 探討神經網絡基本架構:單元/神經元、連接/權重/參數、偏置項
探討神經網絡基本架構:單元/神經元、連接/權重/參數、偏置項
神經網絡(NN)幾乎可以在每個領域幫助我們用創造性的方式解決問題。本文將介紹神經網絡的相關知識。讀后你將對神經網絡有個大概了解,它是如何工作的?如何創建神經網絡?
神經網絡的發展歷史
神經網絡起源于 WarrenMcCulloch 和 Walter Pitts 于 1943 年首次建立的神經網絡模型。他們的模型完全基于數學和算法,由于缺乏計算資源,模型無法測試。
后來,在 1958 年,Frank Rosenblatt 創建了第一個可以進行模式識別的模型,改變了現狀。即感知器。但是他只提出了 notation 和模型。實際的神經網絡模型仍然無法測試,此前的相關研究也較少。
第一批可以測試并具有多個層的神經網絡于 1965 年由 Alexey Ivakhnenko 和 Lapa 創建。
之后,由于機器學習模型具有很強可行性,神經網絡的研究停滯不前。很多人認為這是因為 Marvin Minsky 和 Seymour Papert 在 1969 年完成的書《感知機》(Perceptrons)導致的。
然而,這個停滯期相對較短。6 年后,即 1975 年,Paul Werbos 提出反向傳播,解決了 XOR 問題,并且使神經網絡的學習效率更高。
1992 年,最大池化(max-pooling)被提出,這有助于 3D 目標識別,因為它具備平移不變性,對變形具備一定魯棒性。
2009 年至 2012 年間,JürgenSchmidhuber 研究小組創建的循環神經網絡和深度前饋神經網絡獲得了模式識別和機器學習領域 8 項國際競賽的冠軍。
2011 年,深度學習神經網絡開始將卷積層與最大池化層合并,然后將其輸出傳遞給幾個全連接層,再傳遞給輸出層。這些被稱為卷積神經網絡。
在這之后還有更多的研究。
什么是神經網絡?
了解神經網絡的一個好方法是將它看作復合函數。你輸入一些數據,它會輸出一些數據。
3 個部分組成了神經網絡的的基本架構:
- 單元/神經元
- 連接/權重/參數
- 偏置項
你可以把它們看作建筑物的「磚塊」。根據你希望建筑物擁有的功能來安排磚塊的位置。水泥是權重。無論權重多大,如果沒有足夠的磚塊,建筑物還是會倒塌。然而,你可以讓建筑以最小的精度運行(使用最少的磚塊),然后逐步構建架構來解決問題。
我將在后面的章節中更多地討論權重、偏置項和單元。
單元/神經元
作為神經網絡架構三個部分中最不重要的部分,神經元是包含權重和偏置項的函數,等待數據傳遞給它們。接收數據后,它們執行一些計算,然后使用激活函數將數據限制在一個范圍內(多數情況下)。
我們將這些單元想象成一個包含權重和偏置項的盒子。盒子從兩端打開。一端接收數據,另一端輸出修改后的數據。數據首先進入盒子中,將權重與數據相乘,再向相乘的數據添加偏置項。這是一個單元,也可以被認為是一個函數。該函數與下面這個直線方程類似:
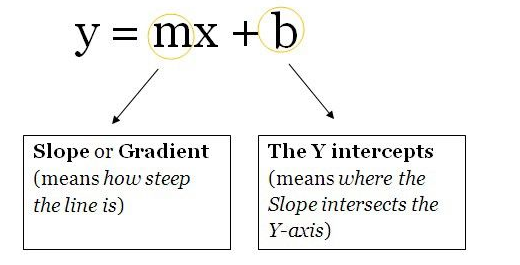
想象一下有多個直線方程,超過 2 個可以促進神經網絡中的非線性。從現在開始,你將為同一個數據點(輸入)計算多個輸出值。這些輸出值將被發送到另一個單元,然后神經網絡會計算出最終輸出值。
權重/參數/連接
作為神經網絡最重要的部分,這些(和偏置項)是用神經網絡解決問題時必須學習的數值。這就是你現在需要知道的。
偏置項
這些數字代表神經網絡認為其在將權重與數據相乘之后應該添加的內容。當然,它們經常出錯,但神經網絡隨后也學習到最佳偏置項。
超參數
超參數必須手動設置。如果將神經網絡看作一臺機器,那么改變機器行為的 nob 就是神經網絡的超參數。
你可以閱讀我的另一篇文章(https://towardsdatascience.com/gas-and-nns-6a41f1e8146d),了解如何優化神經網絡超參數。
激活函數
也稱為映射函數(mapping function)。它們在 x 軸上輸入數據,并在有限的范圍內(大部分情況下)輸出一個值。大多數情況下,它們被用于將單元的較大輸出轉換成較小的值。你選擇的激活函數可以大幅提高或降低神經網絡的性能。如果你喜歡,你可以為不同的單元選擇不同的激活函數。
以下是一些常見的激活函數:
- Sigmoid
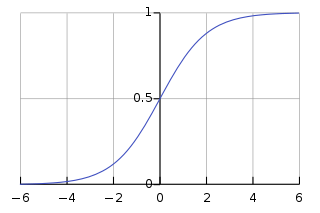
Sigmoid 函數
- Tanh
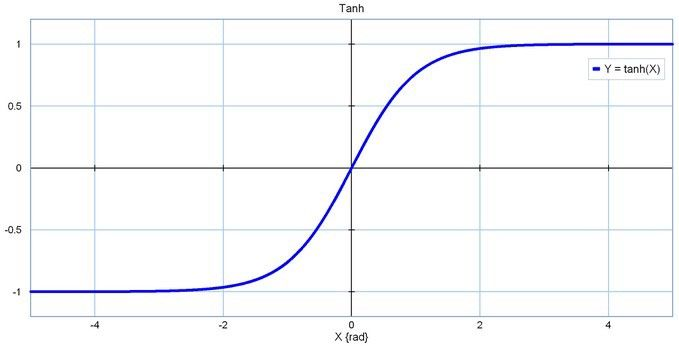
tanh 函數
- ReLU:修正線性單元
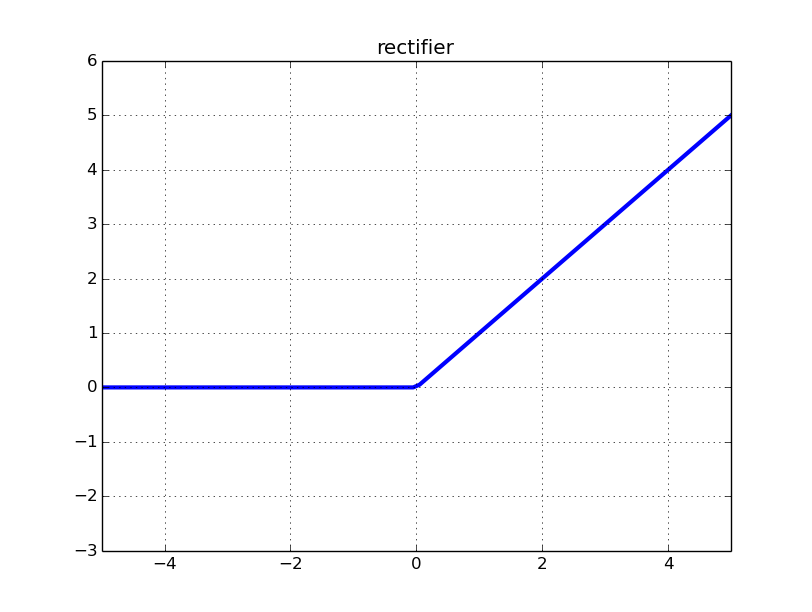
修正線性單元函數
- Leaky ReLU
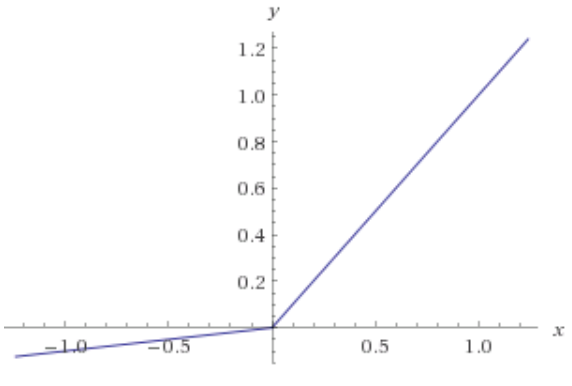
Leaky ReLU 函數
層
這是神經網絡在任何問題中都可獲得復雜度的原因。增加層(具備單元)可增加神經網絡輸出的非線性。
每個層都包含一定數量的單元。大多數情況下單元的數量完全取決于創建者。但是,對于一個簡單的任務而言,層數過多會增加不必要的復雜性,且在大多數情況下會降低其準確率。反之亦然。
每個神經網絡有兩層:輸入層和輸出層。二者之間的層稱為隱藏層。下圖所示的神經網絡包含一個輸入層(8 個單元)、一個輸出層(4 個單元)和 3 個隱藏層(每層包含 9 個單元)。
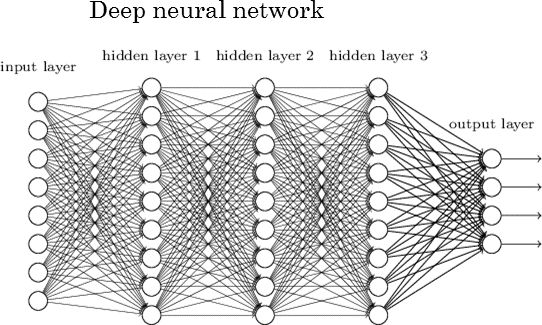
深度神經網絡
具有兩個或更多隱藏層且每層包含大量單元的神經網絡稱為深度神經網絡,它催生了深度學習這一新的學習領域。上圖所示神經網絡就是這樣一個例子。
神經網絡學習時發生了什么?
教神經網絡解決問題的最常見方式是使用梯度下降。梯度下降相關內容,參見:https://hackernoon.com/gradient-descent-aynk-7cbe95a778da。
除梯度下降外,另一種常見的訓練神經網絡方法是使用反向傳播。使用這種方法,神經網絡輸出層的誤差會通過微積分中的鏈式規則向后傳播。這對于沒有微積分知識的初學者來說可能會難以理解,但也不要被嚇倒,反向傳播相關內容,推薦閱讀:http://neuralnetworksanddeeplearning.com/chap2.html。
訓練神經網絡有許多注意事項。但對于初學者來說,沒有必要在一篇文章中了解全部。
實現細節(如何管理項目中的所有因素)
為了解釋如何管理項目中的所有因素,我創建了一個 Jupyter Notebook,包含一個學習 XOR 邏輯門的小型神經網絡。Jupyter Notebook 地址:https://github.com/Frixoe/xor-neural-network/blob/master/XOR-Net-Noteboo...。
在查看并理解 Notebook 內容后,你應該對如何構建基礎神經網絡有一個大致的了解。
Notebook 創建的神經網絡的訓練數據以矩陣排列,這是常見的數據排列方式。不同項目中的矩陣維度可能會有所不同。
大量數據通常分為兩類:訓練數據(60%)和測試數據(40%)。神經網絡先使用訓練數據,然后在測試數據上測試網絡的準確率。
關于神經網絡的更多信息(更多資源鏈接)
如果你仍然無法理解神經網絡,那么推薦以下資源:
YouTube:
Siraj Raval (https://www.youtube.com/channel/UCWN3xxRkmTPmbKwht9FuE5A)
3Blue1Brown (https://www.youtube.com/channel/UCYO_jab_esuFRV4b17AJtAw)
The Coding Train (https://www.youtube.com/playlist?list=PLRqwX-V7Uu6aCibgK1PTWWu9by6XFdCfh)
Brandon Rohrer (https://www.youtube.com/channel/UCsBKTrp45lTfHa_p49I2AEQ)
giant_neural_network (https://www.youtube.com/channel/UCrBzGHKmGDcwLFnQGHJ3XYg)
Hugo Larochelle (https://www.youtube.com/channel/UCiDouKcxRmAdc5OeZdiRwAg)
Jabrils (https://www.youtube.com/channel/UCQALLeQPoZdZC4JNUboVEUg)
Luis Serrano (https://www.youtube.com/channel/UCgBncpylJ1kiVaPyP-PZauQ)
Coursera:
Neural Networks for Machine Learning (https://www.coursera.org/learn/neural-networks) by University of Toronto
Deep Learning Specialization (https://www.coursera.org/specializations/deep-learning) by Andrew Ng
Introduction to Deep Learning (https://www.coursera.org/learn/intro-to-deep-learning) by National Research University Higher School of Economics
編輯:hfy
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100773 -
卷積
+關注
關注
0文章
95瀏覽量
18511 -
神經元
+關注
關注
1文章
363瀏覽量
18452 -
深度學習
+關注
關注
73文章
5503瀏覽量
121170
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論