 tansformer的量化實現方案
tansformer的量化實現方案
理論介紹
相比于訓練后量化方法,將量化過程插入到訓練中可以彌補量化產生的誤差,但是帶來的問題可能是增加了訓練的時間。在tansformer的量化實現中,我們采用了訓練中量化的方法,在網絡前向傳輸中,對權重等參數進行線性量化。反向傳播中,對scale和權重參數的求導采用Hinton的strait-through estimator的方式。在CPU上訓練花費了10天的時間,在這期間又review了最近的量化方法的文章。所以先總結一下,然后再分析一下transformer量化的結果。
1) PACT
這是一種實現對activation量化的方法,基本思想是通過訓練來獲得ReLU的一個clip參數a。a的動態調整能夠在減少量化誤差和保證反向傳播有效進行之間獲得平衡。PACT重新定義了ReLU過程如下:
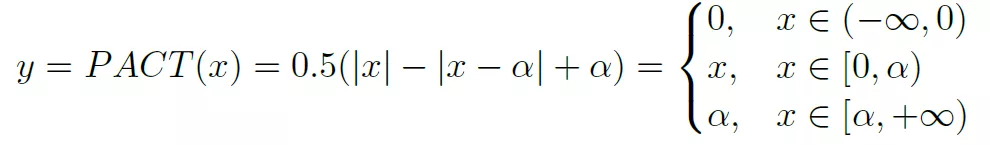
參數a限定了activation的范圍為[0, a]。然后獲得的激活值y在進行線性映射到k bit的表示空間,如下:
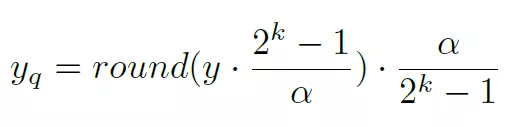
在這里[0, a]是y值的一個限定,a>=y。所以其范圍比y值的實際范圍要大,這可以對y的量化誤差有一些彌補。采用strait-through estimator方法計算其相對于a的梯度為:
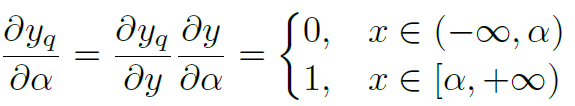
當a趨向于無窮大的時候,就接近于ReLU函數,所以訓練過程一定是往a增大方向移動。通過在loss中增加a的L2 規范化可以尋求一個合適的a值。
2) quantization-aware training
谷歌采用量化和訓練分離的方法,在前向計算使用量化數據,而在訓練的時候還是浮點訓練。量化方法為如下公式:
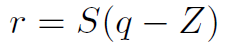
其中S為scale參數,z是零點偏移,q是量化后參數。Z值的存在會導致矩陣或者卷積運算中有交叉項。這會增加一部分加法和乘法項。這在CPU等通用處理器上容易實現,只是一個時間復雜度的問題,但是實際上不利于在FPGA等硬件上實現。所以FPGA等平臺的量化一般都讓z值為0。消除交叉項計算。對于一個矩陣乘法,量化導致了scale的組合,比如:
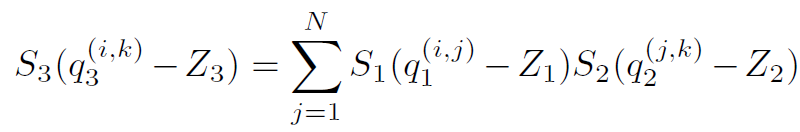
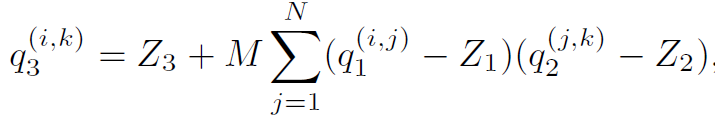
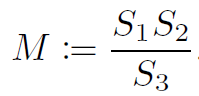
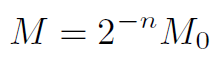
在這里M是浮點數據,在這里作者對其又做了一次量化,首先將M數據映射到[0.5, 1)空間,然后在使用32bit數據來表達為整數。
32bit的表達能夠降低量化精度。
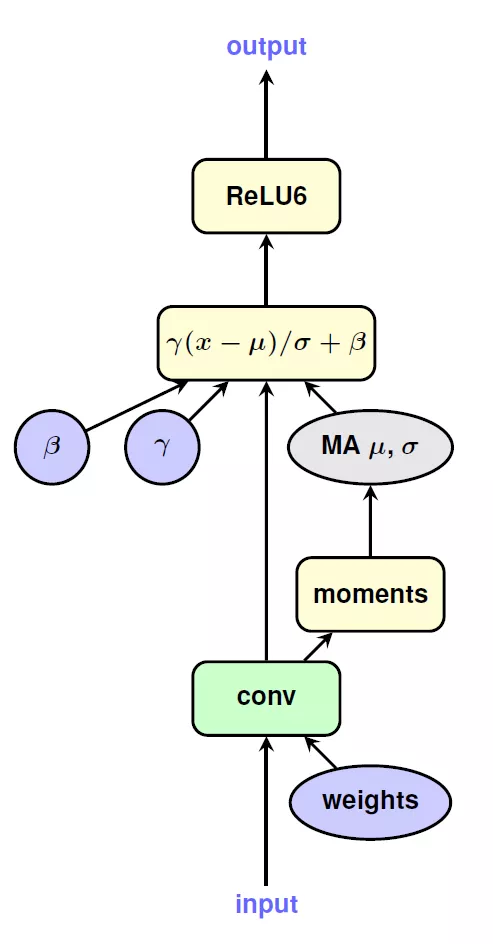
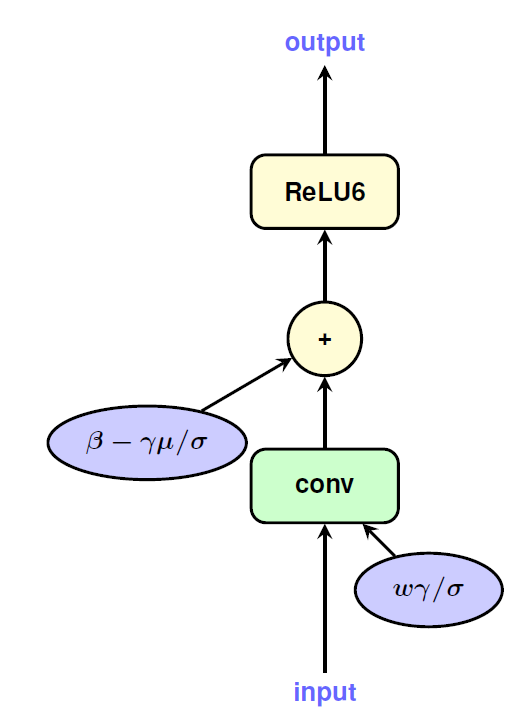
在量化整個網絡的過程中,作者也提供了一些處理技巧。在進行線性量化的時候,采用了對稱的量化區間,比如8bit量化,正常取值范圍在[-128, 127],作者取了對稱空間[-127, 127]。這樣做的目的和實現的平臺有關。在量化activation的時候,使用EMA來處理收集到的數值范圍,這樣做可以在初始訓練中,完全屏蔽掉對activation的量化,使得訓練進入到一個比較穩定的狀態后在進行量化。BN是一個復雜的計算,但是可以將其折疊到之前的卷積層和FC層中,如下圖所示:
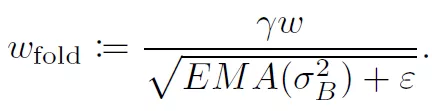
3) 訓練后量化,基于KL發散性。
基于訓練后的量化方法的優勢就是量化花費時間短。在tensorRT中使用了KL發散性來描述量化后的數據和浮點數據之間的信息損失程度。通過最小化這個值來達到量化后數據包含的信息接近浮點數據的信息。這種方法的出發點是,為了保證量化后模型的精度損失較小,應該讓量化后的數據和原始浮點數據表達的信息最一致。具體的做法是:
對每層網絡,先收集activation的數值區間,這樣就生成一個activation值的分布;采用不同的量化區間[a,b]來對activation進行線性映射,這樣就形成了針對參數a和b的多種不同分布,然后找到和原始數據分布KL最小的分布,這個時候得到的a和b的值就是量化activation時所采用的threshold值。
Transformer量化結果
還是決定由簡入難,先進行16bit的量化,量化內容包括transformer中的dense層,FC層。對權重和數據都進行16bit的量化,即將量化節點插入到計算圖中。梯度采用strait-through estimator來估計。對于embedding,softmax,layer normalization還是使用浮點值。因為擔心對這些的量化可能會導致精度降低。選擇batch size為256,epoch為20,數據集使用英語德語翻譯數據集。這個數據集有460萬個句子。在服務器上使用CPU跑了10天,以下是結果:
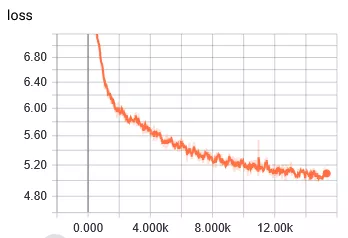
對比一下github上作者浮點模型的訓練結果:
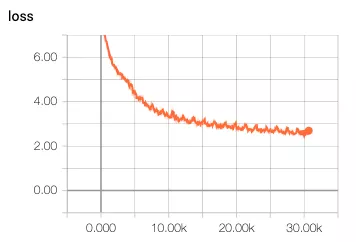
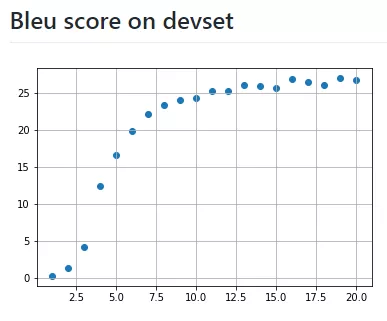
發現存在以下問題:
1 loss下降很慢,浮點模型在訓練到達5k次的時候,loss已經下降到4了,但是量化的訓練loss在5k次的時候才到5.4。經歷了前幾次快速下降之后,后邊更加緩慢。
2 BLEU得分很低,訓練了10K次后得分才有0.11。得分低的原因也是loss值很低。
第一次做沒有什么經驗,猜測可能有以下幾種原因:
1 對所有的scale我都使用了常數2作為初始值,為什么選擇2,并沒有什么原因,就是隨便選擇的。或許初始值的不當導致了loss訓練很慢。設想通過以下方式來改進,先進行warmup,通過計算參數的范圍來計算出一個scale值。進行了幾輪warmup之后再進行量化訓練。
2 因為看到loss也一直是下降的趨勢,那么猜測可能是量化訓練是比正常訓練收斂慢。因為量化參數的梯度在參數超過閾值會為0,這個可能導致梯度更新較慢。
編輯:hfy
-
cpu
+關注
關注
68文章
10863瀏覽量
211765 -
Transformer
+關注
關注
0文章
143瀏覽量
6006
發布評論請先 登錄
相關推薦
解讀大模型FP量化的解決方案

可實現批量化生產線性恒流驅動IC方案
碳纖維為何能實現汽車輕量化?
怎樣分析量化過程及Verilog實現方法?
INT8量化常見問題的解決方案
基于模糊規則的服裝風格的區域量化與實現
數字馬達控制系統的量化誤差設計方案


如何使用FPGA實現微型SAR成像的量化顯示
深度解析MegEngine 4 bits量化開源實現
淺談輕量化設計:材料、創新技術及未來解決方案
輕量化5G核心網的實現方式





 工商網監
工商網監
評論