 RTX 30顯卡細節公布 TFLOPS是什么參數
RTX 30顯卡細節公布 TFLOPS是什么參數
RTX 30顯卡的在線發布會上有一個細節特別引人矚目,那就是公布了一個名為TFLOPS的數據時,如果大家收看的視頻有彈幕,一定馬上就會彈幕爆炸了。這個參數到底是啥?為什么讓大家那么關注呢?咱們今天就來說說吧。
TFLOPS是Tera和Floating-point operations per second詞組的組合,后者的意思是每秒浮點運算次數,Tera則是萬億的意思,合起來就是每秒浮點運算多少萬億次。因為現在的圖像是分成像素點來處理的,每個點的色彩都要進行浮點運算,然后組合成一幅圖片,所以這個參數就說明了顯卡或者GPU每秒能處理多少個像素點。
它的基礎就來自現在的GPU設計,目前的GPU都是由很多小處理核心或者叫流處理器組成,這個核心比處理器核心簡單得多,每個時鐘周期只負責處理一個浮點數據,所以總的浮點運算次數就是核心數量×時鐘周期了。又因為現在的核心可以一次性處理一個雙精度浮點數據,它相當于兩個最基礎的單精度浮點數據,所以再×2就得到了GPU的浮點運算次數。
回過頭來看看這個參數對游戲有啥意義。在分辨率確定后,每一幅畫面的像素點數量也就確定了,那么每秒處理的像素點越多,實際上每秒能處理的畫面數量當然就越多。這說明了啥?當然就是游戲的幀速(每秒畫面數)越高啦。沒錯,對使用同一代特別是同一核心的顯卡,算出它的浮點運算能力,基本就了解游戲速度了。
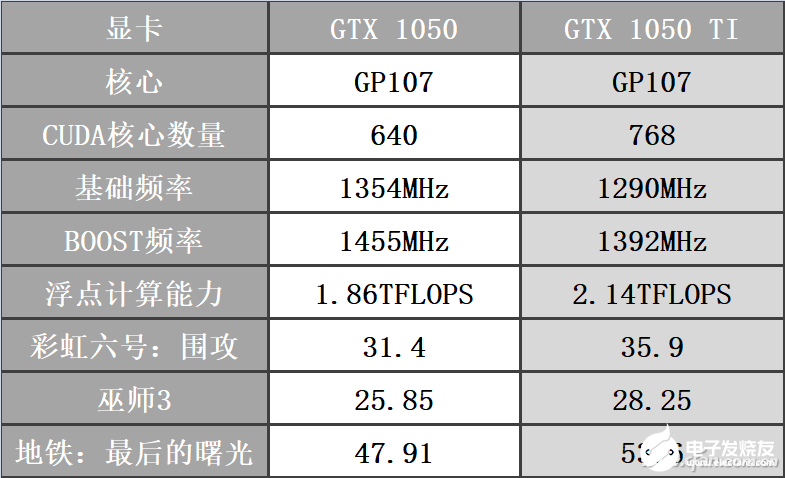
不過對于不同代甚至不同架構的GPU,這種對比就不合適了,比如RTX 3080擁有兩倍于RTX 2080 Ti的浮點運算次數,幀速能達到RTX 2080 Ti的兩倍嗎?從之前的測試大家就知道,當然不是這樣。

這就牽扯出了另一個問題,也就是核心的效率,因為誰也不能保證所有的核心或者流處理器能一直滿載、有效運行,它的實際發揮還要考慮到前端的分配、后端的合成、顯存數據等單元的配合,所以設計不同的架構下,按照最理想情況算出的浮點運算次數能發揮多少也是不同的。
RTX 30還有所不同,因為它實際上是讓每個核心中的整數運算單元也參加浮點運算,造成了“理論”運算能力翻倍、但因為干的是非專業工作,整數單元的浮點運算效率肯定趕不上專業的浮點運算單元,再加上前端的數據分配能力、顯存帶寬啥的沒有跟著翻倍,所以效率大幅下降,最終我們可以看到,翻倍的浮點運算能力帶來的只是不到40%的實際幀速提升。

既然同一個廠家在架構上的改動都會造成浮點運算能力的實際發揮,AMD和NV這種相差更遠的架構就別提了,比如RX 6800系列用了比較特殊的架構設計,就以遠低于RTX 3080/3070的浮點運算能力,得到了能抗衡甚至壓制它們的性能。
編輯:hfy
-
amd
+關注
關注
25文章
5484瀏覽量
134348 -
gpu
+關注
關注
28文章
4760瀏覽量
129129 -
顯卡
+關注
關注
16文章
2442瀏覽量
67886
發布評論請先 登錄
相關推薦
微軟新主機GPU性能公布 略低于目前最強游戲顯卡GeForce RTX 2080 Ti
NVIDIA發布RTX 30系列顯卡,支持PCle 4.0功能
NVIDIA正式發布GeForce RTX 30系列顯卡!
英偉達RTX 30系列顯卡,售價不到RTX 2080 Ti的一半





 工商網監
工商網監
評論