 情感機器人小冰的外部結構
情感機器人小冰的外部結構
在大學時代參加過一次微軟技術大會,沒記錯的是在2015年吧,當時演講者(原諒我不記得名字)在臺上介紹了兩款機器人,所負責日常事務的秘書小娜(Cortana)和具有情感溝通能力的小冰(XiaoIce),前者在現在看來更像是任務型的代表,而小冰,則更像是一個有血有肉的人,在回答中能更明顯地透露出人的氣息,這在當時已經是神級別的產品了。
19年微軟的4位大佬桌子Arxiv上對微軟小冰的整體架構進行了詳盡的介紹,我們來看一下:論文標題:The design and implement of XiaoIce, an empathetic social chatbot。
按事先說明,這篇文章沒有啥復雜的模型,而是把小冰的外部結構講的很清楚,可以說是智能機器人整個領域一個非常前沿的介紹,大家可以在這里面抽取自己所需放入自己的系統里面。
懶人目錄:
小冰的設計原則
小冰的架構
對話引擎
小結
小冰的設計原則
一般系統級介紹的文章,開篇intro結束后會開始講結構了,但是這篇論文卻加了一章專門討論全文的設計原則,這里面其實有很多有參考價值的東西,我們來看看。
IQ+EQ+Personality
文章認為,一個完整的人,需要擁有完整智商情商和人格,小冰也是這樣拆解實現的。
先說智商,文章將小冰的智商理解為知識和記憶的建模,圖像和自然語言的理解、推理、生成和預測。這么說起來其實就非常明確了,一方面我們要有存儲,一種是長期穩定的知識,另一種是短期變化的聊天記憶;另一方面就是滿足基本的交流能力,這個和人的對話類似,理解對方說什么、自己反應提煉信息、產生自己的回復并且對對方的回答產生預期。
然后是情商,情商被拆解為共情能力和社交能力。顧名思義,前者是一種將心比心的能力,理解他人的能力,這里面其實涵蓋了query理解、用戶畫像、情感檢測、情緒識別、動態追蹤情緒變化等多個能力,可能在細節上每個能力其實都已經有一定的研究,但組合在一起還是有一定難度的;而后者,其實體現在交流上,用戶是有不同的文化、性格等的背景的,因此要具備迎合對方興趣的能力,盡可能避免說一些敏感的話題。
最后是人格,中文叫做personality,讓一個人能成為人,必須有他最鮮明的標簽,有自己的性格,因為只有明確性格才能讓用戶有明確的預期,知道他會和你聊什么,當然這點還被做的更加差異化,不同地區、場景的小冰可能會有不同的形象以滿足當地用戶的需求。
抓手:對話交互次數
要衡量一個機器人好壞,對于小冰所應對的場景,文章使用了平均單次對話交互次數作為評價的抓手。文章認為這是一個非常有效、長期可靠的指標。首先對于對話機器人,更多的對話次數意味著用戶愿意與他溝通,獲取所需信息;第二是,雖然類似“沒聽懂”的這種問題可能會短期帶來更高的交互次數,但是這種劣質的交互次數多以后用戶自然就不愿意再和交流了,所以這個指標在長期來看也是比較有意義的;第三雖然一些技能的快速達成同樣會大導致交互次數的下降,但是高效的交互同樣會加強用戶和機器人的紐帶,在長期同樣有意義。(作者在這里說了很多有關交互次數的誤解,但是個人感覺這個指標還是不能只看次數,還有一些別的指標吧,只看一個指標可能會比較危險)
把社交聊天當做是分層決策
這里的分層決策其實看做是將整個對話內容決策看做兩層操作:頂層是技能決策,選擇合適的技能應對用戶的對話,底層則考慮原始基本的話術執行回復,兩者結合完成整體對話操作。
a top-level process manages the overall conversation and selects skills to handle different types of conversation modes (e.g., chatting casually, question answering, ticket booking), and a low- level process, controlled by the selected skill, chooses primitive actions (responses) to generate a conversation segment or complete a task.
小冰的架構
整體架構長這樣。
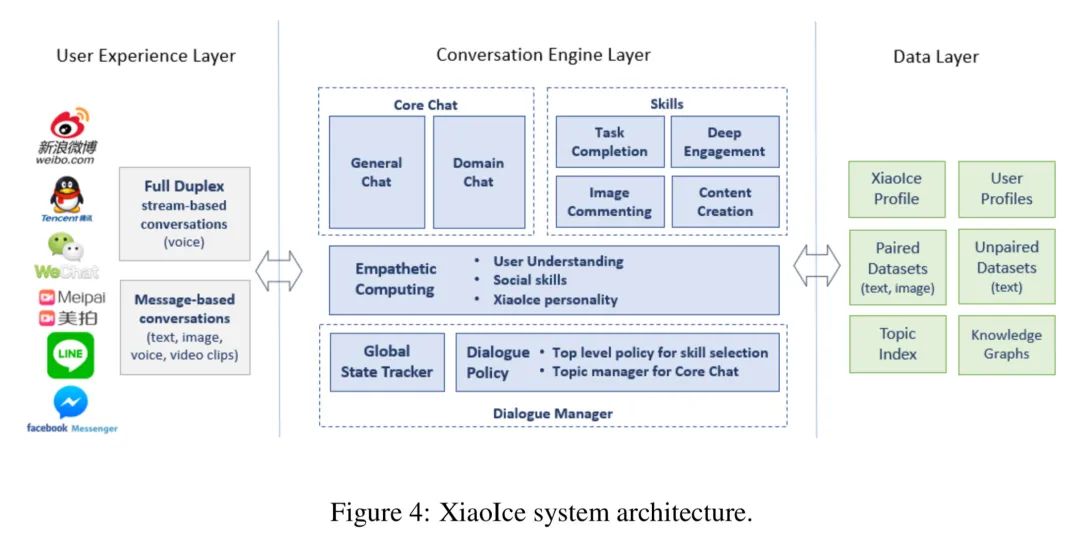
整體架構分了3層。
用戶體驗層。不同APP下、不同的語音輸入場景下,用戶都有不同的需求。這里分了兩種,說人話就是把語音模式單獨抽取出,滿足更為實時的對話場景,另一種則涵蓋文本、圖像、聲音、視頻的模式。這里面會涉及大量的信息預處理的工作,如文本圖像則是歸一化、聲音的去噪、判全和ASR等等。
對話引擎層。看名字就知道了,主要是用來進行對話交互的處理的,里面涵蓋了大量的功能,后面會花點時間展開說,論文也是花了整個章節來討論這塊。
數據層。我們當然知道是需要存儲數據的,但是存了什么與怎么用就是用戶所關心。這里主要講了有什么,有小冰畫像、用戶畫像、成對(我們有的時候叫平行)數據、非成對數據、主題索引、知識圖譜。
對話引擎
前面的章節討論了整體架構后,這時候就把最核心的對話引擎拿出來詳細品一品了。
對話管理器
Dialogue Manager,對話管理器,可以說是多輪對話最為靈魂的一個模塊了,這里作者把它分為了兩個子模塊,分別是全局狀態管理器和對話規則,這里其實把整個對話看成一個類似強化學習問題去看了,根據這個狀態和對話規則,可以進行一些動作決策,即,這個動作可以是特定技能,也可以是核心對話的一些規則。
首先聊聊對話狀態管理器,它主要維護的是對話過程中出現的需要記憶的信息,從而跟蹤對話的狀態,舉個例子,在對話過程匯總達成的共識就需要被記錄下來,如當前的話題、用戶的愛好等,這種是短期、對話內有效的記憶。
而對話規則,則如上所示采用了分層的對話策略,高級策略管技能,低級策略管話術。而在其中,高級策略管理的技能也需要記錄下來,于是有了話題管理器,它主要用于實現當前話題、管理話題切換等功能,這里有很多有意思的技術,如發現用戶覺得無聊的時候主動切換話題、自身知識匱乏聊不下去時的主動切換等等。
說到這個話題的切換,其實內部是按照“召回-排序”的模式去搭建的,這個和推薦搜索非常類似,召回主要就是基于用戶信息和當前對話的狀態了,而排序其實用的就是多個特征合并到一個提升樹上進行機器學習打分排序,文章中列舉了一些排序的規則,如下:
上下文信息。
新鮮度。
用戶個性化特征。
流行度。可以理解為網絡的熱門程度。
接受度。可以理解為在小冰場景下的用戶愿意去聊的程度。
情感計算
如果說小冰情感機器人的一個代表任務,那么情感計算模塊就是整個小冰最為特色的對話模塊了。
實質上情感計算模塊是把上面提到的狀態給構造處后來,這4個東西分別為上下文狀態、上下文、用戶情感向量和回復的情感向量,這個東西后續就會被放入dialog policy(對話規則)中進行處理,最終表現為小冰形式的回復——一個18歲,可靠,富有同情心,深情,博學多聞,但會自欺欺人,并且幽默感極佳的妹子(心動了沒?)。
整合整個計算模塊主要有3個任務:上下文query理解、用戶理解和用戶回復生成。
首先是上下文query理解,這個相信很多做搜索推薦的人應該都會比較熟悉,這里面涉及到這幾個計算任務:
命名實體識別。NLU的基本操作。
共指解析。這個在多輪對話非常常見,要把里面你的代詞給解析出來。
句子完整性。這個在對話問題里面很常見,需要判斷句子是否完整。
用戶理解實質上就是基于上面的和,即上下文狀態和上下文,處理成用戶情感向量。這里面主要有5個核心工作:
話題檢測,檢測當前的話題狀態,看用戶有沒有自己開新的的話題等。這個要會和話題管理器進行交互(topic manager)
識別對話意圖,文中一共提到了11中對話意圖,如打招呼、回復、告知等。
情感分析,分析用戶情緒,是開心、傷心、憤怒等。
觀點分析,分析用戶對話題的觀點,樂觀悲觀等。
在用戶畫像明確的前提下引入用戶畫像,如性別興趣等。
在上面基礎上就可以生成了,這里作者把它叫做用戶共情向量生成,說到生成,說明就要把前面的信息集成起來,這樣才能有一個比較綜合性的結果,這里就包括了前面的對話內容、用戶理解,還需要涵蓋小冰的人格特征等。
核心聊天模塊
核心聊天模塊是處理用戶輸入最終完成結果回復的重要模塊,它主要分為通用域聊天和垂直域聊天。顧名思義通用域就是管常見的閑聊、開放域場景的聊天,對于特定領域、任務的聊天,就交給垂直域聊天負責,一般都會是一些比較有深度知識依賴的領域,例如聊電影演員八卦之類的。這樣劃分的核心主要是根據下游數據庫知識存儲的結構有關,這個和搜索非常類似。
無論是開放域聊天還是垂直于聊天,實質上都是一種“召回-排序”模式的實現方式,召回(生成)多個可能的回答,然后排序。召回的方式文章列舉了3種:
基于成對文本的數據庫檢索。
神經網絡生成。文中提到了實質上用的是seq2seq的框架,并特地提到了GRU-RNN。
非成對樣本。非成對樣本的召回來自一些講座、對話記錄等,進行過一些類似非小冰風格的過濾,使用,即對話上下文狀態作為索引過濾,并借助知識圖譜的方式進行適當的拓展,知識圖譜的構建原理源于“共現”。
然后就是排序了,排序同樣使用的是提升樹類的模型(可見提升樹類的機器學習模型仍有很大的使用空間,不要小看)。特征作者也列舉出來了:
局部語義相似度特征。保證小冰回復的內容和上一句足夠接近,使用的是DSSM模型。
全局語義相似度特征。保證整個聊天會話中內容是比較緊湊的,所以會和全局上下文進行與上述相似的一次語義相似度計算。
情緒匹配度。為了保證小冰的形象及其回復足夠有共情力,需要考慮情緒上的匹配度(注意這里叫匹配度,不是相似性,用戶傷心你不見得要跟著她傷心,你可以嘗試用快樂感染他,大家細品,這也是為什么前兩個用戶用的是coherence,這一個用的是matching的理由)。
檢索相似性。即搜索的相似性,在特定話題下,應該有一些特定的關鍵詞是需要被保留的,所以要有搜索上的相似性,比較突出的當然就是BM25之類的基操了。
圖像評論
圖像評論稍微會觸及到我的知識盲區——CV,我試著講講吧。
首先看需求,回想下我們在微信給別人發圖都是為了什么,為了聊天分享對吧,哪怕是斗圖也有斗圖本身的含義,因此圖像評論功能有別于一般的圖像識別,因為這里除了要識別圖像內容,還要分析出用戶的目的,然后返回針對性的內容,例如“斗圖”,只有能分析出目的并且能給出針對性回復,斗圖才能都得起來。
整體的操作流程和文字的處理其實類似,所以作者更多是舉例子而沒有深入技術細節。
對話技能
對話技能涉及到對話內容中需要完成的任務,這塊和上述的圖像評論和核心聊天共同組成了IQ模塊,對話技能主要分為內容創建,深度參與和任務完成三種能力。
內容創建的主要目標是和人類一起完成一些創作任務,如畫畫、作曲等,甚至包括一些兒童讀物等。這里特別提到了RNN進行創作。
深度參與旨在通過針對特定主題和設置來滿足用戶的特定情感和智力需求,從而提高用戶的長期參與度,類似的一些百科檢索、求安慰之類的其實都算是深度參與的部分,他主要涵蓋兩個維度,從IQ到EQ,以及組內的討論。上面提到的百科、求安慰其實都算是這個維度里面的,這個能覆蓋大量用戶需求。組內討論則傾向于和用戶達成一種更加深入的關系,文中提到的“數羊”技能就是其中一個。
任務完成能力讓小冰具備了和小娜類似的私人秘書能力,而且更具“人性”,完成度和貼心度都很高,類似一些相關的問答,小冰會考慮到用戶的知識背景給出更加通俗的解釋,例如美國人問某個國家的面積,回復可能就是“面積是XXX,相當于X個美國”。
小結
文章讀完,可能深度技術上沒有很明顯的提升,文中但凡說了模型,其實都是一些非常經典簡單的模型,收獲是在于知道了這些架構上、設計思路上的東西,回頭想來說實話其實模型反而不是最值錢的東西,他只是一個工具,有了好的設計,出效果的風險就會更低,哪怕是各種飛機大炮模型,其實都是建立在對用戶對系統現狀足夠理解,根據這個現狀因地制宜建立起來的,不是誰都適用,試錯風險自然就高了,這也是我在本系列第一篇用這個的核心目的所在。
責任編輯:xj
原文標題:【微軟小冰】多輪和情感機器人的先行者
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
微軟
+關注
關注
4文章
6614瀏覽量
104171 -
情感機器人
+關注
關注
1文章
6瀏覽量
3477
原文標題:【微軟小冰】多輪和情感機器人的先行者
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】+初品的體驗
安川工業機器人結構

湯姆貓發布AI語音情感陪伴機器人研發進展
機器人技術的發展趨勢
開源項目!用ESP32做一個可愛的無用機器人
開源項目!用ESP32做一個可愛的無用機器人

柔性機器人與剛性機器人區別與聯系






 工商網監
工商網監
評論