 深度學習中的YOLOv2-Tiny目標檢測算法詳細設計
深度學習中的YOLOv2-Tiny目標檢測算法詳細設計
近年來,以卷積神經網絡(Convolutional Neural Network,DNN)為代表的深度學習算法在許多計算機視覺任務上取得了巨大突破,如圖像分類、目標檢測、畫質增強等[1-2]。然而,隨著識別率的提高,深度學習算法的計算復雜度和內存需求也急劇增加,當前的通用處理器無法滿足其計算需求。主流的解決方法是采用圖形處理器(Graphics Processing Unit,GPU)、專用集成電路(Application Specific Integrated Circuit,ASIC)芯片或現場可編程門陣列(Field-Programmable Gate Array,FPGA)來提升計算性能。GPU采用單指令流多數據流架構,想要充分發揮計算性能,需要大批量數據,并且由于高并行度導致的高功耗,很難應用于對功耗有嚴格限制的場合[3]。ASIC對于具體應用可以獲得最佳性能和能效,但是研發周期長,需要對市場有長久的預見性。FPGA作為一種高性能、低功耗的可編程芯片,可以使用硬件描述語言來設計數字電路,以形成對應算法的加速電路結構。與GPU相比,FPGA低功耗、低延時,適用于小批量流式應用[4]。與ASIC相比,FPGA可以通過配置重新改變硬件結構,對具體應用定制硬件,適用于深度學習這種日新月異、不斷改變的場景。
本文首先介紹深度學習中的YOLOv2-Tiny目標檢測算法[5],然后設計對應的,并且就加速器中各模塊的處理時延進行簡單建模,給出卷積模塊的詳細設計,最后,在Xilinx公司的Zedboard開發板上進行評估。
1 YOLOv2-Tiny模型簡介
YOLOv2-Tiny目標檢測算法由以下3步組成:
(1)對任意分辨率的RGB圖像,將各像素除以255轉化到[0,1]區間,按原圖長寬比縮放至416×416,不足處填充0.5。
(2)將步驟(1)得到的416×416×3大小的數組輸入YOLOv2-Tiny網絡檢測,檢測后輸出13×13×425大小的數組。對于13×13×425數組的理解:將416×416的圖像劃分為13×13的網格。針對每個網格,預測5個邊框,每個邊框包含85維特征(共5×85=425維)。85維特征由3部分組成:對應邊框中包含的80類物體的概率(80維),邊框中心的相對偏移以及相對長寬比的預測(4維),邊框是否包含物體的可信度(1維)。
(3)處理步驟(2)中得到的13×13×425大小的數組,得到邊框的中心和長寬。根據各邊框覆蓋度、可信度和物體的預測概率等,對13×13×5個邊框進行處理,得到最有可能包含某物體的邊框。根據原圖的長寬比,將得到的邊框調整到原圖尺度,即得到物體的位置與類別信息。
YOLOv2-Tiny由16層組成,涉及3種層:卷積層(9層)、最大池化層(6層)以及最后的檢測層(最后1層)。其中,卷積層起到特征提取的作用,池化層用于抽樣和縮小特征圖規模。將步驟(1)稱為圖像的預處理,步驟(3)稱為圖像的后處理(后處理包含檢測層的處理)。
1.1 卷積層
對輸入特征圖以對應的卷積核進行卷積來實現特征提取,偽代碼如下:
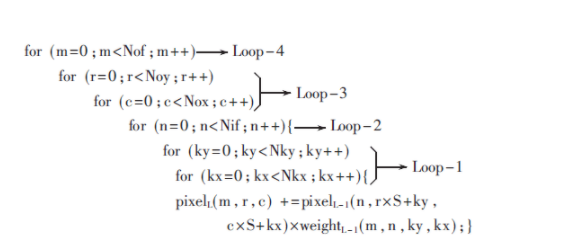
其中(Noy,Nox)、Nof、Nif、(Nky,Nkx)、S分別代表輸出特征圖、輸出特征圖數、輸入特征圖數、卷積核大小和步長。pixelL(m,r,c)代表輸出特征圖m中r行c列的像素。
1.2 池化層
對輸入特征圖降采樣,縮小特征圖的規模,一般跟在卷積層后。YOLOv2-Tiny采用最大池化層,最大池化層偽代碼如下所示:
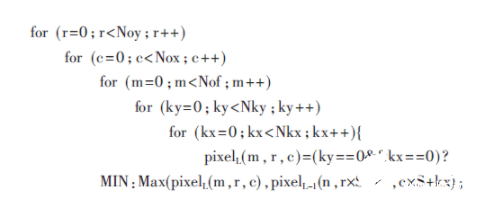
其中Max函數表示返回兩者中較大的值,MIN表示某最小值常量,其他參數含義與卷積層類似。由于池化層與卷積層類似,只是將卷積層的乘加運算替換為比較運算;同時,考慮到卷積層往往在網絡中占據90%以上的計算量,因此下文主要討論卷積模塊的設計。
2 基于FPGA的YOLOv2-Tiny加速器設計
2.1 加速器架構介紹
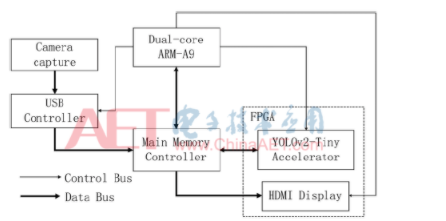
如圖1所示,加速器采用三層存儲架構:片外存儲、片上緩存和處理單元內的局部寄存器。加速器從片外存儲中讀取卷積核權重參數與輸入特征圖像素到FPGA的片上緩存,通過多次復用片上緩存中的數據來減少訪存次數和數據量。同時,計算得到的中間結果都保留在片上輸出緩存或者局部寄存器中,直至計算出最終的結果才寫回片外存儲。同時,也可以看出,加速器的時延主要由三部分組成:訪存時延、片上傳輸時延和計算時延。對應于該加速器架構,實際可以分為4個模塊:輸入讀取模塊、權重讀取模塊、計算模塊與輸出寫回模塊。
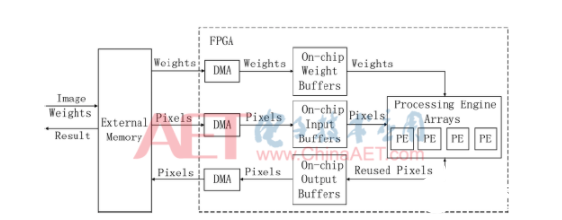
對應的加速器數據流偽代碼如下:

2.2 卷積模塊
對卷積循環中輸出特征圖數和輸入特征圖數兩維展開,形成Tof×Tif個并行乘法單元和Tof個深度的加法樹,流水地處理乘加計算。以Tof=2,Tif=3為例,如圖2所示。
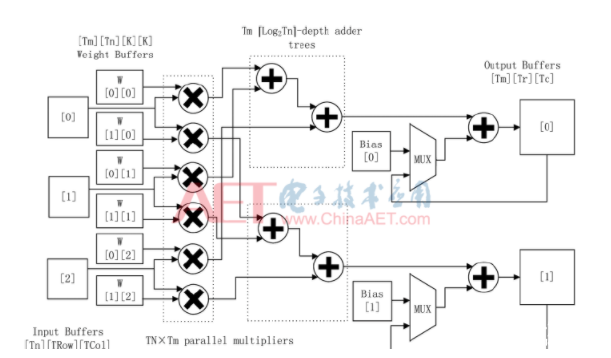
充滿流水線后,每個時鐘從Tif個輸入緩存中讀入Tif個像素,從Tof×Tif個權重緩存中讀入相同位置的參數,Tof×Tif個并行乘法單元復用Tif個輸入像素進行乘法計算。Tof個加法樹將乘積兩兩相加,得到的結果和中間結果累加后,寫回對應輸出緩存。卷積模塊對應的處理時延為:
其中Const表示流水線初始化等其他操作所需時鐘,Freq表示加速器的工作時鐘頻率。
2.3 各模塊的時延建模
本節介紹除卷積計算模塊外,另外三個模塊(輸入讀取模塊、權重讀取模塊、輸出寫回模塊)的處理時延。在此約定,MM(Data Length, Burst Lengthmax)表示以最大突發長度Burst Lengthmax訪存讀取或寫入Data Length長度的連續數據所需的訪存時延。
2.3.1 輸入讀取模塊
輸入讀取模塊的時延LatencyLoad IFM由兩部分組成:
(1)通過DMA從片外讀取Tif張輸入特征圖像Tiy×Tix大小的像素塊到片上的訪存時延:
(2)將輸入特征圖像素塊傳輸到片上緩存的傳輸時延:
一般對兩個過程乒乓,輸入讀取時模塊的處理時延為:
2.3.2 權重讀取模塊
權重讀取模塊的時延LatencyLoad W由兩部分組成:
(1)通過DMA從片外讀取Tof個卷積核中對應Tif張輸入特征圖的Nky×Nkx個權重到片上的訪存時延:
(2)將權重參數傳輸到片上緩存的傳輸時延:

2.3.3 輸出寫回模塊
輸出寫回模塊的時延LatencyStore由兩部分組成:
(1)將輸出特征圖像素塊傳輸到DMA的傳輸時延:
(2)通過DMA將Tof張輸出特征圖Toy×Tox大小的像素塊寫回片外的訪存時延:

通過乒乓緩沖設計,將輸入讀取模塊的時延LatencyLoad、卷積模塊的計算時延LatencyCompute和輸出寫回模塊的時延LatencyStore相互掩蓋,以減少總時延。
3 實驗評估
3.1 實驗環境
基于Xilinx公司的Zedboard開發板(Dual-core ARM-A9+FPGA),其中FPGA的BRAM_18Kb、DSP48E、FF和LUT資源數分別為280、220、106 400和53 200。雙核 ARM-A9,時鐘頻率667 MHz,內存512 MB。采用Logitech C210攝像頭,最大分辨率為640×480,最高可達到30 f/s。當前目標檢測系統的FPGA資源耗費如表1所示。
對比的其他CPU平臺:服務器CPU Intel E5-2620 v4(8 cores)工作頻率為2.1 GHz,內存為256 GB。
3.2 總體架構
如圖3所示,從USB攝像頭處得到采集圖像,存儲在內存中,由ARM進行預處理后交由FPGA端的YOLOv2-Tiny加速器進行目標檢測,檢測后的相關數據仍存放在內存中。經ARM后處理后,將帶有檢測類別與位置的圖像寫回內存中某地址,并交由FPGA端的HDMI控制器顯示在顯示屏上。
對應的顯示屏上的檢測結果如圖4所示。COCO數據集中圖片進行驗證的檢測結果如圖5所示。
3.3 性能評估
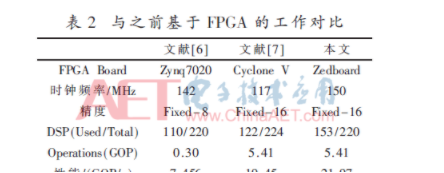
當前的設計在性能上超過了之前的工作,如表2所示。文獻[6]中的設計雖然通過縮小模型以及減小數據精度等方式將簡化后的整個YOLOv2-Tiny網絡按層全部映射到FPGA上,但是各層間由于沒有使用乒乓緩沖,導致訪存與數據傳輸時延無法與計算時延重疊。文獻[7]中的設計將卷積運算轉化為通用矩陣乘法運算,并通過矩陣分塊的方式并行計算多個矩陣分塊,但是將卷積轉化為通用矩陣乘法需要在每次計算前對卷積核參數復制與重排序,增加了額外的時延與復雜度。
矩陣分塊的方式,并行計算多個矩陣分塊,但是將卷積轉化為通用矩陣乘法需要在每次計算前對卷積核參數復制與重排序,增加了額外的時延與復雜度。
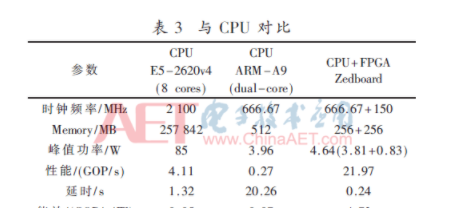
如表3所示,與CPU相比,CPU+FPGA的異構系統是雙核ARM-A9能效的67.5倍,Xeon的94.6倍;速度是雙核ARM-A9的84.4倍,Xeon的5.5倍左右。
4 結論
基于深度學習的目標檢測算法在準確度上已超過了傳統方法,然而隨著準確度的提高,計算復雜度和內存需求也急劇增加,當前的通用處理器無法滿足其計算需求。本文設計并實現了一種基于FPGA的深度學習目標檢測系統,設計了YOLOv2-Tiny硬件加速器,就加速器中各模塊的處理時延進行簡單建模,給出卷積模塊的詳細設計,最終實現的設計性能超過了當前的工作。
參考文獻
[1] RUSSAKOVSKY O,DENG J,SU H,et al.Imagenet large scale visual recognition challenge[J].International Journal of Computer Vision,2015,115(3):211-252.
[2] LIN T Y,MAIRE M,BELONGIE S,et al.Microsoft coco:common objects in context[C].European Conference on Computer Vision. Springer,Cham,2014:740-755.
[3] YU J,GUO K,HU Y,et al.Real-time object detection towards high power efficiency[C].2018 Design,Automation & Test in Europe Conference & Exhibition(DATE).IEEE,2018:704-708.
[4] CONG J,FANG Z,LO M,et al.Understanding performance differences of FPGAs and GPUs[C].2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines(FCCM).IEEE,2018.
[5] REDMON J, FARHADI A.YOLO9000:better,faster,stronger[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:7263-7271.
[6] 張雲軻,劉丹。基于小型Zynq SoC硬件加速的改進TINYYOLO實時車輛檢測算法實現[J]。計算機應用,2019,39(1):192-198.
[7] WAI Y J,YUSSOF Z B M,SALIM S I B,et al.Fixed point implementation of Tiny-Yolo-v2 using OpenCL on FPGA[J].International Journal of Advanced Computer Science and Applications,2018,9(10)。
作者信息:
陳 辰1,嚴 偉2,夏 珺1,柴志雷1
-
深度學習
+關注
關注
73文章
5511瀏覽量
121373 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11887
發布評論請先 登錄
相關推薦
采用華為云 Flexus 云服務器 X 實例部署 YOLOv3 算法完成目標檢測

在樹莓派上部署YOLOv5進行動物目標檢測的完整流程
基于迅為RK3588【RKNPU2項目實戰1】:YOLOV5實時目標分類
慧視小目標識別算法 解決目標檢測中的老大難問題

深度學習算法在集成電路測試中的應用
YOLOv5的原理、結構、特點和應用
口罩佩戴檢測算法

人員跌倒識別檢測算法

安全帽佩戴檢測算法

基于Tiny AI技術的玻璃敲碎聲事件離線檢測方案

深度解析深度學習下的語義SLAM

OpenVINO? C# API部署YOLOv9目標檢測和實例分割模型






 工商網監
工商網監
評論