

效果圖
大家好,我是Gray,是一名默默無聞的嵌入式軟件工程師,比較喜歡鉆研新技術,一直關注鴻蒙,由于錯過最佳申請板子的時間,現在手頭沒有開發板,申請的還沒有下文,現在借用別人的,下班回來搞搞,希望官方有多的板子能送我一套3861~~,今天就給大家分享一下我的在移植OLED到鴻蒙,其實也不叫移植,已經有大佬們移植好了,我只是修改一些函數,讓它用起來更加的方便,更加符合我們程序猿的使用風格,今天的主要內容就是讓OLED能通過Printf那樣輸出字符串,支持中英混合的那種,先看效果圖:
可以是這種姿勢:
ssd1306_Print(0,0,"哈嘍鴻蒙", White);

這種姿勢:
ssd1306_Print(0,0,"哈嘍Harmony", White);

甚至還可以這么搞:
sprintf(buff,"溫度 %d C",20); ssd1306_Print(0,32,buff, White);

這樣用不比下面的這樣的香嗎??????
OLED_ShowCHinese(0,0,0); OLED_ShowCHinese(16,0,1); OLED_ShowCHinese(32,0,2); OLED_ShowCHinese(48,0,3); OLED_ShowCHinese(64,0,4); OLED_ShowCHinese(80,0,5); OLED_ShowCHinese(96,0,6); //顯示 空氣質量檢測儀 OLED_ShowString(0,2,"T:"); OLED_ShowNum(16,2,temperature,2,16);//顯示溫度值 OLED_ShowCHinese(32,2,8);//顯示溫度符號 OLED_ShowString(56,2,"R:"); OLED_ShowChar(88,2,'%');//顯示溫度符號 OLED_ShowNum(72,2,humidity,2,16);
傳統的這種一個字一條語句,你還得算某個字體有沒有越位,或者位置是不是有間隔了。。。這樣浪費多少時間,怎么能容忍這樣的事情發生呢?堅決不能容忍!!!!接下來看看怎么弄吧~~
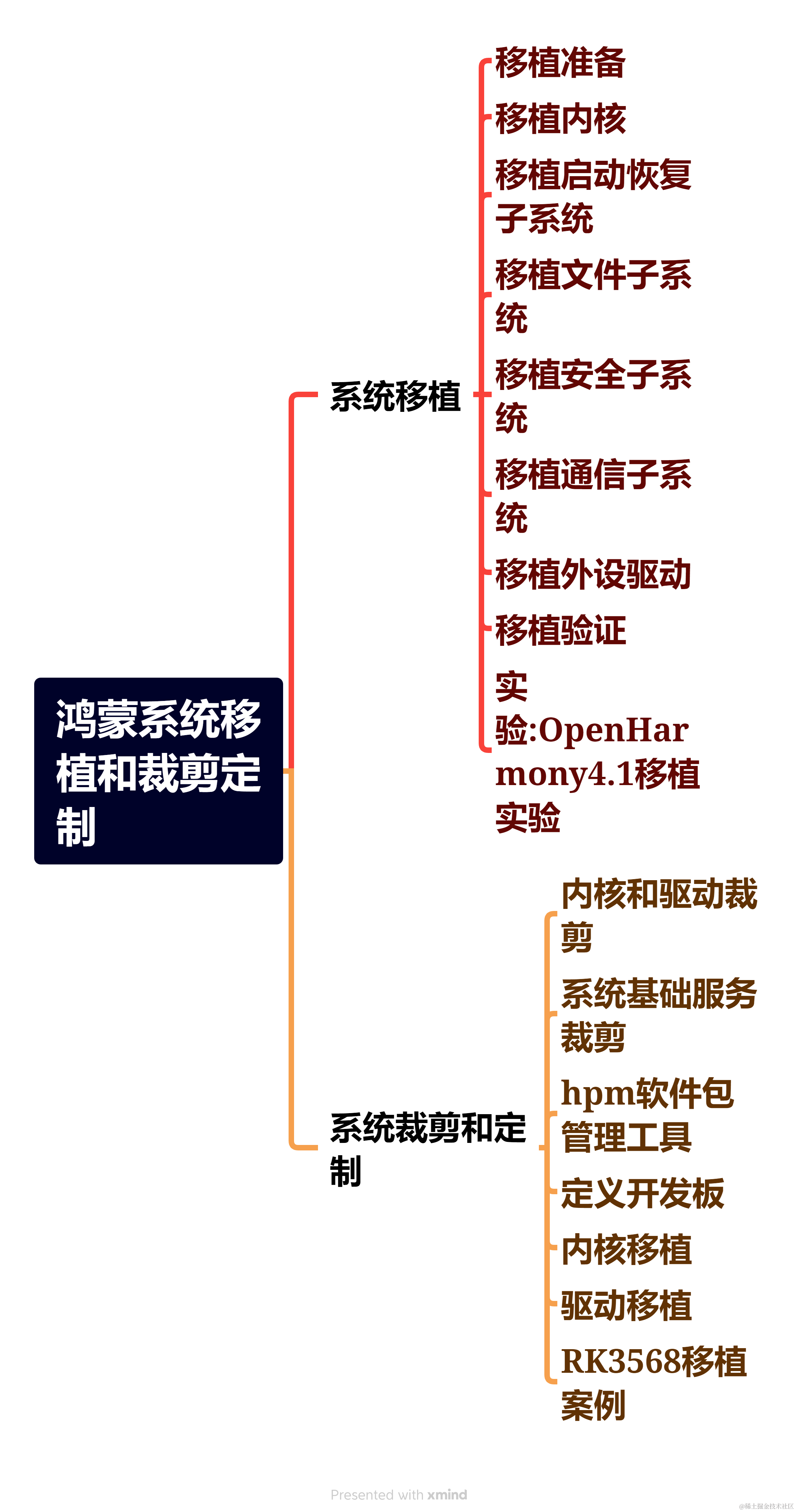
移植教程
聲明:跟著本教程操作默認你已經搭建好環境,環境搭建可移步:
傳送
移植教程已經有了,我是參照潤和許老師的教程修改的,移植教程請移步:
[傳送]
教程是把代碼下載到根目錄,并運行,但是我們做項目都是把外設模塊統一放在app下執行,所以我的移植是這樣的:
1.把代碼下載并上傳到 linux服務器,我的是虛擬機,直接通過共享文件夾上傳到虛擬機桌面,然后敲命令
unzip harmonyos-ssd1306-master.zip -d /home/harmony/harmony/code/code-1.0/applications/sample/wifi-iot/app/
解壓到app文件夾:
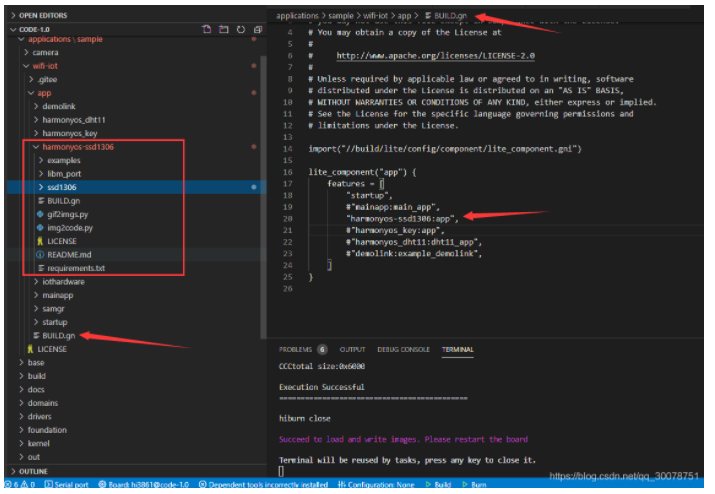
然后修改app目錄下的BUILD.gn ,添加"harmonyos-ssd1306:app", 注意分號
然后編譯,下載即可。
如何顯示中文
我們都知道,oled顯示都是ascii碼,那中文是用什么碼來顯示呢?這里普及一下漢字編碼知識:
中文漢字:
字節數 : 2;編碼:GB2312
字節數 : 2;編碼:GBK
字節數 : 2;編碼:GB18030
字節數 : 1;編碼:ISO-8859-1
字節數 : 3;編碼:UTF-8
字節數 : 4;編碼:UTF-16
字節數 : 2;編碼:UTF-16BE
字節數 : 2;編碼:UTF-16LE
1、美國人首先對其英文字符進行了編碼,也就是最早的ascii碼,用一個字節的低7位來表示英文的128個字符,高1位統一為0;
2、后來歐洲人發現尼瑪你這128位哪夠用,比如我高貴的法國人字母上面的還有注音符,這個怎么區分,得,把高1位編進來吧,這樣歐洲普遍使用一個全字節進行編碼,最多可表示256位。歐美人就是喜歡直來直去,字符少,編碼用得位數少; 3、但是即使位數少,不同國家地區用不同的字符編碼,雖然0–127表示的符號是一樣的,但是128–255這一段的解釋完全亂套了,即使2進制完全一樣,表示的字符完全不一樣,比如135在法語,希伯來語,俄語編碼中完全是不同的符號; 4、更麻煩的是,尼瑪這電腦高科技傳到中國后,中國人發現我們有10萬多個漢字,你們歐美這256字塞牙縫都不夠。于是就發明了GB2312這些漢字編碼,典型的用2個字節來表示絕大部分的常用漢字,最多可以表示65536個漢字字符,這樣就不難理解有些漢字你在新華字典里查得到,但是電腦上如果不處理一下你是顯示不出來的了吧。
5、這下各用各的字符集編碼,這世界咋統一?俄國人發封email給中國人,兩邊字符集編碼不同,尼瑪顯示都是亂碼啊。為了統一,于是就發明了unicode,將世界上所有的符號都納入其中,每一個符號都給予一個獨一無二的編碼,現在unicode可以容納100多萬個符號,每個符號的編碼都不一樣,這下可統一了,所有語言都可以互通,一個網頁頁面里可以同時顯示各國文字。
6、然而,unicode雖然統一了全世界字符的二進制編碼,但沒有規定如何存儲啊,親。x86和amd體系結構的電腦小端序和大端序都分不清,別提計算機如何識別到底是unicode還是acsii了。如果Unicode統一規定,每個符號用三個或四個字節表示,那么每個英文字母前都必然有二到三個字節是0,文本文件的大小會因此大出二三倍,這對于存儲來說是極大的浪費。這樣導致一個后果:出現了Unicode的多種存儲方式。 7、互聯網的興起,網頁上要顯示各種字符,必須統一啊,親。utf-8就是Unicode最重要的實現方式之一。另外還有utf-16、utf-32等。UTF-8不是固定字長編碼的,而是一種變長的編碼方式。它可以使用1~4個字節表示一個符號,根據不同的符號而變化字節長度。這是種比較巧妙的設計,如果一個字節的第一位是0,則這個字節單獨就是一個字符;如果第一位是1,則連續有多少個1,就表示當前字符占用多少個字節。
8、注意unicode的字符編碼和utf-8的存儲編碼表示是不同的,例如"嚴"字的Unicode碼是4E25,UTF-8編碼是E4B8A5,這個7里面解釋了的,UTF-8編碼不僅考慮了編碼,還考慮了存儲,E4B8A5是在存儲識別編碼的基礎上塞進了4E25。
9、UTF-8 使用一至四個字節為每個字符編碼。128 個 ASCII 字符(Unicode 范圍由 U+0000 至 U+007F)只需一個字節,帶有變音符號的拉丁文、希臘文、西里爾字母、亞美尼亞語、希伯來文、阿拉伯文、敘利亞文及馬爾代夫語(Unicode 范圍由 U+0080 至 U+07FF)需要二個字節,其他基本多文種平面(BMP)中的字符(CJK屬于此類-Qieqie注)使用三個字節,其他 Unicode 輔助平面的字符使用四字節編碼。
所以。。我們可以看看在鴻蒙系統上使用的是什么編碼格式的,先寫個demo驗證一下
void test(void)
{
uint8_t i = 0;
char *ch = "鴻蒙";
//uint32_t byte;
printf("len is %d\r\n",strlen(ch));
for (i = 0; i < strlen(ch); i++)
{
printf("code is %x \n", *(ch +i));
}
}
輸出
len is 6 code is ffffffe9 code is ffffffb8 code is ffffffbf code is ffffffe8 code is ffffff92 code is ffffff99
整理一下就是 e9b8bf 和 e89299 兩個漢字6字節,一個就3字節,證明編碼使用UTF-8來的
OK,確定了編碼之后,該如何進行下一步?我們使用的ssd1306是不包含字庫的,所以需要自己生成字庫,那么通常的辦法是把需要的字體生成字庫數組,然后再通過索引找到這個字再顯示出來,我這個也是這樣的思路,只不過換了個方法來找字體,那就是通過編碼來找。
我們可以先把漢字轉成utf-8編碼,比如“鴻蒙”的編碼就是 0xe9b8bf 0xe89299
轉換的網站是這個
轉換UTF-8
在里面生成UTF-8編碼,然后記住
在代碼里創建一個結構體:
typedef struct
{
unsigned int Index; //漢字編碼UTF-8
unsigned char Msk[32]; //字模
}typFNT_GB16;
然后創建結構體數組:
typFNT_GB16 CN16_Msk[2] = {
{
0xE9B8BF,
{
0x00,0x80,0x40,0x1F,0x84,0x44,0x44,0x04,0x24,0x44,0xC4,0x47,0x5C,0x48,0x40,0x00,
0x10,0x20,0x7C,0x44,0x64,0x54,0x44,0x4C,0x40,0x7E,0x02,0x02,0x7A,0x02,0x0A,0x04,/*"鴻",0*/
}
},
{
0xE89299,
{
0x08,0xFF,0x08,0x7F,0x40,0x8F,0x00,0x7F,0x06,0x3B,0x04,0x19,0x62,0x0C,0x72,0x01,
0x20,0xFE,0x20,0xFE,0x02,0xE4,0x00,0xFC,0x00,0x08,0xB0,0xC0,0xA0,0x98,0x86,0x00,/*"蒙",1*/
}
},
};
字模生成使用PCtoLCD 配置是 陰碼,順向,行列式,16進制。
顯示中文代碼
上面的準備工作做好之后,接下來就是編寫顯示的函數了,一開始想直接用代碼自帶的字庫數組,無奈,這個代碼的作者是使用u16類型來編碼的,所以無法適配我們u8類型,所以還是得自己編寫,那么實現的代碼如下:
void ssd1306_Print(uint8_t x, uint8_t y, char *s, SSD1306_COLOR color)
{
unsigned char i,k,length;
uint32_t Index = 0;
uint8_t b;
length = strlen(s);//取字符串總長
for(k=0; k 127){//大于127,為漢字,UTF-8是3個字節
Index = ((uint8_t)(*(s+k)) << 16) | ((uint8_t)(*(s+k+1)) << 8) | (uint8_t)((s+k+2));
//取漢字的編碼
//printf("byte is %x \r\n", Index );
for(i=0;i
核心也是畫點函數,根據字節來確定是否點亮那個位置,
適配英文字符
為了適配英文,原生字庫沒有帶有8x16大小的英文字符數組,最接近的也是7x10,所以我寫了一個8x16顯示字符的函數:
char ssd1306_DrawChar_u8(char ch, SSD1306_COLOR color) {
uint32_t i, j;
uint8_t b;
// Check if character is valid
if (ch < 32 || ch > 126)
return 0;
// Check remaining space on current line
if (SSD1306_WIDTH < (SSD1306.CurrentX + 8) ||
SSD1306_HEIGHT < (SSD1306.CurrentY + 16))
{
// Not enough space on current line
return 0;
}
// Use the font to write
for(i = 0; i < 16; i++) { //
b = Font8x16[(ch - 32) * 16 + i];
for(j = 0; j < 8; j++) {
if((b << j) & 0x80) {
ssd1306_DrawPixel(SSD1306.CurrentX + j, (SSD1306.CurrentY + i), (SSD1306_COLOR) color);
} else {
ssd1306_DrawPixel(SSD1306.CurrentX + j, (SSD1306.CurrentY + i), (SSD1306_COLOR)!color);
}
}
}
// The current space is now taken
SSD1306.CurrentX += 8;
// Return written char for validation
return ch;
}
這個函數是對應8x16大小的ascii碼,如果想換其他的大小的請自己修改。舉一反三
如果想使用原生字庫,只需把ssd1306_DrawChar_u8(*(s+k), color); 改成ssd1306_DrawChar((s+k),(字體), color);
就可以了,不過中英文混搭輸出還是字體大小對應得上比較好。
驗證
? 編寫好代碼之后就是驗證階段了,驗證結果也就是開頭的效果圖,還別說寫好這樣的代碼以后用起來是很方便的。
編輯:hfy
-
OLED
+關注
關注
119文章
6223瀏覽量
225109 -
鴻蒙系統
+關注
關注
183文章
2638瀏覽量
66835
發布評論請先 登錄
相關推薦
如何將RT-Thread移植到NXP MCUXPressoIDE上
【瑞薩RA2L1入門學習】+ OLED驅動
HiSpark IPC AI攝像頭(Hi3518E)串口能輸入輸出嗎?
【星閃派物聯網開發套件體驗連載】智能交通燈
史無前例,移植V8虛擬機到純血鴻蒙系統
【GD32 MCU 移植教程】9、從 STM32F10x 系列移植到 GD32F30x 系列
關于使用esp_iot_rtos_sdk 的 wifi_station_connect() api調用遇到的疑問求解
在OpenHarmony 3.1版本中,潤和hispark hi3861智能家居套件I2C驅動OLED屏幕的驅動如何改寫?
使用GPIO口作為電源驅動OLED

最新開源代碼證實!“鴻蒙原生版”微信正在積極開發中
鴻蒙這么大聲勢,為何遲遲看不見崗位?最新數據來了
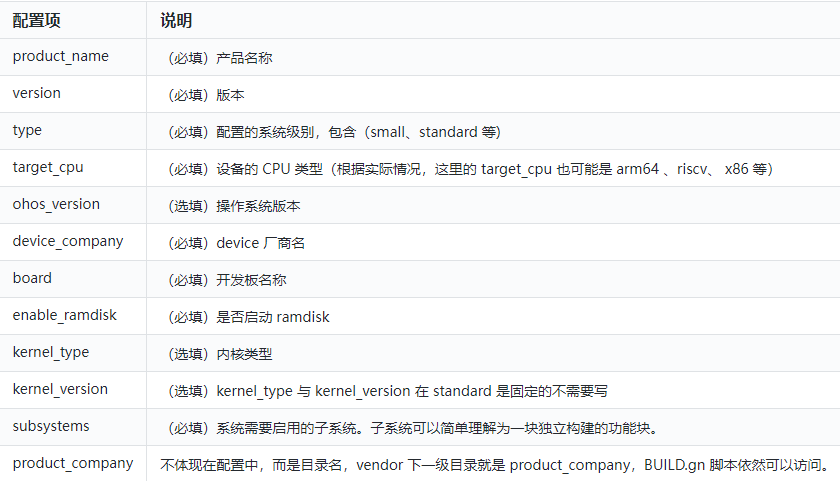
【鴻蒙】標準系統移植指南





 工商網監
工商網監

評論