駛員的操作與“影子”預想的一致,那么數(shù)據(jù)不會被上報;如果“影子”發(fā)現(xiàn)它的判斷與駕駛員操作不相符,那么這次的數(shù)據(jù)就會被送到特斯拉的服務(wù)器中,并對算法進行修正性訓練,達到一定程度后再次下發(fā)到車輛中。
這個過程中,駕駛員不會有任何感知,但特斯拉事實上已經(jīng)完成了“模式識別-算法學習-反饋-升級-應(yīng)用”的閉環(huán)。正是在無數(shù)次的訓練后,特斯拉不斷提升視覺方案的精度,克服視覺方案固有的劣勢,并且將算法優(yōu)勢變成牢不可破的技術(shù)門檻。
用視覺替代激光雷達,可能嗎?
特斯拉最終希望達到的目的,是讓其視覺處理能力達到激光雷達的可見性,在行業(yè)中被稱為“偽激光雷達”。
激光雷達通過每個激光點的距離,實時還原環(huán)境。而特斯拉則是要去預測每個像素的深度,然后將其投射出來,從而復制激光雷達的功能。
分析2D圖像的每個像素,將其還原成真實的3D場景,毫無疑問其中的核心能力,依然是圖像處理的算法以及支持這一算法的高算力硬件,也是特斯拉將其視覺方案進一步升級的體現(xiàn)。
這就不難理解,為何特斯拉一定要將其自動駕駛系統(tǒng)的研發(fā)深入到芯片級。
在特斯拉公開展示的通過“偽激光雷達”還原的3D地圖中,明亮環(huán)境下已經(jīng)非常接近于激光雷達的效果,但相信這只是一個階段性成果,更多的場景仍然有待考察。“偽激光雷達”這項從2018年才開始在學術(shù)界有可見報道的研究,對特斯拉同樣是一個極具探索挑戰(zhàn)的問題。
但如果特斯拉要依靠純視覺方案解決L4乃至L5級別的完全自動駕駛,通過強大的計算能力解決2D圖像到3D實景的轉(zhuǎn)換,是必須要攻克的難關(guān)。
寫在最后
如果一個人還在使用指南針和地圖,此時你給他一個GPS,意味著只是提供了解決問題的一個極有價值的工具,但卻沒有解決問題。激光雷達是那個解決問題的工具,但是視覺方案也許能從一個新的維度解決問題。
是視覺方案變強大的速度更快,還是激光雷達降價的速度更快?無人能給出答案,所以才會產(chǎn)生今天的行業(yè)路線紛爭,每一種路線的踐行者都堅信自己會是最終的勝利者。在無比自信的馬斯克身上,這點體現(xiàn)得尤為明顯。
責任編輯:pj
-
傳感器
+關(guān)注
關(guān)注
2551文章
51106瀏覽量
753617 -
激光雷達
+關(guān)注
關(guān)注
968文章
3972瀏覽量
189930 -
自動駕駛
+關(guān)注
關(guān)注
784文章
13814瀏覽量
166462
發(fā)布評論請先 登錄
相關(guān)推薦
激光雷達,明年要降價至200美元

激光雷達會傷害眼睛嗎?

激光雷達的維護與故障排查技巧
激光雷達技術(shù)的基于深度學習的進步
激光雷達技術(shù)的發(fā)展趨勢
光學雷達和激光雷達的區(qū)別是什么
一文看懂激光雷達

基于FPGA的激光雷達控制板

馬斯克稱特斯拉的FSD系統(tǒng)不需要激光雷達
Luminar: 特斯拉是其最大激光雷達客戶
硅基片上激光雷達的測距原理

激光雷達的探測技術(shù)介紹 機載激光雷達發(fā)展歷程
華為詳細解讀激光雷達
激光雷達LIDAR基本工作原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論