") 深度學(xué)習(xí)&計(jì)算機(jī)視覺(jué)方向的相關(guān)面試題
深度學(xué)習(xí)&計(jì)算機(jī)視覺(jué)方向的相關(guān)面試題
導(dǎo)讀
正值秋招進(jìn)行時(shí),本文收集了深度學(xué)習(xí)&計(jì)算機(jī)視覺(jué)方向的相關(guān)面試題,涵蓋反卷積、神經(jīng)網(wǎng)絡(luò)、目標(biāo)檢測(cè)等多個(gè)方面,內(nèi)容非常全面。
1.什么是反卷積?
反卷積也稱(chēng)為轉(zhuǎn)置卷積,如果用矩陣乘法實(shí)現(xiàn)卷積操作,將卷積核平鋪為矩陣,則轉(zhuǎn)置卷積在正向計(jì)算時(shí)左乘這個(gè)矩陣的轉(zhuǎn)置WT,在反向傳播時(shí)左乘W,與卷積操作剛好相反,需要注意的是,反卷積不是卷積的逆運(yùn)算。
一般的卷積運(yùn)算可以看成是一個(gè)其中非零元素為權(quán)重的稀疏矩陣C與輸入的圖像進(jìn)行矩陣相乘,反向傳播時(shí)的運(yùn)算實(shí)質(zhì)為C的轉(zhuǎn)置與loss對(duì)輸出y的導(dǎo)數(shù)矩陣的矩陣相乘。
逆卷積的運(yùn)算過(guò)程與卷積正好相反,是正向傳播時(shí)做成C的轉(zhuǎn)置,反向傳播時(shí)左乘C
2.反卷積有哪些用途?
實(shí)現(xiàn)上采樣;近似重構(gòu)輸入圖像,卷積層可視化。
3.解釋神經(jīng)網(wǎng)絡(luò)的萬(wàn)能逼近定理
只要激活函數(shù)選擇得當(dāng),神經(jīng)元的數(shù)量足夠,至少有一個(gè)隱含層的神經(jīng)網(wǎng)絡(luò)可以逼近閉區(qū)間上任意一個(gè)連續(xù)函數(shù)到任意指定的精度。
4.神經(jīng)網(wǎng)絡(luò)是生成模型還是判別模型?
判別模型,直接輸出類(lèi)別標(biāo)簽,或者輸出類(lèi)后驗(yàn)概率p(y|x)
5.Batch Normalization 和 Group Normalization有何區(qū)別?
BN是在 batch這個(gè)維度上進(jìn)行歸一化,GN是計(jì)算channel方向每個(gè)group的均值方差.
6.模型壓縮的主要方法有哪些?
從模型結(jié)構(gòu)上優(yōu)化:模型剪枝、模型蒸餾、automl直接學(xué)習(xí)出簡(jiǎn)單的結(jié)構(gòu)
模型參數(shù)量化將FP32的數(shù)值精度量化到FP16、INT8、二值網(wǎng)絡(luò)、三值網(wǎng)絡(luò)等。
7.目標(biāo)檢測(cè)中IOU是如何計(jì)算的?
檢測(cè)結(jié)果與 Ground Truth 的交集比上它們的并集,即為檢測(cè)的準(zhǔn)確率 IoU
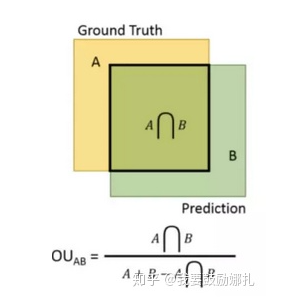
8.使用深度卷積網(wǎng)絡(luò)做圖像分類(lèi)如果訓(xùn)練一個(gè)擁有1000萬(wàn)個(gè)類(lèi)的模型會(huì)碰到什么問(wèn)題?
提示:內(nèi)存/顯存占用;模型收斂速度等
9.深度學(xué)習(xí)中為什么不用二階導(dǎo)去優(yōu)化?
Hessian矩陣是n*n, 在高維情況下這個(gè)矩陣非常大,計(jì)算和存儲(chǔ)都是問(wèn)題。
10.深度機(jī)器學(xué)習(xí)中的mini-batch的大小對(duì)學(xué)習(xí)效果有何影響?
mini-batch太小會(huì)導(dǎo)致收斂變慢,太大容易陷入sharp minima,泛化性不好。
11.dropout的原理
可以把dropout看成是 一種ensemble方法,每次做完dropout相當(dāng)于從原網(wǎng)絡(luò)中找到一個(gè)更瘦的網(wǎng)絡(luò)。
強(qiáng)迫神經(jīng)元和其他隨機(jī)挑選出來(lái)的神經(jīng)元共同工作,減弱了神經(jīng)元節(jié)點(diǎn)間的聯(lián)合適應(yīng)性,增強(qiáng)泛化能力
使用dropout得到更多的局部簇,同等數(shù)據(jù)下,簇變多了,因而區(qū)分性變大,稀疏性也更大
12.為什么SSD對(duì)小目標(biāo)檢測(cè)效果不好:
小目標(biāo)對(duì)應(yīng)的anchor比較少,其對(duì)應(yīng)的feature map上的pixel難以得到訓(xùn)練,這也是為什么SSD在augmentation之后精確度上漲(因?yàn)閏rop之后小目標(biāo)就變?yōu)榇竽繕?biāo))
要檢測(cè)小目標(biāo)需要足夠大的feature map來(lái)提供精確特征,同時(shí)也需要足夠的語(yǔ)義信息來(lái)與背景作區(qū)分
13.空洞卷積及其優(yōu)缺點(diǎn)
pooling操作雖然能增大感受野,但是會(huì)丟失一些信息。空洞卷積在卷積核中插入權(quán)重為0的值,因此每次卷積中會(huì)skip掉一些像素點(diǎn);
空洞卷積增大了卷積輸出每個(gè)點(diǎn)的感受野,并且不像pooling會(huì)丟失信息,在圖像需要全局信息或者需要較長(zhǎng)sequence依賴的語(yǔ)音序列問(wèn)題上有著較廣泛的應(yīng)用。
14.Fast RCNN中位置損失為何使用Smooth L1:
表達(dá)式為:
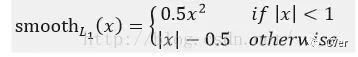
作者這樣設(shè)置的目的是想讓loss對(duì)于離群點(diǎn)更加魯棒,相比于L2損失函數(shù),其對(duì)離群點(diǎn)、異常值(outlier)不敏感,可控制梯度的量級(jí)使訓(xùn)練時(shí)不容易跑飛。
15.Batch Normalization
使用BN的原因是網(wǎng)絡(luò)訓(xùn)練中每一層不斷改變的參數(shù)會(huì)導(dǎo)致后續(xù)每一層輸入的分布發(fā)生變化,而學(xué)習(xí)的過(guò)程又要使每一層去適應(yīng)輸入的分布,因此不得不降低網(wǎng)絡(luò)的學(xué)習(xí)率,并且要小心得初始化(internal covariant shift)
如果僅通過(guò)歸一化方法使得數(shù)據(jù)具有零均值和單位方差,則會(huì)降低層的表達(dá)能力(如使用Sigmoid函數(shù)時(shí),只使用線性區(qū)域)
BN的具體過(guò)程(注意第三個(gè)公式中分母要加上epsilon)

注意點(diǎn):在測(cè)試過(guò)程中使用的均值和方差已經(jīng)不是某一個(gè)batch的了,而是針對(duì)整個(gè)數(shù)據(jù)集而言。因此,在訓(xùn)練過(guò)程中除了正常的前向傳播和反向求導(dǎo)之外,我們還要記錄每一個(gè)Batch的均值和方差,以便訓(xùn)練完成之后按照下式計(jì)算整體的均值和方差。
另一個(gè)注意點(diǎn):在arxiv六月份的preprint論文中,有一篇叫做“How Does Batch Normalization Help Optimization?”的文章,里面提到BN起作用的真正原因和改變輸入的分布從而產(chǎn)生穩(wěn)定性幾乎沒(méi)有什么關(guān)系,真正的原因是BN使對(duì)應(yīng)優(yōu)化問(wèn)題的landscape變得更加平穩(wěn),這就保證了更加predictive的梯度以及可以使用更加大的學(xué)習(xí)率從而使網(wǎng)絡(luò)更快收斂,而且不止BN可以產(chǎn)生這種影響,許多正則化技巧都有這種類(lèi)似影響。
16.超參數(shù)搜索方法
網(wǎng)格搜索:在所有候選的參數(shù)選擇中,通過(guò)循環(huán)遍歷,嘗試每一種可能性,表現(xiàn)最好的參數(shù)就是最終的結(jié)果。
貝葉斯優(yōu)化:貝葉斯優(yōu)化其實(shí)就是在函數(shù)方程不知的情況下根據(jù)已有的采樣點(diǎn)預(yù)估函數(shù)最大值的一個(gè)算法。該算法假設(shè)函數(shù)符合高斯過(guò)程(GP)。
隨機(jī)搜索:已經(jīng)發(fā)現(xiàn),簡(jiǎn)單地對(duì)參數(shù)設(shè)置進(jìn)行固定次數(shù)的隨機(jī)搜索,比在窮舉搜索中的高維空間更有效。這是因?yàn)槭聦?shí)證明,一些超參數(shù)不通過(guò)特征變換的方式把低維空間轉(zhuǎn)換到高維空間,而在低維空間不可分的數(shù)據(jù),到高維空間中線性可分的幾率會(huì)高一些。具體方法:核函數(shù),如:高斯核,多項(xiàng)式核等等。
基于梯度:計(jì)算相對(duì)于超參數(shù)的梯度,然后使用梯度下降優(yōu)化超參數(shù)。
17.如何理解卷積、池化等、全連接層等操作
卷積的作用:捕獲圖像相鄰像素的依賴性;起到類(lèi)似濾波器的作用,得到不同形態(tài)的feature map
激活函數(shù)的作用:引入非線性因素
池化的作用:減少特征維度大小,使特征更加可控;減少參數(shù)個(gè)數(shù),從而控制過(guò)擬合程度;增加網(wǎng)絡(luò)對(duì)略微變換后的圖像的魯棒性;達(dá)到一種尺度不變性,即無(wú)論物體在圖像中哪個(gè)方位均可以被檢測(cè)到
18.1x1大小的卷積核的作用
通過(guò)控制卷積核個(gè)數(shù)實(shí)現(xiàn)升維或者降維,從而減少模型參數(shù)
對(duì)不同特征進(jìn)行歸一化操作
用于不同channel上特征的融合
19.常見(jiàn)激活函數(shù)特點(diǎn)
sigmoid:輸入值很大時(shí)對(duì)應(yīng)的函數(shù)值接近1或0,處于函數(shù)的飽和區(qū),導(dǎo)致梯度幾乎為0,造成梯度消失問(wèn)題
Relu:解決梯度消失問(wèn)題,但是會(huì)出現(xiàn)dying relu現(xiàn)象,即訓(xùn)練過(guò)程中,有些神經(jīng)元實(shí)際上已經(jīng)"死亡“而不再輸出任何數(shù)值
Leaky Relu:f = max(αx, x),解決dying relu問(wèn)題,α的取值較大時(shí)比較小時(shí)的效果更好。它有一個(gè)衍生函數(shù),parametric Leaky Relu,在該函數(shù)中α是需要去學(xué)習(xí)的
ELU:避免dying神經(jīng)元,并且處處連續(xù),從而加速SGD,但是計(jì)算比較復(fù)雜
激活函數(shù)的選擇順序:ELU>Leaky Relu及其變體>Relu>tanh>sigmoid
20.訓(xùn)練過(guò)程中,若一個(gè)模型不收斂,那么是否說(shuō)明這個(gè)模型無(wú)效?導(dǎo)致模型不收斂的原因有哪些?
并不能說(shuō)明這個(gè)模型無(wú)效,導(dǎo)致模型不收斂的原因可能有數(shù)據(jù)分類(lèi)的標(biāo)注不準(zhǔn)確;樣本的信息量太大導(dǎo)致模型不足以fit整個(gè)樣本空間;
學(xué)習(xí)率設(shè)置的太大容易產(chǎn)生震蕩,太小會(huì)導(dǎo)致不收斂;可能復(fù)雜的分類(lèi)任務(wù)用了簡(jiǎn)單的模型;數(shù)據(jù)沒(méi)有進(jìn)行歸一化的操作。
21.深度學(xué)習(xí)中的不同最優(yōu)化方式,如SGD,ADAM下列說(shuō)法中正確的是?
A.在實(shí)際場(chǎng)景下,應(yīng)盡量使用ADAM,避免使用SGD
B.同樣的初始學(xué)習(xí)率情況下,ADAM的收斂速度總是快于SGD方法
C.相同超參數(shù)數(shù)量情況下,比起自適應(yīng)的學(xué)習(xí)率調(diào)整方式,SGD加手動(dòng)調(diào)節(jié)通常會(huì)取得更好效果
D.同樣的初始學(xué)習(xí)率情況下,ADAM比SGD容易過(guò)擬合
S: C
22.深度學(xué)習(xí):凸與非凸的區(qū)別
凸:
指的是順著梯度方向走到底就一定是最優(yōu)解 。
大部分傳統(tǒng)機(jī)器學(xué)習(xí)問(wèn)題都是凸的。
非凸:
指的是順著梯度方向走到底只能保證是局部最優(yōu),不能保證是全局最優(yōu)。
深度學(xué)習(xí)以及小部分傳統(tǒng)機(jī)器學(xué)習(xí)問(wèn)題都是非凸的。
23.googlenet提出的Inception結(jié)構(gòu)優(yōu)勢(shì)有()
A.保證每一層的感受野不變,網(wǎng)絡(luò)深度加深,使得網(wǎng)絡(luò)的精度更高
B.使得每一層的感受野增大,學(xué)習(xí)小特征的能力變大
C.有效提取高層語(yǔ)義信息,且對(duì)高層語(yǔ)義進(jìn)行加工,有效提高網(wǎng)絡(luò)準(zhǔn)確度
D.利用該結(jié)構(gòu)有效減輕網(wǎng)絡(luò)的權(quán)重
S:AD.
24.深度學(xué)習(xí)中的激活函數(shù)需要具有哪些屬性?()
A.計(jì)算簡(jiǎn)單
B.非線性
C.具有飽和區(qū)
D.幾乎處處可微
S: ABC
relu函數(shù)在0處是不可微的。
25.關(guān)于神經(jīng)網(wǎng)絡(luò)中經(jīng)典使用的優(yōu)化器,以下說(shuō)法正確的是
A.Adam的收斂速度比RMSprop慢
B.相比于SGD或RMSprop等優(yōu)化器,Adam的收斂效果是最好的
C.對(duì)于輕量級(jí)神經(jīng)網(wǎng)絡(luò),使用Adam比使用RMSprop更合適
D.相比于Adam或RMSprop等優(yōu)化器,SGD的收斂效果是最好的
S: D
SGD通常訓(xùn)練時(shí)間更長(zhǎng),容易陷入鞍點(diǎn),但是在好的初始化和學(xué)習(xí)率調(diào)度方案的情況下,結(jié)果更可靠。如果在意更快的收斂,并且需要訓(xùn)練較深較復(fù)雜的網(wǎng)絡(luò)時(shí),推薦使用學(xué)習(xí)率自適應(yīng)的優(yōu)化方法。
26.以下說(shuō)法錯(cuò)誤的是
A.使用ReLU做為激活函數(shù),可有效地防止梯度爆炸
B.使用Sigmoid做為激活函數(shù),較容易出現(xiàn)梯度消失
C.使用Batch Normalization層,可有效的防止梯度爆炸
D.使用參數(shù)weight decay,在一程度上可防止模型過(guò)擬合
S: C
意思是BN解決的是梯度消失問(wèn)題?對(duì)結(jié)果存疑。認(rèn)為二者皆可防止。
27.以下哪種方法一般不用于在大數(shù)據(jù)集上訓(xùn)練DNN:
A.SGD B.FTRL C.RMSProp D.L-BFGS
S: D
L-BFGS(Limited-memory BFGS,內(nèi)存受限擬牛頓法)方法:所有的數(shù)據(jù)都會(huì)參與訓(xùn)練,算法融入方差歸一化和均值歸一化。大數(shù)據(jù)集訓(xùn)練DNN,容易參數(shù)量過(guò)大 (牛頓法的進(jìn)化版本,尋找更好的優(yōu)化方向,減少迭代輪數(shù))從LBFGS算法的流程來(lái)看,其整個(gè)的核心的就是如何快速計(jì)算一個(gè)Hesse的近似:重點(diǎn)一是近似,所以有了LBFGS算法中使用前m個(gè)近似下降方向進(jìn)行迭代的計(jì)算過(guò)程;重點(diǎn)二是快速,這個(gè)體現(xiàn)在不用保存Hesse矩陣上,只需要使用一個(gè)保存后的一階導(dǎo)數(shù)序列就可以完成,因此不需要大量的存儲(chǔ),從而節(jié)省了計(jì)算資源;重點(diǎn)三,是在推導(dǎo)中使用秩二校正構(gòu)造了一個(gè)正定矩陣,即便這個(gè)矩陣不是最優(yōu)的下降方向,但至少可以保證函數(shù)下降。
FTRL(Follow-the-regularized-Leader)是一種適用于處理超大規(guī)模數(shù)據(jù)的,含大量稀疏特征的在線學(xué)習(xí)的常見(jiàn)優(yōu)化算法,方便實(shí)用,而且效果很好,常用于更新在線的CTR預(yù)估模型;FTRL在處理帶非光滑正則項(xiàng)(如L1正則)的凸優(yōu)化問(wèn)題上表現(xiàn)非常出色,不僅可以通過(guò)L1正則控制模型的稀疏度,而且收斂速度快;
28.下列關(guān)于深度學(xué)習(xí)說(shuō)法錯(cuò)誤的是
A.LSTM在一定程度上解決了傳統(tǒng)RNN梯度消失或梯度爆炸的問(wèn)題
B.CNN相比于全連接的優(yōu)勢(shì)之一是模型復(fù)雜度低,緩解過(guò)擬合
C.只要參數(shù)設(shè)置合理,深度學(xué)習(xí)的效果至少應(yīng)優(yōu)于隨機(jī)算法
D.隨機(jī)梯度下降法可以緩解網(wǎng)絡(luò)訓(xùn)練過(guò)程中陷入鞍點(diǎn)的問(wèn)題
S: C.
29.多尺度問(wèn)題怎么解決?
實(shí)際上,現(xiàn)在有很多針對(duì)小目標(biāo)的措施和改良,如下:
最常見(jiàn)的是Upsample來(lái)Rezie網(wǎng)絡(luò)輸入圖像的大小;
用dilated/astrous等這類(lèi)特殊的卷積來(lái)提高檢測(cè)器對(duì)分辨率的敏感度;(空洞卷積是針對(duì)圖像語(yǔ)義分割問(wèn)題中下采樣會(huì)降低圖像分辨率、丟失信息而提出的一種卷積思路。利用添加空洞擴(kuò)大感受野,讓原本3 x3的卷積核,在相同參數(shù)量和計(jì)算量下?lián)碛?x5(dilated rate =2)或者更大的感受野,從而無(wú)需下采樣。在保持參數(shù)個(gè)數(shù)不變的情況下增大了卷積核的感受野)
有比較直接的在淺層和深層的Feature Map上直接各自獨(dú)立做預(yù)測(cè)的,這個(gè)就是我們常說(shuō)的尺度問(wèn)題。
用FPN這種把淺層特征和深層特征融合的,或者最后在預(yù)測(cè)的時(shí)候,用淺層特征和深層特征一起預(yù)測(cè);
SNIP(Scale Normalization for Image Pyramids)主要思路:
在訓(xùn)練和反向傳播更新參數(shù)時(shí),只考慮那些在指定的尺度范圍內(nèi)的目標(biāo),由此提出了一種特別的多尺度訓(xùn)練方法。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100851 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1698瀏覽量
46022 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5504瀏覽量
121238
原文標(biāo)題:深度學(xué)習(xí)&計(jì)算機(jī)視覺(jué)常見(jiàn)的29道面試題及解析
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【面試題】人工智能工程師高頻面試題匯總:機(jī)器學(xué)習(xí)深化篇(題目+答案)
人工智能工程師高頻面試題匯總——機(jī)器學(xué)習(xí)篇

【小白入門(mén)必看】一文讀懂深度學(xué)習(xí)計(jì)算機(jī)視覺(jué)技術(shù)及學(xué)習(xí)路線

機(jī)器視覺(jué)和計(jì)算機(jī)視覺(jué)有什么區(qū)別
計(jì)算機(jī)視覺(jué)的五大技術(shù)
計(jì)算機(jī)視覺(jué)的工作原理和應(yīng)用
計(jì)算機(jī)視覺(jué)與人工智能的關(guān)系是什么
計(jì)算機(jī)視覺(jué)與智能感知是干嘛的
計(jì)算機(jī)視覺(jué)和機(jī)器視覺(jué)區(qū)別在哪
計(jì)算機(jī)視覺(jué)和圖像處理的區(qū)別和聯(lián)系
計(jì)算機(jī)視覺(jué)屬于人工智能嗎
深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域的應(yīng)用
計(jì)算機(jī)視覺(jué)的主要研究方向
計(jì)算機(jī)視覺(jué)的十大算法

計(jì)算機(jī)視覺(jué):AI如何識(shí)別與理解圖像





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論