") ZYNQ系列FPGA使用,PS與PL接口設(shè)計(jì)和硬件設(shè)計(jì)
ZYNQ系列FPGA使用,PS與PL接口設(shè)計(jì)和硬件設(shè)計(jì)
隨著開源的MCU源代碼越來越多,也逐漸的影響著嵌入式系統(tǒng)開發(fā)的思路,出現(xiàn)了兩種以前不常見的設(shè)計(jì)思路。第一,原本需要購買一顆MCU芯片的設(shè)計(jì),現(xiàn)在直接考慮購買一顆帶有MCU硬核的FPGA(如ZYNQ系列FPGA)替代,既有MCU的功能,又有接口可編程的能力,更加的靈活;第二種思路是設(shè)計(jì)中原本需要寫復(fù)雜控制邏輯的Verilog模塊,現(xiàn)在直接考慮替換為一顆或者多顆開源的MCU IP核,反正這些MCU都是驗(yàn)證過沒問題的,并且占用資源很小,同時(shí)可編程也帶來了功能改變的靈活性,何樂而不為呢!
(分兩次介紹上述第一種應(yīng)用的兩種不同應(yīng)用場景實(shí)例,帶操作系統(tǒng)和不帶操作系統(tǒng)來控制LED燈的應(yīng)用。)
“龍芯杯”競賽的影響和設(shè)計(jì)水平不斷提升
隨著中興華為事件的不斷發(fā)酵,集成電路行業(yè)恰似長頸鹿的脖子一樣被一雙無形的手給緊緊的卡住了。之所以稱之為長頸鹿的脖子,是因?yàn)榧呻娐沸袠I(yè)擁有很長的產(chǎn)業(yè)鏈,而在這個(gè)產(chǎn)業(yè)鏈上我們卻處處都弱,拿長頸鹿又細(xì)又長的脖子來形容再恰當(dāng)不過了。
國內(nèi)各種IC設(shè)計(jì)競賽、EDA設(shè)計(jì)競賽也越來越多,但筆者認(rèn)為,最具有代表性最能反映一所高校在校學(xué)生數(shù)字IC設(shè)計(jì)水平的也就是“龍芯杯”CPU設(shè)計(jì)競賽。“龍芯杯”MIPS CPU設(shè)計(jì)已經(jīng)舉行三屆了,參賽的隊(duì)伍水平也在不斷的提高,一個(gè)大三本科生設(shè)計(jì)一顆帶有4發(fā)射亂序處理、分支預(yù)測等功能且能跑Linux操作的CPU核已經(jīng)不是什么問題,并且FPGA驗(yàn)證的主頻已經(jīng)超過了120MHz,凸顯了FPGA時(shí)序優(yōu)化能力的提升。隨著RISC-V等開源CPU的不斷發(fā)展,相信國內(nèi)在CPU設(shè)計(jì)能力上的差距正在加速縮小,被ARM和INTEL卡脖子的時(shí)代可能快要結(jié)束了。
從參賽的規(guī)模上來看,也在不斷的擴(kuò)大。今年又新加入了不少高校,像北京郵電大學(xué)、河北大學(xué)等。龍芯杯競賽至少反映了這些高校在CPU設(shè)計(jì)方向的課程設(shè)置已經(jīng)沒有問題,設(shè)計(jì)CPU需要眾多課程的支撐,《計(jì)算機(jī)組成原理》、《編譯原理》、《操作系統(tǒng)》及FPGA設(shè)計(jì)開發(fā)等相關(guān)課程,相對而言,國內(nèi)絕大多數(shù)高校雖然有相關(guān)的課程,可如果找到有能力設(shè)計(jì)CPU的學(xué)生組隊(duì)參賽的高校卻不多。
以下介紹ZYNQ系列FPGA如何使用。以下內(nèi)容作者是殷建飛。
部分硬件設(shè)計(jì)中需要CPU完成對電路寄存器的配置,為了完成Zedboard對FPGA上部分寄存器的配置功能,可以在PS單元(處理器系統(tǒng))上運(yùn)行裸機(jī)程序(無操作系統(tǒng)支持)完成和PL單元(FPGA部分)的數(shù)據(jù)交互功能,此時(shí)PS單元更像單片機(jī)開發(fā);另一種方法是PS單元運(yùn)行Linux操作系統(tǒng),通過驅(qū)動(dòng)程序和應(yīng)用程序完成對硬件寄存器的讀寫操作,并且Linux有著完整的網(wǎng)絡(luò)協(xié)議棧支持,后續(xù)可拓展性更強(qiáng),可以更好的發(fā)揮ZYNQ這種異構(gòu)架構(gòu)芯片的性能。主要分為兩部分,分別闡述Zedboard中FPGA和處理器互聯(lián)總線與硬件設(shè)計(jì)和Zedboard處理器系統(tǒng)上嵌入式Linux的移植與通過驅(qū)動(dòng)和應(yīng)用程序簡單配置FPGA寄存器的實(shí)現(xiàn)。本文主要介紹不帶操作系統(tǒng)的情況。
PS與PL接口設(shè)計(jì)和硬件設(shè)計(jì)
PS與PL交互可以通過ZYNQ系統(tǒng)內(nèi)的高速總線來完成,ZYNQ內(nèi)包含AXI4標(biāo)準(zhǔn)總線、AXI-Lite輕型總線和AXI-Stream流式總線。其中AXI4標(biāo)準(zhǔn)總線支持有地址、猝發(fā)和連續(xù)的傳輸,可以用于大容量數(shù)據(jù)的傳輸;而AXI-Lite總線則是一個(gè)輕量級(jí)的地址映射單次傳輸接口,占用更少的邏輯資源;AXI4-Stream是面向數(shù)據(jù)流的無地址的傳輸,更適合承載視頻流等流式數(shù)據(jù)。綜上,因?yàn)楸敬螌?shí)驗(yàn)硬件設(shè)計(jì)較為簡單,數(shù)據(jù)傳輸量較小,因此選用AXI輕型總線作為PS單元與PL單元交互接口。
(1)自定義IP封裝
VIVADO中提供了多種AXI總線接口的IP核,例如DMA IP中使用AXI-lite用來完成CPU配置DMA引擎的寄存器,而AXI標(biāo)準(zhǔn)總線用來完成DMA引擎面向內(nèi)存地址映射的搬運(yùn)數(shù)據(jù)。但是官方的IP核應(yīng)用不夠靈活,這里我們可以封裝自己的IP并在其中加入需要的邏輯處理。
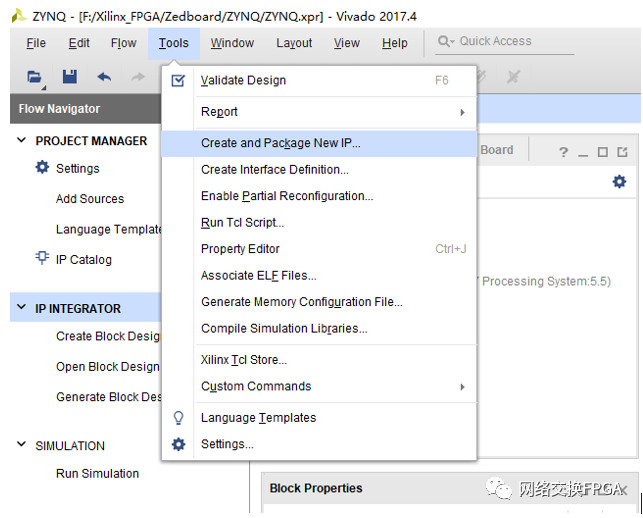
打開任意一個(gè)VIVADO工程,選擇Tools中的Creatand Package New IP選項(xiàng),點(diǎn)擊next前進(jìn)。
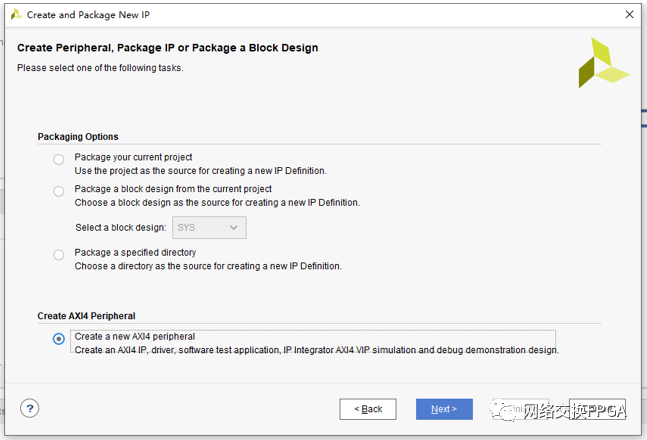
選擇建立一個(gè)AXI4的外設(shè)選項(xiàng)
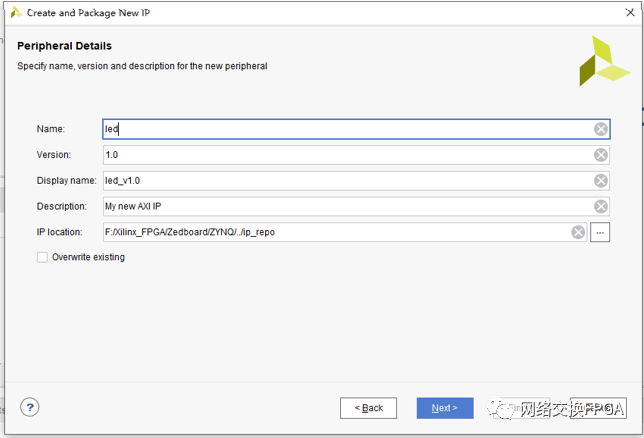
進(jìn)行IP命名和版本的選擇,另外需要選定工程路徑,這是稍后建 立IP時(shí)VIVADO會(huì)新建立的工程路徑。
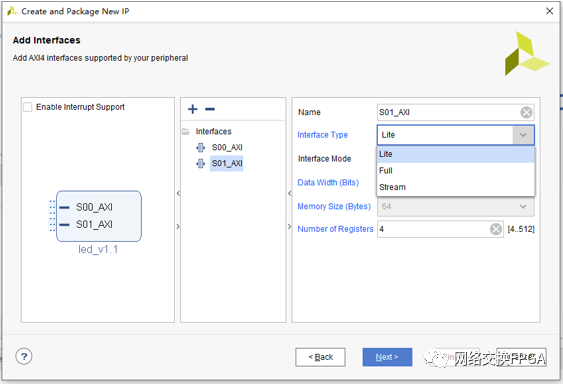
在接口選項(xiàng)中,選擇一個(gè)AXI-lite的Slave接口,數(shù)據(jù)位寬為 32位,寄存器數(shù)量為4,這里我們不需要太多的寄存器。當(dāng)然在面對更復(fù)雜的應(yīng)用時(shí),可以添加更多的AXI總線通道。
選擇Edit IP,此時(shí)VIVADO會(huì)打開一個(gè)新的工程。當(dāng)然,也可以選擇將IP添加到庫,然后在工程中搜索添加該IP核,然后重新選中該IP選擇Edit in IP Packager,VIVADO同樣會(huì)打開一個(gè)新工程修改之前的IP。
在上述新工程中,可以看到工程的組織目錄led_v1_1_S00_AXI才是我們創(chuàng)建的總線接口模塊,而led_v1頂層模塊只是添加了對總線接口的例化而已。那么VIVADO建立的IP為什么要新封裝一層例化呢?我們用另一個(gè)多個(gè)AXI通道的工程來看一下,當(dāng)IP需要多個(gè)AXI通道時(shí),我們發(fā)現(xiàn)頂層例化了多個(gè)AXI總線通道,我們可以方便的設(shè)計(jì)和添加.v文件來完成多個(gè)數(shù)據(jù)通道之間的數(shù)據(jù)傳輸和總線控制。
(2)AXI-Lite協(xié)議分析
下面我們對AXI-Lite總線協(xié)議進(jìn)行簡單分析,AXI總線共5個(gè)數(shù)據(jù)通道,分別是寫地址通道、寫數(shù)據(jù)通道、寫響應(yīng)通道和讀地址通道、讀數(shù)據(jù)通道。AXI采用握手信號(hào)機(jī)制,當(dāng)發(fā)送數(shù)據(jù)一端發(fā)送valid信號(hào),而接受信號(hào)一端發(fā)送ready信號(hào),當(dāng)valid和ready同時(shí)有效時(shí)數(shù)據(jù)完成一次傳輸。
首先來看寫數(shù)據(jù)接口,寫數(shù)據(jù)需要寫數(shù)據(jù)地址通道先發(fā)送地址,然后寫數(shù)據(jù)通道發(fā)送數(shù)據(jù),slave端接受完成后通過寫響應(yīng)通道告訴master端。
上述代碼完成了slave端寫地址通道的響應(yīng),slave端在上電復(fù)位后保持awreday信號(hào)為低電平,當(dāng)master發(fā)出awvalid信號(hào)時(shí),slave端將寫地址通道上的地址數(shù)據(jù)存入寄存器,并將awready信號(hào)拉高一個(gè)時(shí)鐘周期,完成一次寫地址通道的傳輸過程。
對于寫數(shù)據(jù)通道而言,其數(shù)據(jù)傳輸過程和寫地址通道的傳輸過程很類似,slave端上電復(fù)位后將wready信號(hào)拉低,在master將wvalid信號(hào)拉高后,slave端將數(shù)據(jù)存入寄存器同時(shí)將wready信號(hào)拉高一個(gè)周期,完成一次寫數(shù)據(jù)通道傳輸過程。
寫操作由于是從master傳輸數(shù)據(jù)到slave,因此需要slave返回一個(gè)正確的響應(yīng)信號(hào)給master來告訴master我已經(jīng)正確收到數(shù)據(jù),這就是寫響應(yīng)通道。由于寫響應(yīng)通道數(shù)據(jù)是從slave端向master端,因此由master端發(fā)出ready信號(hào),slave端上電復(fù)位后拉低valid信號(hào),在檢測到master端的ready信號(hào)后將valid信號(hào)和bresp回應(yīng)信號(hào)一同發(fā)送到總線上完成寫響應(yīng)傳輸過程。一個(gè)完整的寫交易過程完成。
通過上述代碼,讀者可能會(huì)困惑寫地址通道和寫數(shù)據(jù)通道為什么綁定到一起了呢?難道AXI-Lite總線的寫地址通道和寫數(shù)據(jù)通道數(shù)據(jù)傳輸必須同時(shí)發(fā)生嗎?我們參考了XILINX的xapp1168中關(guān)于AXI總線設(shè)計(jì)的工程,發(fā)現(xiàn)在它的master端設(shè)計(jì)中,寫地址通道和寫數(shù)據(jù)通道的傳輸是由同一個(gè)信號(hào)觸發(fā)的。也就是說master端總是先準(zhǔn)備好寫地址通道和寫數(shù)據(jù)通道的數(shù)據(jù)后,然后同時(shí)傳輸要寫入的地址和要寫入的數(shù)據(jù)。因此,在slave端,保持相同的設(shè)計(jì)就可以獲得最優(yōu)的性能。這也是上述代碼中為何寫地址通道獲取數(shù)據(jù)時(shí)也要求寫數(shù)據(jù)通道(wvalid)信號(hào)也有效。
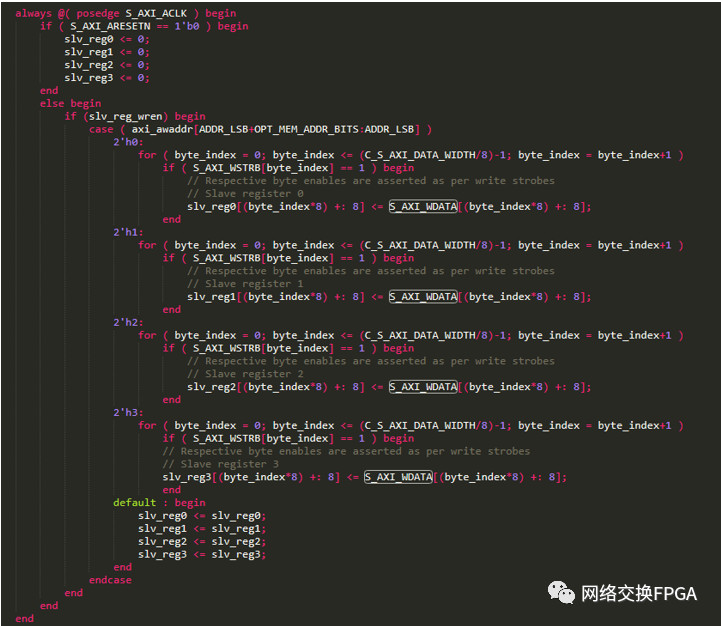
通過上述設(shè)計(jì),通過寫數(shù)據(jù)通道和寫地址通道獲取到了CPU想要寫入的地址和數(shù)據(jù),下一步就要將數(shù)據(jù)寫入對應(yīng)寄存器。由于我們選擇了4個(gè)寄存器,在代碼中已經(jīng)由VIVADO為我們自動(dòng)生成了4個(gè)slave寄存器。4個(gè)寄存器共需要2位地址線來進(jìn)行尋址,由于slave是掛在ARM 處理器外部的,當(dāng)處理器調(diào)用函數(shù)寫外設(shè)的寄存器,如果不做偏移,那么數(shù)據(jù)就會(huì)寫入寄存器0,因此地址axi_awaddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB]決定了將數(shù)據(jù)寫入哪個(gè)寄存器。ADDR_LSB是由數(shù)據(jù)位寬決定的,DDR數(shù)據(jù)位寬為字節(jié),所以地址線最低位對應(yīng)8位數(shù)據(jù),對于32位位寬的數(shù)據(jù),我們必須進(jìn)行32位對齊,所以地址偏移從32/4+1位開始。OPT_MEM_ADDR_BITS則決定了偏移范圍有多大,兩位的位寬就足以尋址4個(gè)寄存器,一次本工程中OPT_MEM_ADDR_BITS是1,地址位寬是[1:0]共二位,如果8個(gè)寄存器就需要三位,那么OPT_MEM_ADDR_BITS就需要定義為2。
下面的代碼實(shí)現(xiàn)了根據(jù)偏移地址將數(shù)據(jù)寫入對應(yīng)寄存器的操作。
假設(shè)slave基地址0x43c00000,當(dāng)我們調(diào)用Xil_Out32(0x43C00000,Value)寫的就是slv_reg0的值,此時(shí)axi_awaddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB]即axi_awaddr[3:2]為2’b00,如果地址偏移4位,Xil_Out32(0x43C00000+4,Value),此時(shí)寫入slv_reg1寄存器,同時(shí)axi_awaddr[3:2]為2’b01.
上面分析了寫通道的數(shù)據(jù)傳輸,接下來分析讀數(shù)據(jù)通道
讀地址通道和讀數(shù)據(jù)通道的傳輸不可能同時(shí)進(jìn)行,master端通過握手信號(hào)將讀地址寫入slave端,slave準(zhǔn)備數(shù)據(jù)然后通過握手信號(hào)返回?cái)?shù)據(jù)給master。
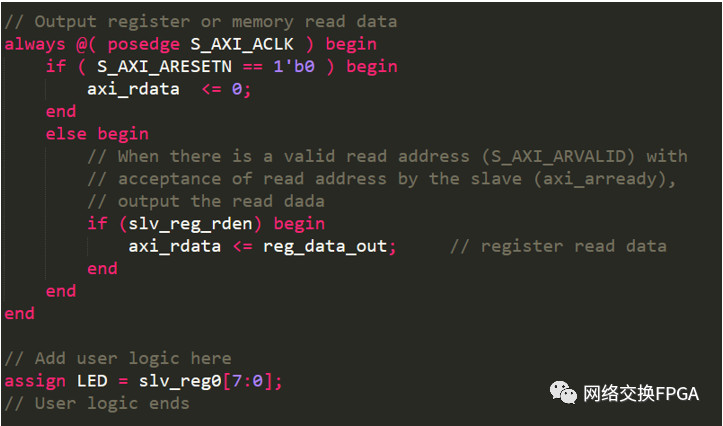
Slave上電復(fù)位后將讀地址通道arready信號(hào)拉低,master需要讀數(shù)據(jù)時(shí)將地址發(fā)送到讀地址通道的araddr信號(hào)線上,同時(shí)拉高arvalid信號(hào),發(fā)起一次讀地址發(fā)送,slave端檢測到arvalid信號(hào)有效,鎖存araddr數(shù)據(jù),并拉高arready信號(hào)完成讀地址接受過程。slave根據(jù)ardddr的偏移獲取對應(yīng)寄存器的數(shù)據(jù),然后在讀數(shù)據(jù)通道上主動(dòng)發(fā)起一次數(shù)據(jù)傳輸,即將數(shù)據(jù)置入rdata并拉高讀地址通道的rvalid信號(hào),等待master接受數(shù)據(jù)并返回rready信號(hào)有效后完成讀數(shù)據(jù)傳輸。
因?yàn)閆edboard開發(fā)板有8位led燈,所以我們設(shè)計(jì)一個(gè)8位寬的wire型線連接到寄存器0的低8位即可。
需要注意在頂層文件中添加該端口。
至此,我們自定義的IP就設(shè)計(jì)完成了,我們重新封裝該IP核。
首先點(diǎn)擊各項(xiàng)的藍(lán)色感嘆號(hào),vivado會(huì)自動(dòng)更改IP的一些信息。全部消失后就可以進(jìn)行IP封裝。
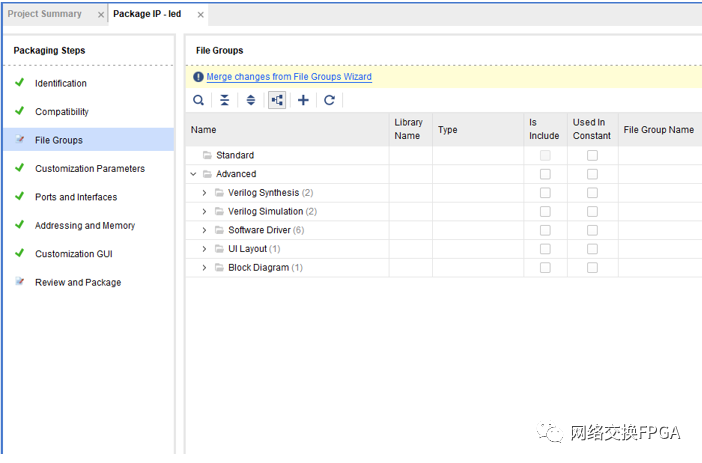
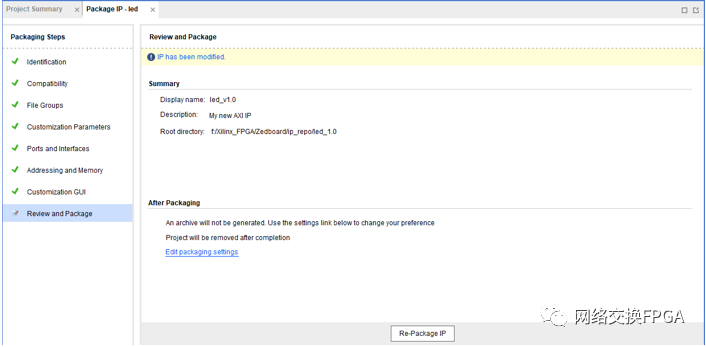
選擇重新封裝選項(xiàng)進(jìn)行封裝,封裝完成后VIVADO工程會(huì)自動(dòng)關(guān)閉。
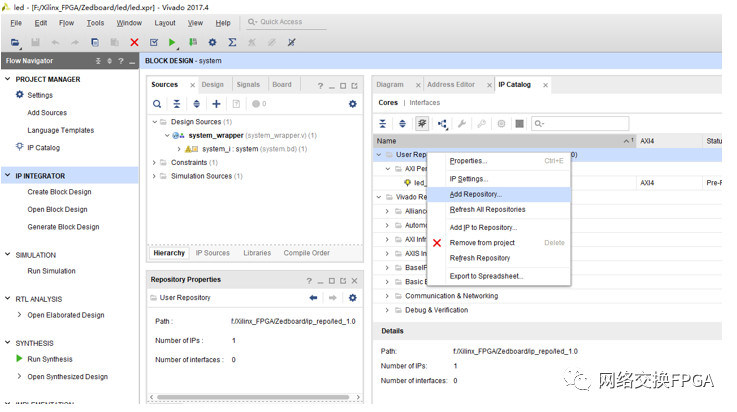
將封裝好的IP添加到庫目錄,在任意VIVADO工程中選擇IP Catalog選項(xiàng),選中USER Repository選項(xiàng),右鍵選中Add Repositor,選中我們之前建立IP時(shí)選擇的目錄。添加完成。
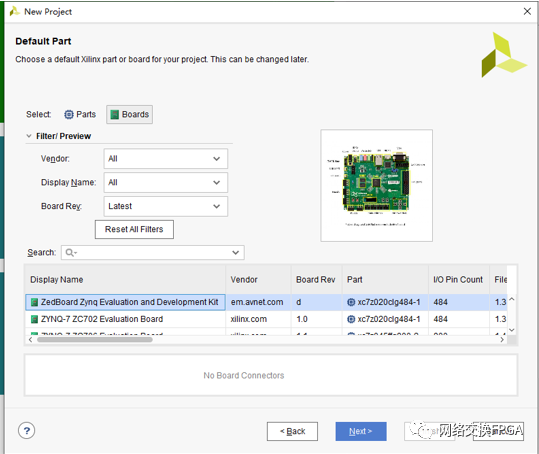
(3)硬件工程設(shè)計(jì)
本次實(shí)驗(yàn)基于VIVADO2017.4版本進(jìn)行硬件設(shè)計(jì),建立VIVADO工程并選用Zedboard開發(fā)板(這樣后面的部分接口可以使用VIVADO默認(rèn)配置)
新建block design,添加zynq processing_system,然后點(diǎn)擊Run BlockAutomation進(jìn)行硬件板卡信息填充。運(yùn)行完成后可以看到ZYNQ系統(tǒng)以及配置好了DDR內(nèi)存和串口設(shè)置。
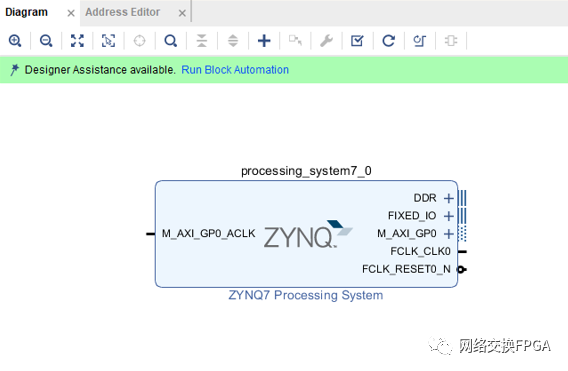
如果你使用其他板卡,那么要根據(jù)外設(shè)的位置和內(nèi)存型號(hào)進(jìn)行設(shè)置,這里進(jìn)行簡單介紹。
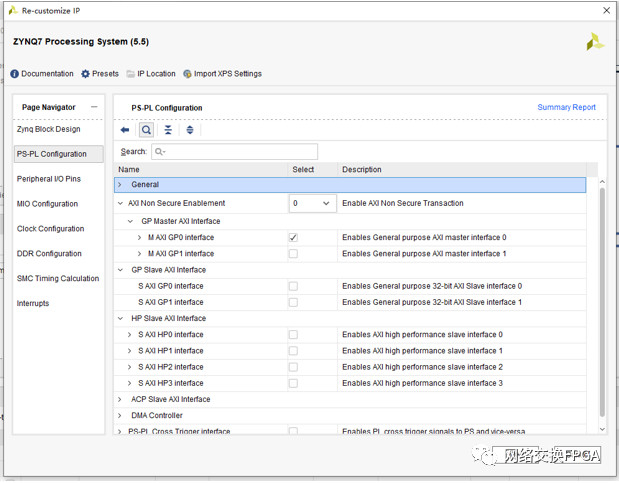
PS-PL配置選項(xiàng)用于打開PS單元和PL單元之前的互聯(lián)總線,PS單元中面向PL單元的有4個(gè)GP接口。也就是兩個(gè)AXI-Lite主端口和兩個(gè)AXI-Lite從端口,以及4個(gè)高速的HP接口。由于我們需要CPU配置FPGA,因此啟用一個(gè)GP主端口。
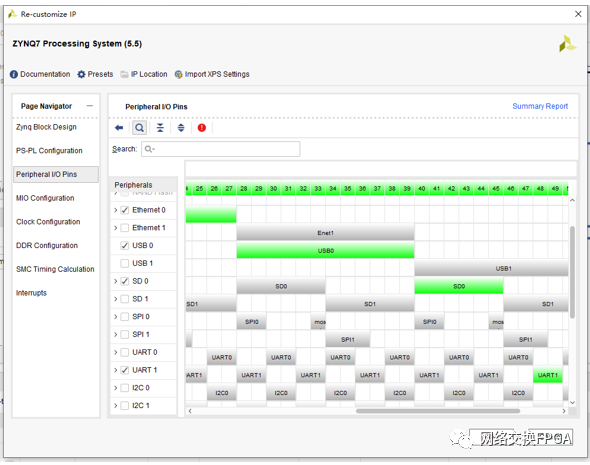
配置IO選項(xiàng)用于關(guān)閉和打開ZYNQ的外設(shè)部分的配置,由于ZYNQ可靈活配置,因此需要選擇和板卡相對應(yīng)的外設(shè)位置,選擇Zedboard的好處在于可以利用VIVADO中預(yù)設(shè)的板卡信息進(jìn)行自動(dòng)設(shè)置。
需要注意的是,這部分I/O口為ZYNQ的MIO,而PL部分的為EMIO。
另外,想要成功啟動(dòng)linux至少需要一個(gè)TTC外設(shè)。
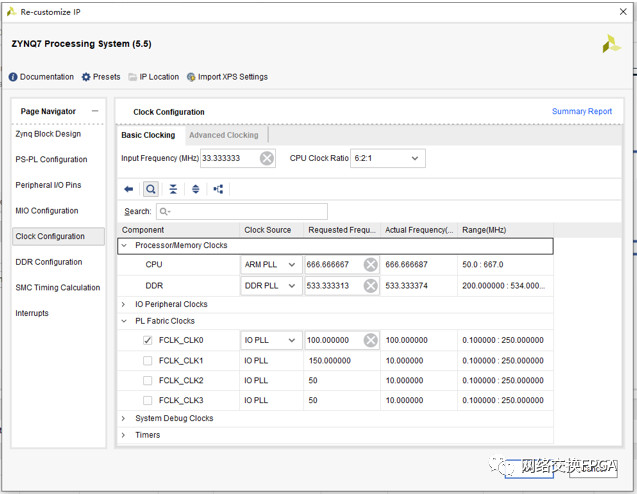
時(shí)鐘配置選項(xiàng)用于管理PS單元和PL單元的時(shí)鐘,包括內(nèi)存頻率和CPU主頻信息,I/O口頻率設(shè)置。另外PS部分可以向PL部分提供最多4個(gè)時(shí)鐘,這里僅開啟一個(gè)100M的時(shí)鐘。
DDR配置選項(xiàng)選擇正確的內(nèi)存型號(hào)即可,這里仍然使用Zedboard的默認(rèn)配置即可。較為重要的是下面的中斷選項(xiàng),可以選擇打開PS和PL之間的中斷開關(guān),因?yàn)楸敬喂こ虝簳r(shí)沒有用到,所以不再贅述。
點(diǎn)擊OK保存對處理器系統(tǒng)的配置,繼續(xù)添加IP,搜索我們之前定制的IP,發(fā)現(xiàn)led V1版本的自定義IP核,點(diǎn)擊添加。
添加完成后將led端口引出,可以使用快捷鍵Ctrl+T,或者使用右鍵菜單也可以完成。我們將剩余的AXI標(biāo)準(zhǔn)端口使用VIVADO的自動(dòng)連線功能完成連接。點(diǎn)擊Run Connection Automation,勾選所有IP,完成后發(fā)現(xiàn)VIVADO為我們自動(dòng)添加了一個(gè)AXI交換矩陣和復(fù)位模塊。
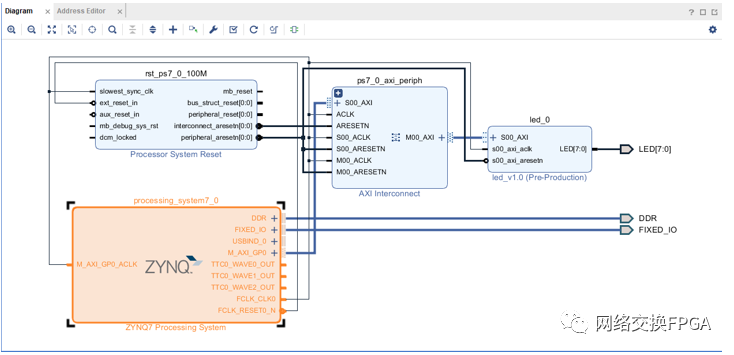
頂層模塊如圖,保存。
我們在工程管理中選中創(chuàng)建的Block Design,選中生成HDL
VIVADO會(huì)將處理器系統(tǒng)和IP部件生成Verilog文件。在工程中添加約束文件,加入對LED[7:0]的管教約束。
set_property PACKAGE_PIN T22 [get_ports {LED[0]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[0]}] set_property PACKAGE_PIN T21 [get_ports {LED[1]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[1]}] set_property PACKAGE_PIN U22 [get_ports {LED[2]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[2]}] set_property PACKAGE_PIN U21 [get_ports {LED[3]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[3]}] set_property PACKAGE_PIN V22 [get_ports {LED[4]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[4]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[5]}] set_property PACKAGE_PIN W22 [get_ports {LED[5]}] set_property PACKAGE_PIN U19 [get_ports {LED[6]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[6]}] set_property IOSTANDARD LVCMOS33 [get_ports {LED[7]}] set_property PACKAGE_PIN U14 [get_ports {LED[7]}]
然后就可以生成比特流了。
硬件設(shè)計(jì)部分的工作在這里就完成了,我們需要記錄外設(shè)在ARM處理器系統(tǒng)上掛載的地址,這樣才能使用軟件寫入和讀取其數(shù)據(jù)。在VIVAOD中Address Edit選項(xiàng)卡中可以編輯外設(shè)地址,這里我們保持默認(rèn),并記錄。
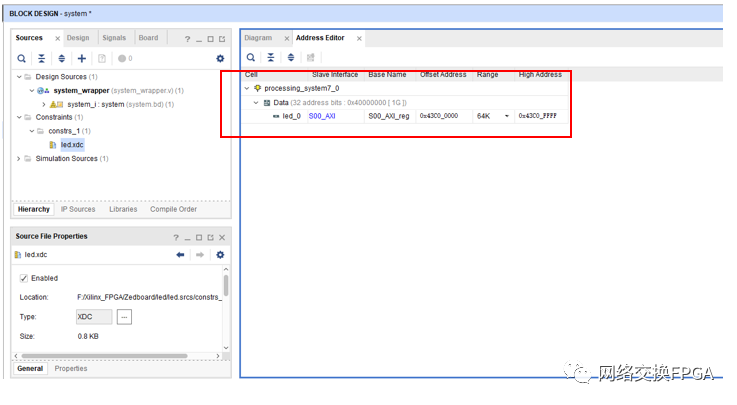
在完成硬件設(shè)計(jì)部分后,我們可以簡單的運(yùn)行一個(gè)裸機(jī)程序來檢驗(yàn)一下我們的映射關(guān)系是否正確。首先在VIVADO中將生成的比特流導(dǎo)出到SDK。
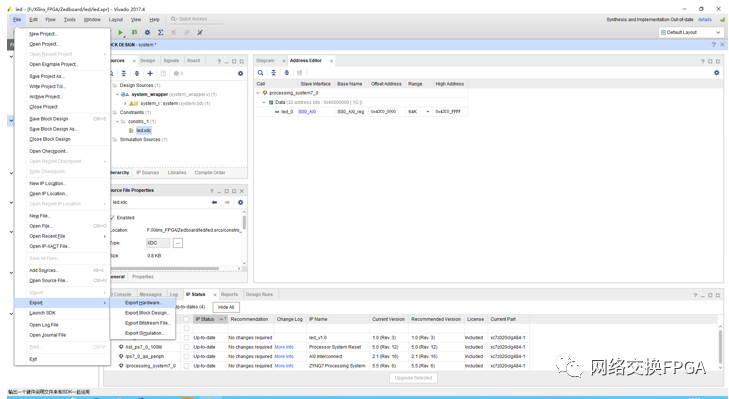
選擇File,Export->ExportHardware,而后選擇File->Lunch SDK,選擇本地路徑(這樣會(huì)包含硬件比特流)。
(4)裸機(jī)程序驗(yàn)證
在SDK下,已經(jīng)包含對應(yīng)工程的硬件平臺(tái)和板級(jí)支持包,點(diǎn)擊File -> New -> Application project建立一個(gè)新的SDK工程。
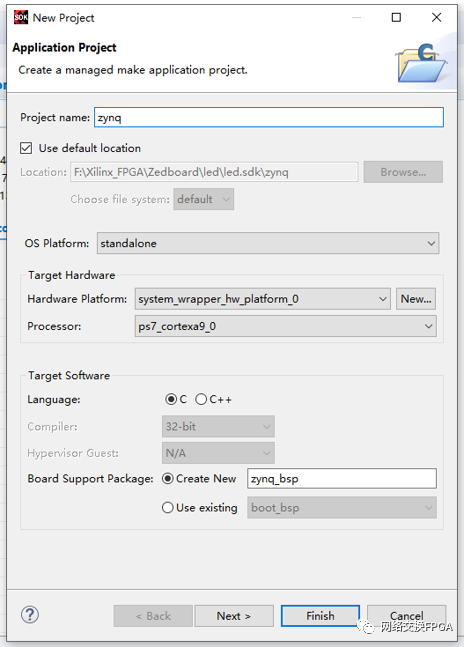
建立工程名稱,選擇裸機(jī),C語言開發(fā),班級(jí)支持包默認(rèn)。Next,選擇HelloWord模板。我們在main函數(shù)中做簡單修改:
#include #include "xparameters.h" #include "sleep.h" #include "xil_io.h" int main() { int i = 1; while(1) { for(i=0;i < 8;i++) { Xil_Out32(0x43c00000, 1<
通過上述程序,我們講一個(gè)8位循環(huán)的數(shù)據(jù)寫入寄存器0中,由于寄存0的低8位連接到了LED燈,因此會(huì)有流水燈的效果。
函數(shù) Xil_Out32(0x43c00000,1<
在軟件工程上右鍵選擇Run As -> runconfigurations
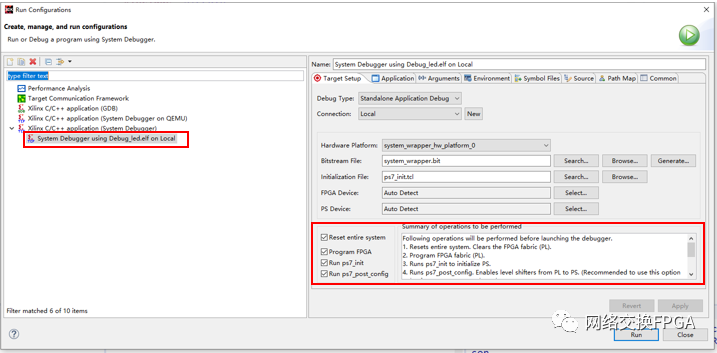
選擇對應(yīng)的比特流,選中燒寫FPGA和復(fù)位系統(tǒng),點(diǎn)擊run,可以看到燒寫完成后開發(fā)板成功點(diǎn)亮流水燈。
編輯:hfy
-
cpu
+關(guān)注
關(guān)注
68文章
10881瀏覽量
212218 -
IC設(shè)計(jì)
+關(guān)注
關(guān)注
38文章
1297瀏覽量
104093 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6856瀏覽量
123436 -
EDA設(shè)計(jì)
+關(guān)注
關(guān)注
1文章
47瀏覽量
13704
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
ZYNQ基礎(chǔ)---AXI DMA使用
dac3174與xilinx zynq7000系列連接,fpga的案例參考代碼有沒有?
Xilinx 7系列FPGA PCIe Gen3的應(yīng)用接口及特性
詳解FPGA的基本結(jié)構(gòu)
正點(diǎn)原子ZYNQ7015開發(fā)板!ZYNQ 7000系列、雙核ARM、PCIe2.0、SFPX2,性能強(qiáng)悍,資料豐富!
[XILINX] 正點(diǎn)原子ZYNQ7035/7045/7100開發(fā)板發(fā)布、ZYNQ 7000系列、雙核ARM、PCIe2.0、SFPX2!
復(fù)旦微PS+PL異構(gòu)多核開發(fā)案例分享,基于FMQL20SM國產(chǎn)處理器平臺(tái)
FM20S用戶手冊-PS + PL異構(gòu)多核案例開發(fā)手冊
簡談Xilinx Zynq-7000嵌入式系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
Xilinx ZYNQ 動(dòng)手實(shí)操演練
Zynq-7000為何不是FPGA?

簡談Xilinx Zynq-7000嵌入式系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
AMD推出全新Spartan UltraScale+ FPGA系列






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論